

現今開發者常苦於將複雜的可視化文件轉為可靠、結構化的輸入以提供給智能體與 LLM 工作流程使用。本文將說明為何進階 OCR 已是必備工具、DeepSeek-OCR 2 如何解決版面配置與閱讀順序辨識失敗的問題,以及如何在生產環境中以可預測的低 API 與 GPU 成本部署它。
為何現代模型迫切需要進階 OCR?
光學字元辨識(OCR)能將可視文字轉換為機器可編碼的文字與結構化表示,支援搜尋、索引、語義解析、編輯,以及與語言導向工作流程的整合。傳統 OCR 專注於字元層級擷取,但新興 AI 工作流程需要更豐富的文件理解能力,包含版面配置與語義上下文,以輸入視覺語言系統或檢索增強生成流程。OCR 對於文件、表單、表格、發票、研究論文與場景文字仍不可或缺,這些用例在業界中隨處可見。

DeepSeek OCR 2 核心創新
| 創新項目 | 說明 | 影響 |
|---|---|---|
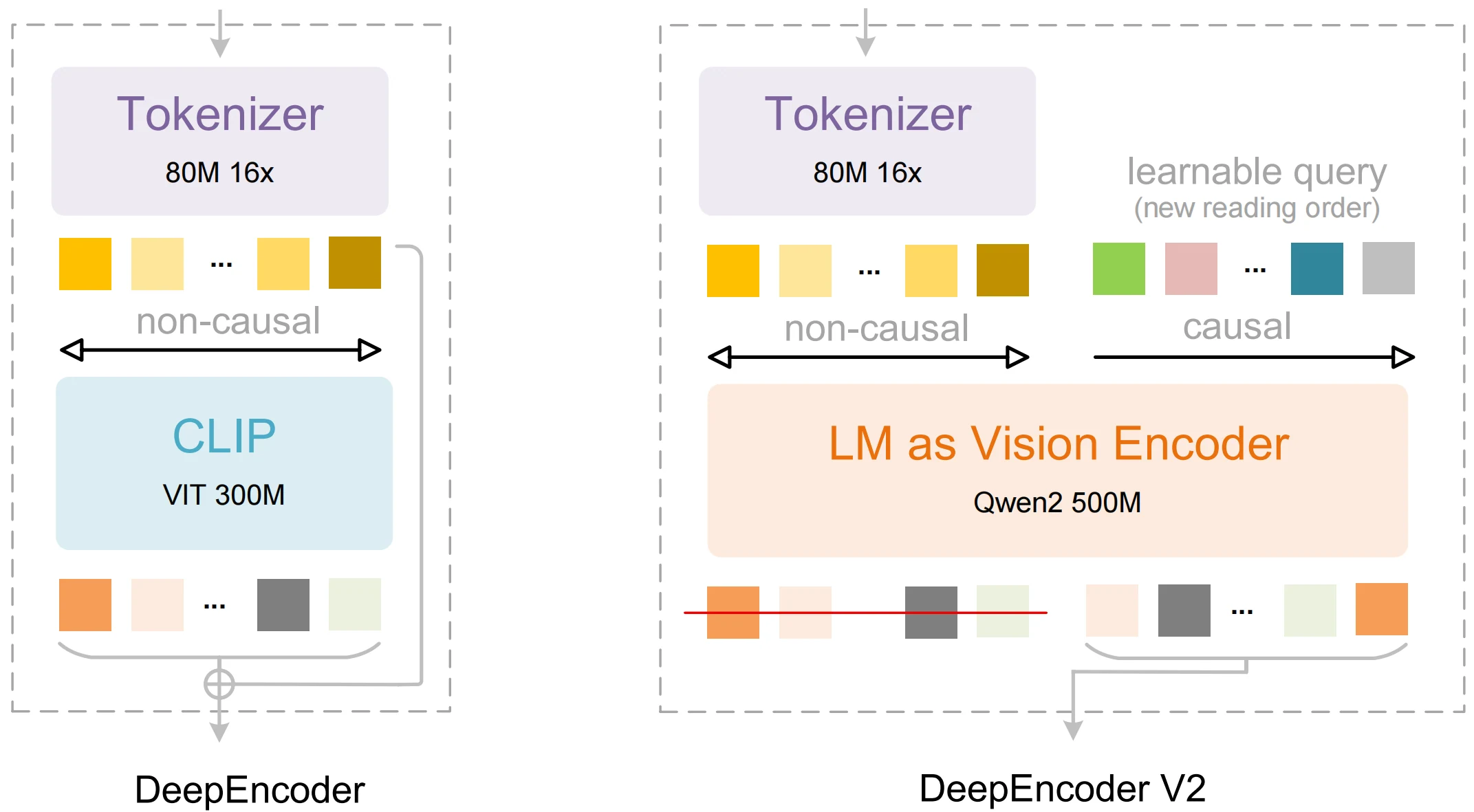
| DeepEncoder V2 | 模仿人類閱讀順序而非固定掃描的視覺編碼器 | 提升結構化擷取能力與版面配置辨識度 |
| 視覺因果流 | 在序列解碼前先理解全域上下文 | 表格與多欄文字的輸出排序更準確 |
| 30 億參數設計 | 體積輕巧卻具備進階推理能力 | 資源佔用低於多數替代方案,同時準確率具競爭力 |
| 多模態處理 | 視覺 + 語言整合,用於 OCR 與解讀 | 支援文字、版面配置與文件層級語義理解 |
來源:github
DeepSeek OCR 2 效能表現
準確率
整體字元準確率從 82.7% 提升至 91.1%(+8.4%),單字準確率從 75.0% 提升至 85.9%(+10.9%)。
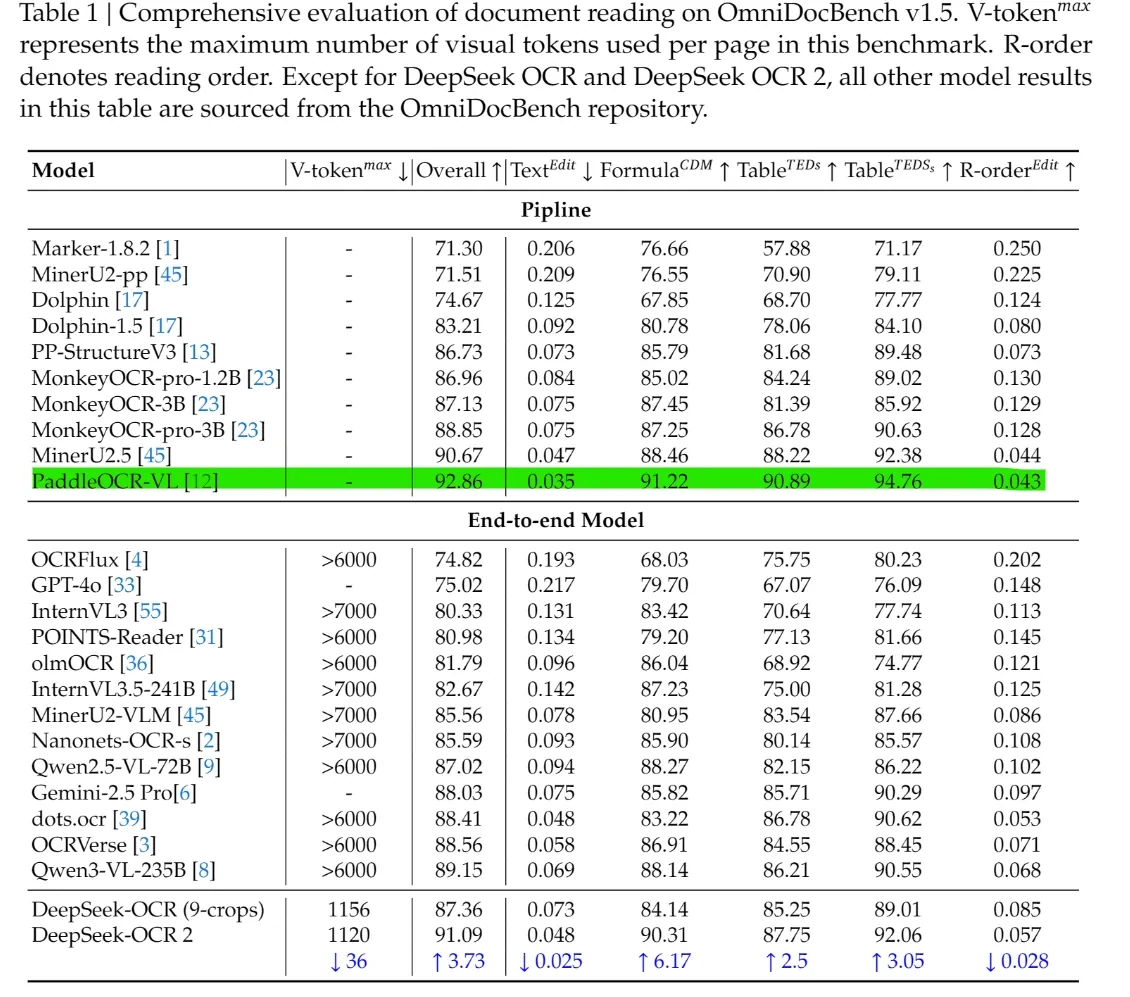
在 OmniDocBench v1.5 測試中,總分達到 91.09,較 v1.0 提升 3.73 分。
閱讀順序辨識
閱讀順序辨識的可靠性大幅提升,編輯距離從 0.085 降至 0.057,代表文件邏輯的重建準確度更高。
生產環境穩定性
各項優化已落地至實際部署場景:
- 線上使用者日誌重複率從 6.25% 降至 4.17%。
- PDF 處理重複率從 3.69% 降至 2.88%。
這些變化代表生產環境中的辨識與版面配置錯誤大幅減少。
效能效率
複雜頁面僅需 256–1120 個視覺標記即可處理。
v1.0 在最高 20 倍壓縮下能維持 60% 準確率,v2.0 則更進一步:在 OmniDocBench 測試中,僅使用 100 個視覺標記(對比 GOT-OCR 2.0 的 256 個)即可超越後者效能。
來源:Reddit
在 OmniDocBench v1.5 測試中,DeepSeek-OCR 2 獲得 91.09 的總分,優於 GPT-4o、Gemini-2.5 Pro、Qwen-VL 等多數端到端模型。其在結構維度也位居領先,Text^Edit 與 R-order^Edit 分數更低,Formula 與 Table 分數更高,展現出比一般視覺語言模型更強的版面配置、表格、公式與閱讀順序建模能力。關鍵在於,這些結果僅使用 1120 個視覺標記即可達成,而多數競爭對手的端到端模型需要超過 6000 個標記。這項差距顯示 DeepSeek-OCR 2 在運算成本大幅降低的前提下,仍能提供更高的文件理解準確率,兼具基準測試領導地位與實際部署可行性。
何時選擇 DeepSeek-OCR 2?
最適合需要文件層級理解、結構化擷取,以及與多模態 AI 系統整合工作流程的應用場景。
** ideal 適用場景:**
- 需保留版面配置完整性的法律與金融文件自動化。
- 研究論文匯入與結構化標記流程。
- 需保留閱讀順序的企業文件索引。
限制:
- 高效推論需要 GPU 資源支援。
- 手寫文字擷取並非其核心功能(專用模型可能表現更佳)。
如何以可預測的 API 成本將 OCR 加入智能體流程
Novita 提供的 H100 隨需定價為每小時 1.80 美元,比其他提供相同 GPU 效能的供應商便宜高達 30%。
Novita AI 的 Spot 模式 是成本優化型的 GPU 租賃選項,會調度平台未使用或閒置的 GPU 容量。與預留專用硬體、保證可持續使用的隨需實例不同,Spot 實例是可中斷的——價格顯著更低,通常比隨需實例便宜40–60%。
這一定價模式能運作,是因為 Novita 會動態將閒置 GPU 重新分配給短期使用者,而非讓其閒置。如此一來,平台提升了整體基礎設施利用率,開發者則能為彈性工作負載爭取到更低的運算成本。
步驟 1:進入控制台
啟動 GPU 介面,選擇「開始使用」進入部署管理頁面。
步驟 2:選擇套件
在模板儲存庫中找到 PaddleOCR-VL,開始安裝流程。
步驟 3:基礎設施設定
配置運算參數,包含記憶體分配、儲存需求與網路設定,選擇「部署」即可執行。
步驟 4:審核與建立
再次確認配置細節與費用摘要,確認無誤後點擊「部署」開始建立流程。
步驟 5:等待建立完成
啟動部署後,系統會自動跳轉至實例管理頁面,你的實例將在背景中建立。
步驟 6:監控下載進度
即時追蹤映像下載進度,部署完成後實例狀態會從「拉取中」變為「執行中」,點擊實例名稱旁的箭頭圖示即可查看詳細進度。
步驟 7:環境存取
透過「連接」介面啟動開發空間,接著初始化「啟動 Web 終端機」。
DeepSeek-OCR 2 具備擬人閱讀順序、優異的結構準確率與極低的視覺標記使用量,表現優於一般視覺語言模型的同時仍具備部署可行性。搭配高性價比 GPU 基礎設施,能讓真實智能體流程具備可擴展、可預測的 OCR 能力。
為何智能體需要 DeepSeek-OCR 2 而非基礎 OCR?
DeepSeek-OCR 2 提供版面配置與閱讀順序建模能力,能讓智能體將表格、PDF 與多欄文件解析為結構化文字。
DeepSeek-OCR 2 在生產場景中的準確率如何?
DeepSeek-OCR 2 將字元準確率提升至 91.1%,並降低閱讀順序錯誤,減少線上系統的重複率。
為何 DeepSeek-OCR 2 的運行成本比一般視覺語言模型更低?
DeepSeek-OCR 2 僅使用 256–1120 個視覺標記即達到基準測試領先水平,遠低於多數視覺語言模型所需的 6000+ 個標記。
Novita AI 是一個 AI 雲端平台,為開發者提供簡單的 API 介面輕鬆部署 AI 模型,同時也提供高性價比、可靠的 GPU 雲端服務,用於建構與擴展 AI 應用。




{kind=link}