

Les développeurs ont aujourd’hui du mal à transformer des documents visuels complexes en entrées fiables et structurées pour les agents et les workflows LLM. Cet article explique pourquoi l’OCR avancé est désormais obligatoire, comment DeepSeek-OCR 2 résout les problèmes de mise en page et d’ordre de lecture, et comment le déployer en production avec des coûts d’API et de GPU prévisibles et bas.
Pourquoi les modèles modernes ont-ils urgemment besoin d’OCR avancé ?
La reconnaissance optique de caractères (OCR) convertit le texte visuel en texte encodé par machine et en représentations structurées, permettant la recherche, l’indexation, l’analyse sémantique, l’édition et l’intégration avec des workflows centrés sur le langage. L’OCR traditionnelle se concentrait sur l’extraction au niveau des caractères, mais les workflows IA émergents nécessitent une compréhension de documents plus riche, incluant le contexte de mise en page et sémantique pour alimenter les systèmes vision-langue ou la génération augmentée par récupération. L’OCR reste essentielle pour les documents, formulaires, tableaux, factures, articles de recherche et texte de scène – des cas d’usage omniprésents dans l’industrie.

Depuis analyticsvidhya
Essayez DeepSeek OCR 2 dès maintenant !
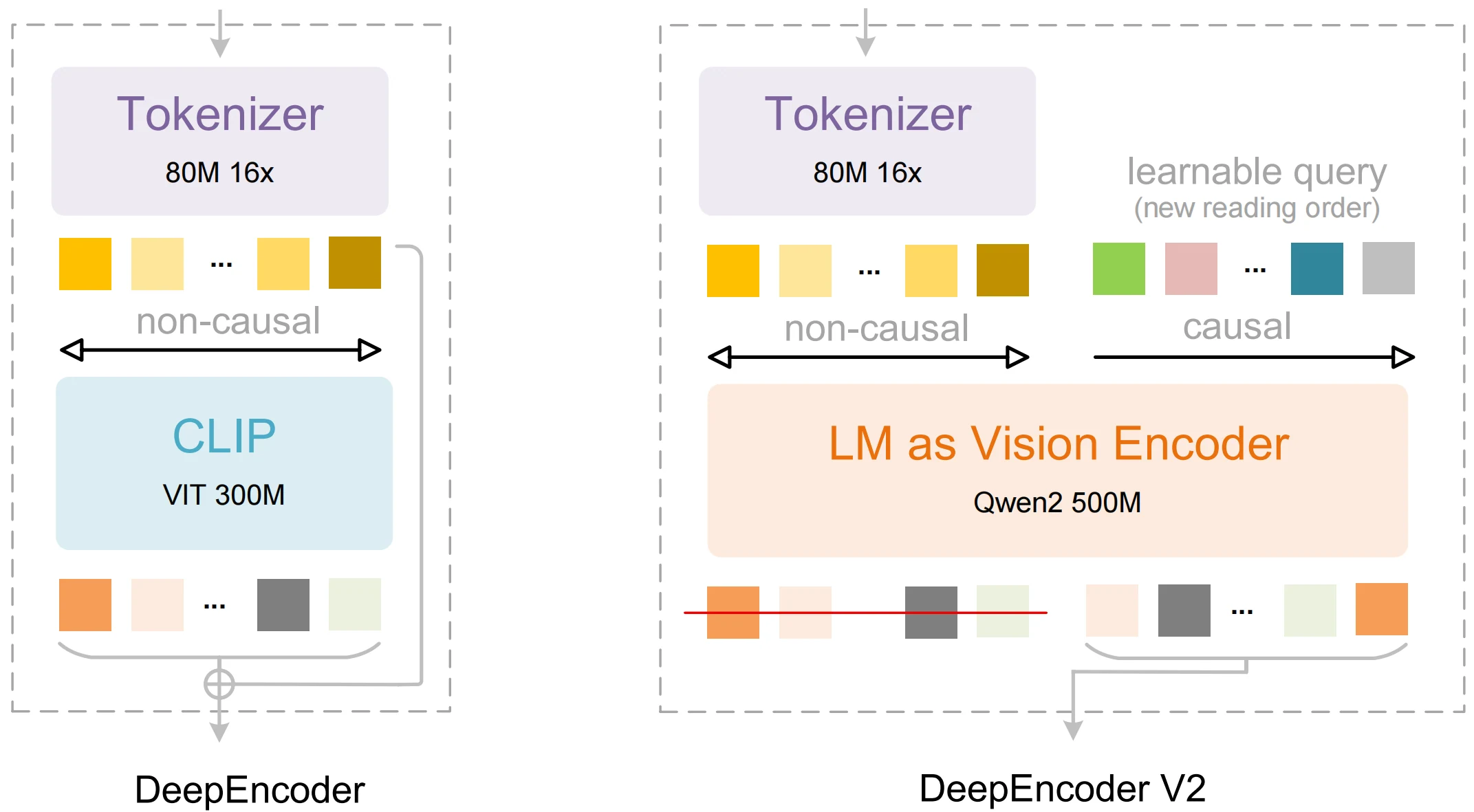
Innovations clés de DeepSeek OCR 2
| Innovation | Description | Impact |
|---|---|---|
| DeepEncoder V2 | Un encodeur visuel qui imite l’ordre de lecture humain plutôt qu’un balayage fixe. | Meilleure extraction structurée et conscience de la mise en page. |
| Visual Causal Flow | Compréhension du contexte global avant le décodage séquentiel. | Ordre plus précis dans la sortie pour les tableaux et le texte multicolonne. |
| Conception 3 milliards de paramètres | Compacte mais capable de raisonnement avancé. | Empreinte ressources plus faible que de nombreuses alternatives tout en étant compétitive en précision. |
| Traitement multimodal | Intégration vision + langage pour l’OCR et l’interprétation. | Permet la sémantique du texte, de la mise en page et au niveau du document. |
Depuis github
Essayez DeepSeek OCR 2 dès maintenant !
Capacités de DeepSeek OCR 2
Précision
La précision globale des caractères passe de 82,7 % à 91,1 % (+8,4 %), et la précision des mots de 75,0 % à 85,9 % (+10,9 %).
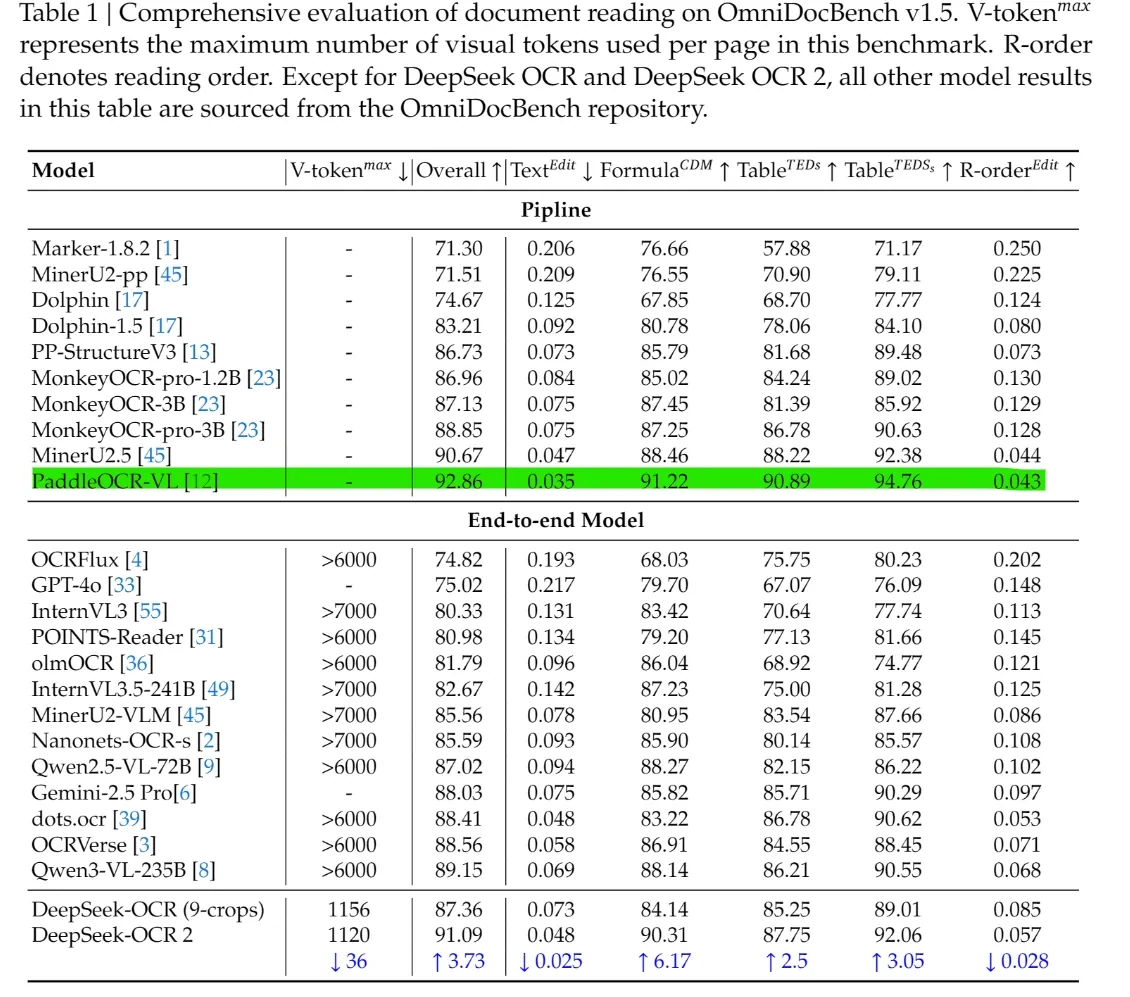
Sur OmniDocBench v1.5, le score global atteint 91,09, soit une amélioration de 3,73 points par rapport à la v1.0.
Ordre de lecture
La reconnaissance de l’ordre de lecture devient plus fiable, avec une distance d’édition réduite de 0,085 à 0,057, indiquant une reconstruction plus précise de la logique du document.
Stabilité en production
Les améliorations se traduisent dans les déploiements réels :
- Le taux de duplication des journaux d’utilisateurs en ligne passe de 6,25 % à 4,17 %.
- Le taux de duplication du traitement des PDF passe de 3,69 % à 2,88 %.
Ces changements reflètent moins d’erreurs de reconnaissance et de mise en page en production.
Efficacité
Les pages complexes sont traitées en utilisant seulement 256 à 1120 jetons visuels.
Alors que la v1.0 maintient une précision de 60 % pour une compression allant jusqu’à 20×, la v2.0 va plus loin : sur OmniDocBench, elle surpasse GOT-OCR 2.0 en utilisant seulement 100 jetons visuels contre 256.
Depuis Reddit
Sur OmniDocBench v1.5, DeepSeek-OCR 2 obtient un score global de 91,09, surpassant la plupart des modèles de bout en bout tels que GPT-4o, Gemini-2.5 Pro et Qwen-VL. Il est également leader dans les dimensions structurelles, avec des scores Text^Edit et R-order^Edit plus bas et des scores Formula et Table plus élevés, démontrant une modélisation plus forte de la mise en page, des tableaux, des formules et de l’ordre de lecture que les VLMs généralistes. Fait crucial, ces résultats sont obtenus avec seulement 1120 jetons visuels, alors que la plupart des modèles de bout en bout concurrents nécessitent plus de 6000. Cet écart montre que DeepSeek-OCR 2 offre une précision de compréhension de documents plus élevée pour un coût de calcul nettement plus faible, combinant leadership en benchmark et déployabilité pratique.
Essayez DeepSeek OCR 2 dès maintenant !
Quand choisir DeepSeek-OCR 2 ?
Idéal pour les applications nécessitant une compréhension au niveau du document, une extraction structurée et une intégration aux workflows avec des systèmes IA multimodaux.
Cas d’usage idéaux :
- Automatisation de documents juridiques et financiers avec intégrité de la mise en page.
- Ingestion d’articles de recherche et pipelines de balisage structuré.
- Indexation de documents d’entreprise avec préservation de l’ordre de lecture.
Limites :
- Nécessite des ressources GPU pour une inférence efficace.
- L’extraction de l’écriture manuscrite n’est pas l’objectif principal (des modèles dédiés peuvent être plus performants).
Comment ajouter l’OCR à votre flux d’agent avec des coûts d’API prévisibles
Novita propose les tarifs de H100 à la demande les plus bas, à 1,80 $/h, soit jusqu’à 30 % moins chers que ceux des autres fournisseurs avec des performances GPU identiques.
Le mode Spot de Novita AI est une option de location de GPU optimisée pour les coûts qui exploite la capacité GPU inutilisée ou inactive de la plateforme. Contrairement aux instances à la demande, qui réservent du matériel dédié pour une utilisation continue garantie, les instances Spot sont interruptibles – proposées à des tarifs nettement plus bas, généralement 40 à 60 % moins chers.
Ce modèle tarifaire fonctionne car Novita réaffecte dynamiquement les GPU inactifs aux utilisateurs à court terme au lieu de les laisser inutilisés. Ce faisant, la plateforme améliore l’efficacité d’utilisation globale de l’infrastructure, tandis que les développeurs bénéficient de coûts de calcul beaucoup plus bas pour des charges de travail flexibles.
Essayez DeepSeek OCR 2 dès maintenant !
Étape 1 : Accès à la console
Lancez l’interface GPU et sélectionnez Get Started pour accéder à la gestion des déploiements.
Étape 2 : Sélection du package
Localisez PaddleOCR-VL dans le référentiel de modèles et lancez la séquence d’installation.
Étape 3 : Configuration de l’infrastructure
Configurez les paramètres de calcul incluant l’allocation de mémoire, les exigences de stockage et les paramètres réseau. Sélectionnez Deploy pour lancer le déploiement.
Étape 4 : Vérification et création
Vérifiez attentivement les détails de votre configuration et le récapitulatif des coûts. Lorsque vous êtes satisfait, cliquez sur Deploy pour lancer le processus de création.
Étape 5 : Attente de la création
Après avoir lancé le déploiement, le système vous redirigera automatiquement vers la page de gestion des instances. Votre instance sera créée en arrière-plan.
Étape 6 : Suivi de la progression du téléchargement
Suivez la progression du téléchargement de l’image en temps réel. L’état de votre instance passera de Pulling à Running une fois le déploiement terminé. Vous pouvez consulter la progression détaillée en cliquant sur l’icône de flèche à côté du nom de votre instance.
Étape 7 : Accès à l’environnement
Lancez l’espace de développement via l’interface Connect, puis initialisez Start Web Terminal.
Avec un ordre de lecture similaire à celui de l’homme, une forte précision structurelle et une utilisation ultra-faible de jetons visuels, DeepSeek-OCR 2 surpasse les VLMs généralistes tout en restant déployable. Associé à une infrastructure GPU rentable, il permet une OCR évolutive et prévisible dans de véritables pipelines d’agents.
Pourquoi les agents ont-ils besoin de DeepSeek-OCR 2 au lieu d’une OCR basique ?
DeepSeek-OCR 2 propose une modélisation de la mise en page et de l’ordre de lecture, permettant aux agents de consommer des tableaux, des PDF et des documents multicolonnes sous forme de texte structuré.
Quelle est la précision de DeepSeek-OCR 2 dans les scénarios de production ?
DeepSeek-OCR 2 porte la précision des caractères à 91,1 % et réduit les erreurs d’ordre de lecture, ce qui diminue les taux de duplication dans les systèmes en direct.
Pourquoi DeepSeek-OCR 2 est-il moins cher à exécuter que les VLMs généralistes ?
DeepSeek-OCR 2 atteint le leadership en benchmark en utilisant seulement 256 à 1120 jetons visuels, bien en dessous des plus de 6000 jetons requis par de nombreux VLMs.
Novita AI est une plateforme cloud IA qui offre aux développeurs un moyen simple de déployer des modèles IA via notre API intuitive, tout en fournissant un cloud GPU abordable et fiable pour construire et mettre à l’échelle.




{kind=link}