

Os desenvolvedores hoje lutam para transformar documentos visuais complexos em entradas confiáveis e estruturadas para fluxos de trabalho de agentes e LLMs. Este artigo explica por que o OCR avançado é agora obrigatório, como o DeepSeek-OCR 2 resolve falhas de layout e ordem de leitura, e como implantá-lo em produção com custos previsíveis e baixos de API e GPU.
Por que os modelos modernos precisam urgentemente de OCR avançado?
O reconhecimento óptico de caracteres (OCR) converte texto visual em texto codificado por máquina e representações estruturadas, permitindo busca, indexação, análise semântica, edição e integração com fluxos de trabalho centrados em linguagem. O OCR tradicional focava na extração em nível de caractere, mas os fluxos de trabalho de IA emergentes exigem compreensão de documentos mais rica, incluindo layout e contexto semântico para alimentar sistemas de visão e linguagem ou geração aumentada por recuperação. O OCR continua sendo essencial para documentos, formulários, tabelas, faturas, artigos de pesquisa e texto de cena — casos de uso onipresentes na indústria.

Experimente o DeepSeek OCR 2 agora!
Inovações principais do DeepSeek OCR 2
| Inovação | Descrição | Impacto |
|---|---|---|
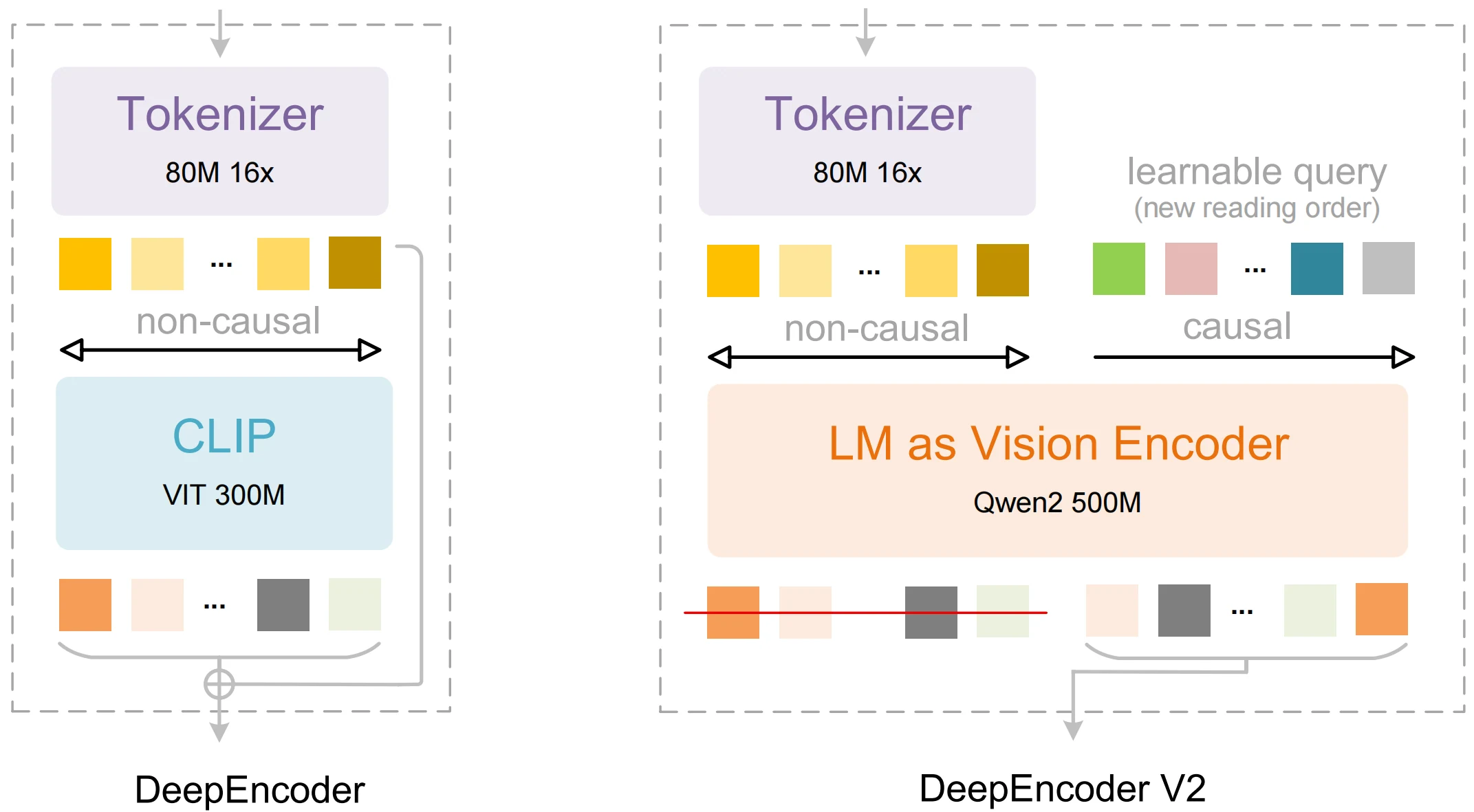
| DeepEncoder V2 | Um codificador de visão que imita a ordem de leitura humana em vez de uma varredura fixa. | Extração estruturada melhorada e consciência de layout. |
| Visual Causal Flow | Compreensão do contexto global antes da decodificação sequencial. | Ordenação mais precisa na saída para tabelas e texto em várias colunas. |
| Projeto de 3 B de parâmetros | Compacto, mas capaz de raciocínio avançado. | Pegada de recursos menor do que muitas alternativas, mantendo competitividade em precisão. |
| Processamento multimodal | Integração de visão + linguagem para OCR e interpretação. | Permite texto, layout e semântica em nível de documento. |
De github
Experimente o DeepSeek OCR 2 agora!
Capacidade do DeepSeek OCR 2
Precisão
A precisão geral de caracteres melhora de 82,7% para 91,1% (+8,4%), e a precisão de palavras de 75,0% para 85,9% (+10,9%).
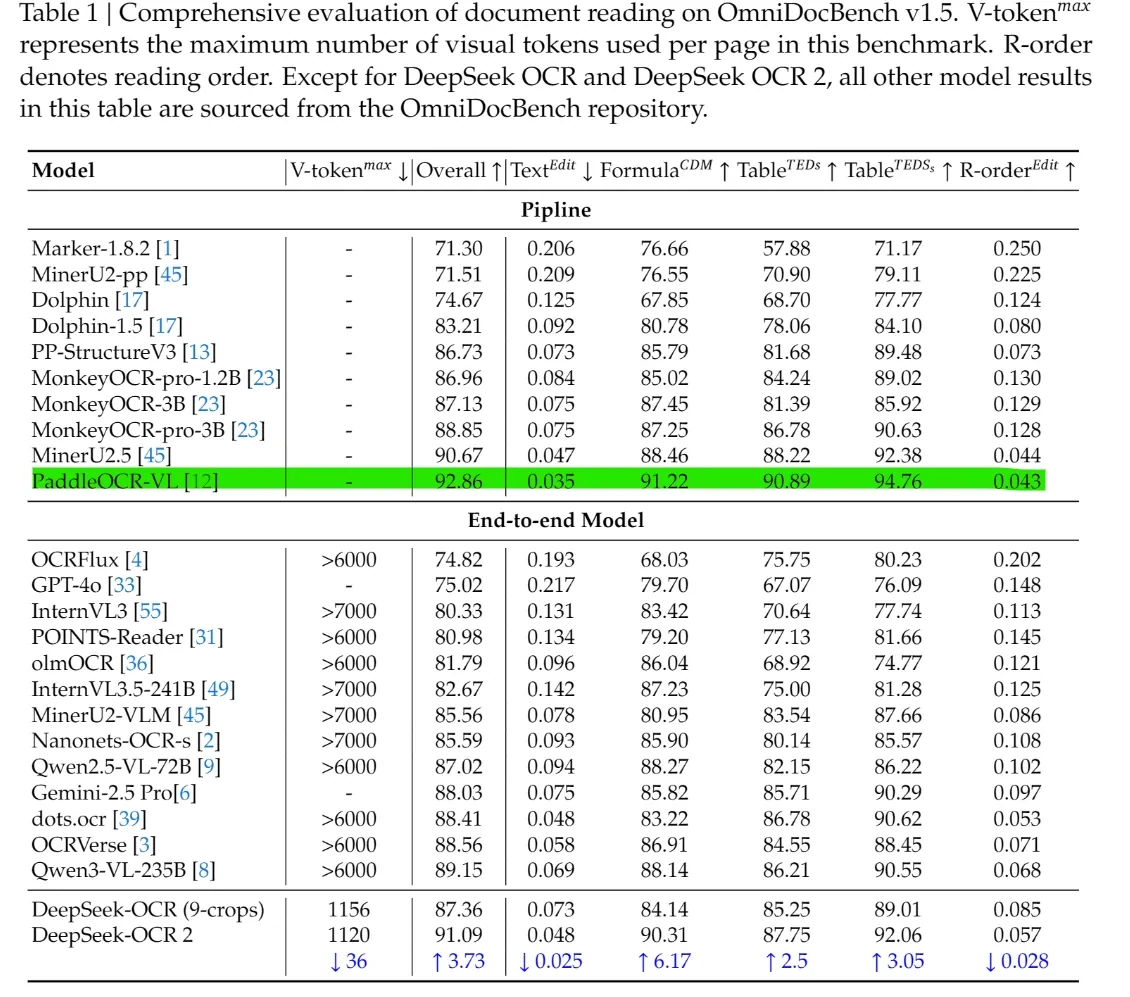
No OmniDocBench v1.5, a pontuação geral atinge 91,09, melhorando 3,73 pontos em relação à v1.0.
Ordem de leitura
O reconhecimento da ordem de leitura se torna mais confiável, com a distância de edição reduzida de 0,085 para 0,057, indicando uma reconstrução mais precisa da lógica do documento.
Estabilidade em produção
As melhorias se aplicam a implantações reais:
- A taxa de duplicação de registros de usuários online cai de 6,25% para 4,17%.
- A taxa de duplicação no processamento de PDFs cai de 3,69% para 2,88%.
Essas mudanças refletem menos erros de reconhecimento e layout em produção.
Eficiência
Páginas complexas são processadas usando apenas 256 a 1120 tokens visuais.
Enquanto a v1.0 mantém 60% de precisão com até 20× de compressão, a v2.0 vai mais longe: no OmniDocBench, supera o GOT-OCR 2.0 usando apenas 100 tokens visuais contra 256.
De Reddit
No OmniDocBench v1.5, o DeepSeek-OCR 2 atinge uma pontuação geral de 91,09, superando a maioria dos modelos de ponta a ponta, como GPT-4o, Gemini-2.5 Pro e Qwen-VL. Ele também lidera nas dimensões estruturais, com menores Text^Edit e R-order^Edit e pontuações mais altas em Fórmula e Tabela, demonstrando modelagem de layout, tabela, fórmula e ordem de leitura mais forte do que VLMs gerais.
Crucialmente, esses resultados são obtidos com apenas 1120 tokens visuais, enquanto a maioria dos modelos de ponta a ponta concorrentes requer mais de 6000. Essa lacuna mostra que o DeepSeek-OCR 2 oferece maior precisão de compreensão de documentos com custo computacional drasticamente menor, combinando liderança em benchmarks com implantação prática.
Experimente o DeepSeek OCR 2 agora!
Quando escolher o DeepSeek-OCR 2?
Mais adequado para aplicações que exigem compreensão em nível de documento, extração estruturada e integração de fluxo de trabalho com sistemas de IA multimodais.
Casos de uso ideais:
- Automação de documentos jurídicos e financeiros com integridade de layout.
- Ingestão de artigos de pesquisa e pipelines de marcação estruturada.
- Indexação de documentos empresariais com preservação da ordem de leitura.
Limitações:
- Requer recursos de GPU para inferência eficiente.
- A extração de manuscritos não é o foco principal (modelos dedicados podem ter melhor desempenho).
Como adicionar OCR ao fluxo do seu agente com custos de API previsíveis
A Novita oferece o menor preço sob demanda para H100 a US$ 1,80/hora, até 30% mais barato do que outros provedores com desempenho de GPU idêntico.
O modo Spot da Novita AI é uma opção de aluguel de GPU otimizada para custos que aproveita a capacidade de GPU não utilizada ou ociosa da plataforma. Ao contrário das instâncias sob demanda, que reservam hardware dedicado para uso contínuo garantido, as instâncias Spot são interrompíveis — oferecidas a preços significativamente menores, geralmente 40–60% mais baratas.
Esse modelo de preços funciona porque a Novita realoca dinamicamente GPUs ociosas para usuários de curto prazo, em vez de deixá-las sem uso. Ao fazer isso, a plataforma melhora a eficiência geral de utilização da infraestrutura, enquanto os desenvolvedores se beneficiam de custos computacionais muito menores para cargas de trabalho flexíveis.
Experimente o DeepSeek OCR 2 agora!
Passo 1: Entrada no Console
Inicie a interface de GPU e selecione Começar para acessar o gerenciamento de implantação.
Passo 2: Seleção de Pacote
Localize o PaddleOCR-VL no repositório de modelos e inicie a sequência de instalação.
Passo 3: Configuração da Infraestrutura
Configure os parâmetros de computação, incluindo alocação de memória, requisitos de armazenamento e configurações de rede. Selecione Implantar para implementar.
Passo 4: Revisão e Criação
Verifique novamente os detalhes da sua configuração e o resumo de custos. Quando estiver satisfeito, clique em Implantar para iniciar o processo de criação.
Passo 5: Aguardar a Criação
Após iniciar a implantação, o sistema redirecionará você automaticamente para a página de gerenciamento de instâncias. Sua instância será criada em segundo plano.
Passo 6: Monitorar o Progresso do Download
Acompanhe o progresso do download da imagem em tempo real. O status da sua instância mudará de Pulling para Running assim que a implantação for concluída. Você pode ver o progresso detalhado clicando no ícone de seta ao lado do nome da sua instância.
Passo 7: Acesso ao Ambiente
Inicie o espaço de desenvolvimento por meio da interface Conectar, depois inicialize o Terminal Web Inicial.
Com ordem de leitura semelhante à humana, alta precisão estrutural e uso ultrabaixo de tokens visuais, o DeepSeek-OCR 2 supera os VLMs gerais, mantendo-se implantável. Combinado com infraestrutura de GPU custo-eficiente, ele permite OCR escalável e previsível dentro de pipelines de agentes reais.
Por que os agentes precisam do DeepSeek-OCR 2 em vez de OCR básico?
O DeepSeek-OCR 2 fornece modelagem de layout e ordem de leitura, permitindo que os agentes consumam tabelas, PDFs e documentos de várias colunas como texto estruturado.
Qual é a precisão do DeepSeek-OCR 2 em cenários de produção?
O DeepSeek-OCR 2 aumenta a precisão de caracteres para 91,1% e reduz erros de ordem de leitura, cortando as taxas de duplicação em sistemas ativos.
Por que o DeepSeek-OCR 2 é mais barato de executar do que VLMs gerais?
O DeepSeek-OCR 2 alcança liderança em benchmarks usando apenas 256 a 1120 tokens visuais, muito abaixo dos mais de 6000 tokens exigidos por muitos VLMs.
Novita AI é uma plataforma de nuvem de IA que oferece aos desenvolvedores uma maneira fácil de implantar modelos de IA usando nossa API simples, além de fornecer nuvem de GPU acessível e confiável para construção e escalonamento.




{kind=link}