

오늘날 개발자들은 복잡한 시각적 문서를 신뢰할 수 있는 구조화된 입력으로 변환하여 에이전트 및 LLM 워크플로우에 제공하는 데 어려움을 겪고 있습니다. 이 글에서는 고급 OCR이 왜 이제 필수인지, DeepSeek-OCR 2가 레이아웃 및 읽기 순서 오류를 어떻게 해결하는지, 그리고 예측 가능한 낮은 API 및 GPU 비용으로 프로덕션에 배포하는 방법을 설명합니다.
최신 모델에 고급 OCR이 절실히 필요한 이유
광학 문자 인식(OCR)은 시각적 텍스트를 기계가 읽을 수 있는 텍스트와 구조화된 표현으로 변환하여 검색, 인덱싱, 의미론적 파싱, 편집 및 언어 중심 워크플로우와의 통합을 가능하게 합니다. 기존 OCR은 문자 수준 추출에 초점을 맞추었지만, 새로운 AI 워크플로우는 시각-언어 시스템이나 검색 증강 생성(RAG)에 공급하기 위해 레이아웃 및 의미론적 컨텍스트를 포함한 더 풍부한 문서 이해를 요구합니다. OCR은 문서, 양식, 표, 청구서, 연구 논문, 장면 텍스트 등 산업 전반에서 널리 사용되는 유스케이스에 여전히 필수적입니다.

출처: analyticsvidhya
DeepSeek OCR 2의 핵심 혁신
| 혁신 | 설명 | 영향 |
|---|---|---|
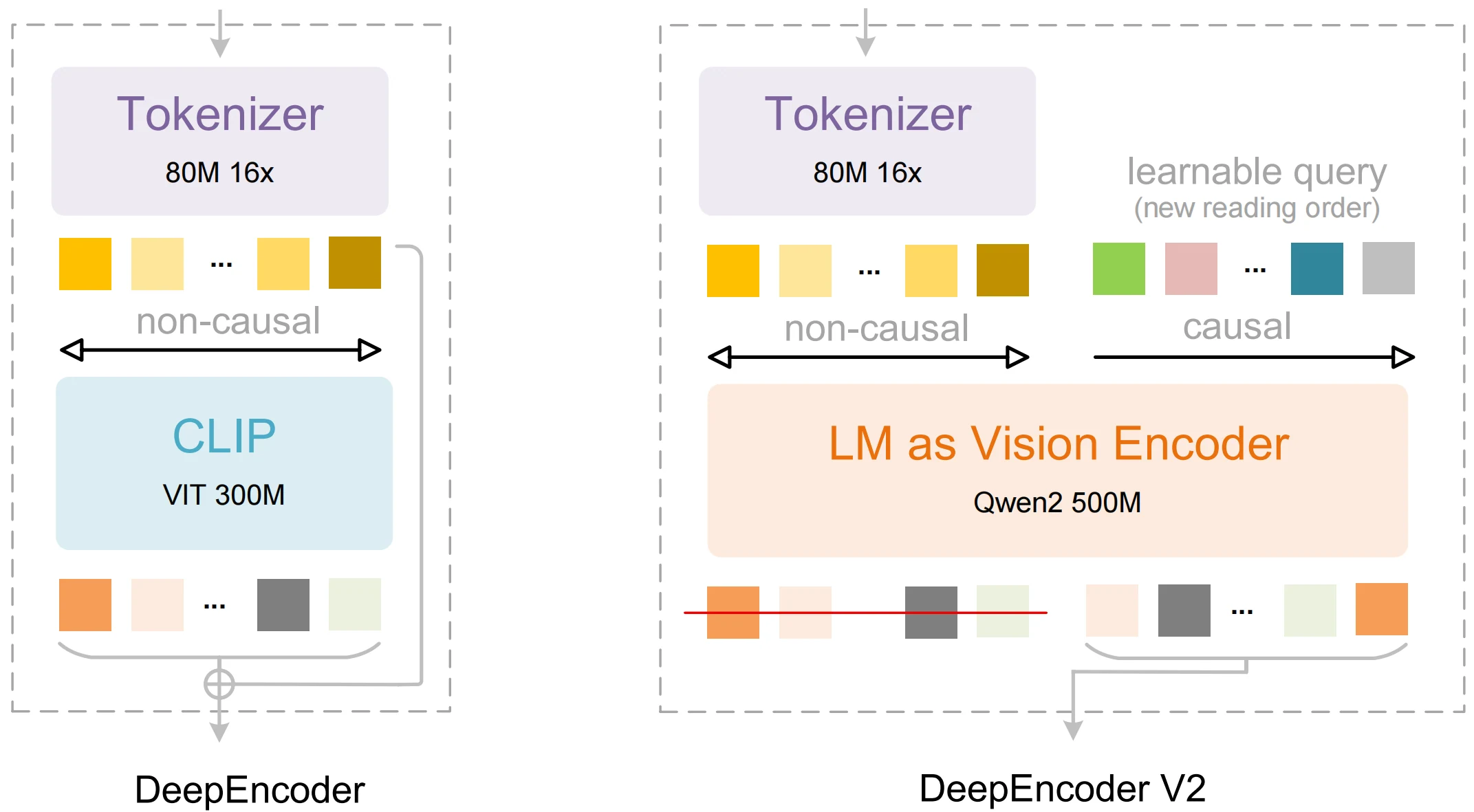
| DeepEncoder V2 | 고정된 스캔 방식 대신 인간의 읽기 순서를 모방하는 비전 인코더 | 더 나은 구조화된 추출 및 레이아웃 인식 |
| Visual Causal Flow | 순차적 디코딩 전 글로벌 컨텍스트 이해 | 표 및 다중 열 텍스트 출력에서 더 정확한 순서 |
| 3B 파라미터 설계 | 컴팩트하면서도 고급 추론 가능 | 많은 대안보다 낮은 리소스 풋프린트, 정확도는 경쟁력 있음 |
| 멀티모달 처리 | 비전 + 언어 통합으로 OCR 및 해석 | 텍스트, 레이아웃, 문서 수준의 의미론 가능 |
출처: github
DeepSeek OCR 2의 성능
정확도
전체 문자 정확도가 82.7%에서 91.1%로(+8.4%), 단어 정확도가 75.0%에서 85.9%로(+10.9%) 향상되었습니다.
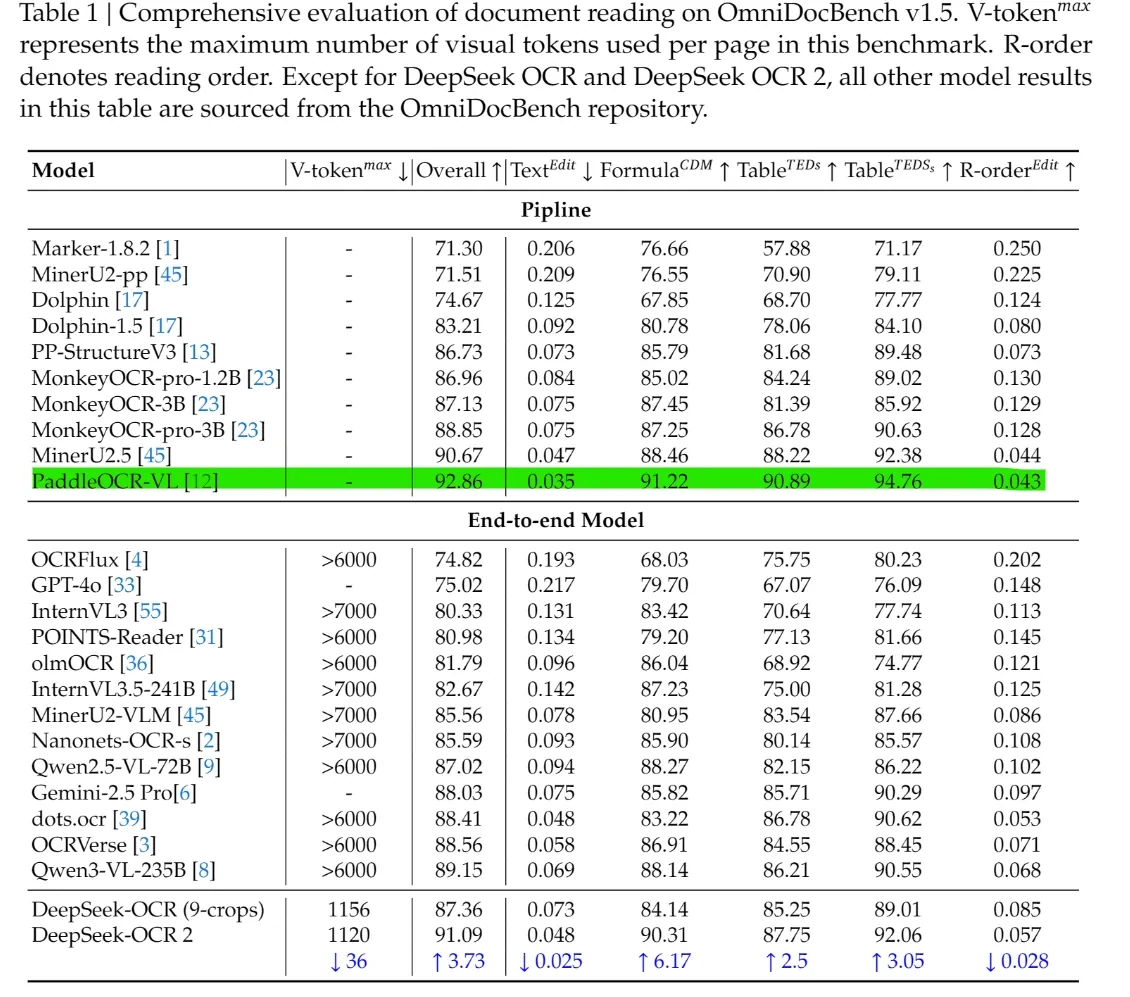
OmniDocBench v1.5에서 Overall 점수는 91.09에 도달하여 v1.0 대비 3.73점 개선되었습니다.
읽기 순서
읽기 순서 인식이 더욱 안정적이 되었으며, 편집 거리가 0.085에서 0.057로 감소하여 문서 논리의 더 정확한 재구성을 나타냅니다.
프로덕션 안정성
개선 사항은 실제 배포에도 반영됩니다.
- 온라인 사용자 로그 중복률이 6.25%에서 4.17%로 감소.
- PDF 처리 중복률이 3.69%에서 2.88%로 감소.
이는 프로덕션에서 인식 및 레이아웃 오류가 감소했음을 의미합니다.
효율성
복잡한 페이지를 처리하는 데 256~1120개의 시각 토큰만 사용합니다.
v1.0이 최대 20배 압축에서 60% 정확도를 유지하는 반면, v2.0은 더 나아갑니다: OmniDocBench에서 GOT-OCR 2.0을 능가하며 256개 대신 100개의 시각 토큰만 사용합니다.
출처: Reddit
OmniDocBench v1.5에서 DeepSeek-OCR 2는 Overall 점수 91.09를 기록하여 GPT-4o, Gemini-2.5 Pro, Qwen-VL과 같은 대부분의 종단간(End-to-End) 모델을 능가합니다. 또한 구조적 차원에서도 선두를 달리며, Text^Edit 및 R-order^Edit 점수가 낮고 Formula 및 Table 점수가 높아 일반 VLM보다 더 강력한 레이아웃, 표, 수식 및 읽기 순서 모델링을 보여줍니다.
결정적으로, 이러한 결과는 단 1120개의 시각 토큰만으로 얻어진 반면, 대부분의 경쟁 종단간 모델은 6000개 이상의 토큰을 필요로 합니다. 이러한 차이는 DeepSeek-OCR 2가 훨씬 낮은 계산 비용으로 더 높은 문서 이해 정확도를 제공하며, 벤치마크 선도성과 실용적인 배포 가능성을 결합하고 있음을 보여줍니다.
DeepSeek-OCR 2를 선택해야 하는 경우
문서 수준 이해, 구조화된 추출 및 멀티모달 AI 시스템과의 워크플로우 통합이 필요한 애플리케이션에 가장 적합합니다.
이상적인 사용 사례:
- 레이아웃 무결성이 중요한 법률 및 금융 문서 자동화
- 연구 논문 수집 및 구조화된 마크업 파이프라인
- 읽기 순서 보존이 필요한 기업 문서 인덱싱
한계:
- 효율적인 추론을 위해 GPU 리소스 필요
- 필기 추출은 주요 초점이 아님(전용 모델이 더 나을 수 있음)
예측 가능한 API 비용으로 에이전트 스트림에 OCR을 추가하는 방법
Novita는 주문형 H100 가격을 시간당 $1.80로 제공하며, 동일한 GPU 성능을 제공하는 다른 공급업체보다 최대 30% 저렴합니다.
Novita AI의 Spot 모드는 플랫폼의 미사용 또는 유휴 GPU 용량을 활용하는 비용 최적화된 GPU 임대 옵션입니다. 전용 하드웨어를 예약하여 지속적인 사용을 보장하는 온디맨드 인스턴스와 달리, Spot 인스턴스는 중단 가능하며 일반적으로 40~60% 저렴한 가격으로 제공됩니다.
이 가격 모델은 Novita가 유휴 GPU를 단기 사용자에게 동적으로 재할당하여 미사용 상태로 두지 않기 때문에 작동합니다. 이를 통해 플랫폼은 전체 인프라 활용 효율성을 개선하고, 개발자는 유연한 워크로드에 대해 훨씬 낮은 계산 비용의 혜택을 누릴 수 있습니다.
1단계: 콘솔 진입
GPU 인터페이스를 실행하고 Get Started를 선택하여 배포 관리에 접속합니다.
2단계: 패키지 선택
템플릿 저장소에서 PaddleOCR-VL을 찾고 설치 시퀀스를 시작합니다.
3단계: 인프라 설정
메모리 할당, 스토리지 요구 사항, 네트워크 설정 등 컴퓨팅 매개변수를 구성합니다. Deploy를 선택하여 구현합니다.
4단계: 검토 및 생성
구성 세부 정보와 비용 요약을 다시 확인합니다. 만족스러우면 Deploy를 클릭하여 생성 프로세스를 시작합니다.
5단계: 생성 대기
배포를 시작하면 시스템이 자동으로 인스턴스 관리 페이지로 리디렉션합니다. 인스턴스는 백그라운드에서 생성됩니다.
6단계: 다운로드 진행 상황 모니터링
이미지 다운로드 진행 상황을 실시간으로 추적합니다. 배포가 완료되면 인스턴스 상태가 Pulling에서 Running으로 변경됩니다. 인스턴스 이름 옆의 화살표 아이콘을 클릭하여 자세한 진행 상황을 볼 수 있습니다.
7단계: 환경 접속
Connect 인터페이스를 통해 개발 공간을 시작한 다음 Start Web Terminal을 초기화합니다.
인간과 유사한 읽기 순서, 강력한 구조적 정확성, 초저 시각 토큰 사용량을 갖춘 DeepSeek-OCR 2는 일반 VLM을 능가하면서도 배포 가능한 상태를 유지합니다. 비용 효율적인 GPU 인프라와 결합하여 실제 에이전트 파이프라인 내에서 확장 가능하고 예측 가능한 OCR을 가능하게 합니다.
에이전트가 기본 OCR 대신 DeepSeek-OCR 2를 필요로 하는 이유는 무엇인가요?
DeepSeek-OCR 2는 레이아웃 및 읽기 순서 모델링을 제공하므로 에이전트가 표, PDF, 다중 열 문서를 구조화된 텍스트로 사용할 수 있습니다.
프로덕션 시나리오에서 DeepSeek-OCR 2의 정확도는 어느 정도인가요?
DeepSeek-OCR 2는 문자 정확도를 91.1%로 높이고 읽기 순서 오류를 줄여 라이브 시스템에서 중복률을 낮춥니다.
DeepSeek-OCR 2가 일반 VLM보다 실행 비용이 저렴한 이유는 무엇인가요?
DeepSeek-OCR 2는 단 256~1120개의 시각 토큰만 사용하여 벤치마크 선도성을 달성하며, 이는 많은 VLM에 필요한 6000개 이상의 토큰보다 훨씬 적습니다.
Novita AI 는 개발자들이 간단한 API를 사용하여 AI 모델을 쉽게 배포할 수 있도록 하고, 구축 및 확장을 위한 저렴하고 안정적인 GPU 클라우드를 제공하는 AI 클라우드 플랫폼입니다.




{kind=link}