

Los desarrolladores hoy en día luchan por convertir documentos visuales complejos en entradas estructuradas y confiables para agentes y flujos de trabajo con LLM. Este artículo explica por qué el OCR avanzado es ahora obligatorio, cómo DeepSeek-OCR 2 resuelve fallos de diseño y orden de lectura, y cómo desplegarlo en producción con costos de API y GPU predecibles y bajos.
¿Por qué los modelos modernos necesitan urgentemente OCR avanzado?
El reconocimiento óptico de caracteres (OCR) convierte texto visual en texto codificado por máquina y representaciones estructuradas, permitiendo búsqueda, indexación, análisis semántico, edición e integración con flujos de trabajo centrados en el lenguaje. El OCR tradicional se centraba en la extracción a nivel de caracteres, pero los flujos de trabajo emergentes de IA requieren una comprensión más rica del documento, incluyendo diseño y contexto semántico para alimentar sistemas de visión-lenguaje o generación aumentada por recuperación. El OCR sigue siendo esencial para documentos, formularios, tablas, facturas, trabajos de investigación y texto en escenas, casos de uso omnipresentes en la industria.

Innovaciones principales en DeepSeek OCR 2
| Innovación | Descripción | Impacto |
|---|---|---|
| DeepEncoder V2 | Un codificador visual que imita el orden de lectura humano en lugar de un escaneo fijo. | Mejor extracción estructurada y conciencia del diseño. |
| Flujo Causal Visual | Comprensión del contexto global antes de la decodificación secuencial. | Orden más preciso en la salida para tablas y texto de múltiples columnas. |
| Diseño de 3B parámetros | Compacto pero capaz de razonamiento avanzado. | Menor huella de recursos que muchas alternativas, manteniendo una precisión competitiva. |
| Procesamiento multimodal | Integración de visión + lenguaje para OCR e interpretación. | Permite texto, diseño y semántica a nivel de documento. |
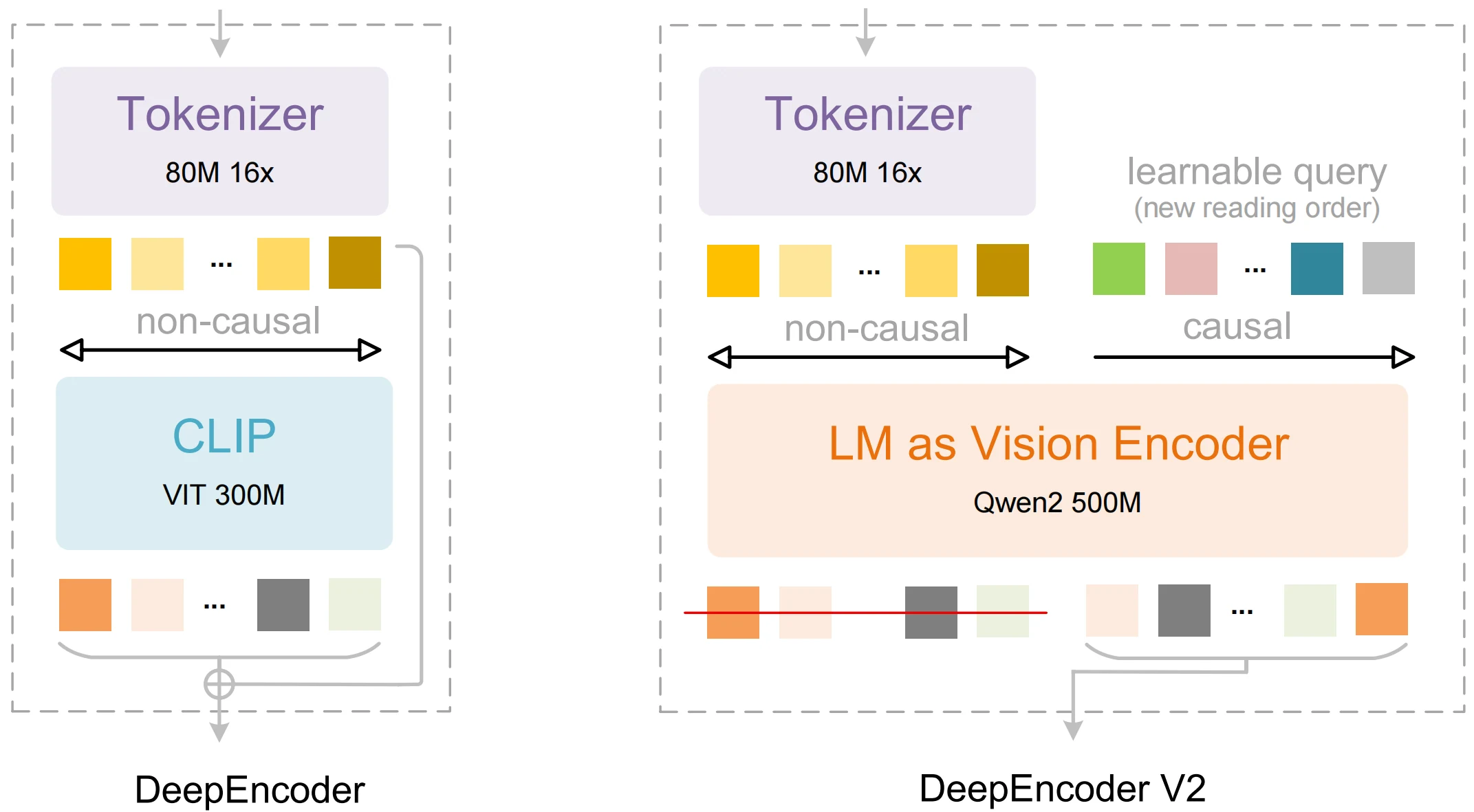
De github
Capacidad de DeepSeek OCR 2
Precisión
La precisión general de caracteres mejora del 82.7% al 91.1% (+8.4%), y la precisión de palabras del 75.0% al 85.9% (+10.9%).
En OmniDocBench v1.5, la puntuación general alcanza 91.09, mejorando en 3.73 puntos respecto a v1.0.
Orden de lectura
El reconocimiento del orden de lectura se vuelve más fiable, con una distancia de edición reducida de 0.085 a 0.057, lo que indica una reconstrucción más precisa de la lógica del documento.
Estabilidad en producción
Las mejoras se trasladan a despliegues reales:
- La tasa de duplicación de registros de usuarios en línea disminuye del 6.25% al 4.17%.
- La tasa de duplicación en el procesamiento de PDF disminuye del 3.69% al 2.88%.
Estos cambios reflejan menos errores de reconocimiento y diseño en producción.
Eficiencia
Las páginas complejas se procesan usando solo 256–1120 tokens visuales.
Mientras que v1.0 mantiene un 60% de precisión con compresión de hasta 20×, v2.0 va más allá: en OmniDocBench, supera a GOT-OCR 2.0 usando solo 100 tokens visuales frente a 256.
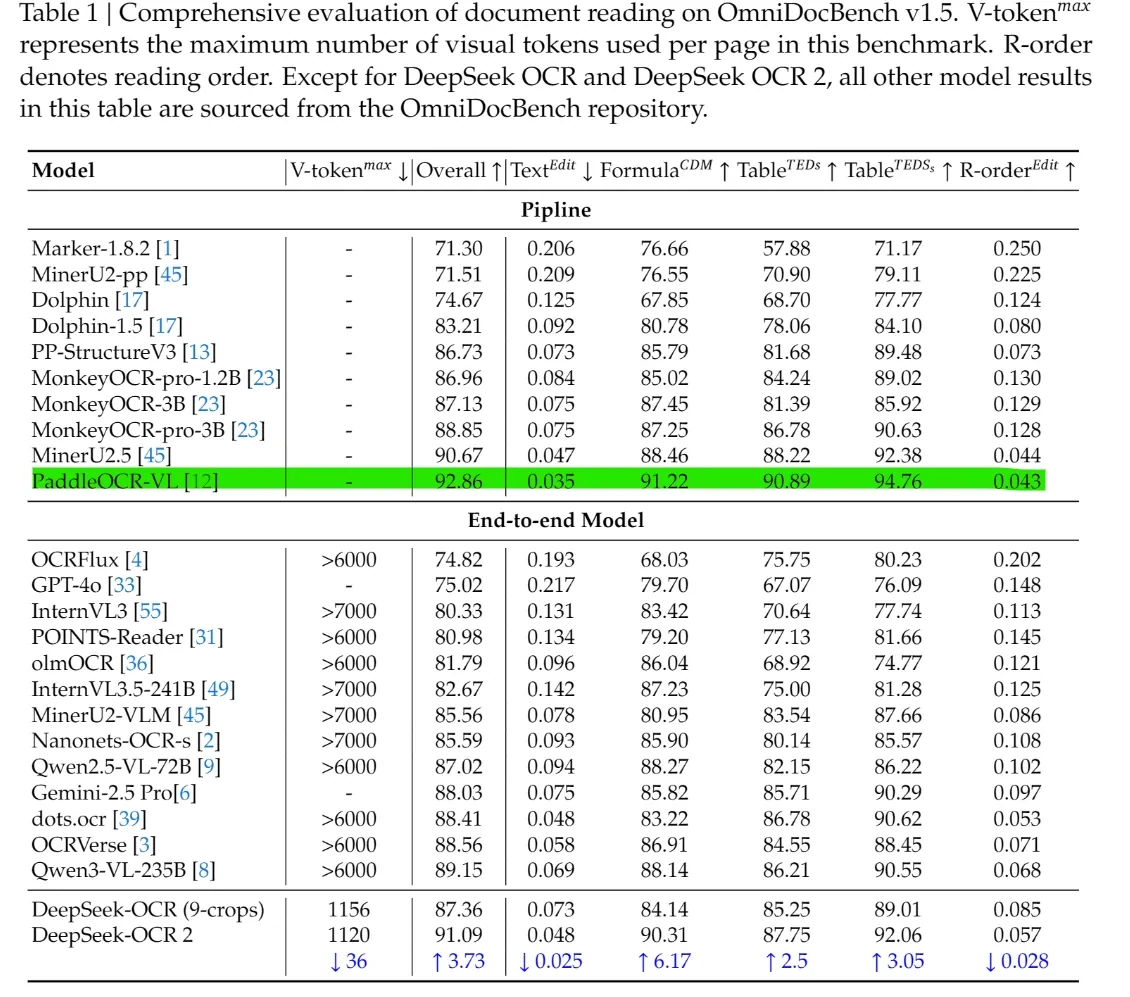
De Reddit
En OmniDocBench v1.5, DeepSeek-OCR 2 obtiene una puntuación general de 91.09, superando a la mayoría de los modelos extremo a extremo como GPT-4o, Gemini-2.5 Pro y Qwen-VL. También lidera en dimensiones estructurales, con valores más bajos de Text^Edit y R-order^Edit y puntuaciones más altas en Fórmula y Tabla, demostrando un modelado de diseño, tablas, fórmulas y orden de lectura más sólido que los VLM generales.
Crucialmente, estos resultados se obtienen con solo 1120 tokens visuales, mientras que la mayoría de los modelos competidores extremo a extremo requieren más de 6000. Esta brecha muestra que DeepSeek-OCR 2 ofrece una mayor precisión en la comprensión de documentos con un costo computacional drásticamente menor, combinando liderazgo en benchmarks con capacidad práctica de despliegue.
¿Cuándo elegir DeepSeek-OCR 2?
Más adecuado para aplicaciones que requieren comprensión a nivel de documento, extracción estructurada e integración con flujos de trabajo multimodales de IA.
Casos de uso ideales:
- Automatización de documentos legales y financieros con integridad de diseño.
- Ingesta de documentos de investigación y canalizaciones de marcado estructurado.
- Indexación de documentos empresariales con preservación del orden de lectura.
Limitaciones:
- Requiere recursos GPU para inferencia eficiente.
- La extracción de escritura a mano no es el enfoque principal (modelos dedicados pueden superarlo).
Cómo agregar OCR a tu flujo de agente con costos de API predecibles
Novita ofrece el precio bajo demanda más bajo para H100 a $1.80/hora, hasta un 30% más barato que otros proveedores con rendimiento GPU idéntico.
El modo Spot de Novita AI es una opción de alquiler de GPU optimizada en costo que aprovecha la capacidad GPU no utilizada o inactiva de la plataforma. A diferencia de las instancias bajo demanda, que reservan hardware dedicado para uso continuo garantizado, las instancias Spot son interrumpibles y se ofrecen a precios significativamente más bajos, típicamente 40–60% más baratas.
Este modelo de precios funciona porque Novita reasigna dinámicamente GPUs inactivas a usuarios a corto plazo en lugar de dejarlas sin usar. Al hacerlo, la plataforma mejora la eficiencia general de utilización de la infraestructura, mientras que los desarrolladores se benefician de costos computacionales mucho más bajos para cargas de trabajo flexibles.
Paso 1: Entrada a la consola
Inicia la interfaz GPU y selecciona Comenzar para acceder a la gestión de despliegue.
Paso 2: Selección del paquete
Localiza PaddleOCR-VL en el repositorio de plantillas e inicia la secuencia de instalación.
Paso 3: Configuración de infraestructura
Configura los parámetros computacionales, incluyendo asignación de memoria, requisitos de almacenamiento y configuración de red. Selecciona Desplegar para implementar.
Paso 4: Revisar y crear
Verifica los detalles de configuración y el resumen de costos. Cuando estés conforme, haz clic en Desplegar para iniciar el proceso de creación.
Paso 5: Esperar la creación
Después de iniciar el despliegue, el sistema te redirigirá automáticamente a la página de gestión de instancias. Tu instancia se creará en segundo plano.
Paso 6: Monitorear el progreso de descarga
Sigue el progreso de descarga de la imagen en tiempo real. El estado de tu instancia cambiará de Pulling a Running una vez que el despliegue esté completo. Puedes ver el progreso detallado haciendo clic en el icono de flecha junto al nombre de tu instancia.
Paso 7: Acceso al entorno
Inicia el espacio de desarrollo a través de la interfaz Conectar, luego inicializa Iniciar Terminal Web.
Con un orden de lectura similar al humano, fuerte precisión estructural y un uso ultrabajo de tokens visuales, DeepSeek-OCR 2 supera a los VLM generales manteniéndose desplegable. Combinado con infraestructura GPU rentable, permite OCR escalable y predecible dentro de tuberías de agentes reales.
¿Por qué los agentes necesitan DeepSeek-OCR 2 en lugar de OCR básico?
DeepSeek-OCR 2 proporciona modelado de diseño y orden de lectura, permitiendo que los agentes consuman tablas, PDFs y documentos de múltiples columnas como texto estructurado.
¿Qué precisión tiene DeepSeek-OCR 2 en escenarios de producción?
DeepSeek-OCR 2 eleva la precisión de caracteres al 91.1% y reduce errores de orden de lectura, reduciendo tasas de duplicación en sistemas en vivo.
¿Por qué DeepSeek-OCR 2 es más barato de ejecutar que los VLM generales?
DeepSeek-OCR 2 alcanza liderazgo en benchmarks usando solo 256–1120 tokens visuales, muy por debajo de los 6000+ tokens requeridos por muchos VLM.
Novita AI es una plataforma de nube de IA que ofrece a los desarrolladores una manera fácil de desplegar modelos de IA usando su API simple, al mismo tiempo que proporciona nube GPU asequible y fiable para construir y escalar.




{kind=link}