

Сегодня разработчики сталкиваются с трудностями при преобразовании сложных визуальных документов в надежные структурированные входные данные для агентов и рабочих процессов LLM. В этой статье объясняется, почему продвинутое OCR теперь является обязательным, как DeepSeek-OCR 2 решает проблемы с макетом и порядком чтения, а также как развернуть его в продакшене с предсказуемыми низкими затратами на API и GPU.
Почему современные модели срочно нуждаются в продвинутом OCR?
Оптическое распознавание символов (OCR) преобразует визуальный текст в машинно-кодированный текст и структурированные представления, обеспечивая поиск, индексацию, семантический разбор, редактирование и интеграцию с рабочими процессами, ориентированными на язык. Традиционное OCR было сосредоточено на извлечении текста на уровне отдельных символов, однако современные рабочие процессы на основе ИИ требуют более глубокого понимания документов, включая контекст макета и семантику для подачи в зрительно-языковые системы или RAG-генерации. OCR остается незаменимым для документов, форм, таблиц, счетов, научных работ и текста на изображениях — варианты использования, повсеместно распространенные в отрасли.

Попробуйте DeepSeek OCR 2 прямо сейчас!
Ключевые инновации в DeepSeek OCR 2
| Инновация | Описание | Влияние |
|---|---|---|
| DeepEncoder V2 | Визуальный энкодер, который имитирует порядок чтения человека вместо фиксированного сканирования. | Более качественное структурированное извлечение и осведомленность о макете. |
| Visual Causal Flow | Понимание глобального контекста перед последовательным декодированием. | Более точное упорядочивание в выводе для таблиц и многоколоночного текста. |
| 3 B параметра | Компактный дизайн, при этом способный к продвинутому рассуждению. | Меньший след в ресурсах по сравнению со многими альтернативами при сопоставимой точности. |
| Мультимодальная обработка | Интеграция зрительного и языкового модулей для OCR и интерпретации. | Обеспечивает работу с текстом, макетом и семантикой на уровне всего документа. |
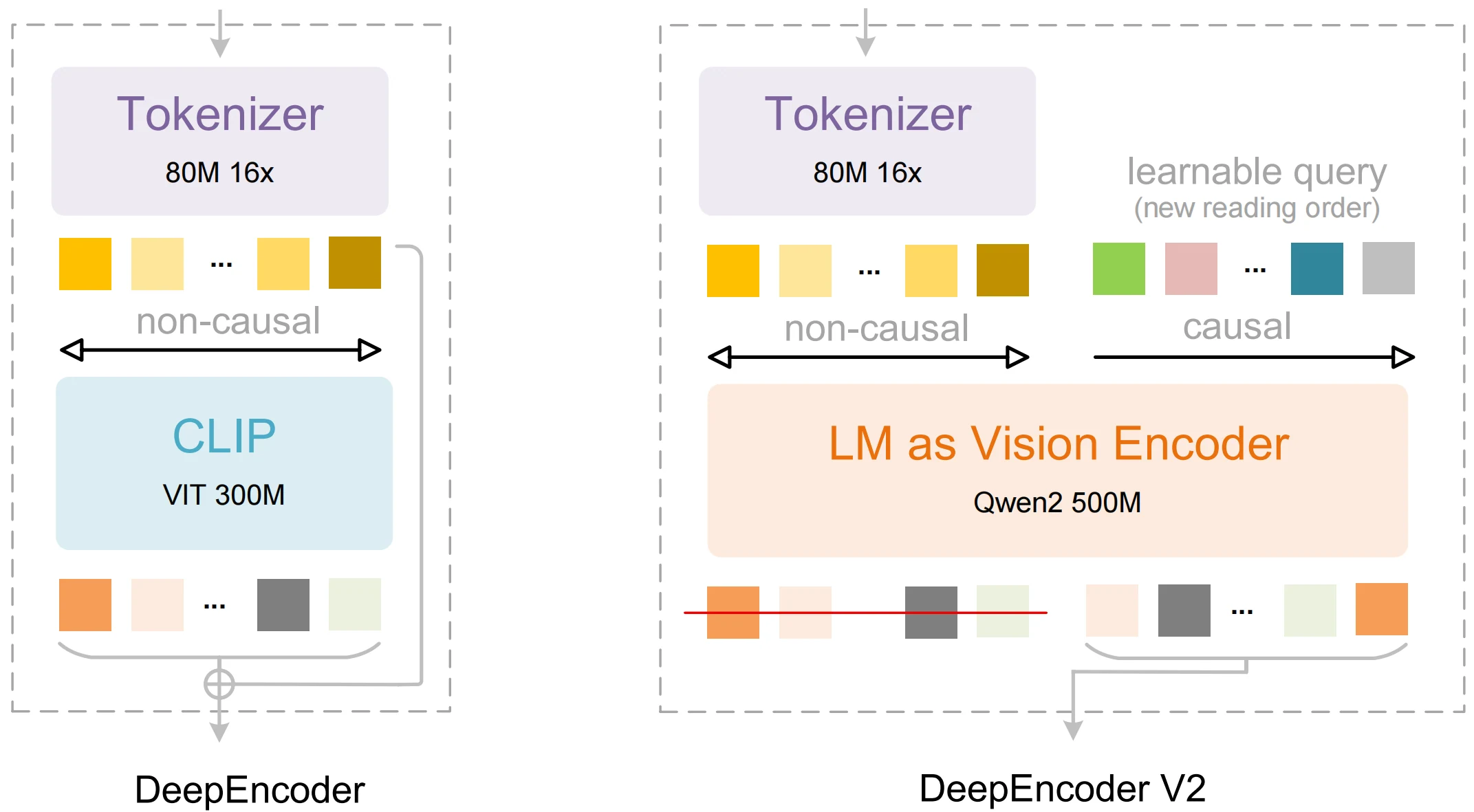
Из github
Попробуйте DeepSeek OCR 2 прямо сейчас!
Возможности DeepSeek OCR 2
Точность
Общая точность распознавания символов повышается с 82,7% до 91,1% (+8,4%), а точность распознавания слов — с 75,0% до 85,9% (+10,9%).
На тесте OmniDocBench v1.5 общий балл достигает 91,09, что на 3,73 балла выше, чем у версии v1.0.
Порядок чтения
Распознавание порядка чтения становится более надежным: расстояние редактирования снижается с 0,085 до 0,057, что указывает на более точное восстановление логики документа.
Стабильность в продакшене
Улучшения переносятся и на реальные развертывания:
- Доля дублирования записей онлайн-пользователей снижается с 6,25% до 4,17%.
- Доля дублирования при обработке PDF снижается с 3,69% до 2,88%.
Эти изменения отражают меньшее количество ошибок распознавания и разметки макета в продакшене.
Эффективность
Сложные страницы обрабатываются с использованием всего 256–1120 визуальных токенов.
Если версия v1.0 сохраняет 60% точности при сжатии до 20×, то v2.0 идет дальше: на тесте OmniDocBench она превосходит GOT-OCR 2.0, используя всего 100 визуальных токенов вместо 256.
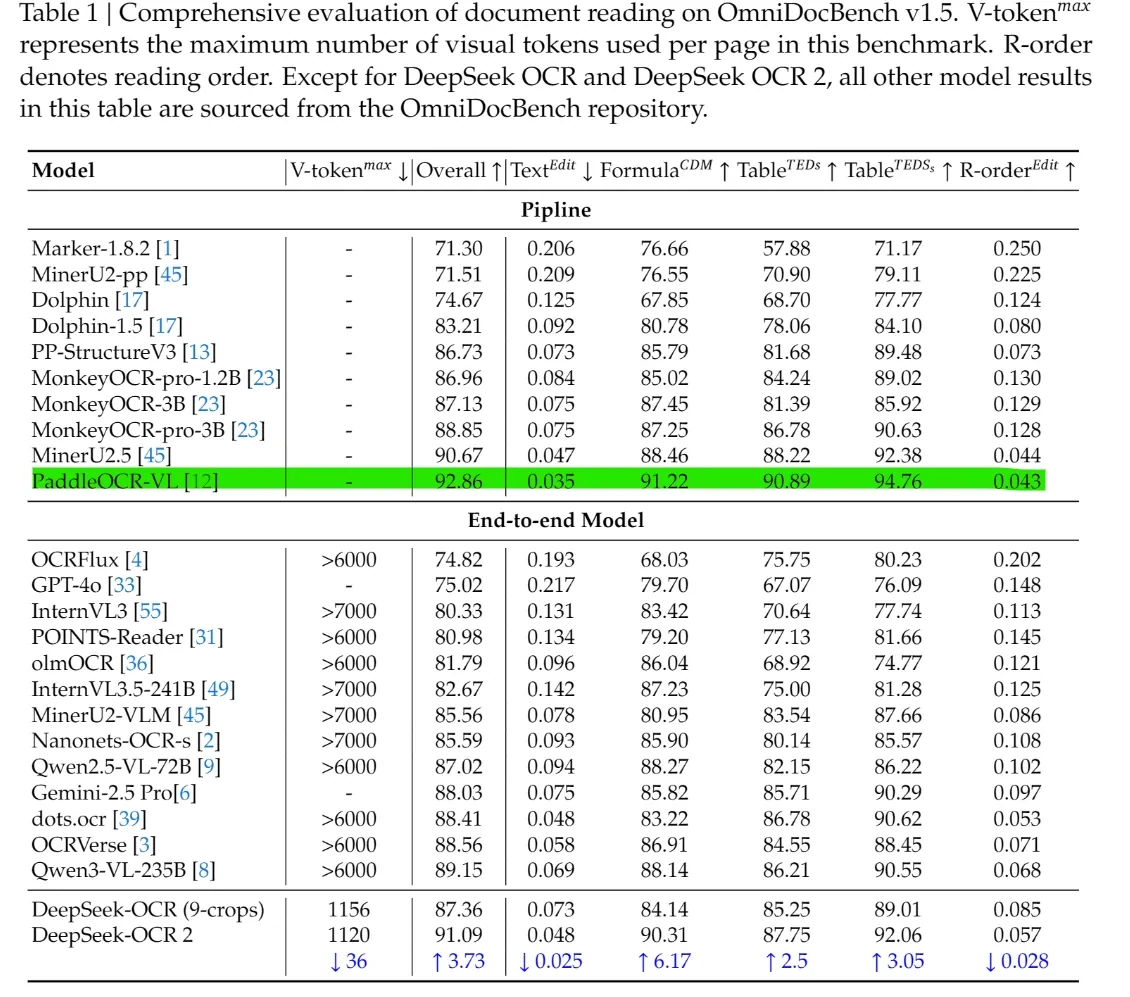
Из Reddit
На тесте OmniDocBench v1.5 DeepSeek-OCR 2 достигает общего балла 91,09, превосходя большинство сквозных моделей, таких как GPT-4o, Gemini-2.5 Pro и Qwen-VL. Он также лидирует по структурным показателям: имеет более низкие значения Text^Edit и R-order^Edit, а также более высокие баллы по формулам и таблицам, демонстрируя более сильное моделирование макета, таблиц, формул и порядка чтения по сравнению с общими VLM. Ключевое преимущество: эти результаты достигаются всего с 1120 визуальными токенами, тогда как большинство конкурирующих сквозных моделей требуют более 6000. Этот разрыв показывает, что DeepSeek-OCR 2 обеспечивает более высокую точность понимания документов при значительно более низких вычислительных затратах, сочетая лидерство в бенчмарках с практической возможностью развертывания.
Попробуйте DeepSeek OCR 2 прямо сейчас!
Когда выбирать DeepSeek-OCR 2?
Лучше всего подходит для приложений, требующих понимания документов на уровне всего документа, структурированного извлечения и интеграции рабочих процессов с мультимодальными системами ИИ.
Идеальные варианты использования:
- Автоматизация работы с юридическими и финансовыми документами с сохранением целостности макета.
- Загрузка и обработка научных публикаций и конвейеры структурированной разметки.
- Индексация корпоративных документов с сохранением порядка чтения.
Ограничения:
- Требует ресурсов GPU для эффективного инференса.
- Извлечение рукописного текста не является основной задачей (специализированные модели могут показать лучшие результаты).
Как добавить OCR в поток работы вашего агента с предсказуемыми затратами на API
Novita предлагает самые низкие цены на аренду H100 по запросу — $1,80 в час, что на до 30% дешевле, чем у других провайдеров с идентичной производительностью GPU.
Spot-режим Novita AI — это оптимизированный по стоимости вариант аренды GPU, который использует неиспользуемые или простаивающие ресурсы платформы. В отличие от инстансов по запросу, которые резервируют выделенное оборудование для гарантированной непрерывной работы, Spot-инстансы являются прерываемыми — предлагаются по значительно более низким ценам, обычно на 40–60% дешевле.
Эта модель ценообразования работает благодаря тому, что Novita динамически перераспределяет простаивающие GPU для краткосрочных пользователей вместо того, чтобы оставлять их неиспользованными. Благодаря этому платформа повышает общую эффективность использования инфраструктуры, а разработчики получают значительно более низкие вычислительные затраты для гибких рабочих нагрузок.
Попробуйте DeepSeek OCR 2 прямо сейчас!
Шаг 1: Вход в консоль
Запустите интерфейс GPU и выберите «Начать», чтобы получить доступ к управлению развертываниями.
Шаг 2: Выбор пакета
Найдите PaddleOCR-VL в репозитории шаблонов и начните последовательность установки.
Шаг 3: Настройка инфраструктуры
Настройте вычислительные параметры, включая распределение памяти, требования к хранилищу и сетевые настройки. Выберите «Развернуть» для запуска.
Шаг 4: Проверка и создание
Дважды проверьте детали конфигурации и сводку затрат. Если все удовлетворяет, нажмите «Развернуть», чтобы начать процесс создания.
Шаг 5: Ожидание создания
После запуска развертывания система автоматически перенаправит вас на страницу управления инстансами. Ваш инстанс будет создан в фоновом режиме.
Шаг 6: Отслеживание прогресса загрузки
Отслеживайте прогресс загрузки образа в реальном времени. Статус вашего инстанса изменится с «Загрузка образа» на «Работает» после завершения развертывания. Вы можете просмотреть детальный прогресс, нажав на стрелку рядом с именем вашего инстанса.
Шаг 7: Доступ к окружению
Запустите пространство разработки через интерфейс «Подключение», затем инициализируйте «Запустить веб-терминал».
С порядком чтения, похожим на человеческий, высокой точностью структурирования и ультра-низким использованием визуальных токенов DeepSeek-OCR 2 превосходит общие VLM, оставаясь при этом простым в развертывании. В паре с экономически эффективной GPU-инфраструктурой он обеспечивает масштабируемое, предсказуемое OCR внутри реальных конвейеров работы агентов.
Почему агентам нужен DeepSeek-OCR 2 вместо базового OCR?
DeepSeek-OCR 2 обеспечивает моделирование макета и порядка чтения, позволяя агентам потреблять таблицы, PDF-файлы и многоколоночные документы в виде структурированного текста.
Насколько точен DeepSeek-OCR 2 в производственных сценариях?
DeepSeek-OCR 2 повышает точность распознавания символов до 91,1% и снижает ошибки порядка чтения, что сокращает долю дублирования в рабочих системах.
Почему эксплуатация DeepSeek-OCR 2 дешевле, чем у общих VLM?
DeepSeek-OCR 2 достигает лидерства в бенчмарках, используя всего 256–1120 визуальных токенов, что значительно меньше 6000+ токенов, требуемых многими VLM.
Novita AI — это облачная платформа ИИ, которая предлагает разработчикам простой способ развертывания моделей ИИ с помощью нашего простого API, а также доступные и надежные GPU-облака для построения и масштабирования решений.




{kind=link}