

如今的开发者难以将复杂的视觉文档转换为供智能体和 LLM 工作流使用的可靠、结构化输入。本文将解释为何先进的 OCR 已成为必需,DeepSeek-OCR 2 如何解决布局与阅读顺序的失败问题,以及如何以可预测的低 API 和 GPU 成本将其部署到生产环境。
为什么现代模型迫切需要高级 OCR?
光学字符识别 (OCR) 将视觉文本转换为机器可读文本和结构化表示,支持搜索、索引、语义解析、编辑以及与以语言为中心的工作流集成。传统 OCR 侧重于字符级提取,但新兴 AI 工作流需要更丰富的文档理解,包括布局和语义上下文,以馈入视觉-语言系统或检索增强生成。OCR 对于文档、表单、表格、发票、研究论文和场景文本依然不可或缺——这些用例在行业中无处不在。

DeepSeek OCR 2 的核心创新
| 创新点 | 描述 | 影响 |
|---|---|---|
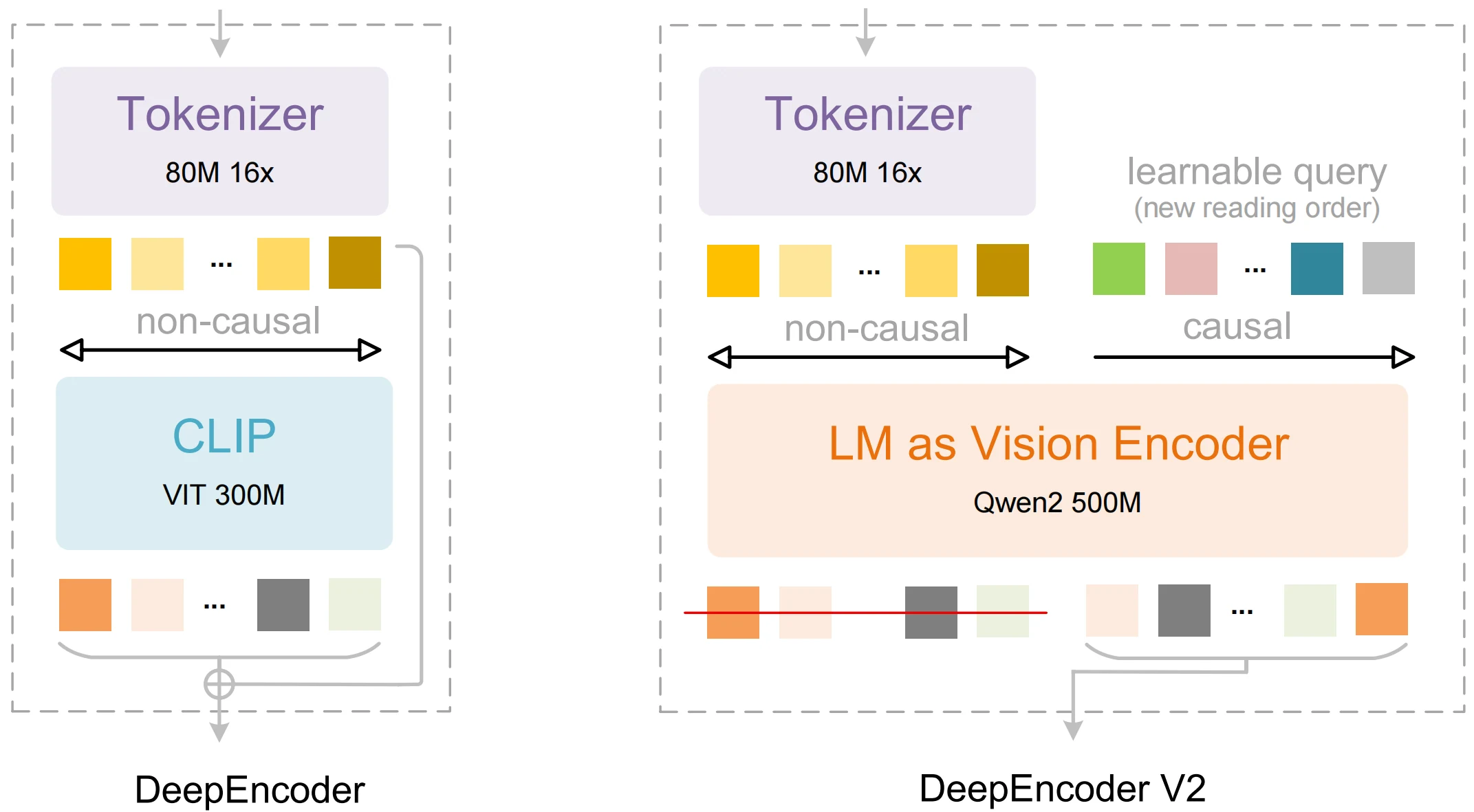
| DeepEncoder V2 | 一种模拟人类阅读顺序而非固定扫描的视觉编码器。 | 更优的结构化提取和布局感知。 |
| Visual Causal Flow | 在顺序解码之前先进行全局上下文理解。 | 输出中表格和多列文本的排序更准确。 |
| 3B 参数设计 | 紧凑但具备高级推理能力。 | 相比许多替代方案资源占用更低,同时精度具有竞争力。 |
| 多模态处理 | 视觉与语言集成,实现 OCR 与解释。 | 支持文本、布局和文档级语义。 |
来自 github
DeepSeek OCR 2 的能力
准确性
整体字符准确率从 82.7% 提升至 91.1%(+8.4%),词语准确率从 75.0% 提升至 85.9%(+10.9%)。
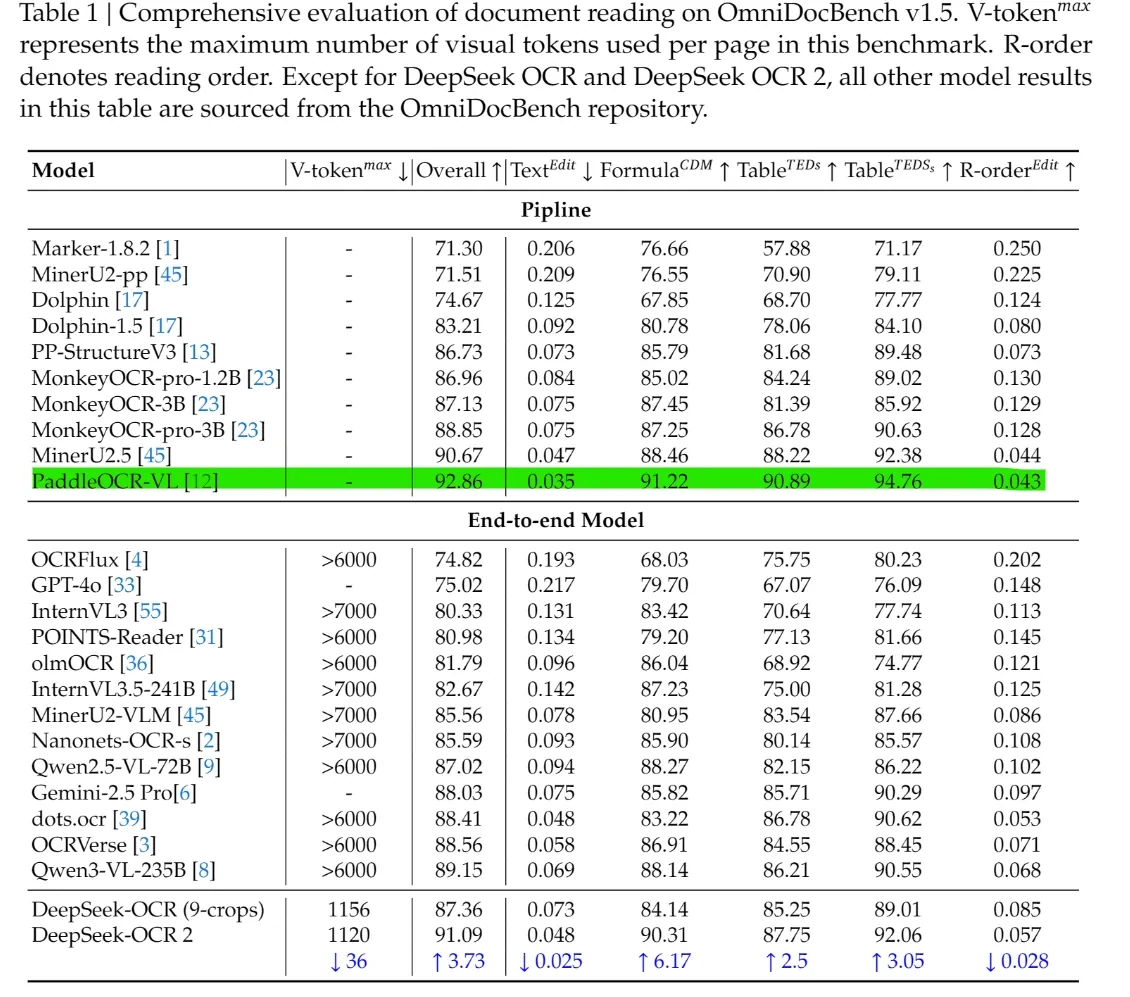
在 OmniDocBench v1.5 上,综合得分达到 91.09,比 v1.0 提高了 3.73 分。
阅读顺序
阅读顺序识别更加可靠,编辑距离从 0.085 降低到 0.057,表明文档逻辑重建更准确。
生产稳定性
改进同样体现在实际部署中:
- 在线用户日志重复率从 6.25% 降至 4.17%。
- PDF 处理重复率从 3.69% 降至 2.88%。
这些变化反映了生产中识别和布局错误的减少。
效率
复杂页面仅使用 256–1120 个视觉 token 即可处理。
v1.0 在高达 20 倍压缩下保持 60% 准确率,而 v2.0 更进一步:在 OmniDocBench 上,仅使用 100 个视觉 token 即超越了使用 256 个 token 的 GOT-OCR 2.0。
来自 Reddit
在 OmniDocBench v1.5 上,DeepSeek-OCR 2 的综合得分达到 91.09,超越了大多数端到端模型,如 GPT-4o、Gemini-2.5 Pro 和 Qwen-VL。在结构维度上也处于领先地位,具有更低的 Text^Edit 和 R-order^Edit 以及更高的 Formula 和 Table 分数,展示了比通用视觉语言模型更强的布局、表格、公式和阅读顺序建模能力。
关键在于,这些结果仅使用 1120 个视觉 token 获得,而大多数竞争的端到端模型需要超过 6000 个 token。这一差距表明,DeepSeek-OCR 2 在计算成本大幅降低的情况下实现了更高的文档理解准确率,兼顾了基准领先地位与实际可部署性。
何时选择 DeepSeek-OCR 2?
最适合需要文档级理解、结构化提取以及与多模态 AI 系统工作流集成的应用场景。
理想用例:
- 需要布局完整性的法律和金融文档自动化。
- 研究论文摄入与结构化标记管线。
- 需要保留阅读顺序的企业文档索引。
局限性:
- 需要 GPU 资源才能高效推理。
- 手写提取并非主要关注点(专用模型可能表现更佳)。
如何以可预测的 API 成本将 OCR 添加到您的智能体流中
Novita 提供市场上最低的按需 H100 定价,仅 $1.80/小时,比同等 GPU 性能的其他提供商便宜高达 30%。
Novita AI 的 Spot 模式 是一种成本优化的 GPU 租赁选项,利用平台未使用或空闲的 GPU 容量。与按需实例(预留专用硬件以保证持续使用)不同,Spot 实例是可中断的——价格显著降低,通常便宜 40–60%。
这种定价模式之所以有效,是因为 Novita 动态地将空闲 GPU 重新分配给短期用户,而不是闲置不用。通过这种方式,平台提高了整体基础设施利用效率,同时开发者从更低的计算成本中获益,适用于灵活的工作负载。
步骤 1:进入控制台
启动 GPU 界面并选择“开始使用”以访问部署管理。
步骤 2:选择模板包
在模板仓库中找到 PaddleOCR-VL,开始安装序列。
步骤 3:基础设施设置
配置计算参数,包括内存分配、存储需求和网络设置。选择“部署”进行实施。
步骤 4:审查并创建
再次检查您的配置详情和成本摘要。确认无误后,单击“部署”开始创建过程。
步骤 5:等待创建
启动部署后,系统会自动将您重定向到实例管理页面。您的实例将在后台创建。
步骤 6:监控下载进度
实时跟踪镜像下载进度。部署完成后,您的实例状态将从“拉取中”变为“运行中”。您可以通过单击实例名称旁边的箭头图标查看详细进度。
步骤 7:环境访问
通过“连接”界面启动开发空间,然后初始化“启动 Web 终端”。
凭借类人阅读顺序、强大的结构准确性以及极低的视觉 token 使用量,DeepSeek-OCR 2 超越了通用视觉语言模型,同时保持可部署性。结合成本高效的 GPU 基础设施,它能够在真实的智能体管线中实现可扩展、可预测的 OCR。
为什么智能体需要 DeepSeek-OCR 2 而非基础 OCR?
DeepSeek-OCR 2 提供布局和阅读顺序建模,让智能体能够将表格、PDF 和多列文档作为结构化文本使用。
DeepSeek-OCR 2 在生产场景中的准确率如何?
DeepSeek-OCR 2 将字符准确率提升至 91.1%,并减少了阅读顺序错误,降低了实时系统中的重复率。
为什么 DeepSeek-OCR 2 的运行成本比通用视觉语言模型更低?
DeepSeek-OCR 2 仅使用 256–1120 个视觉 token 即达到基准领先地位,远低于许多视觉语言模型所需的 6000+ token。
Novita AI 是一个 AI 云平台,为开发者提供通过简单 API 轻松部署 AI 模型的方式,同时还提供经济实惠且可靠的 GPU 云用于构建和扩展。




{kind=link}