

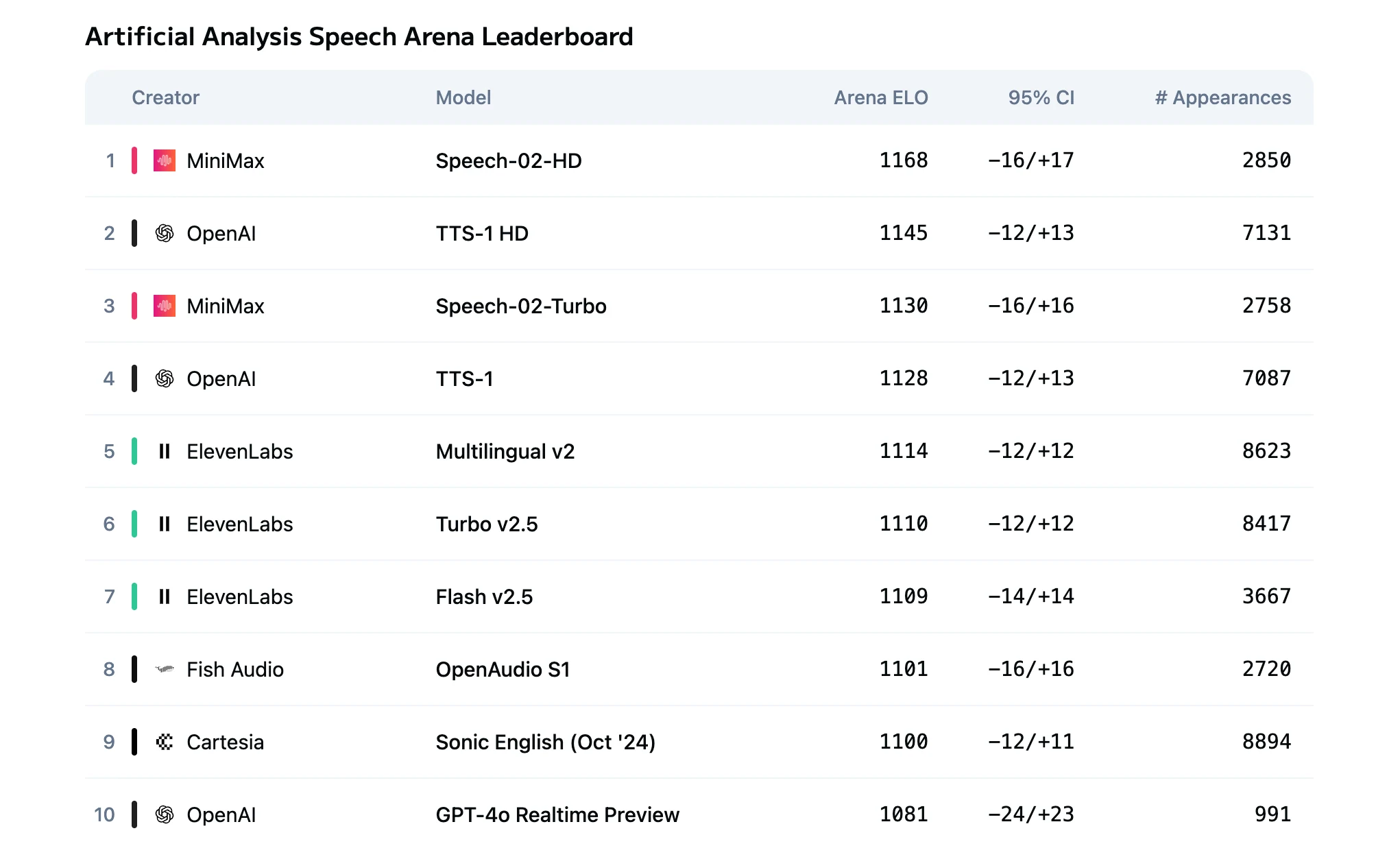
- Modellvergleich von Speech 2.5 Turbo und HD
- Kann Speech 2.5 eine beliebige Stimme mit nur wenigen Sekunden Audio nachbilden?
- Bietet Speech 2.5 eine muttersprachliche Aussprache in über 40 Sprachen?
- Wie gut verarbeitet Speech 2.5 lange Dokumente oder Bücher?
- Wie hoch sind die Kosten pro 1.000 Zeichen für Speech 2.5
- Wie feingranular ist die Kontrolle über Aussprache, Betonung und Pausen?
- Unterstützt MiniMax Speech 2.5 Streaming?
- Wie nutzen Sie MiniMax Speech 2.5 zu einem guten Preis?
Entwickler, die Sprachanwendungen erstellen, haben oft mit langsamen Antwortzeiten, inkonsistenter Audioqualität über Sprachen hinweg, hohen API-Kosten und eingeschränkter Kontrolle über emotionalen Ton oder Aussprache zu kämpfen – Probleme, die die zuverlässige Bereitstellung von Echtzeit-Interaktionen und groß angelegter Generierung erschweren.
MiniMax Speech 2.5 wurde entwickelt, um diese Einschränkungen direkt zu beheben. Es bietet hochgenaue Stimmklonierung aus nur 6–10 Sekunden Audio, mehrsprachige Synthese in über 40 Sprachen mit einer Wortfehlerrate (WER) von ca. 2 % für Chinesisch und Englisch sowie eine Turbo-Modus-Latenz von nahezu 250 ms für interaktive Anwendungen. Langform-Workloads werden durch asynchrone Verarbeitung von bis zu 200.000 Zeichen unterstützt, während die Preisgestaltung mit 0,04 $ pro 1.000 Zeichen entwicklerfreundlich bleibt. Mit feingranularer emotionaler Kontrolle und stabiler Leistung bei einem Signal-Rausch-Verhältnis (SNR) ≥ 3 dB bietet das Modell eine praktische Lösung für Teams, die sowohl Echtzeit-Reaktionsfähigkeit als auch skalierbare, kosteneffiziente Sprachgenerierung benötigen.
Modellvergleich von Speech 2.5 Turbo und HD
Der grundlegende Unterschied zwischen Speech 2.5 HD und Turbo Preview liegt in der Qualitäts-Latenz-Abwägung:
| Metric | HD | Turbo |
|---|---|---|
| Audioqualität | Studioqualität mit höchster Treue | High-Definition-Qualität mit etwas weniger Ausdrucksstärke |
| TTS-Latenz | Mehrere Sekunden | End-to-End-Latenz unter 250 ms |
| Ideales Einsatzszenario | Hochwertige Content-Erstellung | Echtzeit-interaktive Anwendungen |
| Kosten | 80 $ pro Mio. Zeichen | 48 $ pro Mio. Zeichen |
HD bietet überlegene Klangfarben-Ähnlichkeit, emotionale Nuancen und natürliche Prosodie.
Turbo optimiert die Encoding-Pipeline, um extrem niedrige Latenzzeiten für Echtzeit-Interaktionen zu erreichen.
Kann Speech 2.5 eine beliebige Stimme mit nur wenigen Sekunden Audio nachbilden?
Der Flow-VAE-Decoder von MiniMax Speech 2.5 kombiniert Flow Matching und Variational Autoencoding, um Sprache in einem erlernten latenten Raum zu modellieren, anstatt sich ausschließlich auf Mel-Spektrogramme zu stützen. Dadurch werden Tonhöhe, Rhythmus, Akzent und emotionale Färbung erfasst.
Erforderliche Sample-Länge: Nur 6–10 Sekunden für hochwertige Stimmklonierung, mit einer Ähnlichkeit von bis zu 99 %.
Ähnlichkeitsmetriken: Übertrifft ElevenLabs bei der Sprecherähnlichkeit in 24 Sprachen.
Zero-Shot-Stimmklonierung: Kein Transkript erforderlich; ein gelernter Sprecher-Embedding-Encoder extrahiert die Stimmidentität direkt
Probieren Sie MiniMax Speech 2.5 jetzt aus!
Bietet Speech 2.5 eine muttersprachliche Aussprache in über 40 Sprachen?
Mehrsprachige Fähigkeiten:
- Unterstützt über 40 Sprachen
- Chinesisch: Globale Benchmark-Leistung
- Englisch: Deutliches Upgrade gegenüber Speech 0.2 mit reduzierten mechanischen Artefakten
- Weitere Sprachen: Japanisch, Französisch, Spanisch usw. mit natürlicher muttersprachlicher Aussprache
Mechanismen:
- Verbesserte Extraktion von Sprechermerkmalen
- Sprachübergreifende Transfer-Schichten, die die Klangfarbe beibehalten
- End-to-End-Training zur Beibehaltung der Stimmidentität über Sprachen hinweg
Qualitätsmetrik:
Die von MiniMax synthetisierte englische und chinesische Sprache hat eine WER von ca. 2 %, was bedeutet, dass die gesprochenen Wörter von einem ASR (Automatische Spracherkennung) fast perfekt verstanden werden.
Wie gut verarbeitet Speech 2.5 lange Dokumente oder Bücher?
Latenz und Durchsatz bei Langform-Inhalten (Speech 2.5)
MiniMax Speech 2.5 bietet eine stabile Leistung bei langen Eingaben mit quantifizierbaren Latenz- und Durchsatzvorteilen:
• TTS-Latenz:
Die Audio-Wiedergabe beginnt typischerweise innerhalb weniger Sekunden, selbst bei mehrparagraphten Texten. Die aktualisierte 2.5-Audio-Pipeline minimiert die Startverzögerung. Spätere Systeme erreichen eine End-to-End-Latenz von 250 ms in Agent-Umgebungen; Speech 2.5 liegt bei Standard-Syntheseanfragen im Bereich weniger Sekunden.
• Langtext-Kapazität:
Unterstützt bis zu 10.000 Zeichen pro Anfrage über die asynchrone TTS-API. Download-URLs bleiben 9 Stunden lang gültig, sodass ein zuverlässiger Abruf gewährleistet ist.
- Turbo-Modus: Niedrigere Latenz und höherer Durchsatz (mit moderaten Einbußen bei der Treue).
- HD-Modus: Maximale Audioqualität.
Der Durchsatz kann weiter durch Batch-Einreichung oder asynchrone Aufträge erhöht werden, was sich für Workloads wie stündliche Transkription oder Syntheseaufgaben eignet.
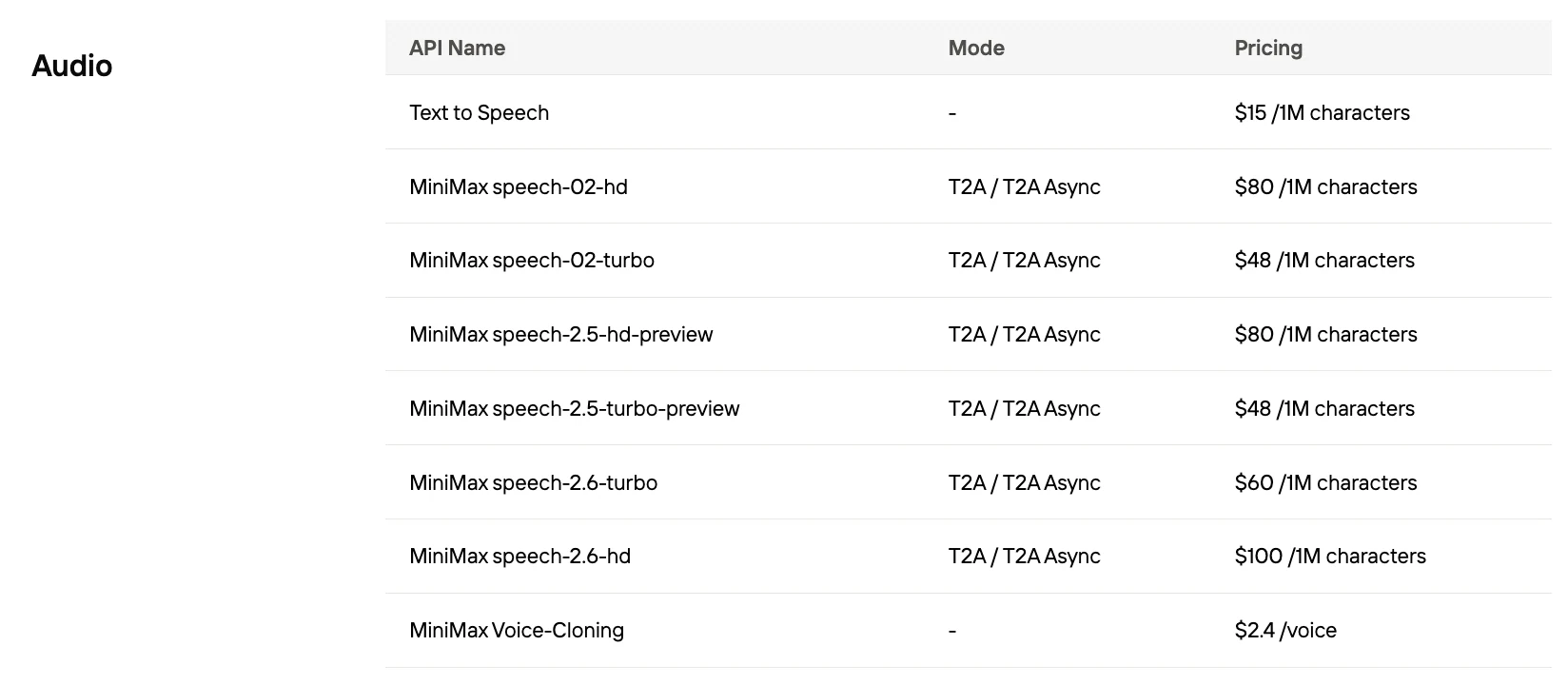
Wie hoch sind die Kosten pro 1.000 Zeichen für Speech 2.5
| Anbieter | Kosten / 1K Zeichen |
|---|---|
| MiniMax Speech 2.5 Turbo | 0,048 $ |
| MiniMax Speech 2.5 HD | 0,08 $ |
| ElevenLabs | 0,24–0,30 $ |
| OpenAI GPT-4 Audio | Typisch >0,10 $ |
| Google Gemini | TTS >2,50 $ pro 1M Token |
Novita AI bietet den besten Preis für MiniMax Speech!
Probieren Sie MiniMax Speech 2.5 jetzt aus!
Wie feingranular ist die Kontrolle über Aussprache, Betonung und Pausen?
| Steuerungsmöglichkeit | API-Feld | Beispielwert / Verwendung |
|---|---|---|
| Benutzerdefinierte Pausen | text mit <#x#> |
Hello<#0.50#>world |
| Phonem-basierte Aussprache (IPA / X-SAMPA) | pronunciation_dict |
"demo": {"type":"ipa","value":"ˈdɛmoʊ"} |
| Chinesische Tonersetzung | pronunciation_dict (type: "tone") |
"你好": {"type":"tone","value":"ni3 hao3"} |
| Sprechgeschwindigkeit | voice_setting.speed |
1.05 |
| Lautstärke | voice_setting.vol |
1.2 |
| Tonhöhe (Halbtonverschiebung) | voice_setting.pitch |
2 |
| Stimmauswahl (Klangfarben-ID) | voice_setting.voice_id |
"Calm_Woman" |
| Emotion | voice_setting.emotion |
"neutral" |
| Englische Textnormalisierung | voice_setting.text_normalization |
true |
| Abtastrate | audio_setting.sample_rate |
44100 |
| Bitrate | audio_setting.bitrate |
128000 |
| Audioformat | audio_setting.format |
"mp3" |
| Kanäle | audio_setting.channel |
1 (Mono) |
| Klangfarben-Mischung (bis zu 4 Stimmen) | timbre_weights |
[{"voice_id":"Calm_Woman","weight":70}] |
| Audio-Effekte (Hall, Telefon, Roboter usw.) | voice_modify.sound_effects |
"spacious_echo" |
| Helligkeits-Tonhöhenanpassung | voice_modify.pitch |
10 |
| Intensitätsanpassung | voice_modify.intensity |
-20 |
| Klangfarben-Schärfe/-Magnetismus | voice_modify.timbre |
-15 |
| Streaming-Modus | stream |
false |
| Sprach-/Dialekt-Boost | language_boost |
"English" |
import requests
url = "https://api.novita.ai/v3/minimax-speech-2.5-hd-preview"
payload = {
"text": "Hello<#0.50#>this is a demo of fine-grained control.<#0.30#>\
Please read the number 2025 clearly.",
"voice_setting": {
"speed": 1.05,
"vol": 1.2,
"pitch": 2,
"voice_id": "Calm_Woman",
"emotion": "neutral",
"text_normalization": True
},
"audio_setting": {
"sample_rate": 44100,
"bitrate": 128000,
"format": "mp3",
"channel": 1
},
# Use the concrete pronunciation dictionary from your example
"pronunciation_dict": {
"demo": {
"type": "ipa",
"value": "ˈdɛmoʊ"
},
"2025": {
"type": "ipa",
"value": "tuː θaʊzənd twɛnti faɪv"
},
"你好": {
"type": "tone",
"value": "ni3 hao3"
}
},
"timbre_weights": [
{
"voice_id": "Calm_Woman",
"weight": 70
},
{
"voice_id": "Friendly_Person",
"weight": 30
}
],
"stream": False,
"language_boost": "English",
"output_format": "url",
"voice_modify": {
"pitch": 10,
"intensity": -20,
"timbre": -15,
"sound_effects": "spacious_echo"
}
}
headers = {
"Content-Type": "application/json",
"Authorization": "Bearer YOUR_API_KEY_HERE"
}
response = requests.post(url, json=payload, headers=headers)
print(response.text)
Probieren Sie MiniMax Speech 2.5 jetzt aus!
Unterstützt MiniMax Speech 2.5 Streaming?
Ja. MiniMax Speech 2.5 unterstützt Streaming sowohl für die Spracherkennung (ASR) als auch für die Text-zu-Sprache-Synthese (TTS). Die API enthält explizit das Feld:
"stream": true
in einer TTS-Anfrage beginnt das System sofort mit der Audio-Generierung und sendet diese in Segmenten zurück. Dadurch kann die Wiedergabe starten, bevor der gesamte Satz synthetisiert wurde. Die typische TTS-Startlatenz liegt innerhalb weniger Sekunden, und optimierte Szenarien können sub-sekündliche End-to-End-Antwortzeiten erreichen.
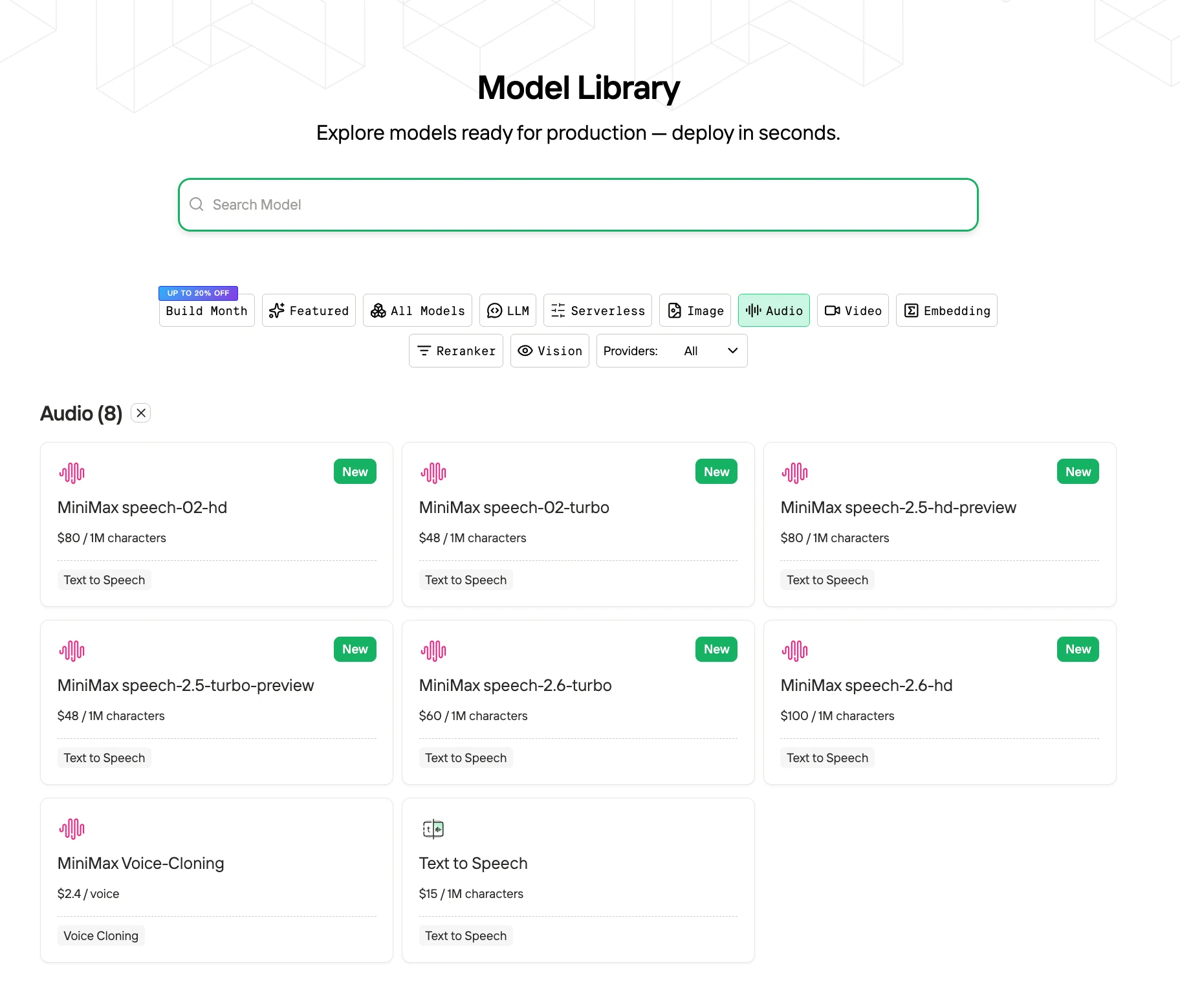
Wie nutzen Sie MiniMax Speech 2.5 zu einem guten Preis?
Schritt 1: Einloggen und Zugriff auf die Modellbibliothek
Loggen Sie sich in Ihrem Konto ein und klicken Sie auf die Schaltfläche Modellbibliothek.

Schritt 2: Wählen Sie Ihr Modell
Durchstöbern Sie die verfügbaren Optionen und wählen Sie das Modell, das Ihren Anforderungen entspricht.
Probieren Sie MiniMax Speech 2.5 jetzt aus!
Schritt 3: Starten Sie Ihre kostenlose Testversion
Starten Sie Ihre kostenlose Testversion, um die Funktionen des ausgewählten Modells kennenzulernen.
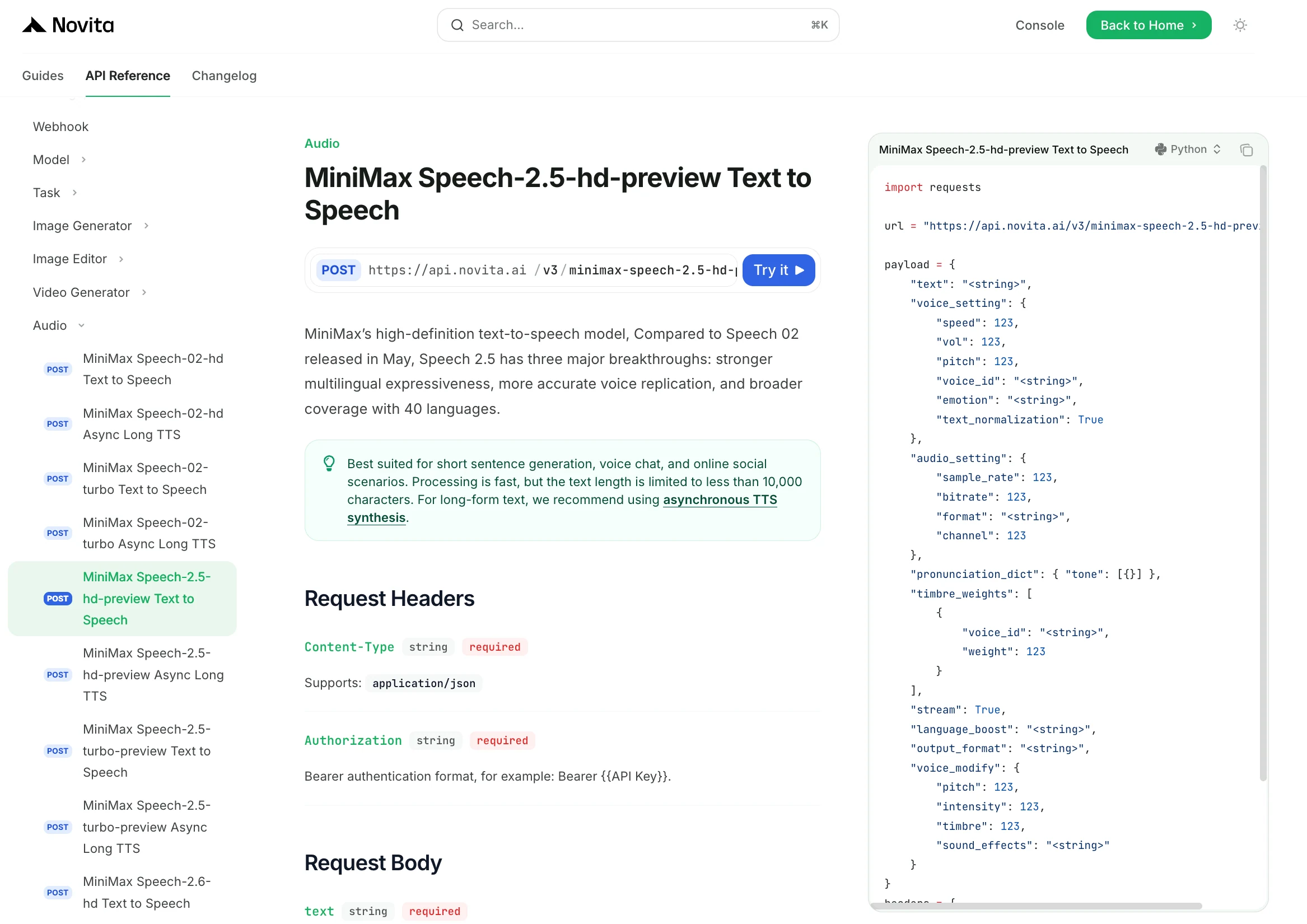
Schritt 4: Holen Sie sich Ihren API-Schlüssel
Zur Authentifizierung gegenüber der API stellen wir Ihnen einen neuen API-Schlüssel zur Verfügung. Auf der Seite „Einstellungen“ können Sie den API-Schlüssel wie in der Abbildung gezeigt kopieren.

MiniMax Speech 2.5 bietet eine ausgewogene, entwicklerbereite Lösung für die zentralen Probleme der modernen Sprachanwendungsentwicklung. Es kombiniert schnelle Antwortzeiten, hohe mehrsprachige Genauigkeit und zuverlässige Langtextverarbeitung mit kosteneffizienter Preisgestaltung und detaillierter Kontrolle über emotionalen Ton, Aussprache und Klangfarbe. Mit den für unterschiedliche Latenz-Qualitäts-Anforderungen optimierten Modi Turbo und HD sowie vollständiger Streaming-Unterstützung ermöglicht MiniMax Speech 2.5 Teams die Entwicklung skalierbarer Sprachagenten, Echtzeit-Transkriptionssysteme und hochwertiger Inhalts-Pipelines mit deutlich weniger technischen Einschränkungen. Die Leistung, Flexibilität und API-Design des Modells machen es zu einer praktischen Wahl für Entwickler, die sowohl Effizienz als auch ausdrucksstarke Sprachgenerierung suchen.
Häufig gestellte Fragen
Unterstützt MiniMax Speech 2.5 Streaming?
Ja. MiniMax Speech 2.5 unterstützt Streaming sowohl für ASR als auch für TTS. Durch Aktivieren von "stream": true kann das System inkrementelle Transkripte oder Audio-Chunks in Echtzeit senden, was sub-sekündliche Antwortzeiten und natürliche Konversations-Timing ermöglicht.
Wie genau ist die Stimmklonierung bei MiniMax Speech 2.5?
MiniMax Speech 2.5 erreicht hochwertige Stimmklonierung mit nur 6–10 Sekunden Audio, einer Ähnlichkeit von bis zu 99 % und übertrifft mehrere kommerzielle Alternativen in mehrsprachigen Sprecherähnlichkeits-Benchmarks.
Verarbeitet MiniMax Speech 2.5 mehrsprachige Sprache gut?
Ja. MiniMax Speech 2.5 unterstützt über 40 Sprachen und erreicht eine WER von ca. 2 % für Chinesisch und Englisch. Es behält die Stimmidentität über Sprachen hinweg durch sprachübergreifende Transfer-Schichten und End-to-End-Training bei.
Novita AI ist die All-in-One-Cloud-Plattform, die Ihre KI-Ambitionen verwirklicht. Integrierte APIs, Serverless, GPU-Instanzen – die kosteneffizienten Tools, die Sie brauchen. Eliminieren Sie Infrastruktur, starten Sie kostenlos und machen Sie Ihre KI-Vision zur Realität.



