

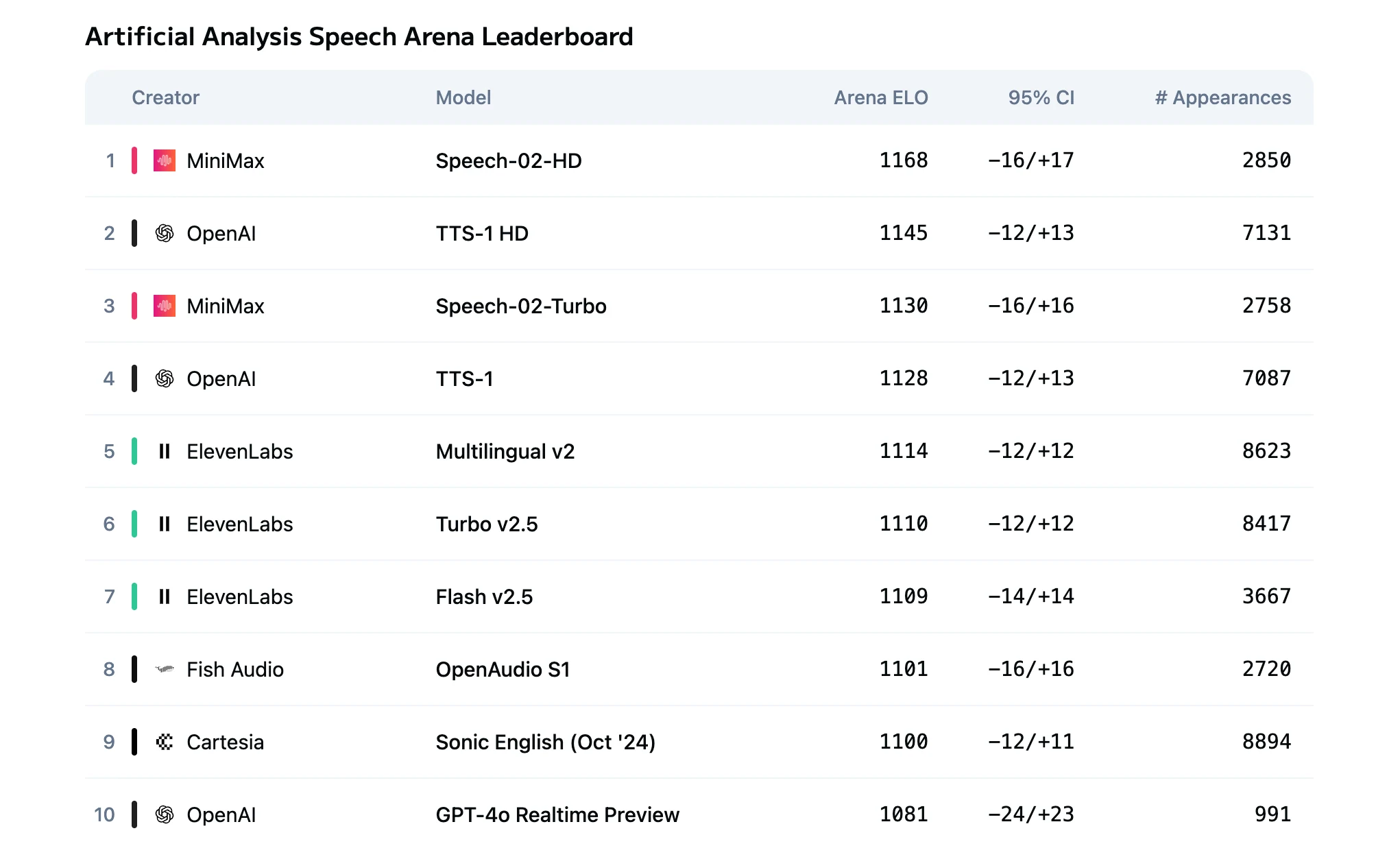
- مقارنة بين نموذجي Speech 2.5 Turbo و HD
- هل يمكن لـ Speech 2.5 استنساخ أي صوت عشوائي باستخدام بضع ثوانٍ فقط من الصوت؟
- هل يقدم Speech 2.5 نطقاً على مستوى اللغة الأصلية عبر أكثر من 40 لغة؟
- كيف يتعامل Speech 2.5 مع المستندات أو الكتب الطويلة؟
- ما هي تكلفة كل 1000 حرف من Speech 2.5؟
- ما مدى دقة التحكم في النطق، والتأكيد، والوقفات؟
- هل يدعم MiniMax Speech 2.5 البث المباشر (Streaming)؟
- كيف تستخدم MiniMax Speech 2.5 بسعر جيد؟
يواجه المطورون الذين يبنون تطبيقات صوتية صعوبات شائعة تتمثل في أوقات استجابة بطيئة، جودة صوت غير متسقة عبر اللغات، تكاليف API مرتفعة، وتحكم محدود في النبرة العاطفية أو النطق—وهي مشاكل تجعل التفاعل في الوقت الفعلي والتوليد على نطاق واسع صعب التقديم بشكل موثوق.
تم تصميم MiniMax Speech 2.5 لمعالجة هذه القيود مباشرة. فهو يقدم استنساخ صوت عالي الدقة من 6 إلى 10 ثوانٍ فقط من الصوت، وتوليد صوت متعدد اللغات عبر أكثر من 40 لغة مع معدل خطأ في الكلمات (WER) يبلغ حوالي 2% للغتين الصينية والإنجليزية، وزمن استجابة لوضع Turbo يبلغ حوالي 250 مللي ثانية للاستخدام التفاعلي. كما يتم دعم أحمال العمل الطويلة من خلال المعالجة غير المتزامنة لما يصل إلى 200,000 حرف، بينما تظل الأسعار مناسبة للمطورين عند 0.04 دولار لكل 1000 حرف. وبفضل التحكم الدقيق في النبرة العاطفية والأداء المستقر عند نسبة إشارة إلى ضجيج (SNR) تبلغ 3 ديسيبل على الأقل، يوفر النموذج حلاً عملياً للفرق التي تحتاج إلى كل من الاستجابة في الوقت الفعلي والتوليد الصوتي القابل للتطوير وفعال من حيث التكلفة.
مقارنة بين نموذجي Speech 2.5 Turbo و HD
الفرق الجوهري بين Speech 2.5 HD و Turbo Preview يكمن في الموازنة بين الجودة وزمن الاستجابة:
| المقياس | HD | Turbo |
|---|---|---|
| جودة الصوت | واقعية بدرجة استوديو مع أعلى دقة | جودة عالية الدقة مع تعبير أقل قليلاً |
| زمن استجابة تحويل النص إلى كلام (TTS) | عدة ثوانٍ | زمن استجابة من البداية إلى النهاية أقل من 250 مللي ثانية |
| السيناريو المثالي | توليد محتوى عالي الجودة | تطبيقات تفاعلية في الوقت الفعلي |
| التكلفة | 80 دولار لكل مليون حرف | 48 دولار لكل مليون حرف |
يوفر HD تشابهاً أعلى في النبرة الصوتية، واختلافات دقيقة في النبرة العاطفية، وإيقاع طبيعي.
يقوم Turbo بتحسين مسار التشفير لتحقيق زمن استجابة منخفض للغاية مناسب للتفاعل في الوقت الفعلي.
هل يمكن لـ Speech 2.5 استنساخ أي صوت عشوائي باستخدام بضع ثوانٍ فقط من الصوت؟
يعتمد مفكك Flow-VAE الخاص بـ MiniMax Speech 2.5 على دمج مطابقة التدفق (Flow Matching) والتشفير التلقائي الاختلافي (Variational Autoencoding) لنمذجة الكلام في فضاء كامن متعلم بدلاً من الاعتماد فقط على مطياف الميل. هذا يلتقط طبقة الصوت، والإيقاع، واللكنة، واللون العاطفي.
الطول المطلوب للعينة: 6 إلى 10 ثوانٍ فقط لاستنساخ عالي الدقة، مع تحقيق تشابه يصل إلى 99%.
مقاييس التشابه: يتفوق على ElevenLabs في تشابه المتحدث عبر 24 لغة.
الاستنساخ بدون عينات مسبقة (Zero-shot): لا يلزم وجود نص مكتوب؛ يقوم مرمز تضمين المتحدث المتعلم باستخراج الهوية الصوتية مباشرة
هل يقدم Speech 2.5 نطقاً على مستوى اللغة الأصلية عبر أكثر من 40 لغة؟
القدرات متعددة اللغات:
- يدعم أكثر من 40 لغة
- الصينية: أداء معياري عالمي
- الإنجليزية: ترقية كبيرة مقارنة بـ Speech 0.2 مع تقليل العيوب الميكانيكية
- اللغات الأخرى: اليابانية، الفرنسية، الإسبانية، إلخ مع نطق أصلي طبيعي
الآليات:
- استخراج محسّن لخصائص المتحدث
- طبقات نقل بين اللغات تحتفظ بالنبرة الصوتية
- تدريب من البداية إلى النهاية للحفاظ على الهوية الصوتية عبر اللغات
مقياس الجودة:
يبلغ معدل خطأ الكلمات (WER) للكلام الصيني والإنجليزي المُولّد من MiniMax حوالي 2%، مما يشير إلى أن الكلمات المنطوقة مفهومة تقريباً بشكل مثالي من قبل نظام التعرف على الكلام التلقائي (ASR).
كيف يتعامل Speech 2.5 مع المستندات أو الكتب الطويلة؟
زمن الاستجابة والإنتاجية للنصوص الطويلة (Speech 2.5)
يحافظ MiniMax Speech 2.5 على أداء مستقر للمدخلات الطويلة مع مزايا قابلة للقياس في زمن الاستجابة والإنتاجية:
• زمن استجابة تحويل النص إلى كلام (TTS):
يبدأ تشغيل الصوت عادةً في غضون بضع ثوانٍ، حتى للنصوص متعددة الفقرات. يعمل مسار الصوت المحدث في الإصدار 2.5 على تقليل تأخير البدء. تحقق الأنظمة الأحدث زمن استجابة من البداية إلى النهاية يبلغ 250 مللي ثانية في إعدادات الوكلاء؛ يبقى Speech 2.5 في نطاق الثواني القليلة لطلبات التوليد القياسية.
• سعة النصوص الطويلة:
يدعم ما يصل إلى 10,000 حرف لكل طلب عبر واجهة برمجة تطبيقات TTS غير المتزامنة. تظل روابط التنزيل صالحة لمدة 9 ساعات، مما يضمن استرجاعاً موثوقاً.
- وضع Turbo: زمن استجابة أقل وإنتاجية أعلى (مع موازنة معتدلة في الدقة).
- وضع HD: جودة صوت قصوى.
يمكن زيادة الإنتاجية بشكل أكبر باستخدام الإرسال الدفعي أو المهام غير المتزامنة، مما يجعله مناسباً لأحمال العمل مثل مهام النسخ أو التوليد التي تستغرق ساعات.
ما هي تكلفة كل 1000 حرف من Speech 2.5؟
| المزود | التكلفة لكل 1000 حرف |
|---|---|
| MiniMax Speech 2.5 Turbo | 0.048 دولار |
| MiniMax Speech 2.5 HD | 0.08 دولار |
| ElevenLabs | 0.24–0.30 دولار |
| OpenAI GPT-4 Audio | أكثر من 0.10 دولار عادةً |
| Google Gemini | أكثر من 2.50 دولار لكل مليون رمز (TTS) |
تقدم Novita AI أفضل سعر لـ MiniMax Speech!
ما مدى دقة التحكم في النطق، والتأكيد، والوقفات؟
| قدرة التحكم | حقل واجهة برمجة التطبيقات | قيمة/استخدام مثال |
|---|---|---|
| وقفات مخصصة | text باستخدام <#x#> |
Hello<#0.50#>world |
| نطق على مستوى الفونيم (IPA / X-SAMPA) | pronunciation_dict |
"demo": {"type":"ipa","value":"ˈdɛmoʊ"} |
| استبدال النبرة الصوتية الصينية | pronunciation_dict (type: "tone") |
"你好": {"type":"tone","value":"ni3 hao3"} |
| معدل الكلام | voice_setting.speed |
1.05 |
| مستوى الصوت | voice_setting.vol |
1.2 |
| طبقة الصوت (انزياح بالسينت) | voice_setting.pitch |
2 |
| اختيار الصوت (معرف النبرة الصوتية) | voice_setting.voice_id |
"Calm_Woman" |
| العاطفة | voice_setting.emotion |
"neutral" |
| تطبيع النص الإنجليزي | voice_setting.text_normalization |
true |
| معدل العينة | audio_setting.sample_rate |
44100 |
| معدل البت | audio_setting.bitrate |
128000 |
| تنسيق الصوت | audio_setting.format |
"mp3" |
| القنوات | audio_setting.channel |
1 (أحادي) |
| مزج النبرة الصوتية (حتى 4 أصوات) | timbre_weights |
[{"voice_id":"Calm_Woman","weight":70}] |
| مؤثرات صوتية (صدى، هاتف، روبوت، إلخ) | voice_modify.sound_effects |
"spacious_echo" |
| ضبط سطوع طبقة الصوت | voice_modify.pitch |
10 |
| ضبط الشدة | voice_modify.intensity |
-20 |
| حدة/مغناطيسية النبرة الصوتية | voice_modify.timbre |
-15 |
| وضع البث المباشر | stream |
false |
| تعزيز اللغة/اللهجة | language_boost |
"English" |
import requests
url = "https://api.novita.ai/v3/minimax-speech-2.5-hd-preview"
payload = {
"text": "Hello<#0.50#>this is a demo of fine-grained control.<#0.30#>\
Please read the number 2025 clearly.",
"voice_setting": {
"speed": 1.05,
"vol": 1.2,
"pitch": 2,
"voice_id": "Calm_Woman",
"emotion": "neutral",
"text_normalization": True
},
"audio_setting": {
"sample_rate": 44100,
"bitrate": 128000,
"format": "mp3",
"channel": 1
},
# Use the concrete pronunciation dictionary from your example
"pronunciation_dict": {
"demo": {
"type": "ipa",
"value": "ˈdɛmoʊ"
},
"2025": {
"type": "ipa",
"value": "tuː θaʊzənd twɛnti faɪv"
},
"你好": {
"type": "tone",
"value": "ni3 hao3"
}
},
"timbre_weights": [
{
"voice_id": "Calm_Woman",
"weight": 70
},
{
"voice_id": "Friendly_Person",
"weight": 30
}
],
"stream": False,
"language_boost": "English",
"output_format": "url",
"voice_modify": {
"pitch": 10,
"intensity": -20,
"timbre": -15,
"sound_effects": "spacious_echo"
}
}
headers = {
"Content-Type": "application/json",
"Authorization": "Bearer YOUR_API_KEY_HERE"
}
response = requests.post(url, json=payload, headers=headers)
print(response.text)
هل يدعم MiniMax Speech 2.5 البث المباشر (Streaming)؟
نعم. يدعم MiniMax Speech 2.5 البث المباشر لكل من التعرف على الكلام التلقائي (ASR) وتحويل النص إلى كلام (TTS). تتضمن واجهة برمجة التطبيقات الحقل صراحةً:
"stream": true
في طلب TTS، يبدأ النظام في توليد الصوت فوراً ويرسله مرة أخرى في أجزاء. هذا يسمح ببدء التشغيل قبل اكتمال توليد الجملة بالكامل. يبلغ زمن استجابة بدء TTS النموذجي بضع ثوانٍ، ويمكن للسيناريوهات المحسنة الوصول إلى أوقات استجابة من البداية إلى النهاية أقل من الثانية.
كيف تستخدم MiniMax Speech 2.5 بسعر جيد؟
الخطوة 1: تسجيل الدخول والوصول إلى مكتبة النماذج
سجل الدخول إلى حسابك وانقر على زر مكتبة النماذج.

الخطوة 2: اختر النموذج الخاص بك
تصفح الخيارات المتاحة واختر النموذج الذي يناسب احتياجاتك.
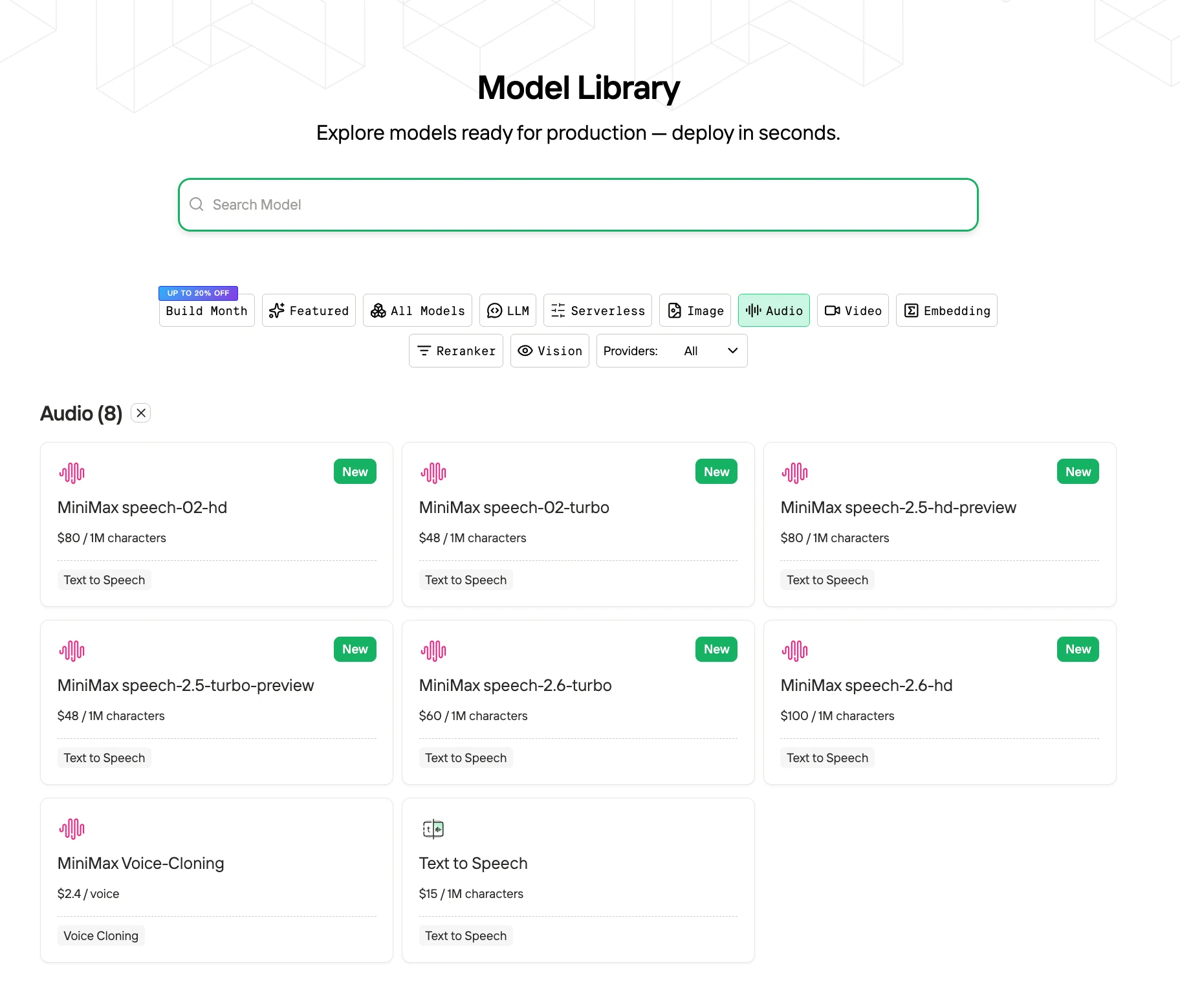
الخطوة 3: ابدأ تجربتك المجانية
ابدأ تجربتك المجانية لاستكشاف قدرات النموذج المحدد.
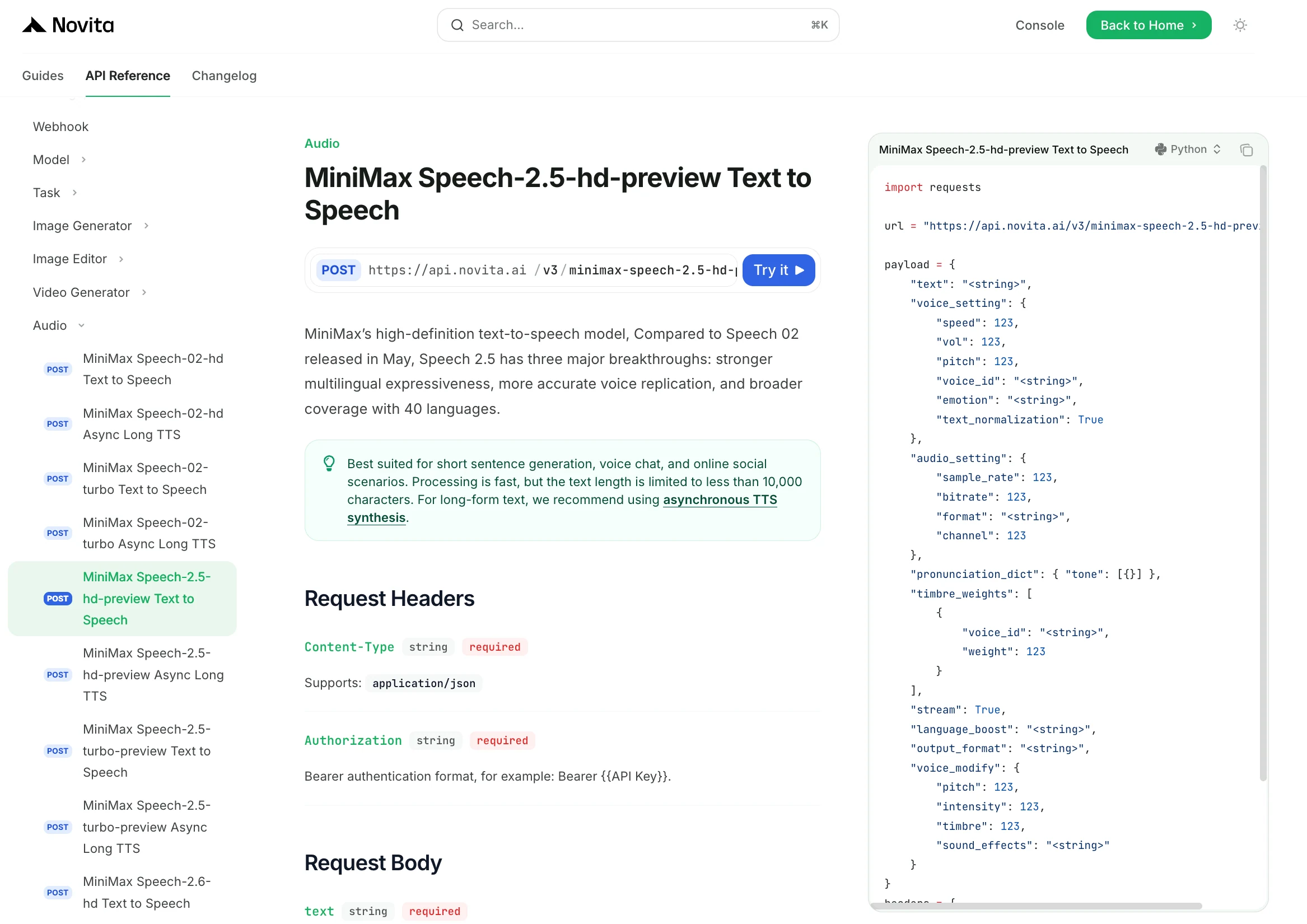
الخطوة 4: احصل على مفتاح API الخاص بك
للمصادقة مع واجهة برمجة التطبيقات، سنزودك بمفتاح API جديد. عند الدخول إلى صفحة “الإعدادات“، يمكنك نسخ مفتاح API كما هو موضح في الصورة.

يقدم MiniMax Speech 2.5 حلاً متوازناً وجاهزاً للمطورين للمشاكل الأساسية في تطوير تطبيقات الصوت الحديثة. فهو يجمع بين أوقات الاستجابة السريعة، والدقة العالية متعددة اللغات، والمعالجة الموثوقة للنصوص الطويلة مع تسعير فعال من حيث التكلفة وتحكم دقيق في النبرة العاطفية، والنطق، والنبرة الصوتية. وبفضل وضعي Turbo و HD المحسّنين لاحتياجات مختلفة من زمن الاستجابة والجودة، مع دعم كامل للبث المباشر، يتيح MiniMax Speech 2.5 للفرق بناء وكلاء صوت قابلين للتطوير، وأنظمة نسخ في الوقت الفعلي، وخطوط أنابيب محتوى عالية الجودة مع عدد أقل بكثير من القيود التقنية. إن أداء النموذج، ومرونته، وتصميم واجهة برمجة التطبيقات يجعله خياراً عملياً للمطورين الذين يسعون إلى كل من الكفاءة وتوليد كلام معبر.
الأسئلة الشائعة
هل يدعم MiniMax Speech 2.5 البث المباشر؟
نعم. يدعم MiniMax Speech 2.5 البث المباشر لكل من ASR و TTS. يسمح تفعيل "stream": true للنظام بإرسال نصوص جزئية أو أجزاء صوتية في الوقت الفعلي، مما يتيح أوقات استجابة أقل من الثانية وتوقيت محادثة طبيعي.
ما مدى دقة استنساخ الصوت في MiniMax Speech 2.5؟
يحقق MiniMax Speech 2.5 استنساخ صوت عالي الدقة باستخدام 6 إلى 10 ثوانٍ فقط من الصوت، مع وصول تشابه يصل إلى 99% وتفوقه على العديد من البدائل التجارية في معايير تشابه المتحدث متعدد اللغات.
هل يتعامل MiniMax Speech 2.5 مع الكلام متعدد اللغات بشكل جيد؟
نعم. يدعم MiniMax Speech 2.5 أكثر من 40 لغة ويحقق معدل خطأ في الكلمات (WER) يبلغ حوالي 2% للغتين الصينية والإنجليزية. ويحافظ على الهوية الصوتية عبر اللغات من خلال طبقات النقل بين اللغات والتدريب من البداية إلى النهاية.
Novita AI هي منصة سحابية شاملة تمكّنك من تحقيق طموحاتك في الذكاء الاصطناعي. واجهات برمجة تطبيقات متكاملة، بدون خوادم، مثيلات GPU — هي الأدوات الفعالة من حيث التكلفة التي تحتاجها. تخلص من البنية التحتية، ابدأ مجاناً، وحقق رؤيتك في الذكاء الاصطناعي.



