

音声アプリケーションを開発するエンジニアは、応答時間の遅さ、言語間での一貫性のない音声品質、高いAPIコスト、感情トーンや発音の制御の限界といった課題にしばしば直面します。これらの問題は、リアルタイムインタラクションや大規模な音声生成を確実に提供することを困難にしています。
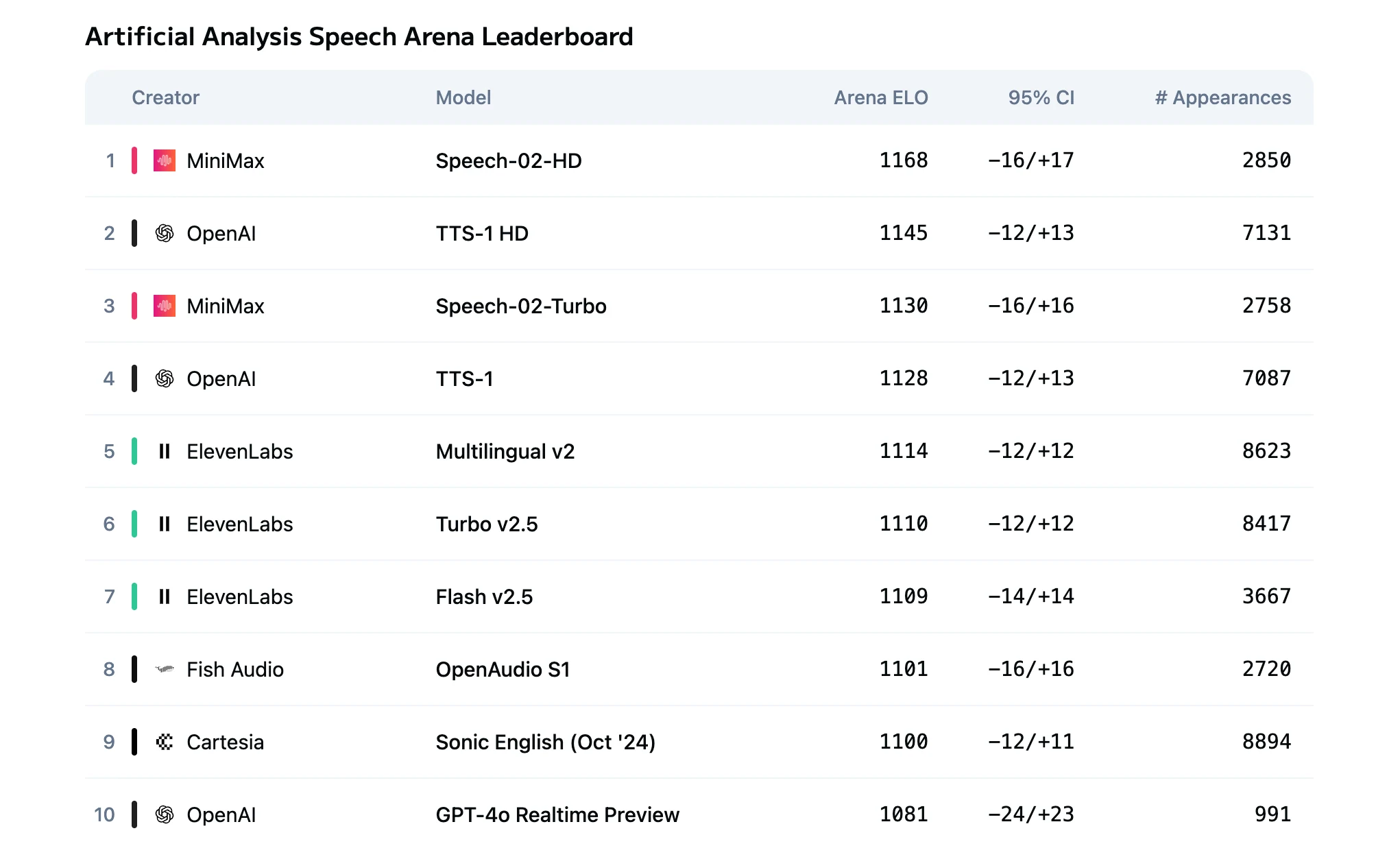
MiniMax Speech 2.5は、これらの制約に直接対処するために設計されています。わずか6~10秒の音声から高精度な声のクローン作成、40以上の言語に対応した多言語合成(中国語・英語で約2%のWER)、インタラクティブ利用に適した約250msのTurboモードレイテンシを実現。長文処理では最大200,000文字の非同期処理が可能で、料金は1,000文字あたり0.04ドルとデベロッパーフレンドリーです。細かな感情制御とSNR 3dB以上での安定したパフォーマンスにより、リアルタイム応答性とスケーラブルでコスト効率の高い音声生成の両方を必要とするチームに実用的なソリューションを提供します。
Speech 2.5 Turbo と HD のモデル比較
Speech 2.5 HDとTurbo Previewの根本的な違いは、品質とレイテンシのトレードオフにあります:
| メトリクス | HD | Turbo |
|---|---|---|
| 音声品質 | スタジオ級のリアリズムで最高の忠実度 | 高精細品質、表現力はやや劣る |
| TTSレイテンシ | 数秒 | エンドツーエンドで250ms未満 |
| 理想的なシナリオ | ハイエンドコンテンツ生成 | リアルタイムインタラクティブアプリケーション |
| コスト | $80/100万文字 | $48/100万文字 |
HDは、優れた音色の類似性、感情のニュアンス、自然な韻律を提供します。
Turboはエンコードパイプラインを最適化し、リアルタイムインタラクションに適した極めて低いレイテンシを実現します。
Speech 2.5は、わずか数秒の音声で任意の声を再現できるか?
MiniMax Speech 2.5のFlow-VAEデコーダは、Flow MatchingとVariational Autoencodingを組み合わせ、メルスペクトログラムのみに頼るのではなく、学習された潜在空間で音声をモデリングします。これにより、ピッチ、リズム、アクセント、感情の色合いを捉えます。
必要なサンプル長: 高忠実度クローンのためにわずか6~10秒、最大99%の類似度を達成。
類似度メトリクス: 24言語にわたる話者類似性でElevenLabsを上回ります。
ゼロショットクローン: トランスクリプトは不要。学習済みの話者埋め込みエンコーダが音声の同一性を直接抽出します。
Speech 2.5は40以上の言語でネイティブレベルの発音を実現するか?
多言語対応:
- 40以上の言語をサポート
- 中国語: グローバルベンチマークでのトップパフォーマンス
- 英語: Speech 0.2から大幅アップグレード、機械的なアーティファクトが低減
- その他の言語: 日本語、フランス語、スペイン語などを自然なネイティブ発音でサポート
メカニズム:
- 強化された話者特徴抽出
- 音色を保持する言語間転送層
- 言語間で声のアイデンティティを維持するエンドツーエンドトレーニング
品質メトリクス:
MiniMaxで合成された英語と中国語の音声はWERが約2%で、ASRが話された単語をほぼ完璧に認識できることを示しています。
Speech 2.5は長いドキュメントや書籍をどの程度うまく処理できるか?
長文のレイテンシとスループット(Speech 2.5)
MiniMax Speech 2.5は、長い入力に対しても安定したパフォーマンスを維持し、定量化可能なレイテンシとスループットの利点を提供します:
• TTSレイテンシ:
複数段落のテキストでも、通常数秒以内に音声再生が開始されます。アップデートされた2.5オーディオパイプラインは起動遅延を最小限に抑えています。後続世代のシステムではエージェント設定で250msのエンドツーエンドレイテンシを実現。Speech 2.5は標準合成リクエストでは低秒台を維持します。
• 長文容量:
非同期TTS API経由でリクエストあたり最大10,000文字をサポート。ダウンロードURLは9時間有効で、確実な取得が可能です。
- Turboモード: 低レイテンシかつ高スループット(忠実度はやや低下)
- HDモード: 音声品質を最大化
- バッチ送信や非同期ジョブを使用することでさらにスループットを向上可能。1時間の文字起こしや合成タスクなどに適しています。
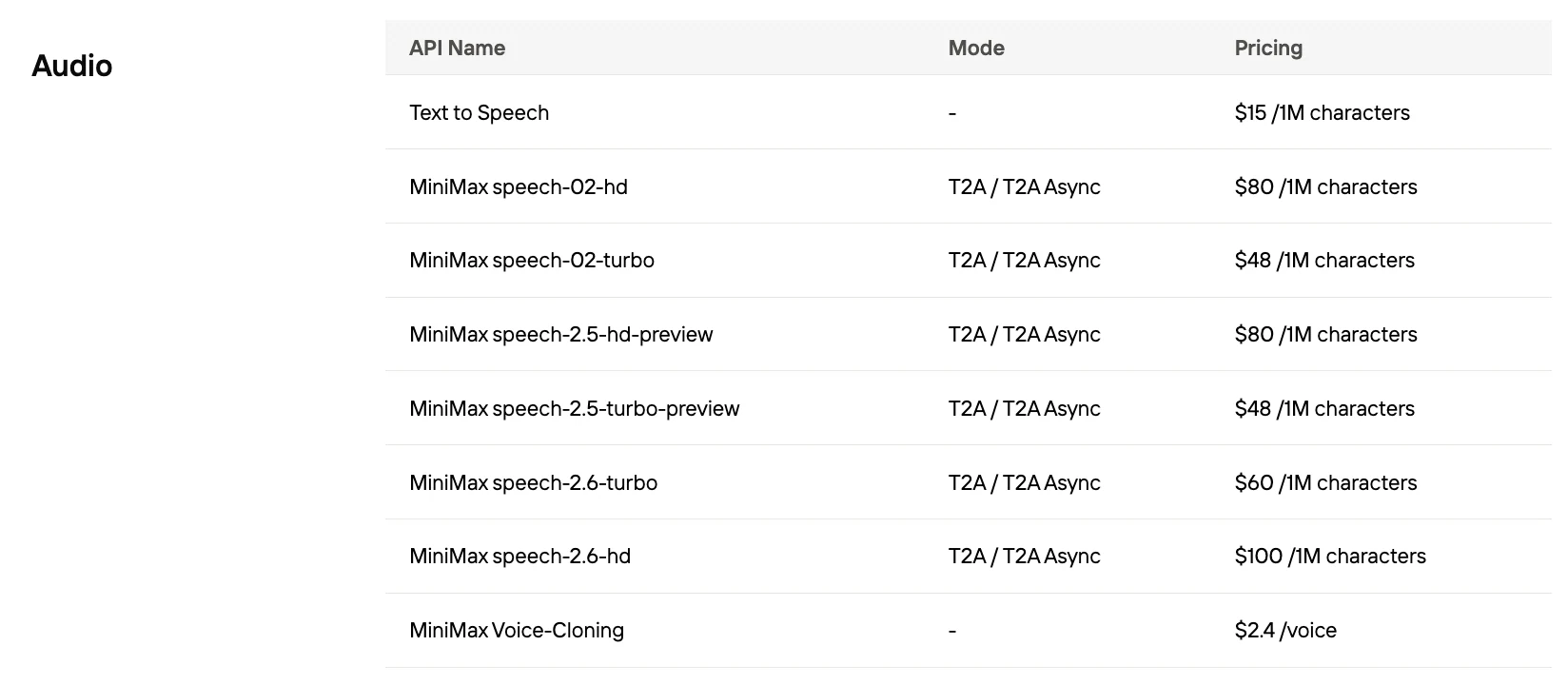
Speech 2.5の1,000文字あたりのコスト
| プロバイダー | コスト / 1K文字 |
|---|---|
| MiniMax Speech 2.5 Turbo | $0.048 |
| MiniMax Speech 2.5 HD | $0.08 |
| ElevenLabs | $0.24–0.30 |
| OpenAI GPT-4 Audio | 通常$0.10以上 |
| Google Gemini | TTS: 100万トークンあたり$2.50以上 |
Novita AIがMiniMaxの最安値を提供!
発音、強調、ポーズに対する制御はどの程度細かいか?
| 制御機能 | APIフィールド | 値の例 / 使用方法 |
|---|---|---|
| カスタムポーズ | text で <#x#> を使用 |
Hello<#0.50#>world |
| 音素レベルの発音(IPA / X-SAMPA) | pronunciation_dict |
"demo": {"type":"ipa","value":"ˈdɛmoʊ"} |
| 中国語の声調置換 | pronunciation_dict (type: "tone") |
"你好": {"type":"tone","value":"ni3 hao3"} |
| 話速 | voice_setting.speed |
1.05 |
| 音量 | voice_setting.vol |
1.2 |
| ピッチ(半音シフト) | voice_setting.pitch |
2 |
| 声の選択(音色ID) | voice_setting.voice_id |
"Calm_Woman" |
| 感情 | voice_setting.emotion |
"neutral" |
| 英語テキスト正規化 | voice_setting.text_normalization |
true |
| サンプルレート | audio_setting.sample_rate |
44100 |
| ビットレート | audio_setting.bitrate |
128000 |
| 音声フォーマット | audio_setting.format |
"mp3" |
| チャンネル数 | audio_setting.channel |
1(モノラル) |
| 音色ミキシング(最大4声) | timbre_weights |
[{"voice_id":"Calm_Woman","weight":70}] |
| オーディオFX(リバーブ、電話、ロボティック等) | voice_modify.sound_effects |
"spacious_echo" |
| 明るさ・ピッチ調整 | voice_modify.pitch |
10 |
| 強度調整 | voice_modify.intensity |
-20 |
| 音色のシャープネス・磁力 | voice_modify.timbre |
-15 |
| ストリーミングモード | stream |
false |
| 言語/方言ブースト | language_boost |
"English" |
import requests
url = "https://api.novita.ai/v3/minimax-speech-2.5-hd-preview"
payload = {
"text": "Hello<#0.50#>this is a demo of fine-grained control.<#0.30#>\
Please read the number 2025 clearly.",
"voice_setting": {
"speed": 1.05,
"vol": 1.2,
"pitch": 2,
"voice_id": "Calm_Woman",
"emotion": "neutral",
"text_normalization": True
},
"audio_setting": {
"sample_rate": 44100,
"bitrate": 128000,
"format": "mp3",
"channel": 1
},
# Use the concrete pronunciation dictionary from your example
"pronunciation_dict": {
"demo": {
"type": "ipa",
"value": "ˈdɛmoʊ"
},
"2025": {
"type": "ipa",
"value": "tuː θaʊzənd twɛnti faɪv"
},
"你好": {
"type": "tone",
"value": "ni3 hao3"
}
},
"timbre_weights": [
{
"voice_id": "Calm_Woman",
"weight": 70
},
{
"voice_id": "Friendly_Person",
"weight": 30
}
],
"stream": False,
"language_boost": "English",
"output_format": "url",
"voice_modify": {
"pitch": 10,
"intensity": -20,
"timbre": -15,
"sound_effects": "spacious_echo"
}
}
headers = {
"Content-Type": "application/json",
"Authorization": "Bearer YOUR_API_KEY_HERE"
}
response = requests.post(url, json=payload, headers=headers)
print(response.text)
MiniMax Speech 2.5はストリーミングに対応しているか?
はい。MiniMax Speech 2.5は、音声認識(ASR) とテキスト読み上げ(TTS) の両方でストリーミングをサポートしています。APIには次のフィールドが明示的に含まれています:
"stream": true
TTSリクエストでこれを有効にすると、システムは即座に音声の生成を開始し、セグメントごとに送信します。これにより、文全体が合成される前に再生を開始できます。一般的なTTS起動レイテンシは数秒以内で、最適化されたシナリオではサブ秒のエンドツーエンド応答時間を達成できます。
MiniMax Speech 2.5をリーズナブルな価格で利用する方法
ステップ1:ログインしてモデルライブラリにアクセス
アカウントにログインし、Model Libraryボタンをクリックします。

ステップ2:モデルを選択
利用可能なオプションから、ニーズに合ったモデルを選択します。
ステップ3:無料トライアルを開始
無料トライアルを開始して、選択したモデルの機能を試します。
ステップ4:APIキーを取得
APIで認証するため、新しいAPIキーを提供します。「Settings」ページに移動し、画像のようにAPIキーをコピーします。

MiniMax Speech 2.5は、現代の音声アプリケーション開発における中核的な問題に対して、バランスの取れたデベロッパー向けソリューションを提供します。高速応答、強力な多言語精度、信頼性の高い長文処理、コスト効率の良い料金、そして感情的なトーン、発音、音色に対する詳細な制御を兼ね備えています。レイテンシと品質のニーズに応じて最適化されたTurboモードとHDモード、ストリーミングの完全サポートにより、MiniMax Speech 2.5はチームがスケーラブルな音声エージェント、リアルタイム文字起こしシステム、高品質なコンテンツパイプラインを構築する際の技術的制約を大幅に軽減します。このモデルのパフォーマンス、柔軟性、API設計は、効率性と表現力豊かな音声生成の両方を求めるデベロッパーにとって実用的な選択肢です。
よくある質問
MiniMax Speech 2.5はストリーミングに対応していますか?
はい。MiniMax Speech 2.5はASRとTTSの両方でストリーミングをサポートしています。"stream": true を有効にすると、システムは増分トランスクリプトまたは音声チャンクをリアルタイムで送信し、サブ秒の応答時間と自然な会話タイミングを実現します。
MiniMax Speech 2.5の声のクローン精度はどのくらいですか?
MiniMax Speech 2.5はわずか6~10秒の音声で高忠実度の声のクローンを実現し、最大99%の類似度を達成します。多言語話者類似性ベンチマークでいくつかの商用代替製品を上回っています。
MiniMax Speech 2.5は多言語音声をうまく処理できますか?
はい。MiniMax Speech 2.5は40以上の言語をサポートし、中国語と英語で約2%のWERを達成します。言語間転送層とエンドツーエンドトレーニングにより、言語間で声のアイデンティティを維持します。
Novita AIは、AIの可能性を引き出すオールインワンのクラウドプラットフォームです。統合API、サーバーレス、GPUインスタンス——必要なコスト効率の高いツール。インフラを排除し、無料で始めて、AIのビジョンを現実にします。



