

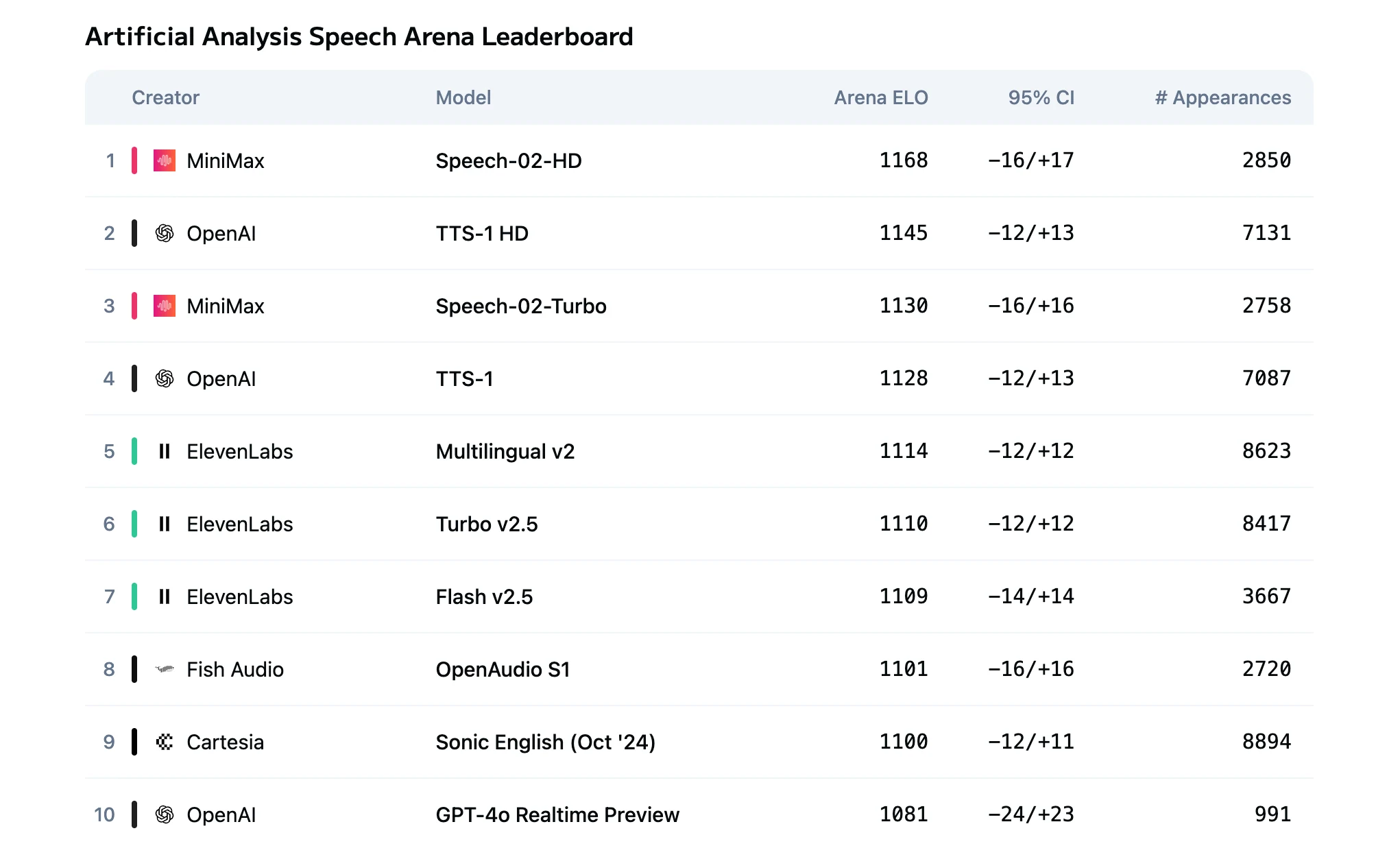
- Сравнение моделей Speech 2.5 Turbo и HD
- Может ли Speech 2.5 воспроизвести произвольный голос по всего нескольким секундам аудио?
- Обеспечивает ли Speech 2.5 произношение на уровне носителя на 40+ языках?
- Насколько хорошо Speech 2.5 справляется с длинными документами или книгами?
- Какова стоимость 1000 символов для Speech 2.5
- Насколько тонкий контроль над произношением, акцентом и паузами?
- Поддерживает ли Speech 2.5 потоковую передачу?
- Как использовать MiniMax Speech 2.5 по выгодной цене?
Разработчики, создающие голосовые приложения, часто сталкиваются с медленным временем отклика, нестабильным качеством аудио на разных языках, высокими затратами на API и ограниченным контролем над эмоциональной окраской или произношением — эти проблемы делают сложной надежную реализацию взаимодействия в реальном времени и массовой генерации.
MiniMax Speech 2.5 разработан для прямого решения этих ограничений. Он предлагает высокоточное клонирование голоса по всего 6–10 секундам аудио, многоязычный синтез на 40+ языках с показателем WER около 2% для китайского и английского, а также задержку в режиме Turbo около 250 мс для интерактивного использования. Поддерживаются длинные рабочие нагрузки за счет асинхронной обработки до 200 000 символов, при этом цены остаются удобными для разработчиков — $0.04 за 1000 символов. Благодаря тонкому контролю над эмоциями и стабильной производительности при SNR ≥ 3 дБ, модель предоставляет практическое решение для команд, которым нужны одновременно отзывчивость в реальном времени и масштабируемая, экономически эффективная генерация голоса.
Сравнение моделей Speech 2.5 Turbo и HD
Фундаментальное различие между Speech 2.5 HD и Turbo Preview заключается в компромиссе между качеством и задержкой:
| Метрика | HD | Turbo |
|---|---|---|
| Качество аудио | Качество студийного уровня с наивысшей точностью | Высокое качество HD с немного меньшей выразительностью |
| Задержка TTS | Несколько секунд | Задержка от конца до конца менее 250 мс |
| Идеальный сценарий | Генерация контента премиум-класса | Приложения для взаимодействия в реальном времени |
| Стоимость | $80 за миллион символов | $48 за миллион символов |
HD обеспечивает превосходное сходство тембра, эмоциональные нюансы и естественную просодию.
Turbo оптимизирует конвейер кодирования для достижения крайне низкой задержки, подходящей для взаимодействия в реальном времени.
Может ли Speech 2.5 воспроизвести произвольный голос по всего нескольким секундам аудио?
Декодер Flow-VAE MiniMax Speech 2.5 сочетает Flow Matching и вариационное автоэнкодирование для моделирования речи в обученном латентном пространстве, а не полагается исключительно на мел-спектрограммы. Это позволяет захватывать высоту тона, ритм, акцент и эмоциональную окраску.
Требуемая длина образца: Всего 6–10 секунд для высокоточного клонирования, достигается сходство до 99%.
Метрики сходства: Превосходит ElevenLabs по сходству говорящего на 24 языках.
Клонирование без примеров (zero-shot): Транскрипт не требуется; обученный speaker embedding encoder извлекает идентичность голоса напрямую
Попробуйте MiniMax Speech 2.5 сейчас!
Обеспечивает ли Speech 2.5 произношение на уровне носителя на 40+ языках?
Многоязычные возможности:
- Поддерживает 40+ языков
- Китайский: Производительность на глобальных бенчмарках
- Английский: Значительное улучшение по сравнению с Speech 0.2, уменьшено количество механических артефактов
- Другие языки: Японский, французский, испанский и другие с естественным произношением на уровне носителя
Механизмы:
- Улучшенное извлечение признаков говорящего
- Слои межъязыкового переноса, сохраняющие тембр
- Сквозное обучение для сохранения идентичности голоса на разных языках
Метрика качества:
Синтезированная речь на английском и китайском от MiniMax имеет WER около 2%, что означает, что произнесенные слова почти идеально распознаются системой ASR.
Насколько хорошо Speech 2.5 справляется с длинными документами или книгами?
Задержка и пропускная способность для длинных текстов (Speech 2.5)
MiniMax Speech 2.5 сохраняет стабильную производительность на длинных входных данных с измеримыми преимуществами по задержке и пропускной способности:
• Задержка TTS:
Воспроизведение аудио обычно начинается в течение нескольких секунд, даже для текста из нескольких абзацев. Обновленный аудиоконвейер 2.5 минимизирует задержку запуска. В системах последующих поколений достигается задержка от конца до конца 250 мс в средах с агентами; Speech 2.5 остается в диапазоне низких секунд для стандартных запросов на синтез.
• Объем длинного текста:
Поддерживает до 10 000 символов за запрос через асинхронный API TTS. Ссылки для скачивания действительны в течение 9 часов, что обеспечивает надежное получение данных.
- Режим Turbo: более низкая задержка и выше пропускная способность (с умеренными компромиссами в точности).
- Режим HD: максимальное качество аудио.
Пропускная способность может быть дополнительно увеличена с помощью пакетной отправки или асинхронных задач, что подходит для рабочих нагрузок таких, как синтез или транскрипция текстов длиной в несколько часов.
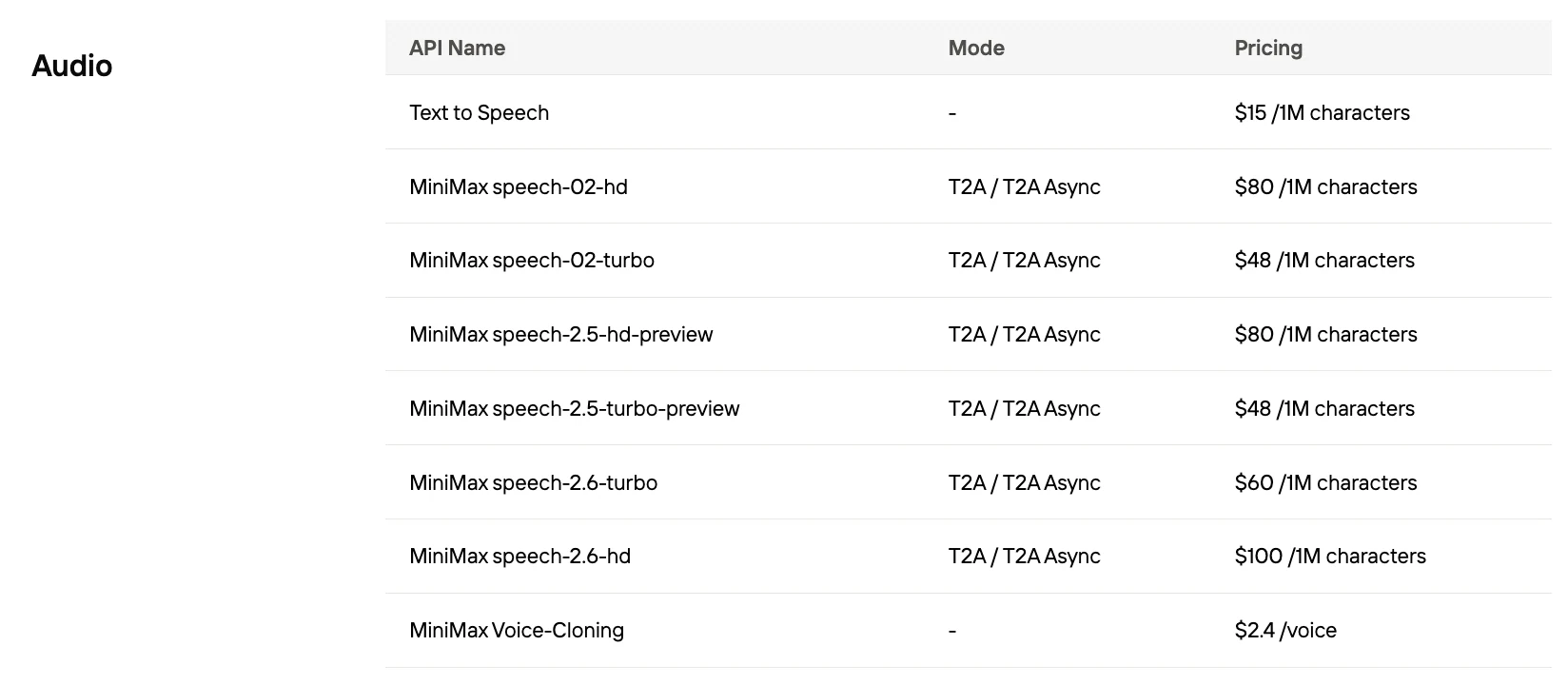
Какова стоимость 1000 символов для Speech 2.5
| Провайдер | Стоимость за 1000 символов |
|---|---|
| MiniMax Speech 2.5 Turbo | $0.048 |
| MiniMax Speech 2.5 HD | $0.08 |
| ElevenLabs | $0.24–0.30 |
| OpenAI GPT-4 Audio | Обычно >$0.10 |
| Google Gemini | TTS >$2.50 за 1 миллион токенов |
Novita AI предлагает лучшую цену на MiniMax Speech!
Попробуйте MiniMax Speech 2.5 сейчас!
Насколько тонкий контроль над произношением, акцентом и паузами?
| Возможность контроля | Поле API | Пример значения / использования |
|---|---|---|
| Пользовательские паузы | text с использованием <#x#> |
Hello<#0.50#>world |
| Произношение на уровне фонем (IPA / X-SAMPA) | pronunciation_dict |
"demo": {"type":"ipa","value":"ˈdɛmoʊ"} |
| Замена тонов в китайском | pronunciation_dict (type: "tone") |
"你好": {"type":"tone","value":"ni3 hao3"} |
| Скорость речи | voice_setting.speed |
1.05 |
| Громкость | voice_setting.vol |
1.2 |
| Высота тона (сдвиг в полутонах) | voice_setting.pitch |
2 |
| Выбор голоса (ID тембра) | voice_setting.voice_id |
"Calm_Woman" |
| Эмоция | voice_setting.emotion |
"neutral" |
| Нормализация английского текста | voice_setting.text_normalization |
true |
| Частота дискретизации | audio_setting.sample_rate |
44100 |
| Битрейт | audio_setting.bitrate |
128000 |
| Формат аудио | audio_setting.format |
"mp3" |
| Каналы | audio_setting.channel |
1 (моно) |
| Смешение тембров (до 4 голосов) | timbre_weights |
[{"voice_id":"Calm_Woman","weight":70}] |
| Аудиоэффекты (реверберация, телефонный эффект, роботизированный голос и т.д.) | voice_modify.sound_effects |
"spacious_echo" |
| Корректировка высоты тона яркости | voice_modify.pitch |
10 |
| Корректировка интенсивности | voice_modify.intensity |
-20 |
| Резкость/магнетизм тембра | voice_modify.timbre |
-15 |
| Режим потоковой передачи | stream |
false |
| Усиление языка/диалекта | language_boost |
"English" |
import requests
url = "https://api.novita.ai/v3/minimax-speech-2.5-hd-preview"
payload = {
"text": "Hello<#0.50#>this is a demo of fine-grained control.<#0.30#>\
Please read the number 2025 clearly.",
"voice_setting": {
"speed": 1.05,
"vol": 1.2,
"pitch": 2,
"voice_id": "Calm_Woman",
"emotion": "neutral",
"text_normalization": True
},
"audio_setting": {
"sample_rate": 44100,
"bitrate": 128000,
"format": "mp3",
"channel": 1
},
# Use the concrete pronunciation dictionary from your example
"pronunciation_dict": {
"demo": {
"type": "ipa",
"value": "ˈdɛmoʊ"
},
"2025": {
"type": "ipa",
"value": "tuː θaʊzənd twɛnti faɪv"
},
"你好": {
"type": "tone",
"value": "ni3 hao3"
}
},
"timbre_weights": [
{
"voice_id": "Calm_Woman",
"weight": 70
},
{
"voice_id": "Friendly_Person",
"weight": 30
}
],
"stream": False,
"language_boost": "English",
"output_format": "url",
"voice_modify": {
"pitch": 10,
"intensity": -20,
"timbre": -15,
"sound_effects": "spacious_echo"
}
}
headers = {
"Content-Type": "application/json",
"Authorization": "Bearer YOUR_API_KEY_HERE"
}
response = requests.post(url, json=payload, headers=headers)
print(response.text)
Попробуйте MiniMax Speech 2.5 сейчас!
Поддерживает ли Speech 2.5 потоковую передачу?
Да. MiniMax Speech 2.5 поддерживает потоковую передачу как для распознавания речи (ASR), так и для преобразования текста в речь (TTS). API явно включает поле:
"stream": true
в запросе TTS система начинает генерировать аудио немедленно и отправляет его обратно сегментами. Это позволяет начать воспроизведение до того, как будет синтезировано все предложение. Типичная задержка запуска TTS составляет несколько секунд, а в оптимизированных сценариях можно достичь времени отклика от конца до конца менее одной секунды.
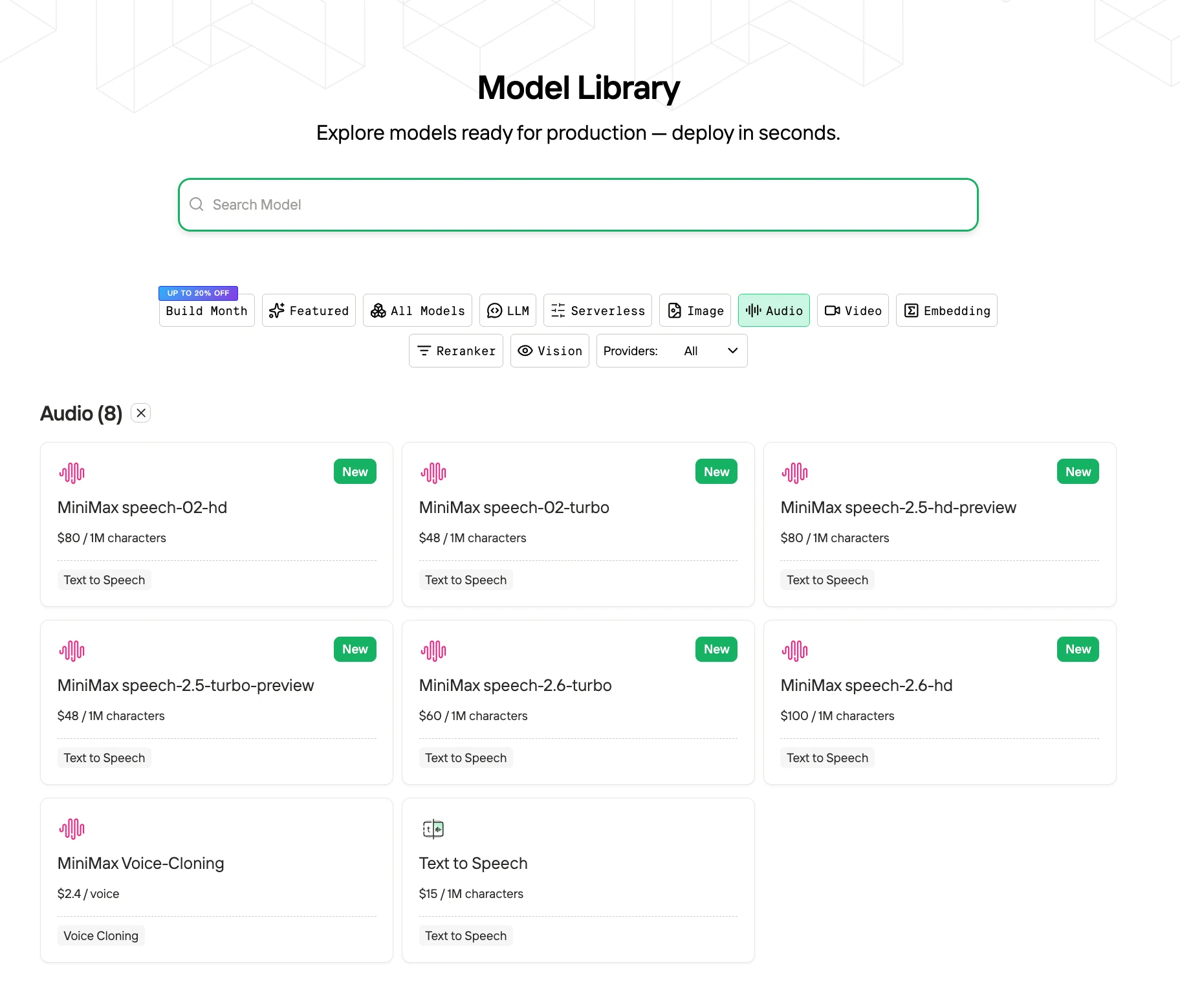
Как использовать MiniMax Speech 2.5 по выгодной цене?
Шаг 1: Войдите в систему и откройте библиотеку моделей
Войдите в свой аккаунт и нажмите кнопку Библиотека моделей.

Шаг 2: Выберите нужную модель
Просмотрите доступные варианты и выберите модель, подходящую для ваших задач.
Попробуйте MiniMax Speech 2.5 сейчас!
Шаг 3: Начните бесплатный пробный период
Начните бесплатный пробный период, чтобы изучить возможности выбранной модели.
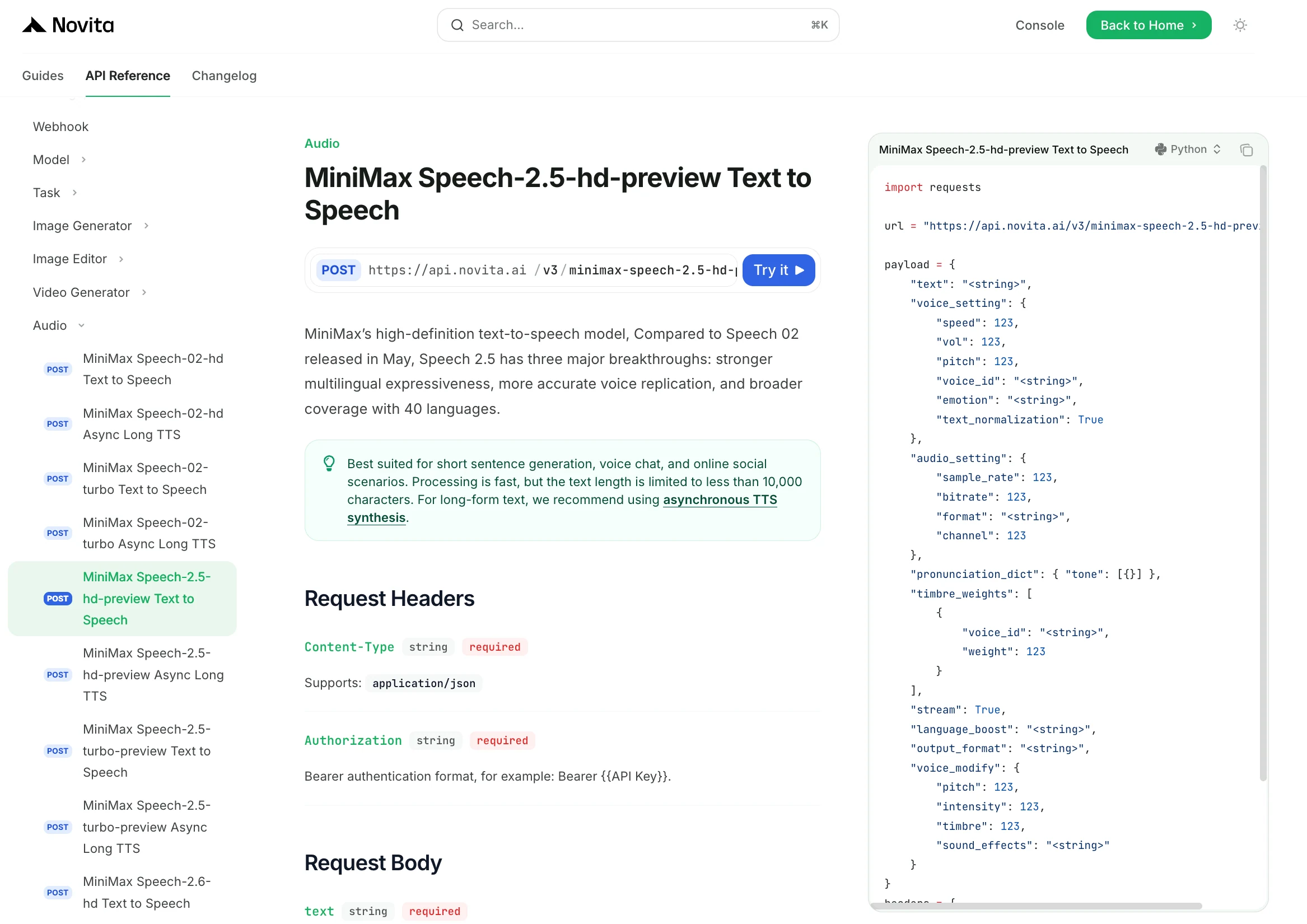
Шаг 4: Получите ключ API
Для аутентификации в API мы предоставим вам новый ключ API. Перейдите на страницу «Настройки», где вы можете скопировать ключ API, как показано на изображении.

MiniMax Speech 2.5 предлагает сбалансированное, готовое для разработчиков решение ключевых проблем современной разработки голосовых приложений. Он сочетает быстрое время отклика, высокую многоязычную точность и надежную обработку длинных текстов с экономически эффективным ценообразованием и детальным контролем над эмоциональной окраской, произношением и тембром. С режимами Turbo и HD, оптимизированными для разных потребностей в задержке и качестве, а также полной поддержкой потоковой передачи, MiniMax Speech 2.5 позволяет командам создавать масштабируемые голосовые агенты, системы транскрипции в реальном времени и конвейеры генерации высококачественного контента с гораздо меньшими техническими ограничениями. Производительность, гибкость и дизайн API модели делают ее практическим выбором для разработчиков, которым нужны как эффективность, так и выразительная генерация речи.
Часто задаваемые вопросы
Поддерживает ли MiniMax Speech 2.5 потоковую передачу?
Да. MiniMax Speech 2.5 поддерживает потоковую передачу как для ASR, так и для TTS. Включение "stream": true позволяет системе отправлять инкрементные транскрипты или аудиочанки в реальном времени, обеспечивая время отклика менее одной секунды и естественный темп разговора.
Насколько точным является клонирование голоса в MiniMax Speech 2.5?
MiniMax Speech 2.5 обеспечивает высокоточное клонирование голоса по всего 6–10 секундам аудио, достигая сходства до 99% и превосходя несколько коммерческих альтернатив в многоязычных бенчмарках сходства говорящего.
Насколько хорошо MiniMax Speech 2.5 справляется с многоязычной речью?
Да. MiniMax Speech 2.5 поддерживает 40+ языков и достигает WER около 2% для китайского и английского. Он сохраняет идентичность голоса на разных языках за счет слоев межъязыкового переноса и сквозного обучения.
Novita AI — это универсальная облачная платформа, которая реализует ваши амбиции в области ИИ. Интегрированные API, бессерверные решения, GPU-инстансы — доступные инструменты, которые вам нужны. Избавьтесь от инфраструктуры, начните бесплатно и воплотите ваше видение ИИ в реальность.



