

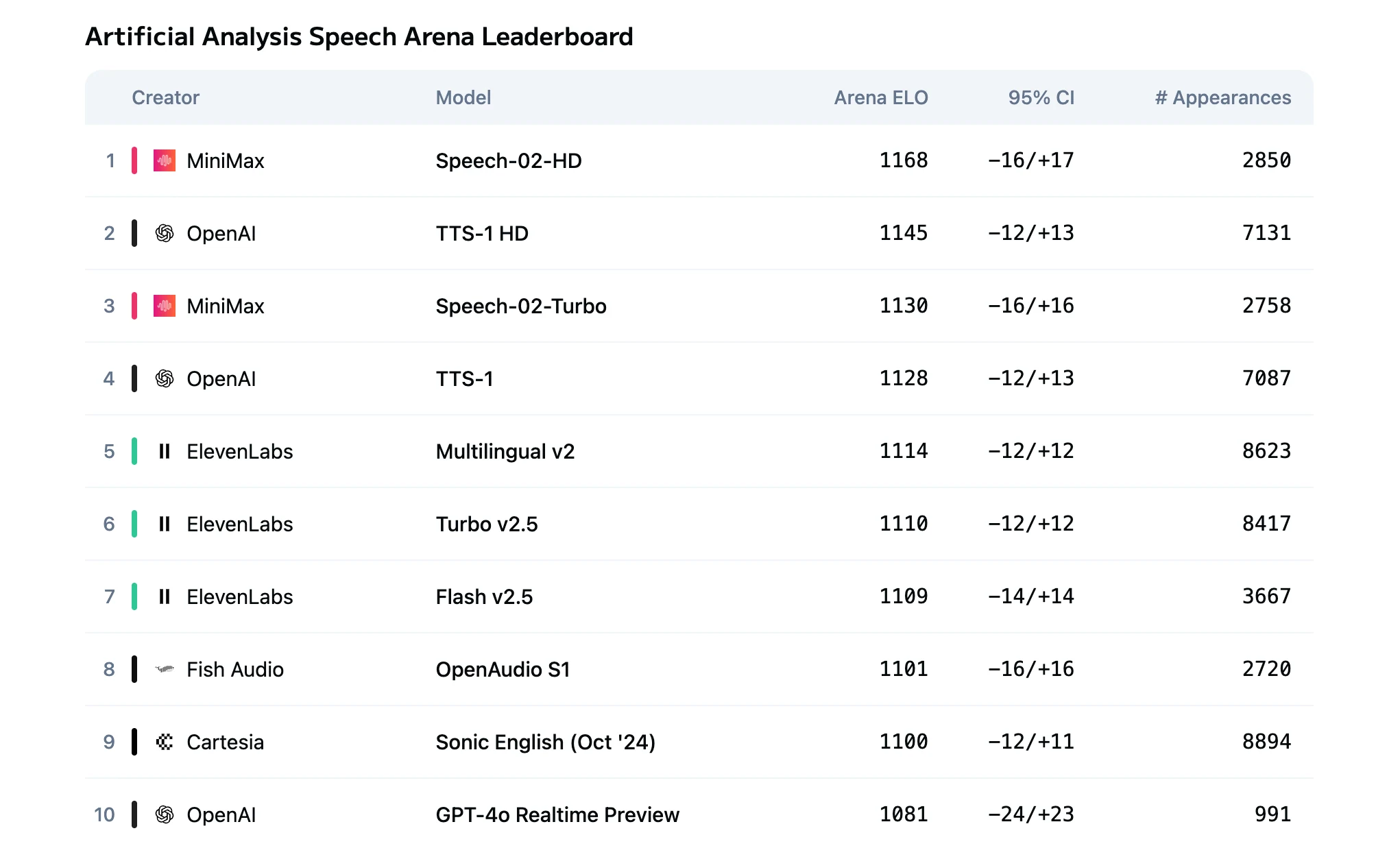
开发语音应用的工程师常面临响应慢、跨语言音频质量不一致、API 成本高以及情感语调或发音控制有限等问题——这些让实时交互和大规模生成变得难以可靠交付。
MiniMax Speech 2.5 正是针对这些瓶颈而设计。它支持仅需 6–10 秒音频的高精度语音克隆,覆盖 40 多种语言的多语言合成(中文和英文 WER 约 2%),Turbo 模式延迟接近 250 ms,适用于交互场景。长文本工作负载支持异步处理高达 200,000 字符,定价对开发者友好,每 1,000 字符仅 $0.04。凭借细粒度的情感控制和 SNR ≥ 3 dB 下的稳定表现,该模型为需要实时响应以及可扩展、经济高效的语音生成团队提供了实用方案。
Speech 2.5 Turbo 与 HD 的模型对比
Speech 2.5 HD 与 Turbo Preview 的根本区别在于质量与延迟的权衡:
| 指标 | HD | Turbo |
|---|---|---|
| 音频质量 | 工作室级真实感,最高保真度 | 高清画质,表现力略低 |
| TTS 延迟 | 数秒 | 端到端延迟低于 250 ms |
| 理想场景 | 高端内容生成 | 实时交互应用 |
| 成本 | $80/百万字符 | $48/百万字符 |
HD 提供更优的音色相似度、情感细腻度和自然韵律。
Turbo 优化了编码管线以实现极低延迟,适合实时交互。
Speech 2.5 能否仅用几秒音频复制任意声音?
MiniMax Speech 2.5 的 Flow-VAE 解码器将 Flow Matching 与变分自编码相结合,在学习的潜在空间中建模语音,而非仅依赖梅尔频谱图。这能捕捉音高、节奏、口音和情感色彩。
所需样本长度: 仅需 6–10 秒 即可实现高保真克隆,相似度高达 99%。
相似度指标: 在 24 种语言中,说话人相似度优于 ElevenLabs。
零样本克隆: 无需转录文本;通过学习的 说话人嵌入编码器 直接提取声音身份
Speech 2.5 能否在 40 多种语言中实现母语级发音?
多语言能力:
- 支持 40 多种语言
- 中文: 全球基准性能领先
- 英文: 相比 Speech 0.2 有重大升级,减少了机械感伪影
- 其他语言: 日语、法语、西班牙语等,发音自然地道
机制:
- 增强的说话人特征提取
- 跨语言迁移层保留音色
- 端到端训练确保跨语言保持声音身份
质量指标:
MiniMax 合成的中文和英文语音 WER 约为 2%,表明 ASR 几乎能完美识别所说的单词。
Speech 2.5 处理长文档或书籍的能力如何?
长文本延迟与吞吐量(Speech 2.5)
MiniMax Speech 2.5 在长输入上保持稳定表现,具备可量化的延迟与吞吐量优势:
• TTS 延迟:
对于多段落文本,音频播放通常在几秒内开始。更新的 2.5 音频管线最小化了启动延迟。在 Agent 场景中,后续世代系统可实现 250 ms 端到端延迟;Speech 2.5 在标准合成请求中仍处于低秒级范围。
• 长文本容量:
通过异步 TTS API 支持每次请求最多 10,000 字符。下载 URL 有效期为 9 小时,确保可靠获取。
- Turbo 模式: 延迟更低、吞吐量更高(保真度略有折衷)。
- HD 模式: 最大化音频质量。
可通过批量提交或异步任务进一步提升吞吐量,适合小时级转录或合成任务。
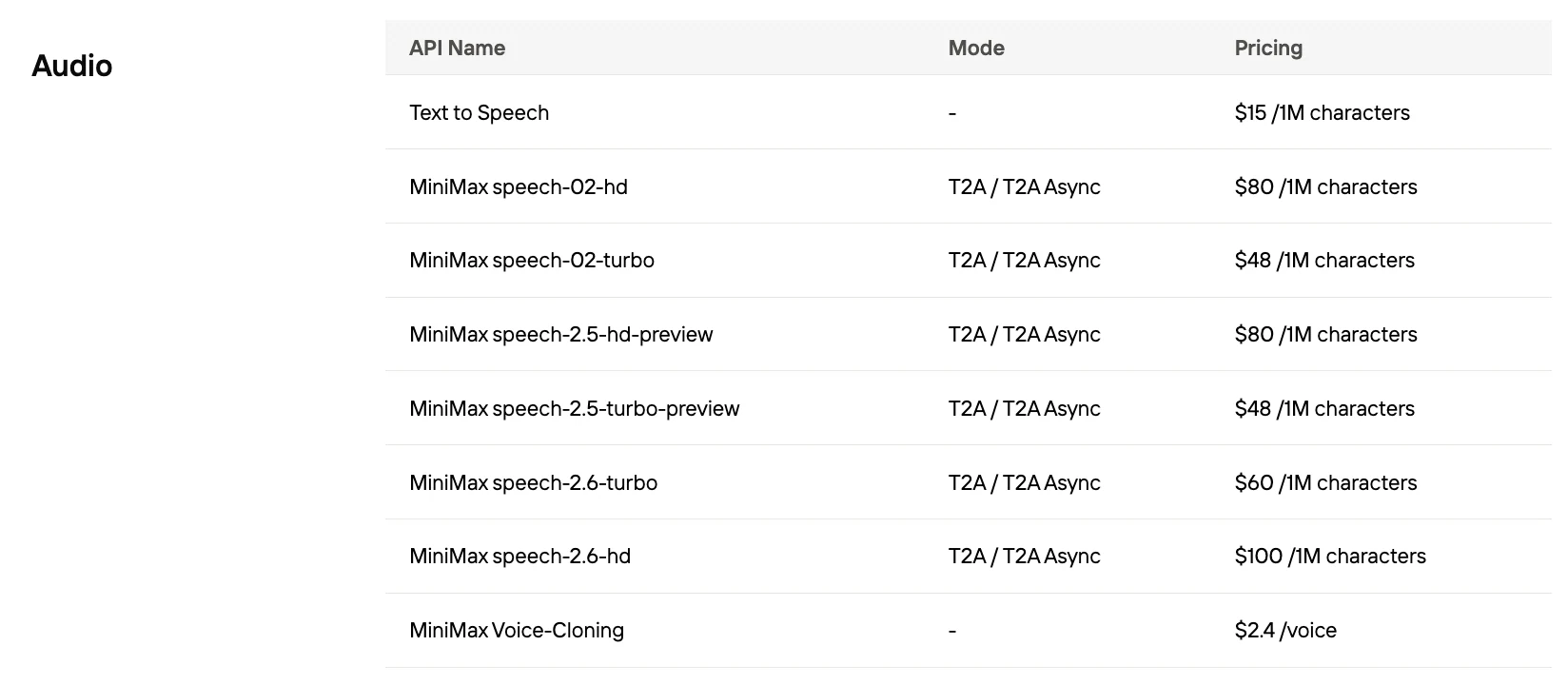
Speech 2.5 每 1,000 字符的成本
| 提供商 | 每千字符成本 |
|---|---|
| MiniMax Speech 2.5 Turbo | $0.048 |
| MiniMax Speech 2.5 HD | $0.08 |
| ElevenLabs | $0.24–0.30 |
| OpenAI GPT-4 Audio | 通常 >$0.10 |
| Google Gemini | TTS >$2.50/百万 token |
Novita AI 提供 MiniMax Speech 最优价格!
对发音、重音和停顿的控制有多精细?
| 控制能力 | API 字段 | 示例值 / 用法 |
|---|---|---|
| 自定义停顿 | text 使用 <#x#> |
Hello<#0.50#>world |
| 音素级发音(IPA / X-SAMPA) | pronunciation_dict |
"demo": {"type":"ipa","value":"ˈdɛmoʊ"} |
| 中文声调替换 | pronunciation_dict (type: "tone") |
"你好": {"type":"tone","value":"ni3 hao3"} |
| 语速 | voice_setting.speed |
1.05 |
| 音量 | voice_setting.vol |
1.2 |
| 音高(半音偏移) | voice_setting.pitch |
2 |
| 音色选择(音色 ID) | voice_setting.voice_id |
"Calm_Woman" |
| 情感 | voice_setting.emotion |
"neutral" |
| 英文文本归一化 | voice_setting.text_normalization |
true |
| 采样率 | audio_setting.sample_rate |
44100 |
| 比特率 | audio_setting.bitrate |
128000 |
| 音频格式 | audio_setting.format |
"mp3" |
| 通道数 | audio_setting.channel |
1 (mono) |
| 音色混合(最多 4 个声音) | timbre_weights |
[{"voice_id":"Calm_Woman","weight":70}] |
| 音频特效(混响、电话音、机器人音等) | voice_modify.sound_effects |
"spacious_echo" |
| 亮度音高调整 | voice_modify.pitch |
10 |
| 强度调整 | voice_modify.intensity |
-20 |
| 音色锐度/磁性 | voice_modify.timbre |
-15 |
| 流式模式 | stream |
false |
| 语言/方言增强 | language_boost |
"English" |
import requests
url = "https://api.novita.ai/v3/minimax-speech-2.5-hd-preview"
payload = {
"text": "Hello<#0.50#>this is a demo of fine-grained control.<#0.30#>\
Please read the number 2025 clearly.",
"voice_setting": {
"speed": 1.05,
"vol": 1.2,
"pitch": 2,
"voice_id": "Calm_Woman",
"emotion": "neutral",
"text_normalization": True
},
"audio_setting": {
"sample_rate": 44100,
"bitrate": 128000,
"format": "mp3",
"channel": 1
},
# Use the concrete pronunciation dictionary from your example
"pronunciation_dict": {
"demo": {
"type": "ipa",
"value": "ˈdɛmoʊ"
},
"2025": {
"type": "ipa",
"value": "tuː θaʊzənd twɛnti faɪv"
},
"你好": {
"type": "tone",
"value": "ni3 hao3"
}
},
"timbre_weights": [
{
"voice_id": "Calm_Woman",
"weight": 70
},
{
"voice_id": "Friendly_Person",
"weight": 30
}
],
"stream": False,
"language_boost": "English",
"output_format": "url",
"voice_modify": {
"pitch": 10,
"intensity": -20,
"timbre": -15,
"sound_effects": "spacious_echo"
}
}
headers = {
"Content-Type": "application/json",
"Authorization": "Bearer YOUR_API_KEY_HERE"
}
response = requests.post(url, json=payload, headers=headers)
print(response.text)
MiniMax Speech 2.5 是否支持流式?
是的。MiniMax Speech 2.5 同时支持语音识别(ASR) 和文本转语音(TTS) 的流式处理。API 明确包含字段:
"stream": true
在 TTS 请求中,系统会立即开始生成音频并按段发送,从而允许在完整句子合成之前开始播放。典型的 TTS 启动延迟在几秒内,优化场景下可实现亚秒级端到端响应时间。
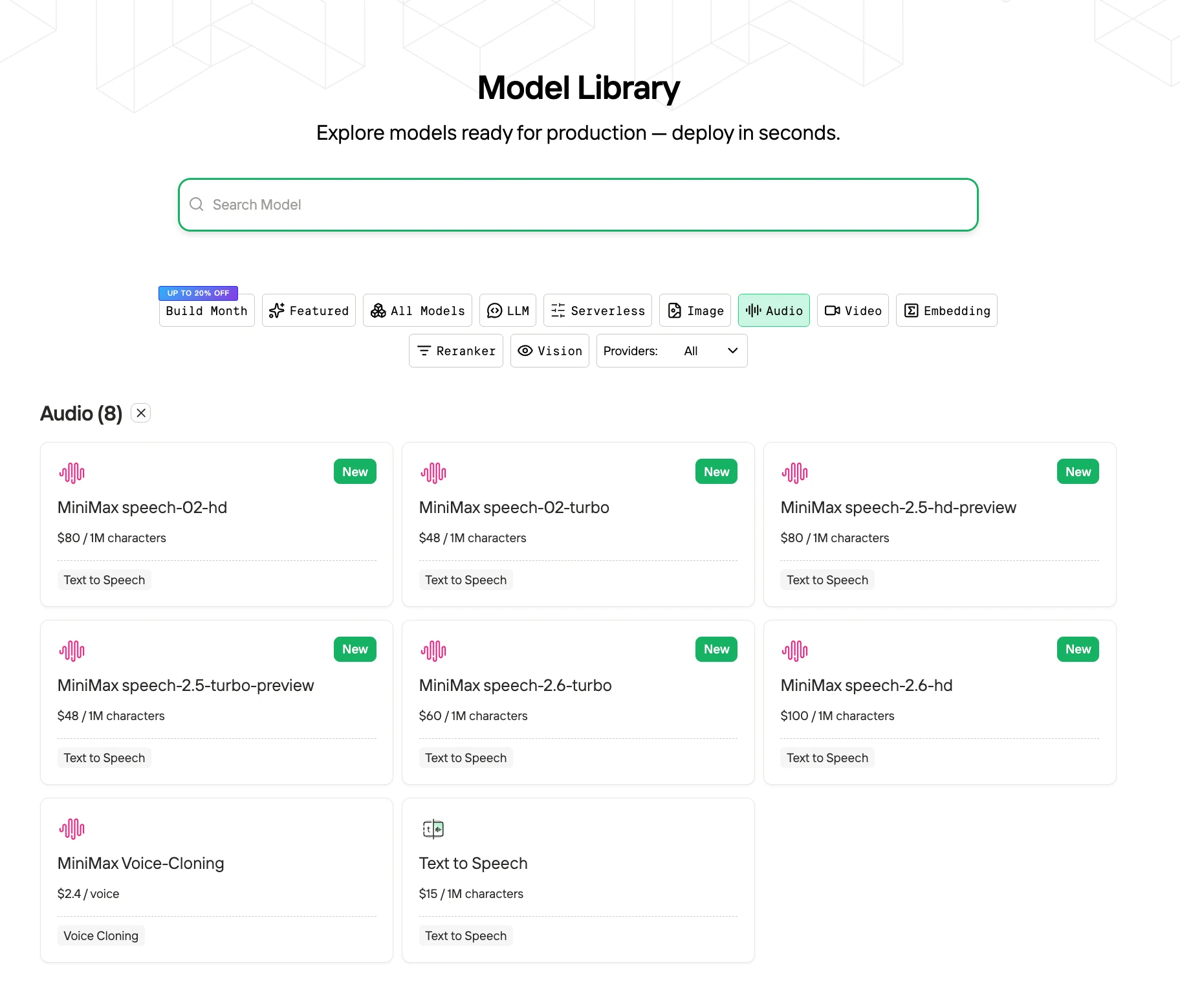
如何以优惠价格使用 MiniMax Speech 2.5?
步骤 1:登录并访问模型库
登录账户,点击模型库按钮。

步骤 2:选择模型
浏览可用选项,选择适合您需求的模型。
步骤 3:开始免费试用
开始免费试用,探索所选模型的能力。
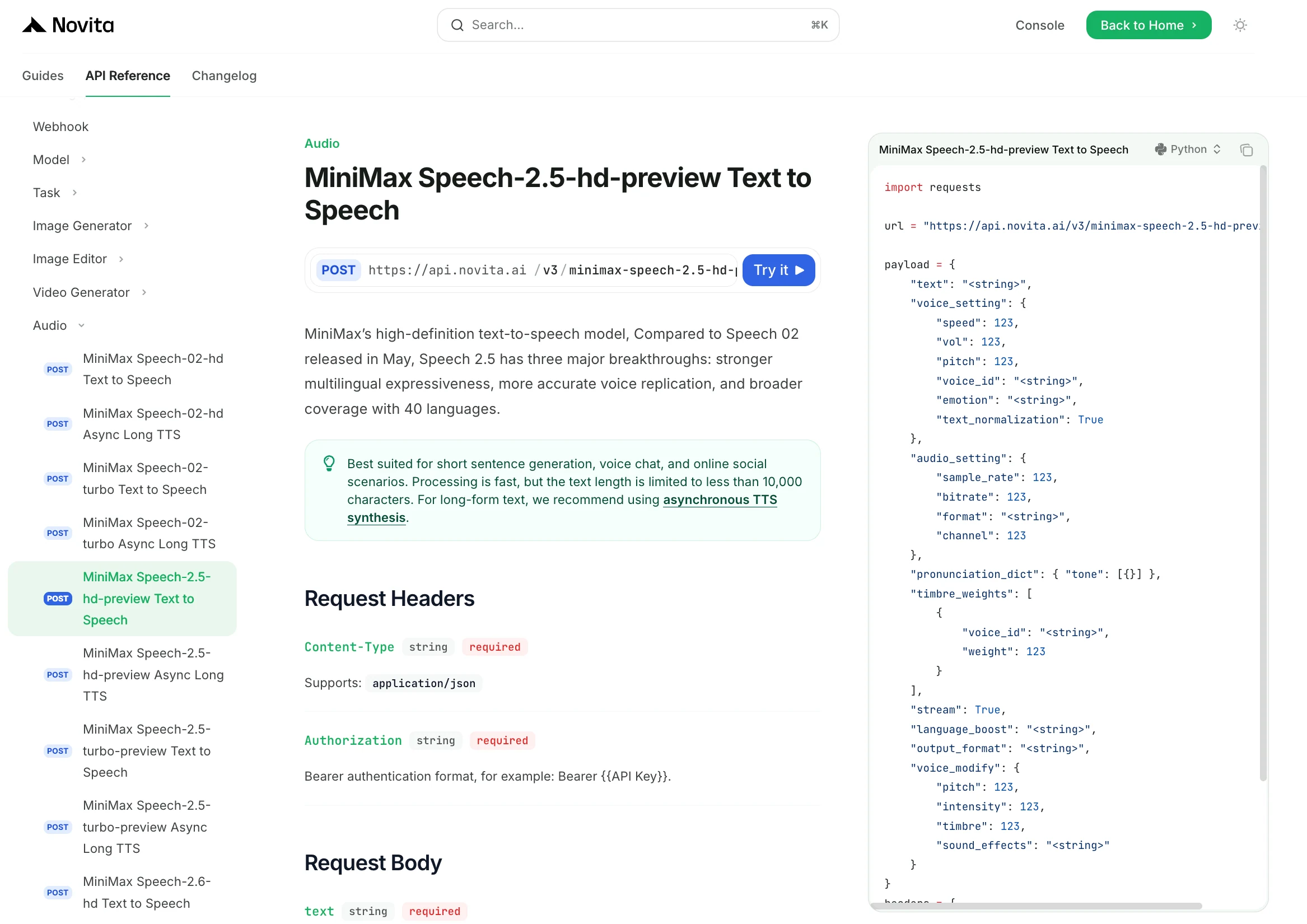
步骤 4:获取 API 密钥
为通过 API 进行身份验证,我们将为您提供新的 API 密钥。进入“设置”页面,可按图中所示复制 API 密钥。

MiniMax Speech 2.5 为现代语音应用开发中的核心问题提供了均衡、就绪的开发方案。它结合了快速响应时间、强大的多语言准确性、可靠的长文本处理能力,以及成本高效的定价和对情感语调、发音、音色的精细控制。通过针对不同延迟–质量需求优化的 Turbo 和 HD 模式,以及对流式的全面支持,MiniMax Speech 2.5 使团队能够构建可扩展的语音代理、实时转录系统和高品质内容管线,大幅降低技术限制。该模型的性能、灵活性和 API 设计使其成为寻求效率与表现力兼具的语音生成的开发者的实用选择。
常见问题
MiniMax Speech 2.5 支持流式吗?
是的。MiniMax Speech 2.5 同时支持 ASR 和 TTS 的流式处理。启用 "stream": true 后,系统可实时发送增量转录或音频块,实现亚秒级响应和自然的对话节奏。
MiniMax Speech 2.5 的语音克隆准确度如何?
MiniMax Speech 2.5 仅需 6–10 秒音频即可实现高保真语音克隆,相似度高达 99%,在多语言说话人相似度基准测试中优于多个商业替代方案。
MiniMax Speech 2.5 的多语言语音表现好吗?
是的。MiniMax Speech 2.5 支持 40 多种语言,中文和英文的 WER 约 2%。通过跨语言迁移层和端到端训练,能跨语言保持声音身份。
Novita AI 是一个一体化云平台,助力您的 AI 愿景。集成 API、无服务器、GPU 实例——您需要的经济高效工具。免除基础设施烦恼,免费开始,让您的 AI 梦想成真。



