

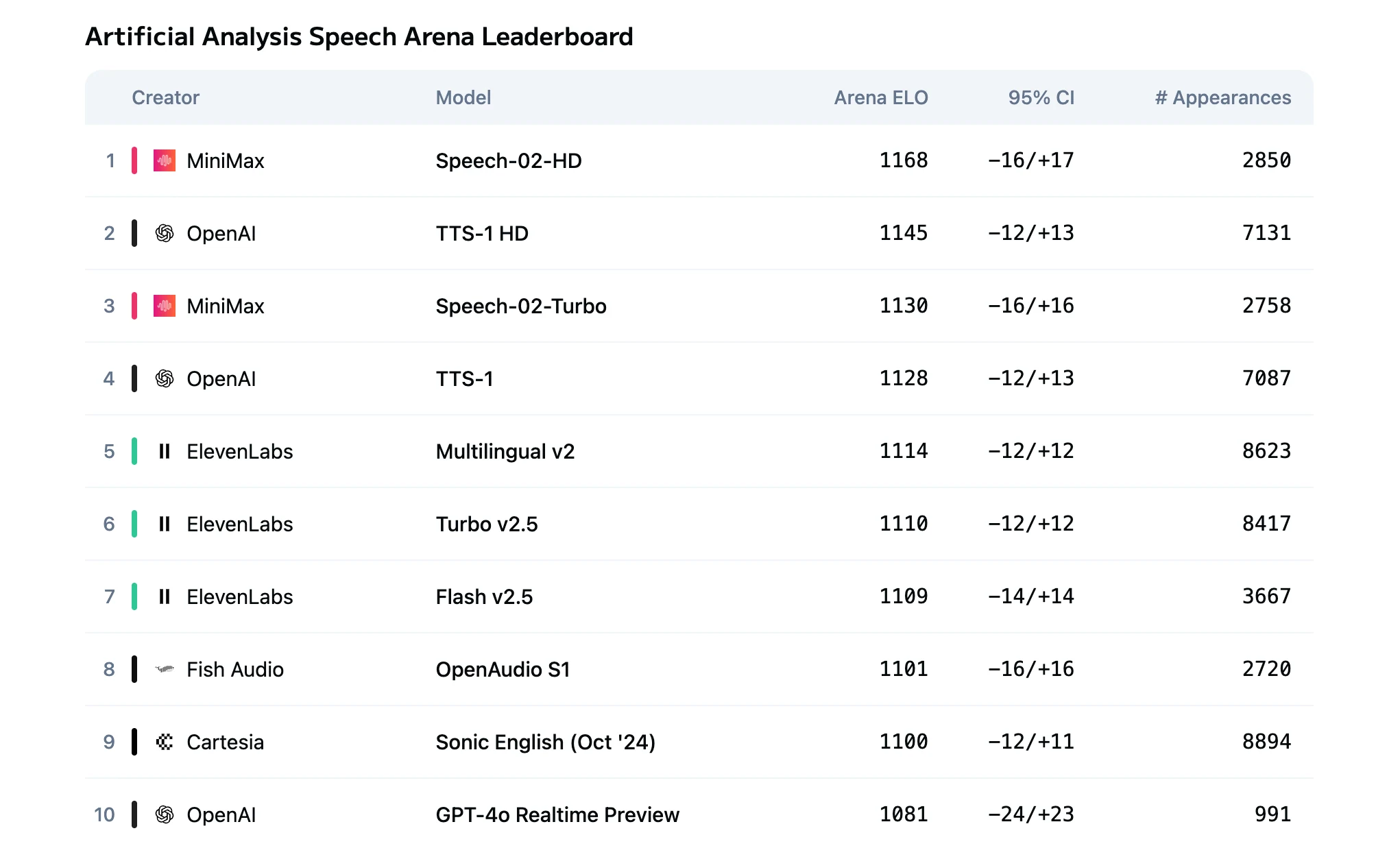
- Comparación de Modelos: Speech 2.5 Turbo y HD
- ¿Puede Speech 2.5 Replicar una Voz Arbitraria Usando Solo unos Segundos de Audio?
- ¿Ofrece Speech 2.5 una Pronunciación a Nivel Nativo en Más de 40 Idiomas?
- ¿Qué tan Bien Maneja Speech 2.5 Documentos Largos o Libros?
- ¿Cuál es el Costo por Cada 1 000 Caracteres de Speech 2.5?
- ¿Qué Tan Detallado es el Control sobre Pronunciación, Énfasis y Pausas?
- ¿Soporta MiniMax Speech 2.5 Streaming?
- Cómo Usar MiniMax Speech 2.5 a un Buen Precio?
Los desarrolladores que crean aplicaciones de voz a menudo enfrentan tiempos de respuesta lentos, calidad de audio inconsistente entre idiomas, altos costos de API y control limitado sobre el tono emocional o la pronunciación, problemas que dificultan la interacción en tiempo real y la generación a gran escala de manera confiable.
MiniMax Speech 2.5 está diseñado para abordar estas limitaciones directamente. Ofrece clonación de voz de alta precisión con solo 6–10 segundos de audio, síntesis multilingüe en más de 40 idiomas con un WER de aproximadamente el 2% en chino e inglés, y latencia en modo Turbo cercana a los 250 ms para uso interactivo. Las cargas de trabajo de formato largo se gestionan mediante procesamiento asíncrono de hasta 200 000 caracteres, mientras que los precios siguen siendo amigables para desarrolladores: $0.04 por cada 1 000 caracteres. Con control emocional detallado y rendimiento estable bajo SNR ≥ 3 dB, el modelo ofrece una solución práctica para equipos que necesitan tanto capacidad de respuesta en tiempo real como generación de voz escalable y rentable.
Comparación de Modelos: Speech 2.5 Turbo y HD
La diferencia fundamental entre Speech 2.5 HD y Turbo Preview radica en su equilibrio entre calidad y latencia:
| Métrica | HD | Turbo |
|---|---|---|
| Calidad de audio | Realismo de estudio con la más alta fidelidad | Calidad de alta definición con expresividad ligeramente menor |
| Latencia de TTS | Varios segundos | Latencia de extremo a extremo inferior a 250 ms |
| Escenario ideal | Generación de contenido de alta gama | Aplicaciones interactivas en tiempo real |
| Costo | $80/M caracteres | $48/M caracteres |
HD ofrece similitud de timbre superior, matices emocionales y prosodia natural.
Turbo optimiza el pipeline de codificación para lograr una latencia extremadamente baja, adecuada para la interacción en tiempo real.
¿Puede Speech 2.5 Replicar una Voz Arbitraria Usando Solo unos Segundos de Audio?
El decodificador Flow-VAE de MiniMax Speech 2.5 combina Flow Matching y Autoencoding Variacional para modelar el habla en un espacio latente aprendido, en lugar de depender únicamente de los mel-espectrogramas. Esto captura tono, ritmo, acento y color emocional.
Longitud de muestra requerida: Solo 6–10 segundos para una clonación de alta fidelidad, logrando hasta un 99% de similitud.
Métricas de similitud: Supera a ElevenLabs en similitud de locutor en 24 idiomas.
Clonación zero-shot: No se necesita transcripción; un codificador de embedding de locutor entrenado extrae la identidad vocal directamente.
¡Prueba MiniMax Speech 2.5 Ahora!
¿Ofrece Speech 2.5 una Pronunciación a Nivel Nativo en Más de 40 Idiomas?
Capacidad multilingüe:
- Soporta más de 40 idiomas
- Chino: Rendimiento de referencia global
- Inglés: Mejora importante respecto a Speech 0.2, con menos artefactos mecánicos
- Otros idiomas: Japonés, francés, español, etc., con pronunciación nativa natural
Mecanismos:
- Extracción mejorada de características del locutor
- Capas de transferencia entre idiomas que conservan el timbre
- Entrenamiento de extremo a extremo para mantener la identidad vocal en todos los idiomas
Métrica de calidad:
El habla sintetizada en inglés y chino con MiniMax tiene un WER de aproximadamente el 2%, lo que indica que las palabras habladas son entendidas casi perfectamente por un ASR.
¿Qué tan Bien Maneja Speech 2.5 Documentos Largos o Libros?
Latencia y rendimiento en formato largo (Speech 2.5)
MiniMax Speech 2.5 mantiene un rendimiento estable en entradas largas con ventajas cuantificables de latencia y rendimiento:
• Latencia de TTS:
La reproducción de audio generalmente comienza en unos pocos segundos, incluso para texto de varios párrafos. El pipeline de audio actualizado 2.5 minimiza el retardo de inicio. Los sistemas de generaciones posteriores logran una latencia de extremo a extremo de 250 ms en entornos de agente; Speech 2.5 permanece en el rango de unos pocos segundos para solicitudes de síntesis estándar.
• Capacidad de texto largo:
Soporta hasta 10 000 caracteres por solicitud a través de la API asíncrona de TTS. Las URLs de descarga permanecen válidas durante 9 horas, lo que garantiza una recuperación confiable.
- Modo Turbo: menor latencia y mayor rendimiento (con compromisos moderados de fidelidad).
- Modo HD: máxima calidad de audio.
El rendimiento se puede aumentar aún más mediante el envío por lotes o trabajos asíncronos, adecuado para cargas de trabajo como transcripción o síntesis de horas de duración.
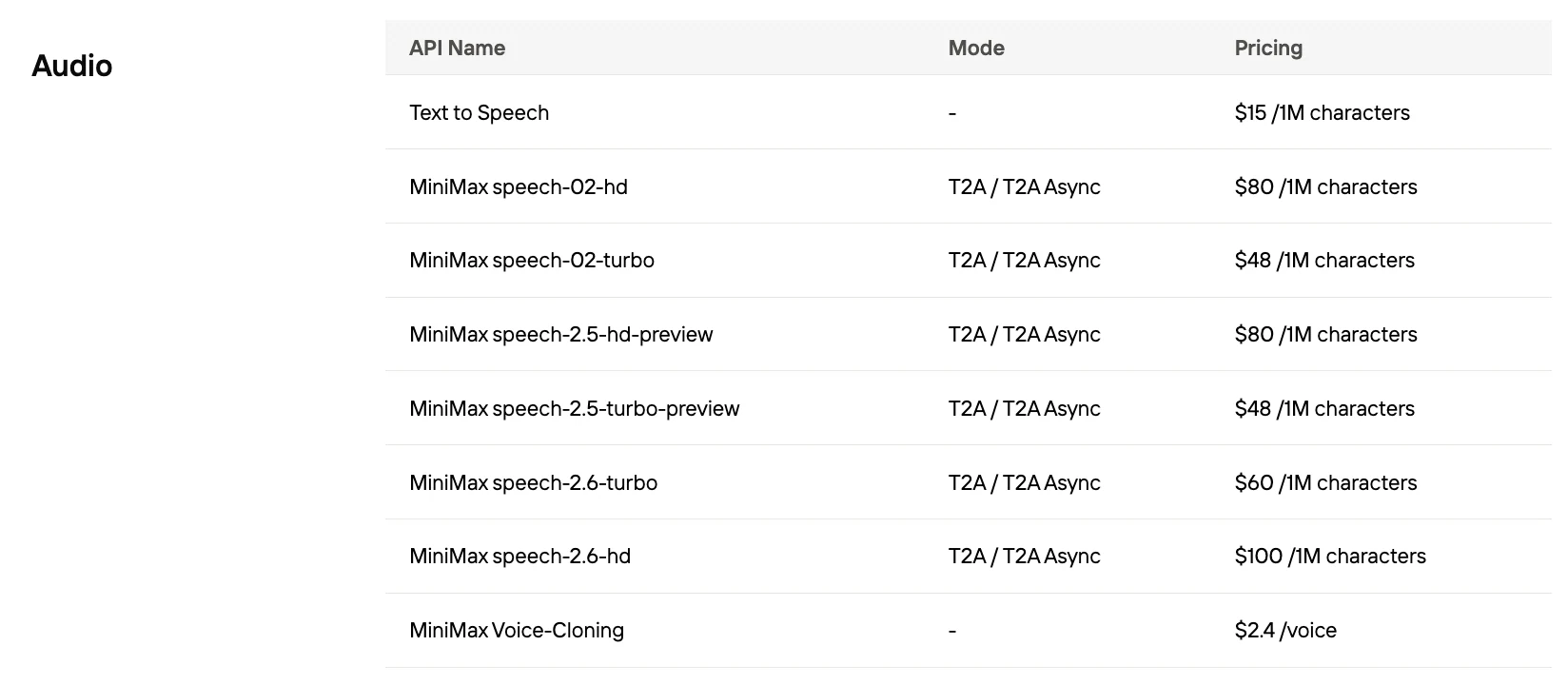
¿Cuál es el Costo por Cada 1 000 Caracteres de Speech 2.5?
| Proveedor | Costo / 1K caracteres |
|---|---|
| MiniMax Speech 2.5 Turbo | $0.048 |
| MiniMax Speech 2.5 HD | $0.08 |
| ElevenLabs | $0.24–0.30 |
| OpenAI GPT-4 Audio | Generalmente >$0.10 |
| Google Gemini | TTS >$2.50 por 1M tokens |
¡Novita AI ofrece el mejor precio de Minimax Speech!
¡Prueba MiniMax Speech 2.5 Ahora!
¿Qué Tan Detallado es el Control sobre Pronunciación, Énfasis y Pausas?
| Capacidad de control | Campo de API | Ejemplo de valor / Uso |
|---|---|---|
| Pausas personalizadas | text usando <#x#> |
Hello<#0.50#>world |
| Pronunciación a nivel de fonema (IPA / X-SAMPA) | pronunciation_dict |
"demo": {"type":"ipa","value":"ˈdɛmoʊ"} |
| Reemplazo de tono en chino | pronunciation_dict (type: "tone") |
"你好": {"type":"tone","value":"ni3 hao3"} |
| Velocidad del habla | voice_setting.speed |
1.05 |
| Volumen | voice_setting.vol |
1.2 |
| Tono (desplazamiento en semitonos) | voice_setting.pitch |
2 |
| Selección de voz (ID de timbre) | voice_setting.voice_id |
"Calm_Woman" |
| Emoción | voice_setting.emotion |
"neutral" |
| Normalización de texto en inglés | voice_setting.text_normalization |
true |
| Frecuencia de muestreo | audio_setting.sample_rate |
44100 |
| Tasa de bits | audio_setting.bitrate |
128000 |
| Formato de audio | audio_setting.format |
"mp3" |
| Canales | audio_setting.channel |
1 (mono) |
| Mezcla de timbres (hasta 4 voces) | timbre_weights |
[{"voice_id":"Calm_Woman","weight":70}] |
| Efectos de audio (reverberación, teléfono, robótico, etc.) | voice_modify.sound_effects |
"spacious_echo" |
| Ajuste de brillo/tono | voice_modify.pitch |
10 |
| Ajuste de intensidad | voice_modify.intensity |
-20 |
| Nitidez / magnetismo del timbre | voice_modify.timbre |
-15 |
| Modo streaming | stream |
false |
| Refuerzo de idioma/dialecto | language_boost |
"English" |
import requests
url = "https://api.novita.ai/v3/minimax-speech-2.5-hd-preview"
payload = {
"text": "Hello<#0.50#>this is a demo of fine-grained control.<#0.30#>\
Please read the number 2025 clearly.",
"voice_setting": {
"speed": 1.05,
"vol": 1.2,
"pitch": 2,
"voice_id": "Calm_Woman",
"emotion": "neutral",
"text_normalization": True
},
"audio_setting": {
"sample_rate": 44100,
"bitrate": 128000,
"format": "mp3",
"channel": 1
},
# Use the concrete pronunciation dictionary from your example
"pronunciation_dict": {
"demo": {
"type": "ipa",
"value": "ˈdɛmoʊ"
},
"2025": {
"type": "ipa",
"value": "tuː θaʊzənd twɛnti faɪv"
},
"你好": {
"type": "tone",
"value": "ni3 hao3"
}
},
"timbre_weights": [
{
"voice_id": "Calm_Woman",
"weight": 70
},
{
"voice_id": "Friendly_Person",
"weight": 30
}
],
"stream": False,
"language_boost": "English",
"output_format": "url",
"voice_modify": {
"pitch": 10,
"intensity": -20,
"timbre": -15,
"sound_effects": "spacious_echo"
}
}
headers = {
"Content-Type": "application/json",
"Authorization": "Bearer YOUR_API_KEY_HERE"
}
response = requests.post(url, json=payload, headers=headers)
print(response.text)
¡Prueba MiniMax Speech 2.5 Ahora!
¿Soporta MiniMax Speech 2.5 Streaming?
Sí. MiniMax Speech 2.5 admite streaming tanto para reconocimiento de voz (ASR) como para texto a voz (TTS). La API incluye explícitamente el campo:
"stream": true
en una solicitud de TTS, el sistema comienza a generar audio inmediatamente y lo envía en segmentos. Esto permite que la reproducción comience antes de que se sintetice la frase completa. La latencia típica de inicio de TTS es de unos pocos segundos, y en escenarios optimizados puede alcanzar tiempos de respuesta de extremo a extremo inferiores a un segundo.
Cómo Usar MiniMax Speech 2.5 a un Buen Precio?
Paso 1: Inicia Sesión y Accede a la Biblioteca de Modelos
Inicia sesión en tu cuenta y haz clic en el botón Model Library.

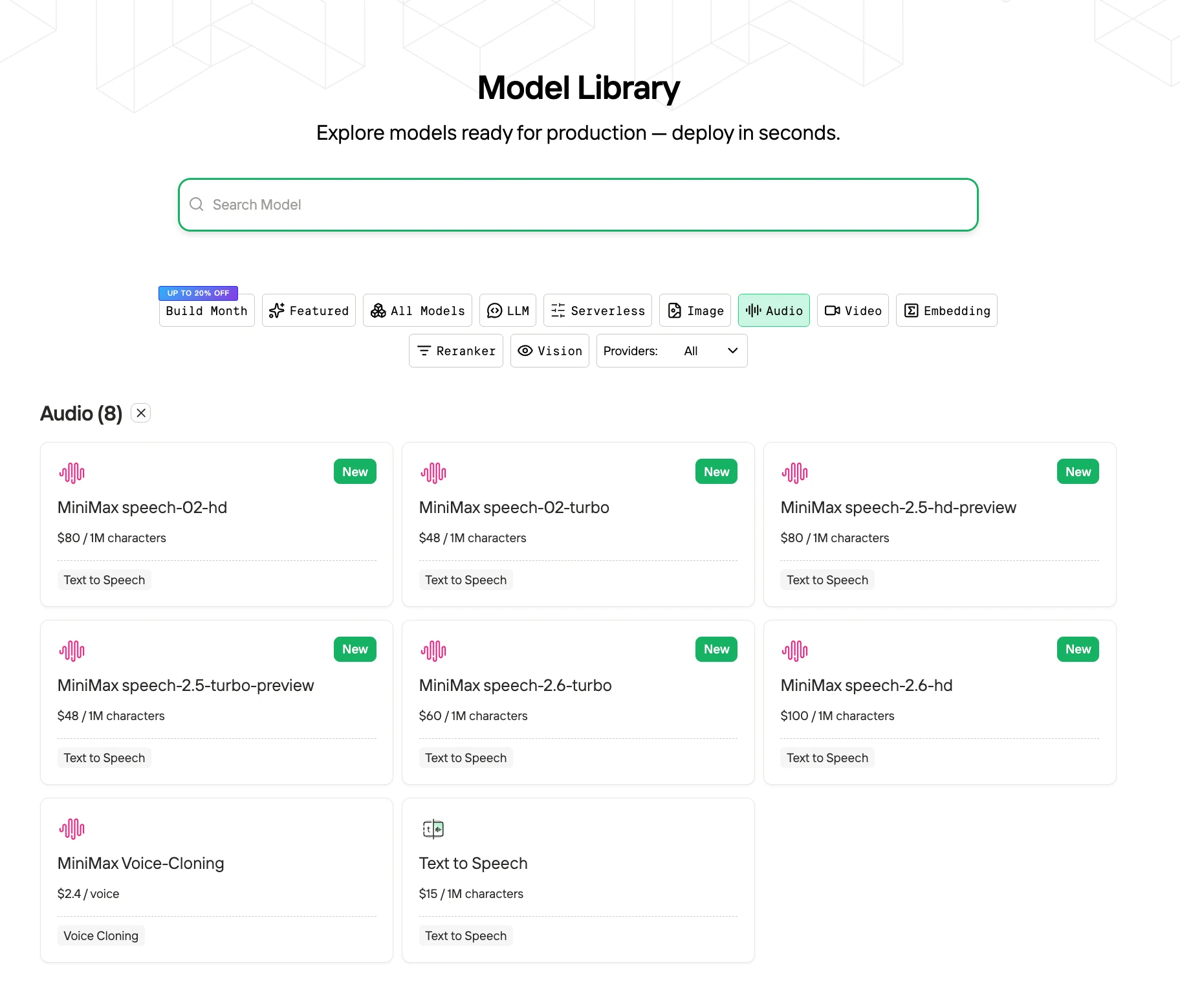
Paso 2: Elige tu Modelo
Navega por las opciones disponibles y selecciona el modelo que se adapte a tus necesidades.
¡Prueba MiniMax Speech 2.5 Ahora!
Paso 3: Comienza tu Prueba Gratuita
Inicia tu prueba gratuita para explorar las capacidades del modelo seleccionado.
Paso 4: Obtén tu Clave de API
Para autenticarte con la API, te proporcionaremos una nueva clave de API. Ingresa a la página “Configuración” y copia la clave de API como se indica en la imagen.

MiniMax Speech 2.5 ofrece una solución equilibrada y lista para el desarrollador para los problemas centrales en el desarrollo moderno de aplicaciones de voz. Combina tiempos de respuesta rápidos, fuerte precisión multilingüe y procesamiento confiable de texto largo con precios rentables y control detallado sobre el tono emocional, la pronunciación y el timbre. Con los modos Turbo y HD optimizados para diferentes necesidades de latencia y calidad, y con soporte completo para streaming, MiniMax Speech 2.5 permite a los equipos construir agentes de voz escalables, sistemas de transcripción en tiempo real y pipelines de contenido de alta calidad con muchas menos limitaciones técnicas. El rendimiento, la flexibilidad y el diseño de la API del modelo lo convierten en una opción práctica para los desarrolladores que buscan tanto eficiencia como generación de voz expresiva.
Preguntas Frecuentes
¿Soporta MiniMax Speech 2.5 streaming?
Sí. MiniMax Speech 2.5 admite streaming tanto para ASR como para TTS. Habilitar "stream": true permite que el sistema envíe transcripciones incrementales o fragmentos de audio en tiempo real, logrando tiempos de respuesta inferiores a un segundo y un ritmo conversacional natural.
¿Qué tan precisa es la clonación de voz en MiniMax Speech 2.5?
MiniMax Speech 2.5 logra una clonación de voz de alta fidelidad con solo 6–10 segundos de audio, alcanzando hasta un 99% de similitud y superando a varios competidores comerciales en benchmarks de similitud de locutor multilingüe.
¿MiniMax Speech 2.5 maneja bien el habla multilingüe?
Sí. MiniMax Speech 2.5 soporta más de 40 idiomas y alcanza un WER de aproximadamente el 2% para chino e inglés. Mantiene la identidad vocal entre idiomas mediante capas de transferencia entre idiomas y entrenamiento de extremo a extremo.
Novita AI es la plataforma integral en la nube que impulsa tus ambiciones de IA. APIs integradas, sin servidor, instancias GPU: las herramientas rentables que necesitas. Elimina la infraestructura, comienza gratis y haz realidad tu visión de IA.



