

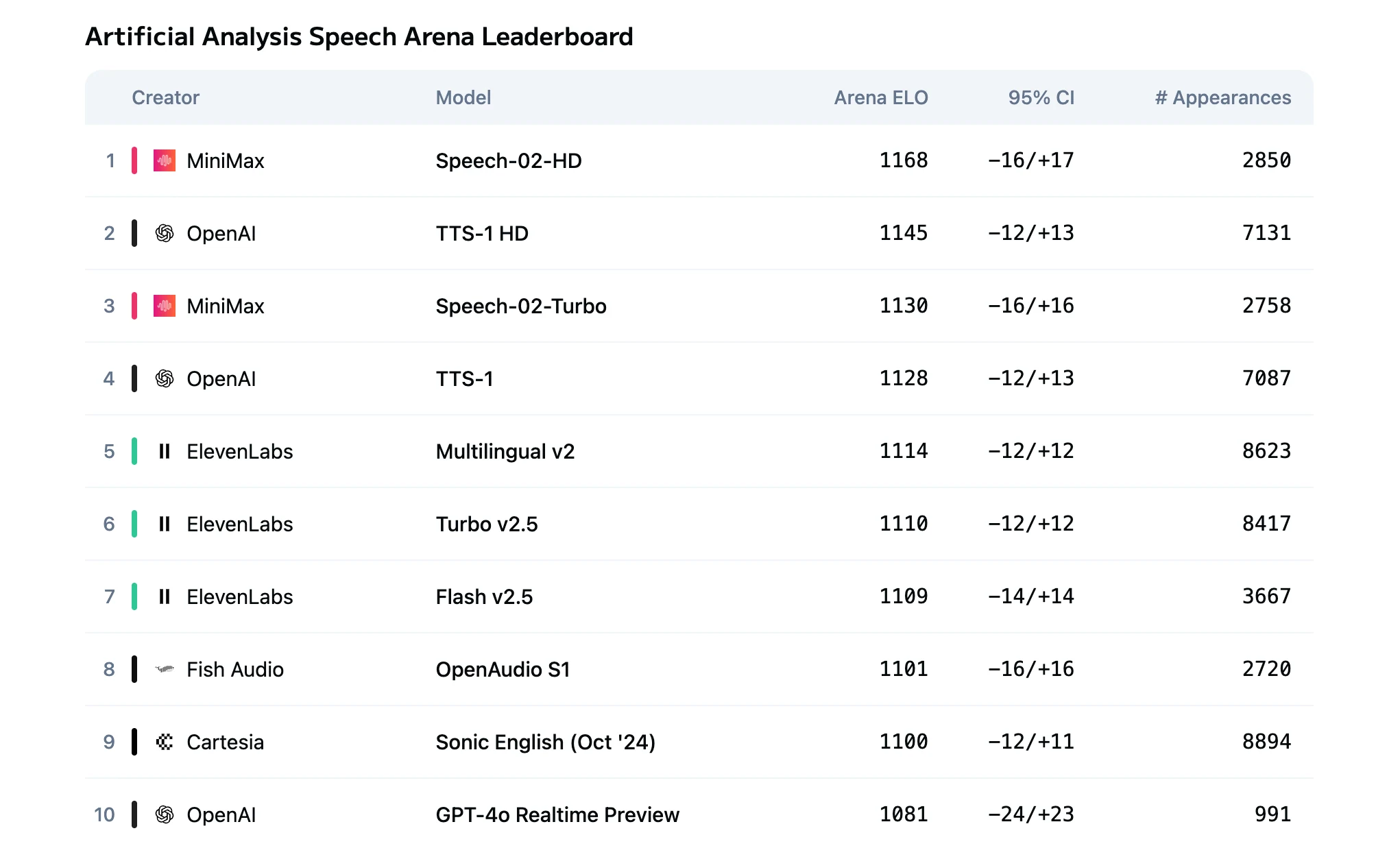
음성 애플리케이션을 개발하는 개발자들은 느린 응답 시간, 언어 간 일관되지 않은 오디오 품질, 높은 API 비용, 감정 톤이나 발음에 대한 제한된 제어와 같은 문제로 어려움을 겪는 경우가 많습니다. 이러한 문제들은 실시간 상호작용과 대규모 생성을 안정적으로 제공하기 어렵게 만듭니다.
MiniMax Speech 2.5는 이러한 제약을 직접 해결하도록 설계되었습니다. 6~10초의 오디오만으로 고정밀 음성 복제, 40개 이상의 언어에 대한 다국어 합성(중국어 및 영어에서 약 2% WER), 그리고 대화형 사용을 위한 250ms에 가까운 Turbo 모드 지연 시간을 제공합니다. 긴 문서 작업은 최대 200,000자 비동기 처리를 통해 지원되며, 가격은 개발자 친화적인 1,000자당 $0.04입니다. 세분화된 감정 제어와 SNR ≥ 3dB에서 안정적인 성능을 갖춘 이 모델은 실시간 응답성과 확장 가능한 비용 효율적인 음성 생성이 모두 필요한 팀에게 실용적인 솔루션을 제공합니다.
Speech 2.5 Turbo 및 HD 모델 비교
Speech 2.5 HD와 Turbo Preview의 근본적인 차이는 품질과 지연 시간 간의 트레이드오프에 있습니다:
| 지표 | HD | Turbo |
|---|---|---|
| 오디오 품질 | 스튜디오급 현실감, 최고 충실도 | 약간 덜 표현력 있지만 고음질 |
| TTS 지연 시간 | 수 초 | 250ms 미만 종단 간 지연 |
| 이상적인 시나리오 | 고급 콘텐츠 생성 | 실시간 대화형 애플리케이션 |
| 비용 | $80/백만 자 | $48/백만 자 |
HD는 우수한 음색 유사성, 감정적 뉘앙스, 자연스러운 운율을 제공합니다. Turbo는 인코딩 파이프라인을 최적화하여 실시간 상호작용에 적합한 매우 낮은 지연 시간을 달성합니다.
Speech 2.5가 단 몇 초의 오디오로 임의의 음성을 복제할 수 있나요?
MiniMax Speech 2.5의 Flow-VAE 디코더는 Flow Matching과 Variational Autoencoding을 결합하여 멜-스펙트로그램에만 의존하지 않고 학습된 잠재 공간에서 음성을 모델링합니다. 이를 통해 피치, 리듬, 악센트 및 감정적 색상을 포착합니다.
필요한 샘플 길이: 고충실도 복제를 위해 6~10초 만 필요, 최대 99% 유사도 달성.
유사도 지표: 24개 언어에서 스피커 유사도에서 ElevenLabs를 능가합니다.
제로샷 복제: 대본이 필요 없음; 학습된 스피커 임베딩 인코더가 음성 ID를 직접 추출합니다.
Speech 2.5가 40개 이상의 언어에서 원어민 수준의 발음을 제공하나요?
다국어 능력:
- 40개 이상의 언어 지원
- 중국어: 글로벌 벤치마크 성능
- 영어: 기계적 인공물이 줄어든 Speech 0.2 대비 주요 업그레이드
- 기타 언어: 일본어, 프랑스어, 스페인어 등 자연스러운 원어민 발음 제공
메커니즘:
- 향상된 스피커 특징 추출
- 음색을 유지하는 교차 언어 전송 레이어
- 언어 간 음성 ID 유지를 위한 종단 간 학습
품질 지표: MiniMax에서 합성된 영어 및 중국어 음성의 WER은 약 2%로, ASR이 음성을 거의 완벽하게 이해함을 나타냅니다.
Speech 2.5는 긴 문서나 책을 얼마나 잘 처리하나요?
긴 문서 지연 시간 및 처리량 (Speech 2.5)
MiniMax Speech 2.5는 긴 입력에서도 정량화 가능한 지연 시간 및 처리량 이점을 통해 안정적인 성능을 유지합니다:
• TTS 지연 시간: 여러 문단의 텍스트에서도 오디오 재생이 일반적으로 몇 초 내에 시작됩니다. 업데이트된 2.5 오디오 파이프라인은 시작 지연 시간을 최소화합니다. 후세대 시스템은 에이전트 설정에서 250ms 종단 간 지연 시간을 달성합니다; Speech 2.5는 표준 합성 요청에서 낮은 초 범위를 유지합니다.
• 긴 텍스트 용량: 비동기 TTS API를 통해 요청당 최대 10,000자 지원. 다운로드 URL은 9시간 동안 유효하여 안정적인 검색을 보장합니다.
- Turbo 모드: 더 낮은 지연 시간과 더 높은 처리량 (적당한 충실도 트레이드오프).
- HD 모드: 최대 오디오 품질. 배치 제출 또는 비동기 작업을 통해 처리량을 더욱 높일 수 있어, 1시간 분량의 전사 또는 합성 작업에 적합합니다.
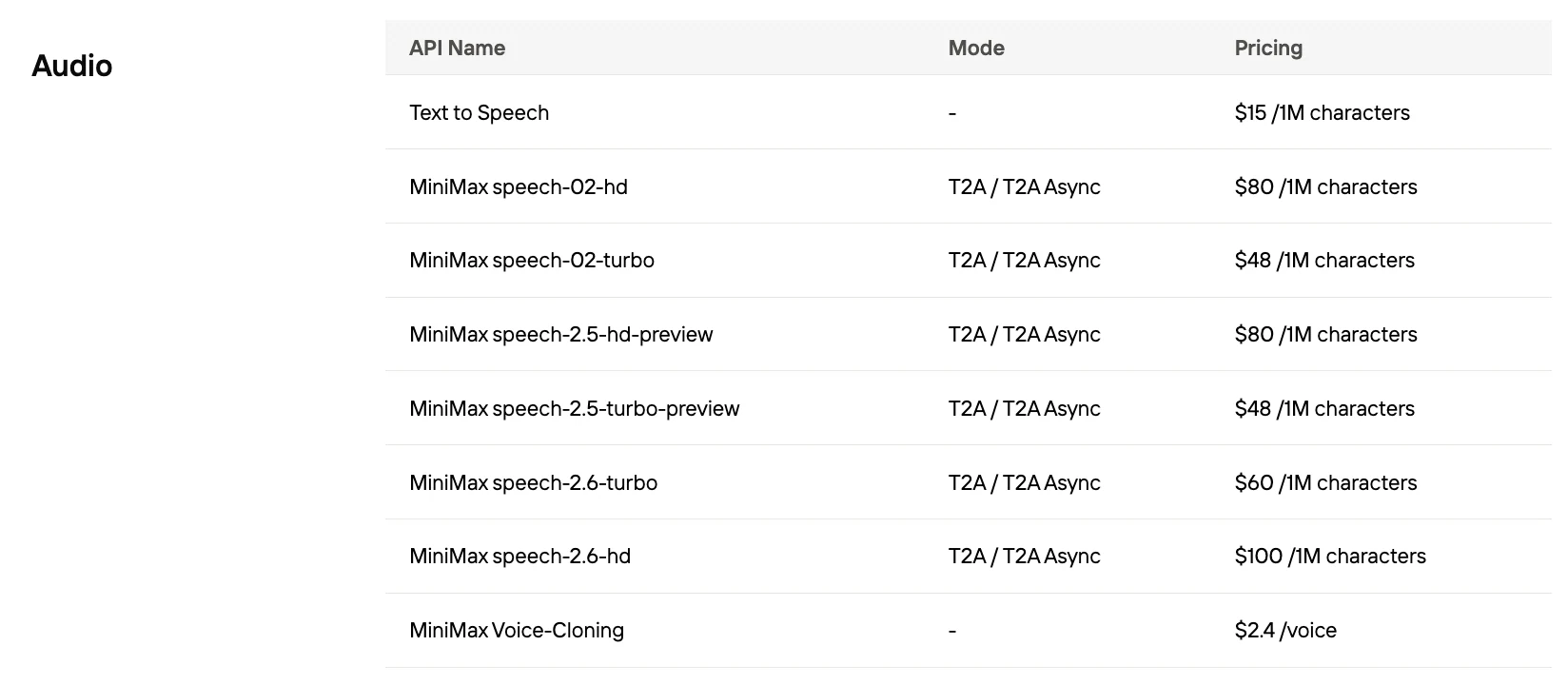
Speech 2.5의 1,000자당 비용은 얼마인가요?
| 제공자 | 1,000자당 비용 |
|---|---|
| MiniMax Speech 2.5 Turbo | $0.048 |
| MiniMax Speech 2.5 HD | $0.08 |
| ElevenLabs | $0.24–$0.30 |
| OpenAI GPT-4 Audio | 일반적으로 >$0.10 |
| Google Gemini | TTS >1M 토큰당 $2.50 |
Novita AI가 MiniMax의 최고 가격을 제공합니다!
발음, 강조 및 일시 중지 제어는 얼마나 세분화되어 있나요?
| 제어 기능 | API 필드 | 예시 값 / 사용법 |
|---|---|---|
| 사용자 정의 일시 중지 | <#x#>를 사용한 text |
Hello<#0.50#>world |
| 음소 수준 발음 (IPA / X-SAMPA) | pronunciation_dict |
"demo": {"type":"ipa","value":"ˈdɛmoʊ"} |
| 중국어 성조 대체 | pronunciation_dict (type: "tone") |
"你好": {"type":"tone","value":"ni3 hao3"} |
| 말하기 속도 | voice_setting.speed |
1.05 |
| 볼륨 | voice_setting.vol |
1.2 |
| 피치 (반음 이동) | voice_setting.pitch |
2 |
| 음성 선택 (음색 ID) | voice_setting.voice_id |
"Calm_Woman" |
| 감정 | voice_setting.emotion |
"neutral" |
| 영어 텍스트 정규화 | voice_setting.text_normalization |
true |
| 샘플 레이트 | audio_setting.sample_rate |
44100 |
| 비트레이트 | audio_setting.bitrate |
128000 |
| 오디오 포맷 | audio_setting.format |
"mp3" |
| 채널 | audio_setting.channel |
1 (모노) |
| 음색 혼합 (최대 4개 음성) | timbre_weights |
[{"voice_id":"Calm_Woman","weight":70}] |
| 오디오 효과 (리버브, 전화기, 로봇 등) | voice_modify.sound_effects |
"spacious_echo" |
| 밝기 피치 조정 | voice_modify.pitch |
10 |
| 강도 조정 | voice_modify.intensity |
-20 |
| 음색 선명도/매력 | voice_modify.timbre |
-15 |
| 스트리밍 모드 | stream |
false |
| 언어/방언 부스트 | language_boost |
"English" |
import requests
url = "https://api.novita.ai/v3/minimax-speech-2.5-hd-preview"
payload = {
"text": "Hello<#0.50#>this is a demo of fine-grained control.<#0.30#>\
Please read the number 2025 clearly.",
"voice_setting": {
"speed": 1.05,
"vol": 1.2,
"pitch": 2,
"voice_id": "Calm_Woman",
"emotion": "neutral",
"text_normalization": True
},
"audio_setting": {
"sample_rate": 44100,
"bitrate": 128000,
"format": "mp3",
"channel": 1
},
# Use the concrete pronunciation dictionary from your example
"pronunciation_dict": {
"demo": {
"type": "ipa",
"value": "ˈdɛmoʊ"
},
"2025": {
"type": "ipa",
"value": "tuː θaʊzənd twɛnti faɪv"
},
"你好": {
"type": "tone",
"value": "ni3 hao3"
}
},
"timbre_weights": [
{
"voice_id": "Calm_Woman",
"weight": 70
},
{
"voice_id": "Friendly_Person",
"weight": 30
}
],
"stream": False,
"language_boost": "English",
"output_format": "url",
"voice_modify": {
"pitch": 10,
"intensity": -20,
"timbre": -15,
"sound_effects": "spacious_echo"
}
}
headers = {
"Content-Type": "application/json",
"Authorization": "Bearer YOUR_API_KEY_HERE"
}
response = requests.post(url, json=payload, headers=headers)
print(response.text)
MiniMax Speech 2.5는 스트리밍을 지원하나요?
예. MiniMax Speech 2.5는 **음성 인식(ASR)**과 텍스트 음성 변환(TTS) 모두에 대해 스트리밍을 지원합니다. API에는 명시적으로 다음 필드가 포함되어 있습니다.
"stream": true
TTS 요청에서 이 필드를 설정하면 시스템이 오디오를 즉시 생성하여 세그먼트로 다시 보냅니다. 이를 통해 전체 문장이 합성되기 전에 재생을 시작할 수 있습니다. 일반적인 TTS 시작 지연 시간은 몇 초 이내이며, 최적화된 시나리오에서는 1초 미만의 종단 간 응답 시간을 달성할 수 있습니다.
좋은 가격에 MiniMax Speech 2.5를 사용하는 방법
1단계: 로그인 및 모델 라이브러리 액세스
계정에 로그인하고 모델 라이브러리 버튼을 클릭하세요.

2단계: 모델 선택
사용 가능한 옵션을 살펴보고 필요에 맞는 모델을 선택하세요.
3단계: 무료 평가판 시작
선택한 모델의 기능을 살펴보려면 무료 평가판을 시작하세요.
4단계: API 키 받기
API에 인증하려면 새 API 키를 제공해 드립니다. “설정“ 페이지로 이동하여 이미지에 표시된 대로 API 키를 복사하세요.

MiniMax Speech 2.5는 현대 음성 애플리케이션 개발의 핵심 문제에 대한 균형 잡히고 개발자 친화적인 솔루션을 제공합니다. 빠른 응답 시간, 강력한 다국어 정확도, 안정적인 긴 텍스트 처리, 비용 효율적인 가격, 그리고 감정 톤, 발음, 음색에 대한 세밀한 제어를 결합합니다. 다양한 지연 시간-품질 요구에 최적화된 Turbo 및 HD 모드와 스트리밍에 대한 완전한 지원을 통해 MiniMax Speech 2.5는 팀이 훨씬 적은 기술적 제약으로 확장 가능한 음성 에이전트, 실시간 전사 시스템 및 고품질 콘텐츠 파이프라인을 구축할 수 있도록 합니다. 이 모델의 성능, 유연성 및 API 설계는 효율성과 표현력 있는 음성 생성을 모두 추구하는 개발자에게 실용적인 선택입니다.
자주 묻는 질문
MiniMax Speech 2.5가 스트리밍을 지원하나요?
예. MiniMax Speech 2.5는 ASR과 TTS 모두에 대해 스트리밍을 지원합니다. "stream": true를 활성화하면 시스템이 증분 전사 또는 오디오 청크를 실시간으로 전송하여 1초 미만의 응답 시간과 자연스러운 대화 타이밍을 가능하게 합니다.
MiniMax Speech 2.5에서 음성 복제는 얼마나 정확한가요?
MiniMax Speech 2.5는 6~10초의 오디오만으로 최대 99% 유사도의 고충실도 음성 복제를 달성하며, 다국어 스피커 유사도 벤치마크에서 여러 상용 대안을 능가합니다.
MiniMax Speech 2.5가 다국어 음성을 잘 처리하나요?
예. MiniMax Speech 2.5는 40개 이상의 언어를 지원하며 중국어와 영어에서 약 2%의 WER을 달성합니다. 교차 언어 전송 레이어와 종단 간 학습을 통해 언어 간 음성 ID를 유지합니다.
Novita AI는 AI 야망을 실현하는 올인원 클라우드 플랫폼입니다. 통합 API, 서버리스, GPU 인스턴스 — 필요한 비용 효율적인 도구입니다. 인프라를 없애고 무료로 시작하여 AI 비전을 현실로 만드세요.



