

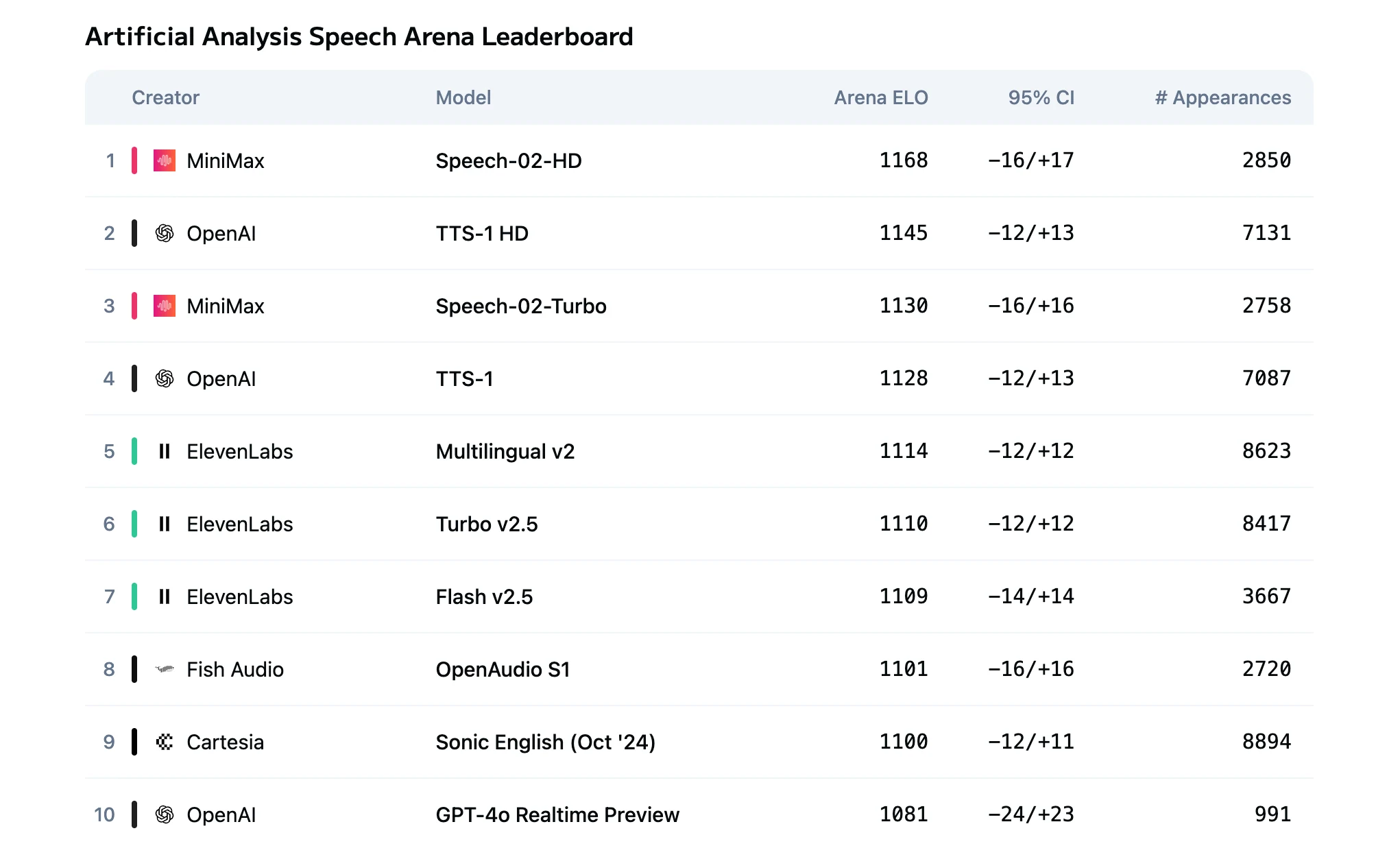
- Comparação de Modelos do Speech 2.5 Turbo e HD
- O Speech 2.5 consegue replicar uma voz arbitrária usando apenas alguns segundos de áudio?
- O Speech 2.5 oferece pronúncia de nível nativo em mais de 40 idiomas?
- Quão bem o Speech 2.5 lida com documentos longos ou livros?
- Qual é o custo por 1.000 caracteres do Speech 2.5
- Quão granular é o controle sobre pronúncia, ênfase e pausas?
- O MiniMax Speech 2.5 suporta streaming?
- Como usar o MiniMax Speech 2.5 por um bom preço?
Desenvolvedores que criam aplicativos de voz frequentemente enfrentam tempos de resposta lentos, qualidade de áudio inconsistente entre idiomas, custos elevados de API e controle limitado sobre o tom emocional ou a pronúncia — problemas que tornam a interação em tempo real e a geração em larga escala difíceis de entregar de forma confiável.
O MiniMax Speech 2.5 foi projetado para resolver essas restrições diretamente. Ele oferece clonagem de voz de alta precisão com apenas 6 a 10 segundos de áudio, síntese multilíngue em mais de 40 idiomas com ~2% de WER (Taxa de Erro de Palavras) em chinês e inglês, e latência no modo Turbo próxima de 250 ms para uso interativo. Cargas de trabalho de formato longo são suportadas por meio de processamento assíncrono de até 200.000 caracteres, enquanto o preço permanece acessível para desenvolvedores, a US$ 0,04 por 1.000 caracteres. Com controle emocional granular e desempenho estável sob relação sinal-ruído (SNR) ≥ 3 dB, o modelo oferece uma solução prática para equipes que precisam tanto de responsividade em tempo real quanto de geração de voz escalável e econômica.
Comparação de Modelos do Speech 2.5 Turbo e HD
A diferença fundamental entre o Speech 2.5 HD e o Turbo Preview está na relação qualidade-latência deles:
| Métrica | HD | Turbo |
|---|---|---|
| Qualidade de Áudio | Realismo de nível de estúdio com a maior fidelidade | Qualidade de alta definição com expressividade ligeiramente menor |
| Latência de TTS | Vários segundos | Latência ponta a ponta inferior a 250 ms |
| Cenário Ideal | Geração de conteúdo de alto nível | Aplicativos interativos em tempo real |
| Custo | US$ 80 por milhão de caracteres | US$ 48 por milhão de caracteres |
O HD oferece semelhança de timbre superior, nuances emocionais e prosódia natural. O Turbo otimiza o pipeline de codificação para atingir latência extremamente baixa adequada para interação em tempo real.
O Speech 2.5 consegue replicar uma voz arbitrária usando apenas alguns segundos de áudio?
O decodificador Flow-VAE do MiniMax Speech 2.5 combina Flow Matching e Codificação Automática Variacional para modelar a fala em um espaço latente aprendido, em vez de depender apenas de mel-espectrogramas. Isso captura o tom, o ritmo, o sotaque e a cor emocional.
Comprimento de Amostra Necessário: Apenas 6 a 10 segundos para clonagem de alta fidelidade, atingindo até 99% de semelhança.
Métricas de Semelhança: Supera o ElevenLabs em semelhança de locutor em 24 idiomas.
Clonagem Zero-shot: Nenhuma transcrição necessária; um codificador de incorporação de locutor aprendido extrai a identidade vocal diretamente
Experimente o MiniMax Speech 2.5 agora!
O Speech 2.5 oferece pronúncia de nível nativo em mais de 40 idiomas?
Capacidade Multilíngue:
- Suporta mais de 40 idiomas
- Chinês: Desempenho de benchmark global
- Inglês: Grande atualização em comparação com o Speech 0.2, com artefatos mecânicos reduzidos
- Outros idiomas: Japonês, francês, espanhol etc., com pronúncia nativa natural
Mecanismos:
- Extração aprimorada de características do locutor
- Camadas de transferência interlinguística que retêm o timbre
- Treinamento ponta a ponta para manter a identidade vocal entre idiomas
Métrica de Qualidade: A fala sintetizada em inglês e chinês do MiniMax tem WER de cerca de 2%, indicando que as palavras faladas são quase perfeitamente compreendidas por um ASR (Reconhecimento Automático de Fala).
Quão bem o Speech 2.5 lida com documentos longos ou livros?
Latência e Vazão de Formato Longo (Speech 2.5)
O MiniMax Speech 2.5 mantém desempenho estável em entradas longas, com vantagens quantificáveis de latência e vazão:
• Latência de TTS: A reprodução de áudio geralmente começa em alguns segundos, mesmo para texto com vários parágrafos. O pipeline de áudio atualizado do 2.5 minimiza o atraso de inicialização. Sistemas de gerações mais recentes atingem latência ponta a ponta de 250 ms em configurações de agentes; o Speech 2.5 permanece na faixa de poucos segundos para solicitações de síntese padrão.
• Capacidade de Texto Longo: Suporta até 10.000 caracteres por solicitação por meio da API de TTS assíncrona. As URLs de download permanecem válidas por 9 horas, garantindo recuperação confiável.
- Modo Turbo: latência menor e vazão maior (com perdas moderadas de fidelidade).
- Modo HD: qualidade de áudio maximizada. A vazão pode ser aumentada ainda mais usando envio em lote ou trabalhos assíncronos, adequados para cargas de trabalho como transcrição ou tarefas de síntese de uma hora de duração.
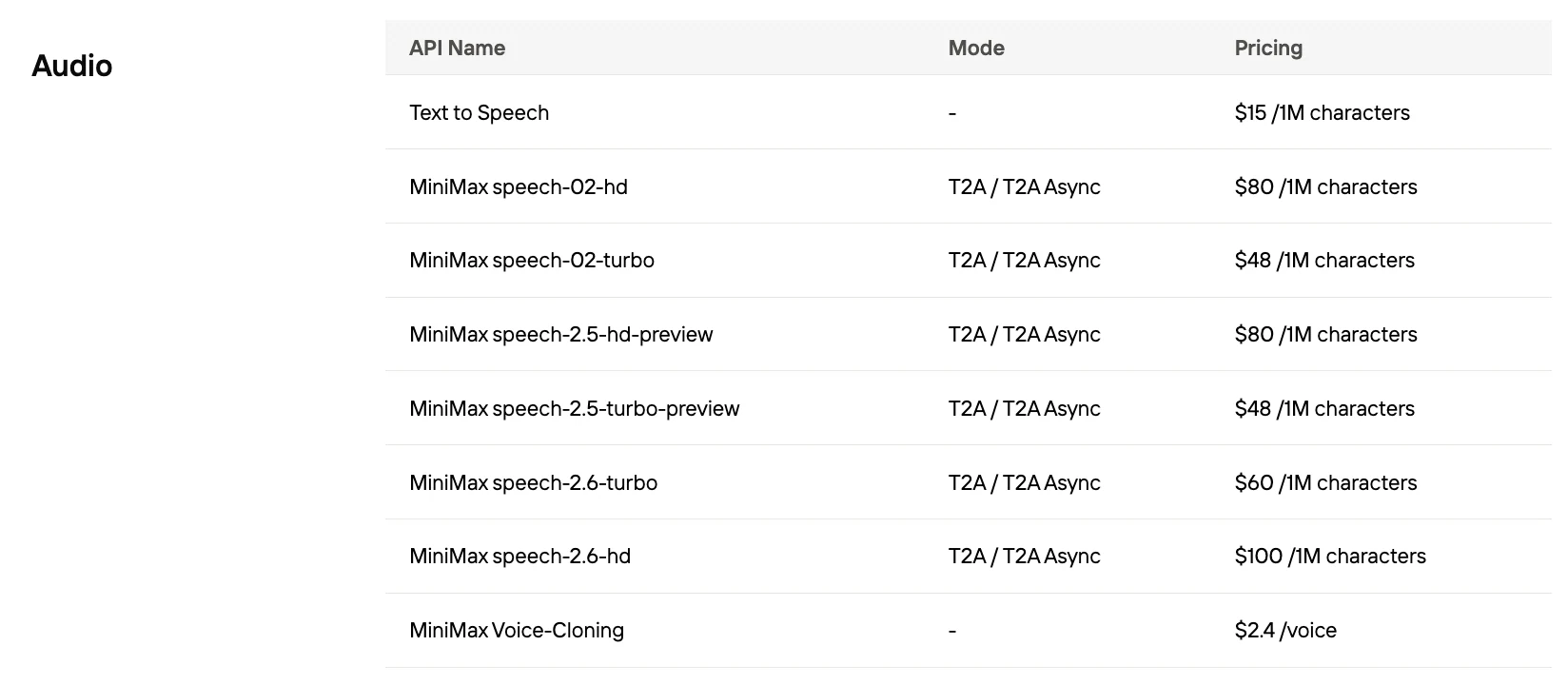
Qual é o custo por 1.000 caracteres do Speech 2.5
| Provedor | Custo / 1K caracteres |
|---|---|
| MiniMax Speech 2.5 Turbo | US$ 0,048 |
| MiniMax Speech 2.5 HD | US$ 0,08 |
| ElevenLabs | US$ 0,24 a 0,30 |
| OpenAI GPT-4 Audio | Geralmente > US$ 0,10 |
| Google Gemini | TTS > US$ 2,50 por 1 milhão de tokens |
A Novita AI oferece o melhor preço do Minimax Speech!
Experimente o MiniMax Speech 2.5 agora!
Quão granular é o controle sobre pronúncia, ênfase e pausas?
| Capacidade de Controle | Campo da API | Exemplo de Valor / Uso |
|---|---|---|
| Pausas personalizadas | text usando <#x#> |
Hello<#0.50#>world |
| Pronúncia em nível de fonema (IPA / X-SAMPA) | pronunciation_dict |
"demo": {"type":"ipa","value":"ˈdɛmoʊ"} |
| Substituição de tons chineses | pronunciation_dict (type: "tone") |
"你好": {"type":"tone","value":"ni3 hao3"} |
| Velocidade da fala | voice_setting.speed |
1.05 |
| Volume | voice_setting.vol |
1.2 |
| Tom (deslocamento de semitom) | voice_setting.pitch |
2 |
| Seleção de voz (ID de timbre) | voice_setting.voice_id |
"Calm_Woman" |
| Emoção | voice_setting.emotion |
"neutral" |
| Normalização de texto em inglês | voice_setting.text_normalization |
true |
| Taxa de amostragem | audio_setting.sample_rate |
44100 |
| Taxa de bits | audio_setting.bitrate |
128000 |
| Formato de áudio | audio_setting.format |
"mp3" |
| Canais | audio_setting.channel |
1 (mono) |
| Mistura de timbre (até 4 vozes) | timbre_weights |
[{"voice_id":"Calm_Woman","weight":70}] |
| Efeitos de áudio (reverberação, telefone, robótico etc.) | voice_modify.sound_effects |
"spacious_echo" |
| Ajuste de brilho do tom | voice_modify.pitch |
10 |
| Ajuste de intensidade | voice_modify.intensity |
-20 |
| Nitidez/magnetismo do timbre | voice_modify.timbre |
-15 |
| Modo de streaming | stream |
false |
| Reforço de idioma/dialeto | language_boost |
"English" |
import requests
url = "https://api.novita.ai/v3/minimax-speech-2.5-hd-preview"
payload = {
"text": "Hello<#0.50#>this is a demo of fine-grained control.<#0.30#>\
Please read the number 2025 clearly.",
"voice_setting": {
"speed": 1.05,
"vol": 1.2,
"pitch": 2,
"voice_id": "Calm_Woman",
"emotion": "neutral",
"text_normalization": True
},
"audio_setting": {
"sample_rate": 44100,
"bitrate": 128000,
"format": "mp3",
"channel": 1
},
# Use the concrete pronunciation dictionary from your example
"pronunciation_dict": {
"demo": {
"type": "ipa",
"value": "ˈdɛmoʊ"
},
"2025": {
"type": "ipa",
"value": "tuː θaʊzənd twɛnti faɪv"
},
"你好": {
"type": "tone",
"value": "ni3 hao3"
}
},
"timbre_weights": [
{
"voice_id": "Calm_Woman",
"weight": 70
},
{
"voice_id": "Friendly_Person",
"weight": 30
}
],
"stream": False,
"language_boost": "English",
"output_format": "url",
"voice_modify": {
"pitch": 10,
"intensity": -20,
"timbre": -15,
"sound_effects": "spacious_echo"
}
}
headers = {
"Content-Type": "application/json",
"Authorization": "Bearer YOUR_API_KEY_HERE"
}
response = requests.post(url, json=payload, headers=headers)
print(response.text)
Experimente o MiniMax Speech 2.5 agora!
O MiniMax Speech 2.5 suporta streaming?
Sim. O MiniMax Speech 2.5 suporta streaming tanto para reconhecimento de fala (ASR) quanto para texto para fala (TTS). A API inclui explicitamente o campo:
"stream": true
em uma solicitação de TTS, o sistema começa a gerar o áudio imediatamente e o envia de volta em segmentos. Isso permite que a reprodução comece antes que a frase completa seja sintetizada. A latência de inicialização típica de TTS é de alguns segundos, e cenários otimizados podem atingir tempos de resposta ponta a ponta de menos de um segundo.
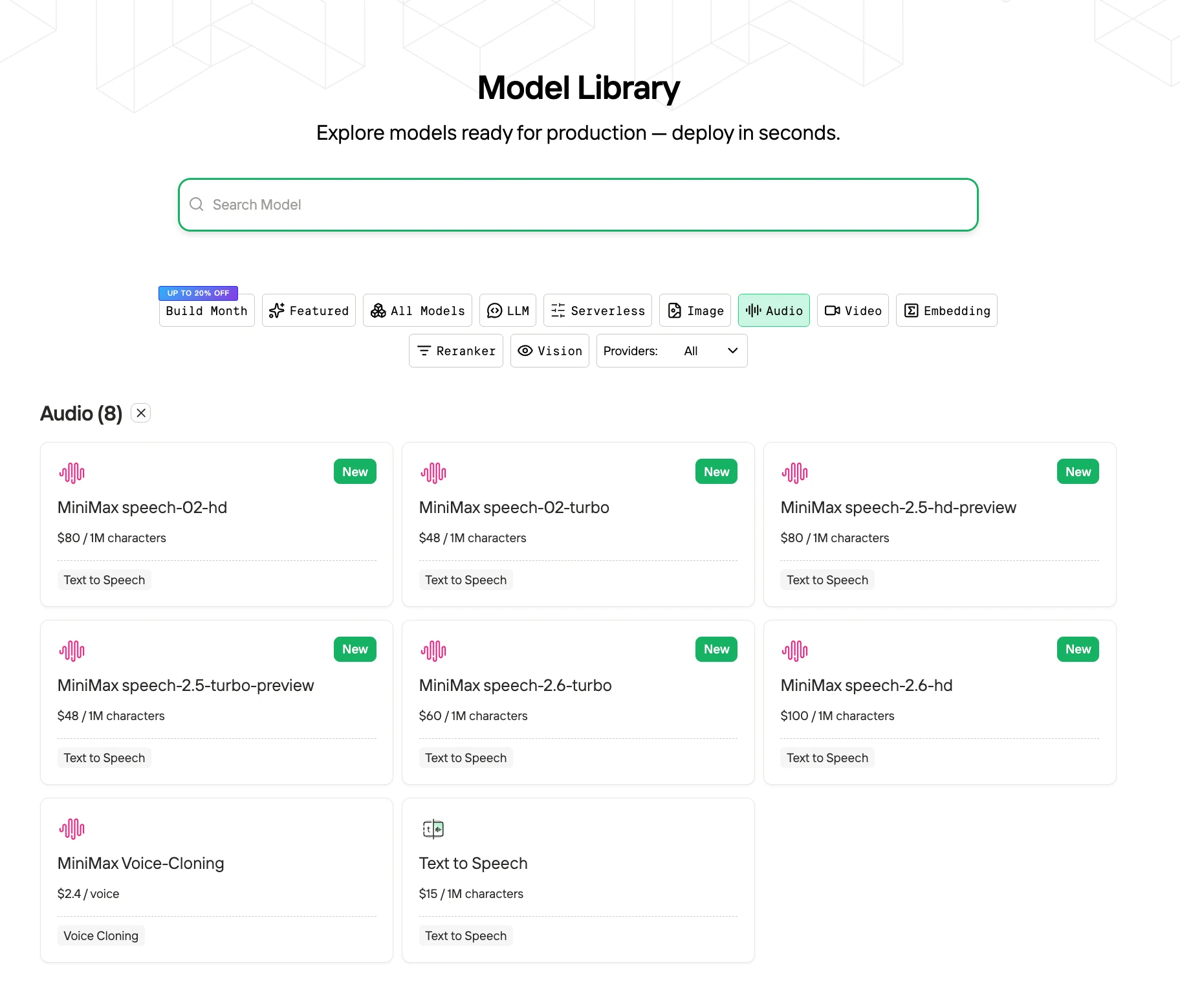
Como usar o MiniMax Speech 2.5 por um bom preço?
Passo 1: Faça login e acesse a Biblioteca de Modelos
Faça login na sua conta e clique no botão Biblioteca de Modelos.

Passo 2: Escolha seu modelo
Navegue pelas opções disponíveis e selecione o modelo que atende às suas necessidades.
Experimente o MiniMax Speech 2.5 agora!
Passo 3: Inicie seu teste gratuito
Comece seu teste gratuito para explorar as capacidades do modelo selecionado.
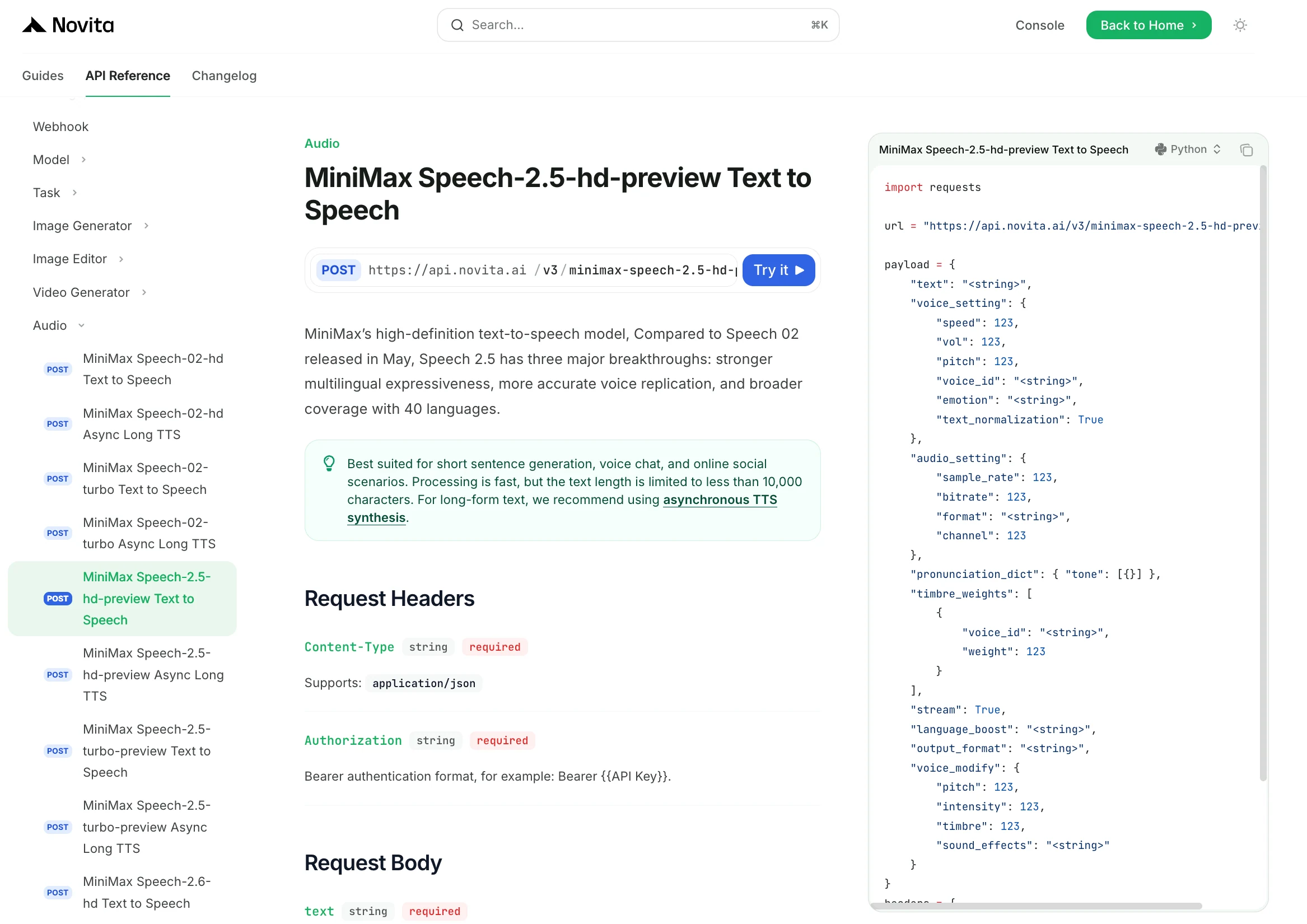
Passo 4: Obtenha sua chave de API
Para autenticar com a API, forneceremos uma nova chave de API. Acessando a página “Configurações”, você pode copiar a chave de API conforme indicado na imagem.

O MiniMax Speech 2.5 oferece uma solução equilibrada e pronta para desenvolvedores para os problemas centrais do desenvolvimento moderno de aplicativos de voz. Ele combina tempos de resposta rápidos, alta precisão multilíngue e processamento confiável de texto longo com preços econômicos e controle detalhado sobre o tom emocional, a pronúncia e o timbre. Com os modos Turbo e HD otimizados para diferentes necessidades de latência e qualidade, e com suporte completo a streaming, o MiniMax Speech 2.5 permite que equipes construam agentes de voz escaláveis, sistemas de transcrição em tempo real e pipelines de conteúdo de alta qualidade com muito menos restrições técnicas. O desempenho, a flexibilidade e o design da API do modelo tornam uma escolha prática para desenvolvedores que buscam tanto eficiência quanto geração de fala expressiva.
Perguntas Frequentes
O MiniMax Speech 2.5 suporta streaming?
Sim. O MiniMax Speech 2.5 suporta streaming tanto para ASR quanto para TTS. Habilitar "stream": true permite que o sistema envie transcrições incrementais ou fragmentos de áudio em tempo real, permitindo tempos de resposta de menos de um segundo e temporização de conversa natural.
Quão precisa é a clonagem de voz no MiniMax Speech 2.5? O MiniMax Speech 2.5 alcança clonagem de voz de alta fidelidade com apenas 6 a 10 segundos de áudio, atingindo até 99% de semelhança e superando várias alternativas comerciais em benchmarks de semelhança de locutor multilíngue.
O MiniMax Speech 2.5 lida bem com fala multilíngue? Sim. O MiniMax Speech 2.5 suporta mais de 40 idiomas e alcança ~2% de WER para chinês e inglês. Ele mantém a identidade vocal entre idiomas por meio de camadas de transferência interlinguística e treinamento ponta a ponta.
Novita AI é a plataforma de nuvem tudo-em-um que capacita suas ambições de IA. APIs integradas, serverless, Instâncias de GPU — as ferramentas econômicas que você precisa. Elimine a infraestrutura, comece gratuitamente e torne sua visão de IA uma realidade.



