

開發語音應用的開發者經常面臨回應速度慢、跨語言音訊品質不一致、API 成本高,以及對情感語調或發音的控制有限等問題——這些問題使得即時互動與大規模生成難以穩定實現。
MiniMax Speech 2.5 正是為直接解決這些限制而設計。它僅需 6–10 秒的音訊即可實現高準確度語音克隆,支援 40 種以上語言的多語言合成,中文與英文的字錯率(WER)約 2%,Turbo 模式延遲接近 250 毫秒,適合互動場景使用。長文本工作負載可透過非同步處理最多 20 萬字元來實現,同時定價對開發者非常友好,每 1000 字元僅需 0.04 美元。模型支援細粒度情感控制,在 SNR ≥ 3 dB 的環境下仍能穩定運行,為需要即時回應能力、可擴展且高性價比語音生成的團隊提供了實用解決方案。
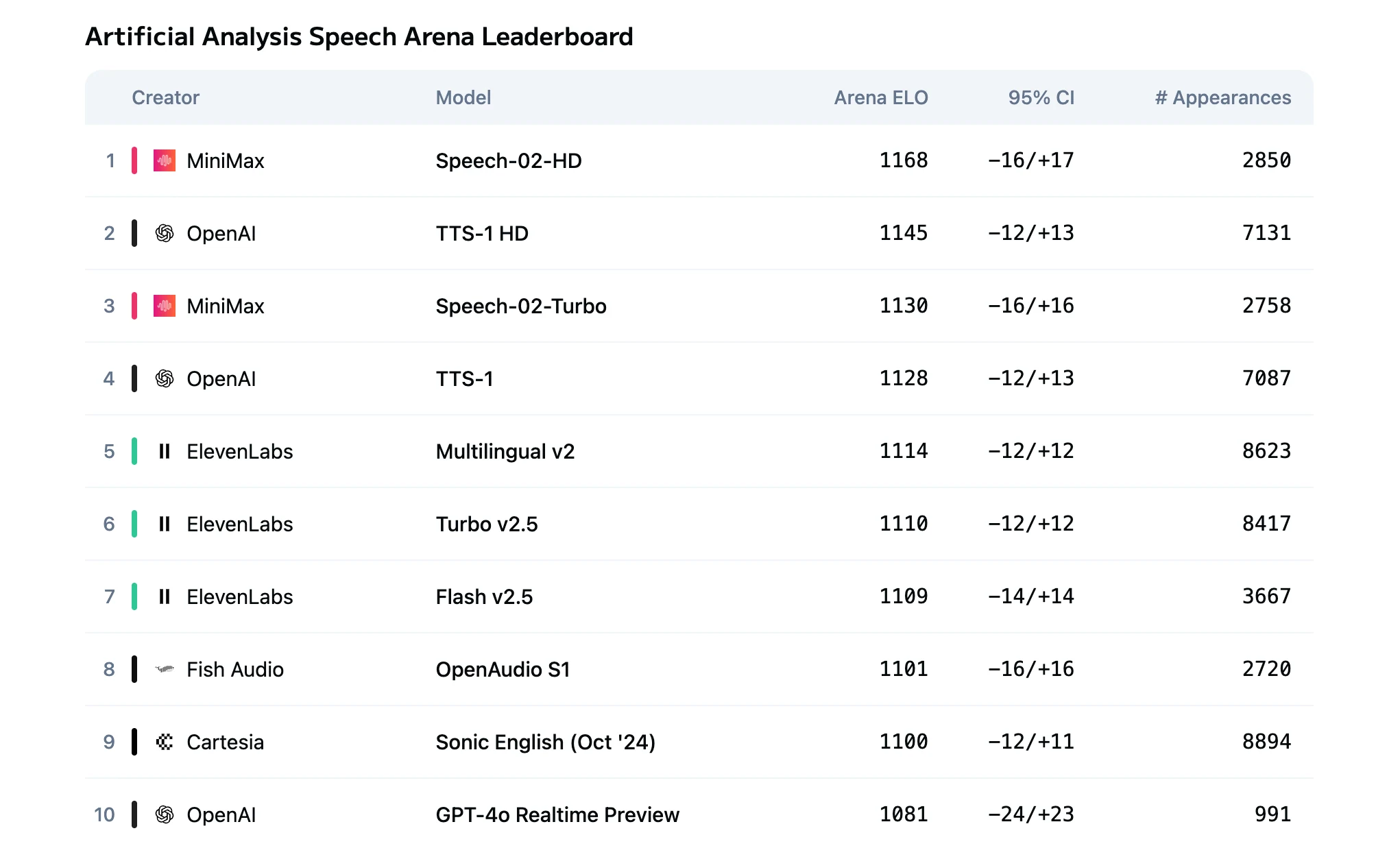
Speech 2.5 Turbo 與 HD 模型比較
Speech 2.5 HD 與 Turbo Preview 的核心差異在於其品質與延遲的取捨:
| 指標 | HD | Turbo |
|---|---|---|
| 音訊品質 | 錄音室等級的逼真度,fidelity 最高 | 高清品質,表現力略遜一籌 |
| TTS 延遲 | 數秒 | 端到端延遲低於 250 毫秒 |
| 適用場景 | 高端內容生成 | 即時互動應用 |
| 成本 | 每百萬字元 80 美元 | 每百萬字元 48 美元 |
HD 版本在音色相似度、情感細膩度與自然韻律方面表現更優。
Turbo 版本優化了編碼管線,實現極低延遲,適合即時互動場景。
Speech 2.5 是否僅需數秒音訊即可複製任意語音?
MiniMax Speech 2.5 的 Flow-VAE 解碼器結合了 Flow Matching 與變分自編碼技術,在學習到的潛空間中對語音進行建模,而非僅依賴梅爾頻譜圖,因此能捕捉音高、節奏、口音與情感色調。
所需取樣長度: 僅需 6–10 秒 音訊即可實現高保真克隆,相似度最高可達 99%。
相似度指標: 在 24 種語言的說話人相似度測試中,表現優於 ElevenLabs。
零樣本克隆: 無需提供文字稿,訓練好的 說話人嵌入編碼器 可直接提取語音身份特徵
Speech 2.5 是否能在 40 種以上語言中實現母語級發音?
多語言能力:
- 支援 40 種以上語言
- 中文: 全球基準測試表現優異
- 英文: 相較 Speech 0.2 有大幅升級,機械感雜訊大幅減少
- 其他語言: 日語、法語、西班牙語等均可實現自然母語級發音
實現機制:
- 強化說話人特徵提取
- 保留音色的跨語言傳遞層
- 端到端訓練,跨語言維持語音身份特徵
品質指標:
MiniMax 合成的中文與英文語音字錯率(WER)約 2%,表示語音內容幾乎可被語音辨識(ASR)系統完美理解。
Speech 2.5 處理長文件或書籍的表現如何?
長文本延遲與吞吐量(Speech 2.5)
MiniMax Speech 2.5 在長輸入場景下仍能維持穩定效能,且延遲與吞吐量具有可量化的優勢:
• TTS 延遲:
即使輸入多段落文字,音訊播放通常也在數秒內開始。更新後的 2.5 音訊管線最大程度降低了啟動延遲。後續世代系統在代理場景下可實現 250 毫秒的端到端延遲;Speech 2.5 在標準合成請求場景下仍能維持數秒級的延遲水平。
• 長文本處理容量:
透過非同步 TTS API,單次請求最多可處理 10,000 字元。下載連結有效期長達 9 小時,確保可穩定取得結果。
- Turbo 模式: 延遲更低、吞吐量更高(會適度犧牲音質)。
- HD 模式: 音訊品質最大化。
可透過批次提交或非同步任務進一步提升吞吐量,適合處理長達數小時的轉錄或合成等工作負載。
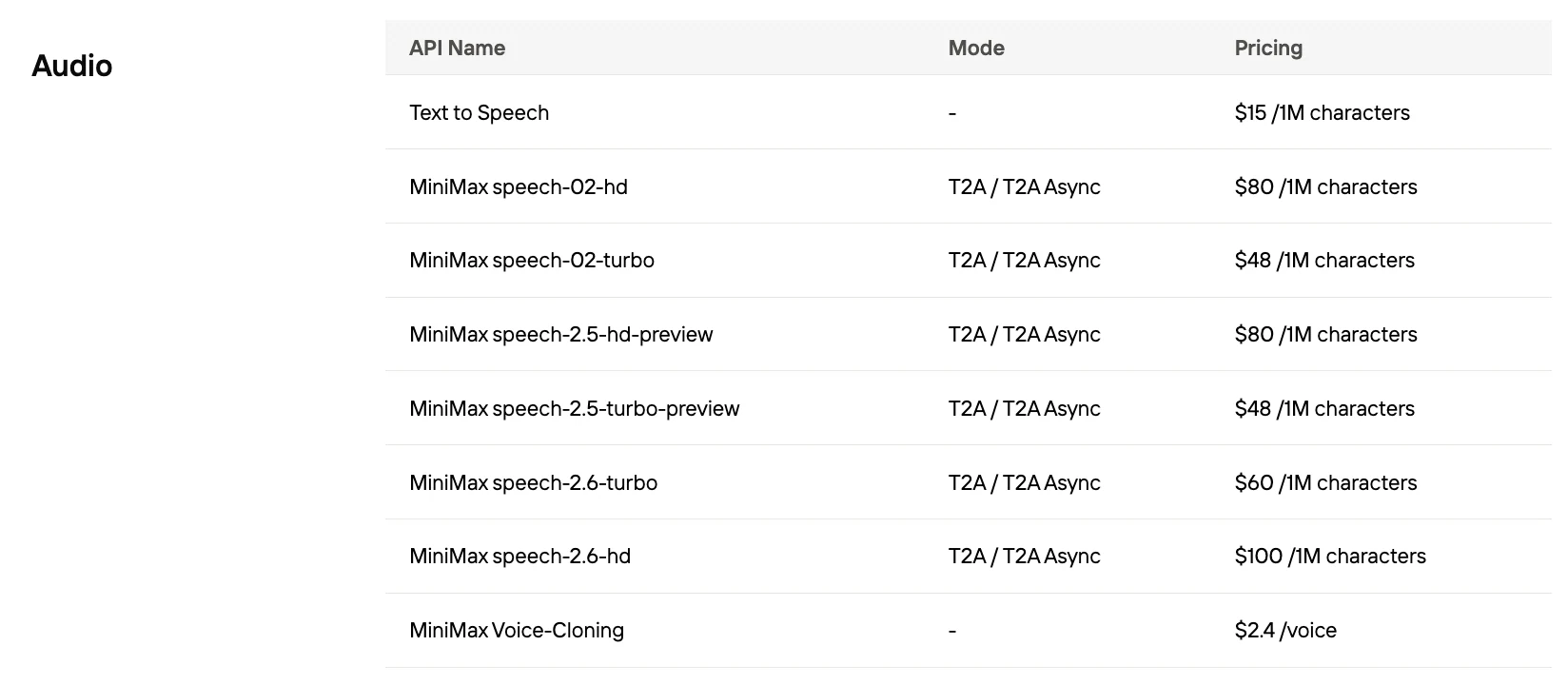
Speech 2.5 每 1000 字元的成本是多少?
| 供應商 | 每 1K 字元成本 |
|---|---|
| MiniMax Speech 2.5 Turbo | $0.048 |
| MiniMax Speech 2.5 HD | $0.08 |
| ElevenLabs | $0.24–0.30 |
| OpenAI GPT-4 Audio | 通常高於 $0.10 |
| Google Gemini | TTS 每 100 萬 token 高於 $2.50 |
Novita AI 提供 MiniMax Speech 的最優價格!
對發音、重音與停頓的控制細緻度如何?
| 控制能力 | API 欄位 | 範例值 / 用法 |
|---|---|---|
| 自訂停頓 | text 中使用 <#x#> |
Hello<#0.50#>world |
| 音素級發音(IPA / X-SAMPA) | pronunciation_dict |
"demo": {"type":"ipa","value":"ˈdɛmoʊ"} |
| 中文聲調替換 | pronunciation_dict (type: "tone") |
"你好": {"type":"tone","value":"ni3 hao3"} |
| 語速 | voice_setting.speed |
1.05 |
| 音量 | voice_setting.vol |
1.2 |
| 音高(半音偏移) | voice_setting.pitch |
2 |
| 語音選擇(音色 ID) | voice_setting.voice_id |
"Calm_Woman" |
| 情感 | voice_setting.emotion |
"neutral" |
| 英文文字正規化 | voice_setting.text_normalization |
true |
| 取樣率 | audio_setting.sample_rate |
44100 |
| 位元率 | audio_setting.bitrate |
128000 |
| 音訊格式 | audio_setting.format |
"mp3" |
| 聲道數 | audio_setting.channel |
1 (單聲道) |
| 音色混合(最多 4 種語音) | timbre_weights |
[{"voice_id":"Calm_Woman","weight":70}] |
| 音訊特效(迴響、電話、機器人等) | voice_modify.sound_effects |
"spacious_echo" |
| 亮度音高調整 | voice_modify.pitch |
10 |
| 強度調整 | voice_modify.intensity |
-20 |
| 音色銳度 / 磁性 | voice_modify.timbre |
-15 |
| 串流模式 | stream |
false |
| 語言 / 方言強化 | language_boost |
"English" |
import requests
url = "https://api.novita.ai/v3/minimax-speech-2.5-hd-preview"
payload = {
"text": "Hello<#0.50#>this is a demo of fine-grained control.<#0.30#>\
Please read the number 2025 clearly.",
"voice_setting": {
"speed": 1.05,
"vol": 1.2,
"pitch": 2,
"voice_id": "Calm_Woman",
"emotion": "neutral",
"text_normalization": True
},
"audio_setting": {
"sample_rate": 44100,
"bitrate": 128000,
"format": "mp3",
"channel": 1
},
# Use the concrete pronunciation dictionary from your example
"pronunciation_dict": {
"demo": {
"type": "ipa",
"value": "ˈdɛmoʊ"
},
"2025": {
"type": "ipa",
"value": "tuː θaʊzənd twɛnti faɪv"
},
"你好": {
"type": "tone",
"value": "ni3 hao3"
}
},
"timbre_weights": [
{
"voice_id": "Calm_Woman",
"weight": 70
},
{
"voice_id": "Friendly_Person",
"weight": 30
}
],
"stream": False,
"language_boost": "English",
"output_format": "url",
"voice_modify": {
"pitch": 10,
"intensity": -20,
"timbre": -15,
"sound_effects": "spacious_echo"
}
}
headers = {
"Content-Type": "application/json",
"Authorization": "Bearer YOUR_API_KEY_HERE"
}
response = requests.post(url, json=payload, headers=headers)
print(response.text)
MiniMax Speech 2.5 是否支援串流?
是的。MiniMax Speech 2.5 同時支援 語音辨識(ASR) 與 文字轉語音(TTS) 的串流功能。API 明確包含以下欄位:
"stream": true
在 TTS 請求中包含此欄位時,系統會立即開始生成音訊,並分段返回。這使得播放可以在完整句子合成完成前就啟動。一般 TTS 啟動延遲在數秒內,優化後的場景可達到 亞秒級 的端到端回應速度。
如何以優惠價格使用 MiniMax Speech 2.5?
步驟 1:登入並進入模型庫
登入你的帳號,點擊 模型庫 按鈕。

步驟 2:選擇你需要的模型
瀏覽可用的選項,選擇符合你需求的模型。
步驟 3:開始免費試用
開始免費試用,探索所選模型的能力。
步驟 4:取得 API 金鑰
要進行 API 驗證,我們會提供你新的 API 金鑰。進入「設定」頁面,即可按照圖片指示複製 API 金鑰。

MiniMax Speech 2.5 為現代語音應用開發的核心問題提供了平衡、開發者就緒的解決方案。它結合了快速回應速度、強大的多語言準確度、可靠的長文本處理能力,搭配高性價比的定價,以及對情感語調、發音、音色的細緻控制。Turbo 與 HD 模式分別針對不同的延遲與品質需求進行優化,同時完整支援串流功能,讓團隊能夠以更少的技術限制構建可擴展的語音代理、即時轉錄系統與高品質內容管線。模型的效能、靈活性與 API 設計,使其成為尋求高效能與表現力兼備的語音生成的開發者的實用選擇。
常見問題
MiniMax Speech 2.5 是否支援串流?
是的。MiniMax Speech 2.5 同時支援 ASR 與 TTS 的串流功能。啟用 "stream": true 後,系統會即時傳送增量文字稿或音訊區塊,實現亞秒級回應速度與自然的對話節奏。
MiniMax Speech 2.5 的語音克隆準確度如何?
MiniMax Speech 2.5 僅需 6–10 秒音訊即可實現高保真語音克隆,相似度最高可達 99%,在多語言說話人相似度基準測試中表現優於多款商業替代方案。
MiniMax Speech 2.5 的多語言語音處理表現如何?
是的。MiniMax Speech 2.5 支援 40 種以上語言,中文與英文的字錯率(WER)約 2%。透過跨語言傳遞層與端到端訓練,可在不同語言間維持語音身份特徵。
Novita AI 是實現你 AI 抱負的一站式雲端平台。整合式 API、無伺服器架構、GPU 實例——都是你所需的高性價比工具。免除基礎設施煩惱,免費開始使用,讓你的 AI 願景成為現實。



