

重點摘要
Llama 4 Scout 憑藉處理超長上下文(例如 10M tokens)的能力,提供卓越效能,非常適合先進的 AI 應用。
它在長上下文推理方面超越其他模型,但需要高達 18.8 TB 的 VRAM 與 240 張 H100 GPU,使得本機部署極具挑戰性。
API 提供經濟且可擴展的解決方案,免除昂貴硬體需求,優化多 GPU 通訊,並確保可靠性。
Llama 4 Scout 是一款處理超長上下文(如 10M tokens)的前沿模型,遠超大多數模型的能力。雖然其效能無與倫比,但極端的硬體需求使得本機部署對許多使用者而言不切實際。
Llama 4 Scout VRAM 需求
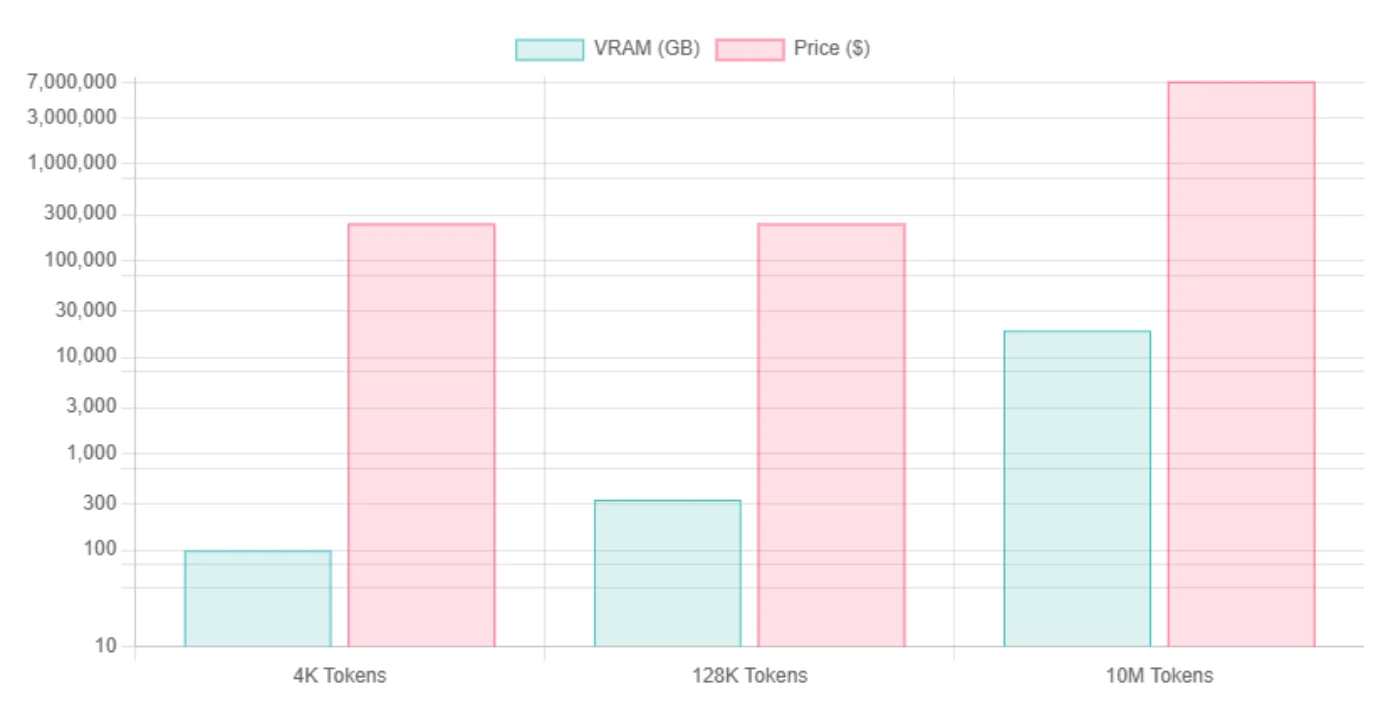
| 上下文長度 | Llama 4 Scout Int4 VRAM | 所需 GPU | Llama 4 Scout FP16 VRAM | 所需 GPU |
| 4K Tokens | ~99.5 GB / ~76.2 GB | H100 | ~345 GB | 8*H100 |
| 128K Tokens | ~334 GB | 8*H100 | ~579 GB | 8*H100 |
| 10M Tokens | 主要由 KV Cache 佔用,估計 ~18.8 TB | 240*H100 | 與 INT4 相同(因 KV 為主) | 240*H100 |
本機執行 Llama 4 Scout 的挑戰
1. KV Cache 記憶體需求
- 極長的上下文(例如 10M Tokens)需要大量記憶體來儲存 KV cache,即使在 INT4 模式下也高達 18.8 TB VRAM。這需要一個由 240 張 H100 GPU 組成的大型叢集,導致擴展性問題。
2. 多 GPU 通訊開銷
- 使用 8 或 240 張 GPU 時,分散式 KV cache 儲存與存取的通訊開銷變得顯著,可能拖慢整體效能。
3. 高成本與高能耗
- 運行大型 GPU 叢集(尤其針對 10M Tokens)會導致極高的硬體、營運與能源成本,使許多使用案例不切實際。
4. 推理效率
- 對於極長上下文(例如 128K 或 10M Tokens),計算複雜度急遽增加。這可能導致推理期間顯著的延遲,無法滿足即時需求。
本機執行 Llama 4 Scout 的潛在解決方案
1. 優化 KV Cache
- 使用分散式 KV cache 將記憶體需求分攤到多個 GPU。
- 探索更有效的記憶體管理技術,例如壓縮 KV cache,或將較不常存取的資料儲存在較慢的記憶體層級。
2. 改善多 GPU 通訊
- 利用高頻寬互連(如 NVIDIA NVLink 或 Infiniband)來降低延遲並加速 GPU 間通訊。
- 優化分散式運算框架(如 DeepSpeed 或 Megatron-LM),以減少通訊開銷並提升擴展性。
3. 降低成本與能耗
- 使用 稀疏注意力機制 等技術優化模型架構,以減少記憶體用量與運算需求。
- 探索硬體改善(例如未來 GPU 架構或自訂 AI 加速器)以提供更高效率。
4. 提升推理效率
- 實作稀疏注意力機制或分塊處理,更有效地處理長上下文。
- 使用分層快取或分層儲存策略來優化 KV cache 管理,並減少推理延遲。
API 存取:小型開發者的經濟選擇

為什麼 API 是強大的解決方案
1. KV Cache 與 GPU 記憶體需求
- API 解決方案: API 在其基礎設施上處理所有 KV cache 與記憶體需求,免除您購買或管理 GPU 的必要。它們能動態分配記憶體,即使對於 10M tokens 這樣的超長上下文也一樣。
- 為什麼重要: 這消除了昂貴硬體與複雜記憶體管理的需求,讓您能專注於使用模型本身。
2. 多 GPU 通訊複雜性
- API 解決方案: API 內部使用 NVLink 或 Infiniband 等先進互連技術優化多 GPU 通訊,確保高效能,無需您介入。
- 為什麼重要: 您無需面對配置與維護分散式 GPU 系統的技術與營運挑戰,同時享受無縫效能。
3. 高昂的硬體與維護成本
- API 解決方案: 使用 API,您只需按使用量付費(隨用隨付模式),避免了購買 GPU 硬體的數百萬前期成本與持續維護費用。
- 為什麼重要: API 使高效能 AI 變得易於使用且經濟高效,尤其適合預算有限或使用頻率不高的企業。
4. 大規模工作負載的擴展性
- API 解決方案: API 能自動擴展以滿足您的工作負載需求,無論是處理小型任務還是 10M tokens 這樣的大規模上下文。供應商會根據需要動態分配資源。
- 為什麼重要: 這確保您的應用程式能夠應對突然的流量高峰或大型任務,無需升級基礎設施或停機。
5. 推理效率
- API 解決方案: API 採用稀疏注意力和並行化等先進優化技術,高效處理長上下文,比大多數本機設定更快提供結果。
- 為什麼重要: 更快的推理時間改善了使用者體驗,並減少了等待時間,即使是涉及超長上下文的嚴苛應用也一樣。
6. 可靠性與維護
- API 解決方案: API 透過處理硬體故障、更新與擴展問題,確保高可靠性。供應商保證正常運作時間並無縫提供最新模型版本。
- 為什麼重要: 您無需擔心系統停機、硬體維護或手動更新,確保應用程式不中斷服務。
一個穩定且極具成本效益的 API – Novita AI
步驟 1:登入並存取模型庫
登入您的帳戶,點擊 模型庫(Model Library) 按鈕。

步驟 2:選擇您的模型
瀏覽可用選項,選擇符合您需求的模型。

步驟 3:開始免費試用
開始免費試用,探索所選模型的功能。
步驟 4:取得您的 API 金鑰
為驗證 API,我們會提供您一個新的 API 金鑰。進入「設定(Settings)」頁面,您可以按照圖片指示複製 API 金鑰。

步驟 5:安裝 API
使用您程式語言專屬的套件管理器安裝 API。

安裝後,將必要的函式庫匯入您的開發環境。使用您的 API 金鑰初始化 API,開始與 Novita AI LLM 互動。以下是 Python 使用者使用聊天補全 API 的範例。
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<YOUR Novita AI API Key>",
)
model = "meta-llama/llama-4-scout-17b-16e-instruct"
stream = True # or False
max_tokens = 2048
system_content = """Be a helpful assistant"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
結論
Llama 4 Scout 處理長上下文的無與倫比效率,使其成為進階 AI 任務的首選。API 消除了本機部署的挑戰,提供可靠、可擴展且具成本效益的解決方案。透過 API 存取,開發者可以充分利用 Llama 4 Scout 的能力,同時避免基礎設施管理的負擔,從而專注於創新與創造價值。
常見問題
Llama 4 Scout 與其他模型相比有何優勢?
Llama 4 Scout 擅長處理超長上下文(例如 10M tokens),效率無與倫比。
為什麼在本機執行 Llama 4 Scout 很困難?
本機執行 Llama 4 Scout 需要高達 18.8 TB 的 VRAM 與 240 張 H100 GPU,導致高成本、擴展性問題以及複雜的 GPU 通訊挑戰。
如何透過 API 開始使用 Llama 4 Scout?
只需登入 Novita AI,從模型庫中選擇 Llama 4 Scout,開始免費試用,產生 API 金鑰,然後使用提供的工具將其整合到您的開發環境中。
Novita AI 是一個 AI 雲端平台,為開發者提供使用簡易 API 部署 AI 模型的方式,同時也提供價格合理且可靠的 GPU 雲端,用於建置與擴展應用程式。



