

Points clés
Llama 4 Scout offre des performances supérieures grâce à sa capacité à traiter des contextes extrêmement longs, comme 10M tokens, ce qui le rend idéal pour les applications avancées d’IA.
Il surpasse les autres modèles dans le traitement d’inférences à long contexte, mais nécessite jusqu’à 18,8 To de VRAM et 240 GPU H100, ce qui rend son déploiement local difficile.
Les API offrent une solution économique et évolutive, éliminant le besoin de matériel coûteux, optimisant la communication multi-GPU et garantissant la fiabilité.
Llama 4 Scout se distingue comme un modèle de pointe pour le traitement de contextes ultra-longs comme 10M tokens, dépassant largement les capacités de la plupart des modèles. Bien que ses performances soient inégalées, les besoins matériels extrêmes rendent son déploiement local peu pratique pour de nombreux utilisateurs.
Exigences VRAM de Llama 4 Scout
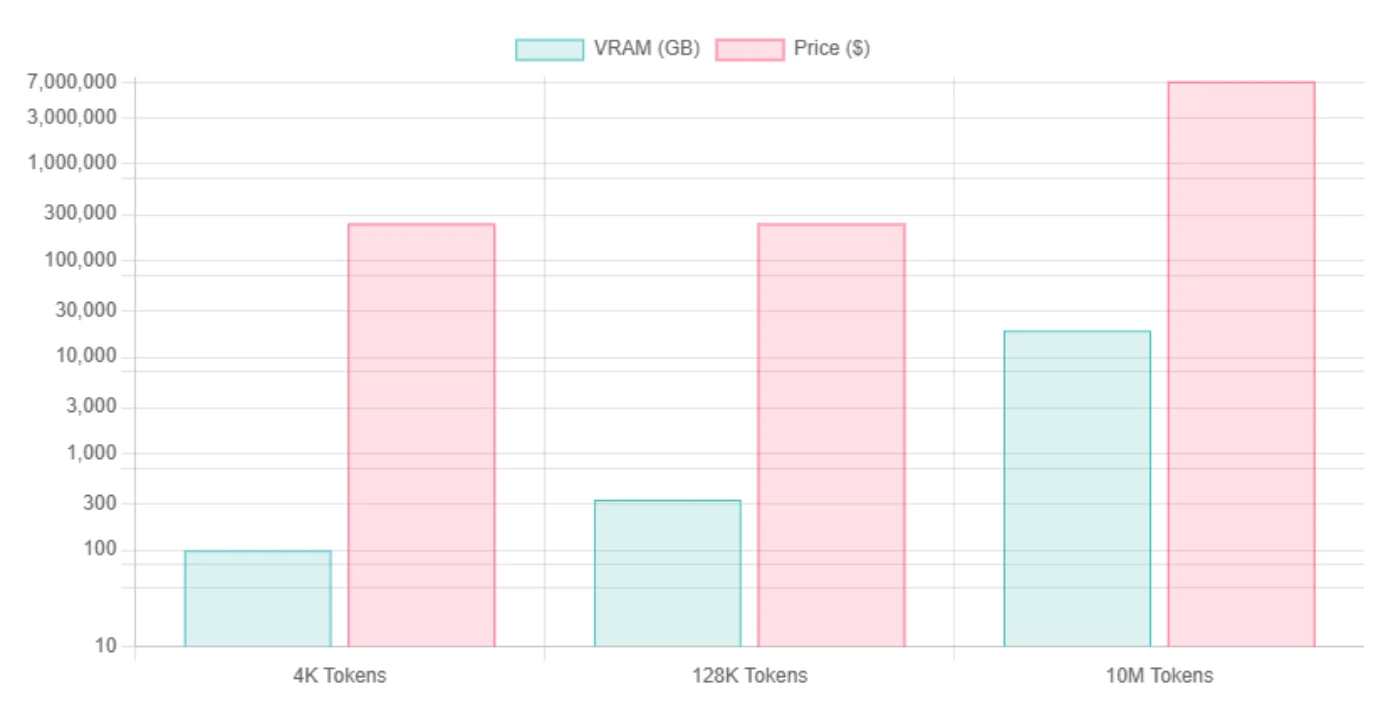
| Longueur du contexte | VRAM Llama 4 Scout Int4 | Besoins en GPU | VRAM Llama 4 Scout FP16 | Besoins en GPU |
| 4K tokens | ~99,5 Go / ~76,2 Go | H100 | ~345 Go | 8*H100 |
| 128K tokens | ~334 Go | 8*H100 | ~579 Go | 8*H100 |
| 10M tokens | Dominé par le cache KV, estimé ~18,8 To | 240*H100 | Identique à INT4, en raison de la dominance du cache KV | 240*H100 |
Défis de l’exécution locale de Llama 4 Scout
1. Exigences de mémoire du cache KV
- Les contextes extrêmement longs (par exemple, 10M tokens) nécessitent une mémoire massive pour stocker le cache KV, jusqu’à 18,8 To de VRAM même en mode INT4. Cela nécessite un grand cluster de GPU de 240 H100, entraînant des problèmes de scalabilité.
2. Surcharge de communication multi-GPU
- Avec 8 ou 240 GPU, la surcharge de communication pour le stockage et l’accès distribué du cache KV devient importante, ce qui peut ralentir les performances globales.
3. Coût élevé et consommation d’énergie
- L’exploitation de grands clusters de GPU, en particulier pour 10M tokens, entraîne des coûts matériels, opérationnels et énergétiques extrêmement élevés, ce qui la rend peu pratique pour de nombreux cas d’utilisation.
4. Efficacité de l’inférence
- Pour les contextes extrêmement longs (par exemple, 128K ou 10M tokens), la complexité de calcul augmente considérablement. Cela peut entraîner une latence importante lors de l’inférence, ce qui peut ne pas répondre aux exigences en temps réel.
Solutions potentielles pour exécuter Llama 4 Scout localement
1. Optimisation du cache KV
- Utiliser un cache KV distribué pour répartir les besoins en mémoire sur plusieurs GPU.
- Explorer des techniques de gestion de mémoire plus efficaces, comme la compression du cache KV ou le stockage des données moins fréquemment consultées sur des niveaux de mémoire plus lents.
2. Amélioration de la communication multi-GPU
- Exploiter des interconnexions à haute bande passante comme NVIDIA NVLink ou Infiniband pour réduire la latence et accélérer la communication entre les GPU.
- Optimiser les frameworks de calcul distribué comme DeepSpeed ou Megatron-LM pour minimiser la surcharge de communication et améliorer la scalabilité.
3. Réduction des coûts et de la consommation d’énergie
- Optimiser l’architecture du modèle en utilisant des techniques comme les mécanismes d’attention sparse pour réduire l’utilisation de la mémoire et la demande de calcul.
- Explorer des améliorations matérielles (par exemple, les futures architectures GPU ou les accélérateurs IA personnalisés) offrant une efficacité accrue.
4. Amélioration de l’efficacité de l’inférence
- Implémenter des mécanismes d’attention sparse ou un traitement par morceaux pour gérer les longs contextes plus efficacement.
- Utiliser des stratégies de mise en cache hiérarchique ou de stockage par niveaux pour optimiser la gestion du cache KV et réduire la latence d’inférence.
Accès par API : un choix économique pour les petits développeurs

Pourquoi les API sont une solution solide
1. Exigences de cache KV et de mémoire GPU
- Solution API : Les API gèrent toutes les exigences de cache KV et de mémoire sur leur infrastructure, éliminant ainsi le besoin d’acheter ou de gérer des GPU. Elles allouent la mémoire de manière dynamique, même pour des contextes extrêmement longs comme 10M tokens.
- Pourquoi c’est important : Cela supprime le besoin de matériel coûteux et de gestion complexe de la mémoire, vous permettant de vous concentrer uniquement sur l’utilisation du modèle.
2. Complexité de la communication multi-GPU
- Solution API : Les API optimisent la communication multi-GPU en interne à l’aide d’interconnexions avancées comme NVLink ou Infiniband, garantissant des performances efficaces sans nécessiter votre intervention.
- Pourquoi c’est important : Vous évitez les défis techniques et opérationnels de la configuration et de la maintenance de systèmes GPU distribués tout en bénéficiant de performances fluides.
3. Coûts matériels et de maintenance élevés
- Solution API : Avec les API, vous ne payez que pour ce que vous utilisez grâce à un modèle de paiement à l’utilisation, évitant les coûts initiaux de plusieurs millions de dollars pour l’achat de GPU et les dépenses de maintenance continues.
- Pourquoi c’est important : Les API rendent l’IA haute performance accessible et économique, en particulier pour les entreprises sans gros budgets ou ayant des besoins d’utilisation peu fréquents.
4. Scalabilité pour les grandes charges de travail
- Solution API : Les API se scalent automatiquement pour répondre à vos besoins de charge de travail, que vous traitiez de petites tâches ou des contextes massifs comme 10M tokens. Le fournisseur alloue dynamiquement les ressources selon les besoins.
- Pourquoi c’est important : Cela garantit que votre application peut gérer des pics soudains de demande ou des tâches à grande échelle sans nécessiter de mise à niveau de l’infrastructure ou de temps d’arrêt.
5. Efficacité de l’inférence
- Solution API : Les API utilisent des optimisations avancées comme l’attention sparse et la parallélisation pour traiter efficacement les longs contextes, offrant des résultats plus rapides que la plupart des configurations locales.
- Pourquoi c’est important : Des temps d’inférence plus rapides améliorent l’expérience utilisateur et réduisent les temps d’attente, même pour les applications exigeantes impliquant de très longs contextes.
6. Fiabilité et maintenance
- Solution API : Les API garantissent une haute fiabilité en gérant les pannes matérielles, les mises à jour et les problèmes de scalabilité. Les fournisseurs assurent la disponibilité et un accès transparent aux dernières versions du modèle.
- Pourquoi c’est important : Vous n’avez pas à vous soucier des temps d’arrêt du système, de la maintenance matérielle ou des mises à jour manuelles, garantissant un service ininterrompu pour votre application.
Une API stable et hautement économique – Novita AI
Étape 1 : Connectez-vous et accédez à la bibliothèque de modèles
Connectez-vous à votre compte et cliquez sur le bouton Bibliothèque de modèles.

Essayez Llama 4 Scout maintenant !
Étape 2 : Choisissez votre modèle
Parcourez les options disponibles et sélectionnez le modèle qui correspond à vos besoins.

Étape 3 : Commencez votre essai gratuit
Démarrez votre essai gratuit pour explorer les capacités du modèle sélectionné.
Étape 4 : Obtenez votre clé API
Pour vous authentifier auprès de l’API, nous vous fournirons une nouvelle clé API. Rendez-vous sur la page « Paramètres » et copiez la clé API comme indiqué dans l’image.

Étape 5 : Installez l’API
Installez l’API à l’aide du gestionnaire de paquets spécifique à votre langage de programmation.

Après l’installation, importez les bibliothèques nécessaires dans votre environnement de développement. Initialisez l’API avec votre clé API pour commencer à interagir avec Novita AI LLM. Voici un exemple d’utilisation de l’API de complétion de chat pour les utilisateurs Python.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<VOTRE Clé API Novita AI>",
)
model = "meta-llama/llama-4-scout-17b-16e-instruct"
stream = True # or False
max_tokens = 2048
system_content = """Soyez un assistant serviable"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Bonjour !",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Conclusion
La capacité de Llama 4 Scout à gérer de longs contextes avec une efficacité inégalée en fait le choix privilégié pour les tâches avancées d’IA. Les API éliminent les défis du déploiement local, offrant une solution fiable, évolutive et économique. En utilisant l’accès par API, les développeurs peuvent exploiter pleinement les capacités de Llama 4 Scout tout en évitant la charge de la gestion de l’infrastructure, leur permettant de se concentrer sur l’innovation et la création de valeur.
Foire aux questions
Qu’est-ce qui rend Llama 4 Scout supérieur aux autres modèles ?
Llama 4 Scout excelle dans le traitement de contextes ultra-longs (par exemple, 10M tokens) avec une efficacité inégalée.
Pourquoi l’exécution locale de Llama 4 Scout est-elle difficile ?
L’exécution locale de Llama 4 Scout nécessite jusqu’à 18,8 To de VRAM et 240 GPU H100, ce qui entraîne des coûts élevés, des problèmes de scalabilité et des défis complexes de communication GPU.
Comment commencer à utiliser Llama 4 Scout via l’API ?
Connectez-vous simplement à Novita AI, sélectionnez Llama 4 Scout dans la bibliothèque de modèles, commencez votre essai gratuit, générez une clé API et intégrez-la dans votre environnement de développement à l’aide des outils fournis.
Novita AI est une plateforme cloud d’IA qui offre aux développeurs un moyen simple de déployer des modèles d’IA via notre API facile à utiliser, tout en fournissant un cloud GPU abordable et fiable pour la construction et le passage à l’échelle.



