

Aspectos destacados
Llama 4 Scout ofrece un rendimiento superior gracias a su capacidad para procesar contextos extremadamente largos, como 10M tokens, lo que lo hace ideal para aplicaciones avanzadas de IA.
Supera a otros modelos en el manejo de inferencias de contexto largo, pero requiere hasta 18.8 TB de VRAM y 240 GPUs H100, lo que dificulta el despliegue local.
Las APIs ofrecen una solución rentable y escalable, eliminando la necesidad de hardware costoso, optimizando la comunicación multi-GPU y garantizando la confiabilidad.
Llama 4 Scout se destaca como un modelo de vanguardia para procesar contextos ultralargos como 10M tokens, superando con creces las capacidades de la mayoría de los modelos. Si bien su rendimiento es incomparable, los requisitos extremos de hardware hacen que el despliegue local sea poco práctico para muchos usuarios.
Requisitos de VRAM de Llama 4 Scout
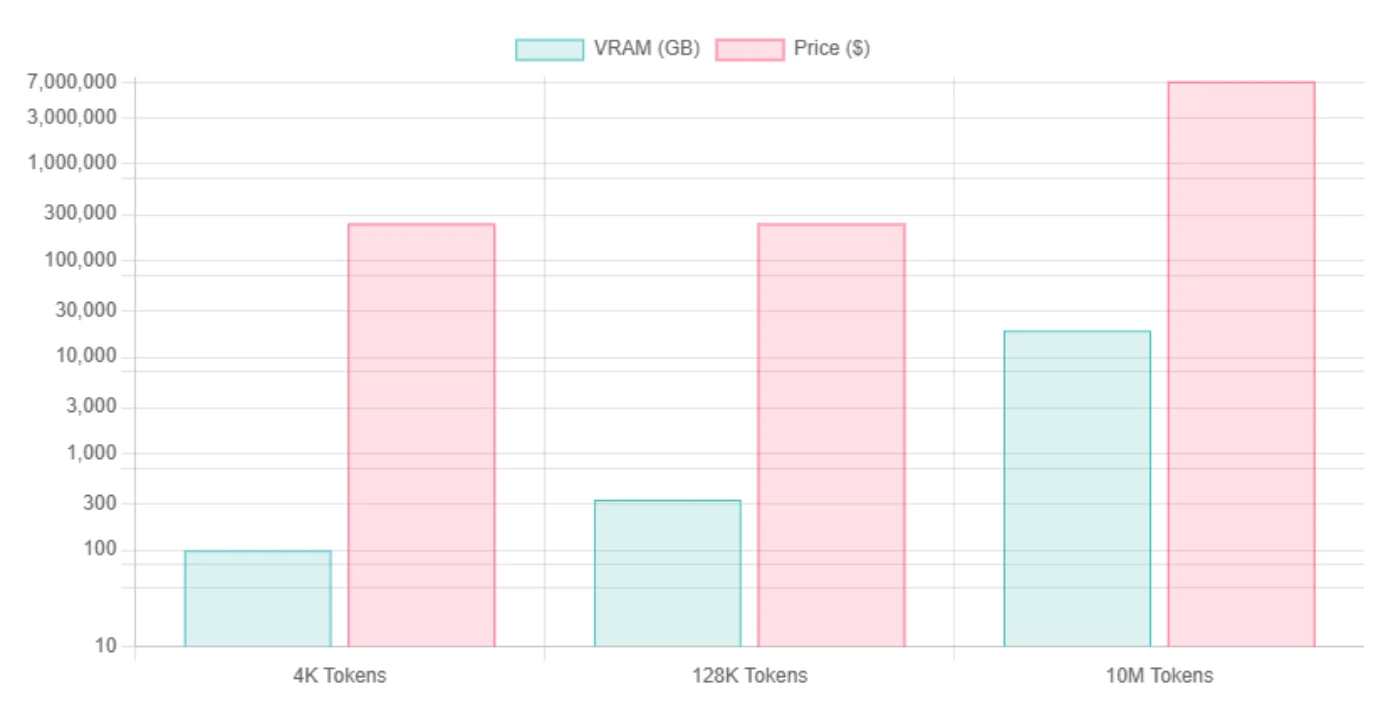
| Longitud de contexto | Llama 4 Scout Int4 VRAM | GPUs necesarias | Llama 4 Scout FP16 VRAM | GPUs necesarias |
| 4K Tokens | ~99.5 GB / ~76.2 GB | H100 | ~345 GB | 8*H100 |
| 128K Tokens | ~334 GB | 8*H100 | ~579 GB | 8*H100 |
| 10M Tokens | Dominado por caché KV, estimado ~18.8 TB | 240*H100 | Igual que INT4, debido al dominio de KV | 240*H100 |
Desafíos de ejecutar Llama 4 Scout localmente
1. Requisitos de memoria del caché KV
- Los contextos extremadamente largos (por ejemplo, 10M tokens) demandan una memoria masiva para almacenar el caché KV, requiriendo hasta 18.8 TB de VRAM incluso en modo INT4. Esto exige un gran clúster de 240 GPUs H100, lo que genera problemas de escalabilidad.
2. Sobrecarga de comunicación multi-GPU
- Con 8 o 240 GPUs, la sobrecarga de comunicación para el almacenamiento y acceso distribuido del caché KV se vuelve significativa, lo que puede ralentizar el rendimiento general.
3. Alto costo y consumo energético
- Ejecutar clústeres de GPU a gran escala, especialmente para 10M tokens, resulta en costos extremadamente altos de hardware, operación y energía, lo que lo hace poco práctico para muchos casos de uso.
4. Eficiencia de inferencia
- Para contextos extremadamente largos (por ejemplo, 128K o 10M tokens), la complejidad computacional aumenta drásticamente. Esto puede provocar una latencia significativa durante la inferencia, que quizás no cumpla con los requisitos de tiempo real.
Soluciones potenciales para ejecutar Llama 4 Scout localmente
1. Optimización del caché KV
- Utilizar un caché KV distribuido para fragmentar los requisitos de memoria en múltiples GPUs.
- Explorar técnicas de gestión de memoria más eficientes, como comprimir el caché KV o almacenar datos de acceso menos frecuente en niveles de memoria más lentos.
2. Mejora de la comunicación multi-GPU
- Aprovechar interconexiones de alto ancho de banda como NVIDIA NVLink o Infiniband para reducir la latencia y acelerar la comunicación entre GPUs.
- Optimizar marcos de computación distribuida como DeepSpeed o Megatron-LM para minimizar la sobrecarga de comunicación y mejorar la escalabilidad.
3. Reducción de costos y consumo energético
- Optimizar la arquitectura del modelo mediante técnicas como mecanismos de atención dispersa para reducir el uso de memoria y la demanda computacional.
- Explorar mejoras de hardware (por ejemplo, futuras arquitecturas de GPU o aceleradores de IA personalizados) que ofrezcan mayor eficiencia.
4. Mejora de la eficiencia de inferencia
- Implementar mecanismos de atención dispersa o procesamiento por partes para manejar contextos largos de manera más eficiente.
- Usar estrategias de caché jerárquica o almacenamiento por niveles para optimizar la gestión del caché KV y reducir la latencia de inferencia.
Acceso por API: una opción rentable para pequeños desarrolladores

Por qué las APIs son una solución sólida
1. Requisitos de caché KV y memoria de GPU
- Solución API: Las APIs manejan todos los requisitos de caché KV y memoria en su infraestructura, eliminando la necesidad de que compres o administres GPUs. Asignan memoria dinámicamente, incluso para contextos extremadamente largos como 10M tokens.
- Por qué es importante: Esto elimina la necesidad de hardware costoso y una gestión compleja de la memoria, permitiéndote centrarte únicamente en usar el modelo.
2. Complejidad de la comunicación multi-GPU
- Solución API: Las APIs optimizan internamente la comunicación multi-GPU utilizando interconexiones avanzadas como NVLink o Infiniband, garantizando un rendimiento eficiente sin necesidad de tu intervención.
- Por qué es importante: Evitas los desafíos técnicos y operativos de configurar y mantener sistemas de GPU distribuidos, mientras te beneficias de un rendimiento fluido.
3. Altos costos de hardware y mantenimiento
- Solución API: Con las APIs, solo pagas por lo que usas mediante un modelo de pago por uso, evitando los costos iniciales de millones de dólares en la compra de hardware de GPU y los gastos de mantenimiento continuo.
- Por qué es importante: Las APIs hacen que la IA de alto rendimiento sea accesible y rentable, especialmente para empresas sin grandes presupuestos o con necesidades de uso poco frecuentes.
4. Escalabilidad para cargas de trabajo grandes
- Solución API: Las APIs se escalan automáticamente para satisfacer las demandas de tu carga de trabajo, ya sea que proceses tareas pequeñas o contextos masivos como 10M tokens. El proveedor asigna recursos dinámicamente según sea necesario.
- Por qué es importante: Esto asegura que tu aplicación pueda manejar picos repentinos de demanda o tareas a gran escala sin requerir actualizaciones de infraestructura ni tiempo de inactividad.
5. Eficiencia de inferencia
- Solución API: Las APIs emplean optimizaciones avanzadas como atención dispersa y paralelización para procesar contextos largos de manera eficiente, entregando resultados más rápido que la mayoría de las configuraciones locales.
- Por qué es importante: Tiempos de inferencia más rápidos mejoran la experiencia del usuario y reducen los tiempos de espera, incluso para aplicaciones exigentes que implican contextos muy largos.
6. Confiabilidad y mantenimiento
- Solución API: Las APIs garantizan una alta confiabilidad al manejar fallos de hardware, actualizaciones y problemas de escalabilidad por su cuenta. Los proveedores garantizan tiempo de actividad y acceso fluido a las últimas versiones del modelo.
- Por qué es importante: No necesitas preocuparte por tiempos de inactividad del sistema, mantenimiento de hardware o actualizaciones manuales, lo que garantiza un servicio ininterrumpido para tu aplicación.
Una API estable y altamente rentable: Novita AI
Paso 1: Inicia sesión y accede a la Biblioteca de Modelos
Inicia sesión en tu cuenta y haz clic en el botón Biblioteca de modelos.

Paso 2: Elige tu modelo
Navega por las opciones disponibles y selecciona el modelo que se adapte a tus necesidades.

Paso 3: Inicia tu prueba gratuita
Comienza tu prueba gratuita para explorar las capacidades del modelo seleccionado.
Paso 4: Obtén tu clave de API
Para autenticarte con la API, te proporcionaremos una nueva clave de API. Ingresa a la página de Configuración y copia la clave de API como se indica en la imagen.

Paso 5: Instala la API
Instala la API utilizando el administrador de paquetes específico de tu lenguaje de programación.

Después de la instalación, importa las bibliotecas necesarias en tu entorno de desarrollo. Inicializa la API con tu clave de API para comenzar a interactuar con Novita AI LLM. Este es un ejemplo de uso de la API de finalización de chat para usuarios de Python.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<YOUR Novita AI API Key>",
)
model = "meta-llama/llama-4-scout-17b-16e-instruct"
stream = True # or False
max_tokens = 2048
system_content = """Be a helpful assistant"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Conclusión
La capacidad de Llama 4 Scout para manejar contextos largos con una eficiencia inigualable lo convierte en la mejor opción para tareas avanzadas de IA. Las APIs eliminan los desafíos del despliegue local, proporcionando una solución confiable, escalable y rentable. Al aprovechar el acceso por API, los desarrolladores pueden utilizar plenamente las capacidades de Llama 4 Scout mientras evitan la carga de la gestión de infraestructura, lo que les permite centrarse en la innovación y la entrega de valor.
Preguntas frecuentes
¿Qué hace que Llama 4 Scout sea superior a otros modelos?
Llama 4 Scout destaca en el procesamiento de contextos ultralargos (por ejemplo, 10M tokens) con una eficiencia inigualable.
¿Por qué es difícil ejecutar Llama 4 Scout localmente?
Ejecutar Llama 4 Scout localmente requiere hasta 18.8 TB de VRAM y 240 GPUs H100, lo que genera altos costos, problemas de escalabilidad y desafíos complejos de comunicación entre GPUs.
¿Cómo empiezo a usar Llama 4 Scout a través de la API?
Simplemente inicia sesión en Novita AI, selecciona Llama 4 Scout en la biblioteca de modelos, comienza tu prueba gratuita, genera una clave de API e intégrala en tu entorno de desarrollo utilizando las herramientas proporcionadas.
Novita AI es una plataforma en la nube de IA que ofrece a los desarrolladores una forma sencilla de implementar modelos de IA mediante nuestra API simple, al mismo tiempo que proporciona una GPU en la nube asequible y confiable para construir y escalar.



