

主なハイライト
Llama 4 Scout は、10Mトークン といった超長大コンテキストを処理できる優れた性能を備えており、先進的なAIアプリケーションに最適です。
長いコンテキスト推論において他のモデルを凌駕しますが、最大 18.8 TBのVRAM と 240基のH100 GPU が必要となるため、ローカルでのデプロイは困難です。
APIは費用対効果が高くスケーラブルなソリューションを提供し、高価なハードウェアを不要にし、マルチGPU通信を最適化し、信頼性を確保します。
Llama 4 Scout は、10Mトークン のような超長大コンテキストを処理する最先端モデルとして際立っており、ほとんどのモデルの性能をはるかに超えています。その性能は比類のないものですが、極端なハードウェア要件により、多くのユーザーにとってローカルデプロイは非現実的です。
Llama 4 Scout のVRAM要件
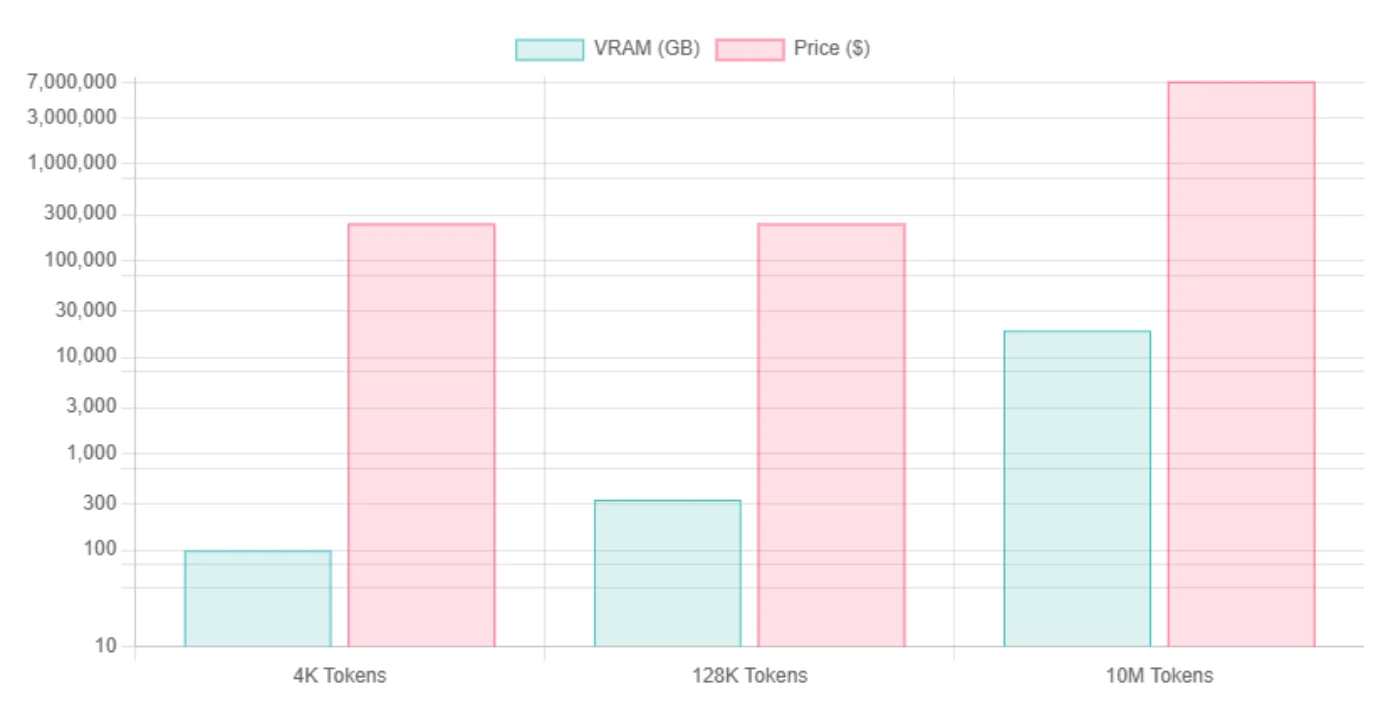
| コンテキスト長 | Llama 4 Scout Int4 VRAM | GPU必要数 | Llama 4 Scout FP16 VRAM | GPU必要数 |
| 4Kトークン | ~99.5 GB / ~76.2 GB | H100 | ~345 GB | 8*H100 |
| 128Kトークン | ~334 GB | 8*H100 | ~579 GB | 8*H100 |
| 10Mトークン | KVキャッシュが支配的、推定 ~18.8 TB | 240*H100 | INT4と同様(KVが支配的なため) | 240*H100 |
Llama 4 Scout をローカルで実行する際の課題
1. KVキャッシュメモリ要件
- 超長大コンテキスト(例:10Mトークン)はKVキャッシュを格納するために莫大なメモリを必要とし、INT4モードでも最大 18.8 TBのVRAM が必要です。これには 240基のH100 GPU からなる大規模クラスタが必要となり、スケーラビリティの問題が生じます。
2. マルチGPU通信のオーバーヘッド
- 8基または240基のGPUの場合、分散KVキャッシュの保存とアクセスにかかる通信オーバーヘッドが大きくなり、全体的なパフォーマンスが低下する可能性があります。
3. 高コストとエネルギー消費
- 特に10Mトークン向けの大規模GPUクラスタの運用は、ハードウェア、運用、エネルギーコストが極めて高くなり、多くのユースケースで実用的ではありません。
4. 推論効率
- 超長大コンテキスト(例:128Kまたは10Mトークン)では、計算の複雑さが劇的に増加します。その結果、推論中のレイテンシーが大幅に増大し、リアルタイム要件を満たせない可能性があります。
Llama 4 Scout をローカルで実行するための潜在的ソリューション
1. KVキャッシュの最適化
- 分散KVキャッシュを使用して、メモリ要件を複数のGPUに分散する。
- KVキャッシュの圧縮や、アクセス頻度の低いデータを低速なメモリ階層に保存するなど、より効率的なメモリ管理技術を模索する。
2. マルチGPU通信の改善
- NVIDIA NVLink や InfiniBand などの高帯域幅インターコネクトを活用し、GPU間のレイテンシーを低減し通信を高速化する。
- DeepSpeed や Megatron-LM などの分散コンピューティングフレームワークを最適化し、通信オーバーヘッドを最小限に抑え、スケーラビリティを向上させる。
3. コストとエネルギー消費の削減
- スパースアテンション機構 などの技術を用いてモデルアーキテクチャを最適化し、メモリ使用量と計算需要を削減する。
- より高い効率を提供する将来のGPUアーキテクチャやカスタムAIアクセラレータなどのハードウェア改良を模索する。
4. 推論効率の向上
- スパースアテンション機構やチャンク処理を実装し、長いコンテキストをより効率的に処理する。
- 階層型キャッシュや階層ストレージ戦略を使用してKVキャッシュ管理を最適化し、推論レイテンシーを低減する。
APIアクセス:小規模開発者にとって費用対効果の高い選択肢

APIが強力なソリューションである理由
1. KVキャッシュとGPUメモリ要件
- APIソリューション: APIはすべてのKVキャッシュとメモリ要件を自社インフラで処理するため、GPUを購入・管理する必要がありません。10Mトークンのような超長大コンテキストでも、メモリを動的に割り当てます。
- 重要性: 高価なハードウェアや複雑なメモリ管理が不要になり、モデルの使用に専念できます。
2. マルチGPU通信の複雑さ
- APIソリューション: APIはNVLinkやInfiniBandなどの高度なインターコネクトを使用してマルチGPU通信を内部で最適化し、ユーザーの介入なしに効率的なパフォーマンスを実現します。
- 重要性: 分散GPUシステムの設定や運用に関する技術的・運用上の課題を回避し、シームレスなパフォーマンスを享受できます。
3. 高いハードウェアと保守コスト
- APIソリューション: APIは従量課金制で、実際に使用した分だけ支払うため、GPUハードウェアの購入にかかる数百万ドル規模の初期費用や継続的な保守費用がかかりません。
- 重要性: 特に予算が限られている企業や使用頻度が低い場合でも、高性能AIへのアクセスが手頃で費用対効果の高いものになります。
4. 大規模ワークロードへのスケーラビリティ
- APIソリューション: APIはワークロードの需要に応じて自動的にスケールし、小さなタスクから10Mトークンのような大規模なコンテキスト処理まで対応します。プロバイダーが必要に応じてリソースを動的に割り当てます。
- 重要性: インフラのアップグレードやダウンタイムなしに、アプリケーションが需要の急増や大規模タスクに対応できるようになります。
5. 推論効率
- APIソリューション: APIはスパースアテンションや並列化などの高度な最適化を採用し、長いコンテキストを効率的に処理し、ほとんどのローカルセットアップよりも高速に結果を提供します。
- 重要性: 推論時間の短縮により、非常に長いコンテキストを含む要求の厳しいアプリケーションでも、ユーザーエクスペリエンスが向上し、待ち時間が短縮されます。
6. 信頼性とメンテナンス
- APIソリューション: APIはハードウェア障害、アップデート、スケーリングの問題を自社側で処理し、高い信頼性を確保します。プロバイダーはアップタイムと最新モデルへのシームレスなアクセスを保証します。
- 重要性: システムのダウンタイム、ハードウェアのメンテナンス、手動アップデートを気にする必要がなく、アプリケーションの中断のないサービスを確保できます。
安定していて非常にコスト効率の良い API – Novita AI
ステップ1:ログインしてモデルライブラリにアクセス
アカウントにログインし、モデルライブラリ ボタンをクリックします。

ステップ2:モデルを選択
利用可能なオプションを参照し、ニーズに合ったモデルを選択します。

ステップ3:無料トライアルを開始
選択したモデルの機能を無料トライアルで試してみましょう。
ステップ4:APIキーを取得
APIで認証するために、新しいAPIキーを提供します。設定 ページに移動し、画像の指示に従ってAPIキーをコピーします。

ステップ5:APIをインストール
お使いのプログラミング言語に応じたパッケージマネージャーを使用してAPIをインストールします。

インストール後、必要なライブラリを開発環境にインポートします。APIキーを使用してAPIを初期化し、Novita AI LLMとの対話を開始します。以下は、Pythonユーザー向けのチャット補完APIの使用例です。
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<YOUR Novita AI API Key>",
)
model = "meta-llama/llama-4-scout-17b-16e-instruct"
stream = True # or False
max_tokens = 2048
system_content = """Be a helpful assistant"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
reponse_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
結論
Llama 4 Scout は長いコンテキストを比類のない効率で処理する能力を持ち、高度なAIタスクに最適な選択肢です。APIはローカルデプロイの課題を排除し、信頼性が高くスケーラブルで費用対効果の高いソリューションを提供します。APIアクセスを活用することで、開発者はインフラ管理の負担を回避しながらLlama 4 Scoutの機能を最大限に活用し、イノベーションと価値の提供に集中できます。
よくある質問
Llama 4 Scout が他のモデルより優れている点は何ですか?
Llama 4 Scout は超長大コンテキスト(例:10Mトークン)を比類のない効率で処理することに優れています。
Llama 4 Scout をローカルで実行するのが難しい理由は?
Llama 4 Scout をローカルで実行するには、最大 18.8 TBのVRAM と 240基のH100 GPU が必要であり、高コスト、スケーラビリティの問題、複雑なGPU通信の課題が生じます。
APIを介してLlama 4 Scoutを使い始めるにはどうすればよいですか?
Novita AI にログインし、モデルライブラリからLlama 4 Scoutを選択し、無料トライアルを開始し、APIキーを生成し、提供されたツールを使用して開発環境に統合するだけです。
Novita AI は、開発者がシンプルなAPIを使用してAIモデルを簡単にデプロイできるようにするAIクラウドプラットフォームであり、手頃で信頼性の高いGPUクラウドをビルドとスケーリングに提供します。



