

주요 포인트
Llama 4 Scout 는 10M 토큰 과 같은 매우 긴 컨텍스트를 처리하는 능력으로 뛰어난 성능을 제공하며, 고급 AI 애플리케이션에 이상적입니다.
긴 컨텍스트 추론 처리에서 다른 모델을 능가하지만, 최대 18.8TB의 VRAM 과 240개의 H100 GPU 가 필요하므로 로컬 배포가 어렵습니다.
API는 값비싼 하드웨어를 없애고 멀티 GPU 통신을 최적화하며 안정성을 보장하는 비용 효율적이고 확장 가능한 솔루션을 제공합니다.
Llama 4 Scout 는 10M 토큰 과 같은 초장기 컨텍스트를 처리하는 최첨단 모델로, 대부분의 모델 능력을 훨씬 뛰어넘습니다. 성능은 타의 추종을 불허하지만 극단적인 하드웨어 요구 사항으로 인해 많은 사용자에게 로컬 배포가 비현실적입니다.
Llama 4 Scout VRAM 요구 사항
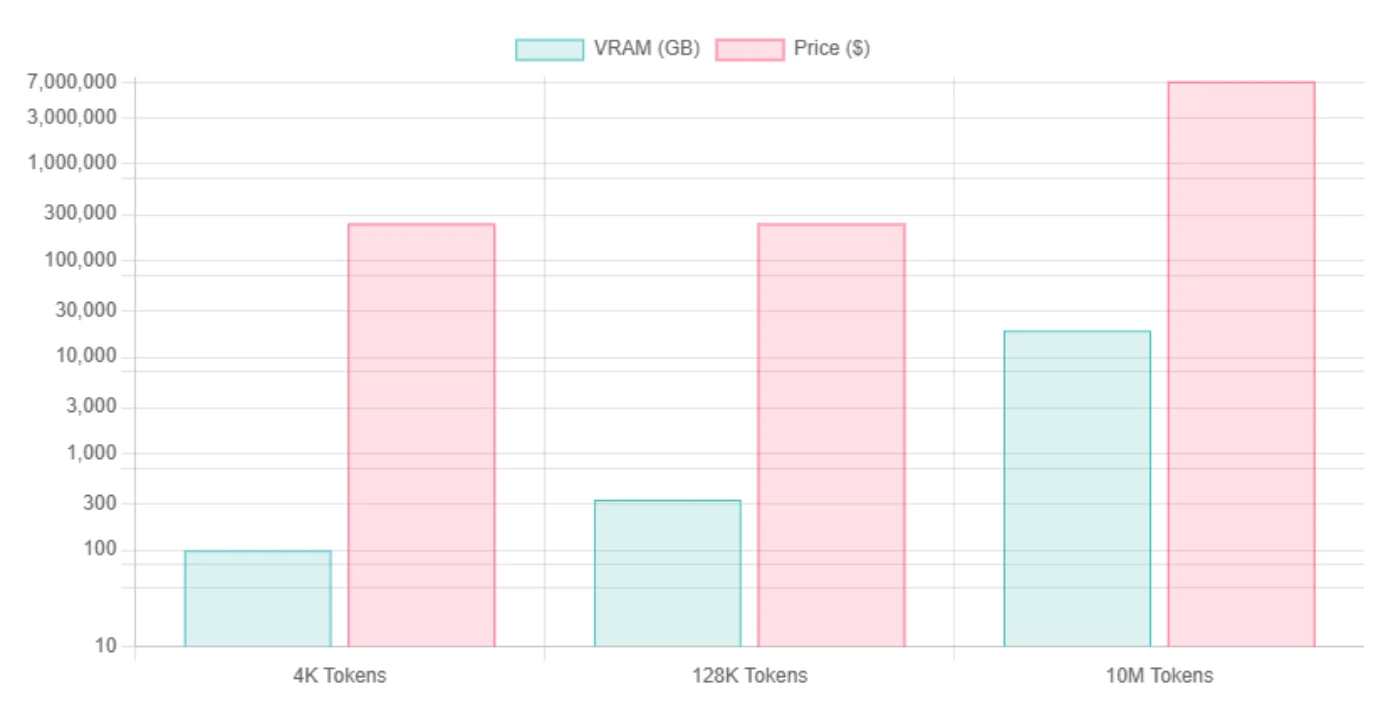
| 컨텍스트 길이 | Llama 4 Scout Int4 VRAM | 필요 GPU 수 | Llama 4 Scout FP16 VRAM | 필요 GPU 수 |
| 4K 토큰 | ~99.5 GB / ~76.2 GB | H100 | ~345 GB | 8*H100 |
| 128K 토큰 | ~334 GB | 8*H100 | ~579 GB | 8*H100 |
| 10M 토큰 | KV 캐시가 지배적, 약 ~18.8 TB로 추정 | 240*H100 | INT4와 동일 (KV가 지배적이므로) | 240*H100 |
Llama 4 Scout를 로컬에서 실행할 때의 과제
1. KV 캐시 메모리 요구 사항
- 매우 긴 컨텍스트(예: 10M 토큰)는 KV 캐시 저장을 위해 막대한 메모리를 필요로 하며, INT4 모드에서도 최대 18.8TB VRAM 이 필요합니다. 이는 240개의 H100 GPU 로 구성된 대규모 GPU 클러스터를 필요로 하여 확장성 문제를 초래합니다.
2. 멀티 GPU 통신 오버헤드
- 8개 또는 240개의 GPU를 사용할 경우 분산 KV 캐시 저장 및 액세스를 위한 통신 오버헤드가 상당해져 전체 성능을 저하시킬 수 있습니다.
3. 높은 비용과 에너지 소비
- 대규모 GPU 클러스터, 특히 10M 토큰을 실행하면 하드웨어, 운영 및 에너지 비용이 매우 높아져 많은 사용 사례에 비현실적입니다.
4. 추론 효율성
- 매우 긴 컨텍스트(예: 128K 또는 10M 토큰)의 경우 계산 복잡성이 급격히 증가합니다. 이는 추론 중 상당한 지연 시간을 초래할 수 있으며 실시간 요구 사항을 충족하지 못할 수 있습니다.
Llama 4 Scout 로컬 실행을 위한 잠재적 솔루션
1. KV 캐시 최적화
- 분산 KV 캐시를 사용하여 메모리 요구 사항을 여러 GPU에 분할합니다.
- KV 캐시 압축 또는 덜 자주 액세스하는 데이터를 느린 메모리 계층에 저장하는 등 보다 효율적인 메모리 관리 기술을 탐색합니다.
2. 멀티 GPU 통신 개선
- NVIDIA NVLink 또는 Infiniband 와 같은 고대역폭 상호 연결을 활용하여 지연 시간을 줄이고 GPU 간 통신 속도를 높입니다.
- DeepSpeed 또는 Megatron-LM 과 같은 분산 컴퓨팅 프레임워크를 최적화하여 통신 오버헤드를 최소화하고 확장성을 개선합니다.
3. 비용 및 에너지 소비 절감
- 희소 주의 메커니즘(sparse attention mechanisms) 과 같은 기술을 사용하여 모델 아키텍처를 최적화하고 메모리 사용량과 계산 요구 사항을 줄입니다.
- 더 높은 효율성을 제공하는 하드웨어 개선(예: 차세대 GPU 아키텍처 또는 맞춤형 AI 가속기)을 탐색합니다.
4. 추론 효율성 향상
- 희소 주의 메커니즘 또는 청크 처리를 구현하여 긴 컨텍스트를 보다 효율적으로 처리합니다.
- 계층적 캐싱 또는 계층화된 저장 전략을 사용하여 KV 캐시 관리를 최적화하고 추론 지연 시간을 줄입니다.
API 접근: 소규모 개발자를 위한 비용 효율적인 선택

API가 강력한 솔루션인 이유
1. KV 캐시 및 GPU 메모리 요구 사항
- API 솔루션: API는 인프라에서 모든 KV 캐시 및 메모리 요구 사항을 처리하므로 GPU를 구매하거나 관리할 필요가 없습니다. 10M 토큰과 같은 매우 긴 컨텍스트에서도 메모리를 동적으로 할당합니다.
- 중요한 이유: 값비싼 하드웨어와 복잡한 메모리 관리가 필요 없어져 모델 사용에만 집중할 수 있습니다.
2. 멀티 GPU 통신 복잡성
- API 솔루션: API는 NVLink 또는 Infiniband와 같은 고급 상호 연결을 사용하여 내부적으로 멀티 GPU 통신을 최적화하므로 사용자의 개입 없이 효율적인 성능을 보장합니다.
- 중요한 이유: 분산 GPU 시스템을 구성하고 유지 관리하는 기술적, 운영적 문제를 피하면서 원활한 성능을 누릴 수 있습니다.
3. 높은 하드웨어 및 유지 관리 비용
- API 솔루션: API를 사용하면 사용한 만큼만 지불하는 종량제 모델을 통해 GPU 하드웨어 구매에 필요한 수백만 달러의 초기 비용과 지속적인 유지 관리 비용을 피할 수 있습니다.
- 중요한 이유: API는 특히 예산이 부족하거나 사용 빈도가 낮은 기업에게 고성능 AI를 접근 가능하고 비용 효율적으로 만듭니다.
4. 대규모 워크로드를 위한 확장성
- API 솔루션: API는 소규모 작업을 처리하든 10M 토큰과 같은 대규모 컨텍스트를 처리하든 워크로드 요구에 맞게 자동으로 확장됩니다. 제공자가 필요에 따라 리소스를 동적으로 할당합니다.
- 중요한 이유: 인프라 업그레이드나 다운타임 없이 애플리케이션이 갑작스러운 수요 급증이나 대규모 작업을 처리할 수 있습니다.
5. 추론 효율성
- API 솔루션: API는 희소 주의 및 병렬화와 같은 고급 최적화를 사용하여 긴 컨텍스트를 효율적으로 처리하며, 대부분의 로컬 설정보다 빠르게 결과를 제공합니다.
- 중요한 이유: 더 빠른 추론 시간은 사용자 경험을 개선하고 매우 긴 컨텍스트를 포함하는 까다로운 애플리케이션에서도 대기 시간을 줄입니다.
6. 안정성 및 유지 관리
- API 솔루션: API는 하드웨어 장애, 업데이트 및 확장 문제를 자체적으로 처리하여 높은 안정성을 보장합니다. 제공자는 가동 시간과 최신 모델 버전에 대한 원활한 액세스를 보장합니다.
- 중요한 이유: 시스템 다운타임, 하드웨어 유지 관리 또는 수동 업데이트에 대한 걱정 없이 애플리케이션에 중단 없는 서비스를 보장할 수 있습니다.
안정적이고 비용 효율적인 API-Novita AI
1단계: 로그인 및 모델 라이브러리 접근
계정에 로그인하고 모델 라이브러리 버튼을 클릭합니다.

2단계: 모델 선택
사용 가능한 옵션을 살펴보고 필요에 맞는 모델을 선택합니다.

3단계: 무료 체험 시작
선택한 모델의 기능을 탐색하기 위해 무료 체험을 시작합니다.
4단계: API 키 받기
API 인증을 위해 새 API 키를 제공합니다. “설정” 페이지로 이동하여 이미지에 표시된 대로 API 키를 복사할 수 있습니다.

5단계: API 설치
프로그래밍 언어에 맞는 패키지 관리자를 사용하여 API를 설치합니다.

설치 후 개발 환경에 필요한 라이브러리를 가져옵니다. API 키로 API를 초기화하여 Novita AI LLM과 상호 작용을 시작합니다. 다음은 Python 사용자를 위한 채팅 완성 API 사용 예시입니다.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<YOUR Novita AI API Key>",
)
model = "meta-llama/llama-4-scout-17b-16e-instruct"
stream = True # or False
max_tokens = 2048
system_content = """Be a helpful assistant"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
결론
Llama 4 Scout는 긴 컨텍스트를 타의 추종을 불허하는 효율성으로 처리하는 능력 덕분에 고급 AI 작업에 최고의 선택입니다. API는 로컬 배포의 어려움을 제거하고 안정적이고 확장 가능하며 비용 효율적인 솔루션을 제공합니다. API 액세스를 활용함으로써 개발자는 인프라 관리의 부담 없이 Llama 4 Scout의 기능을 최대한 활용하여 혁신과 가치 창출에 집중할 수 있습니다.
자주 묻는 질문
Llama 4 Scout가 다른 모델보다 뛰어난 이유는 무엇인가요?
Llama 4 Scout는 초장기 컨텍스트(예: 10M 토큰)를 타의 추종을 불허하는 효율성으로 처리하는 데 탁월합니다.
Llama 4 Scout를 로컬에서 실행하기 어려운 이유는 무엇인가요?
Llama 4 Scout를 로컬에서 실행하려면 최대 18.8TB의 VRAM 과 240개의 H100 GPU 가 필요하므로 높은 비용, 확장성 문제 및 복잡한 GPU 통신 문제가 발생합니다.
API를 통해 Llama 4 Scout를 어떻게 사용할 수 있나요?
Novita AI에 로그인하고 모델 라이브러리에서 Llama 4 Scout를 선택한 후 무료 체험을 시작하고 API 키를 생성한 다음 제공된 도구를 사용하여 개발 환경에 통합하기만 하면 됩니다.
Novita AI는 간단한 API를 통해 개발자가 AI 모델을 쉽게 배포할 수 있는 AI 클라우드 플랫폼이며, 구축 및 확장을 위한 저렴하고 안정적인 GPU 클라우드도 제공합니다.



