

Principais Destaques
Llama 4 Scout oferece desempenho superior com sua capacidade de processar contextos extremamente longos, como 10M de tokens, tornando-o ideal para aplicações avançadas de IA.
Ele supera outros modelos no manuseio de inferência de contexto longo, mas requer até 18,8 TB de VRAM e 240 GPUs H100, tornando a implantação local desafiadora.
As APIs fornecem uma solução econômica e escalável, eliminando a necessidade de hardware caro, otimizando a comunicação multi-GPU e garantindo confiabilidade.
Llama 4 Scout destaca-se como um modelo de ponta para processar contextos ultra-longos, como 10M de tokens, superando em muito as capacidades da maioria dos modelos. Embora seu desempenho seja incomparável, os requisitos extremos de hardware tornam a implantação local impraticável para muitos usuários.
Requisitos de VRAM do Llama 4 Scout
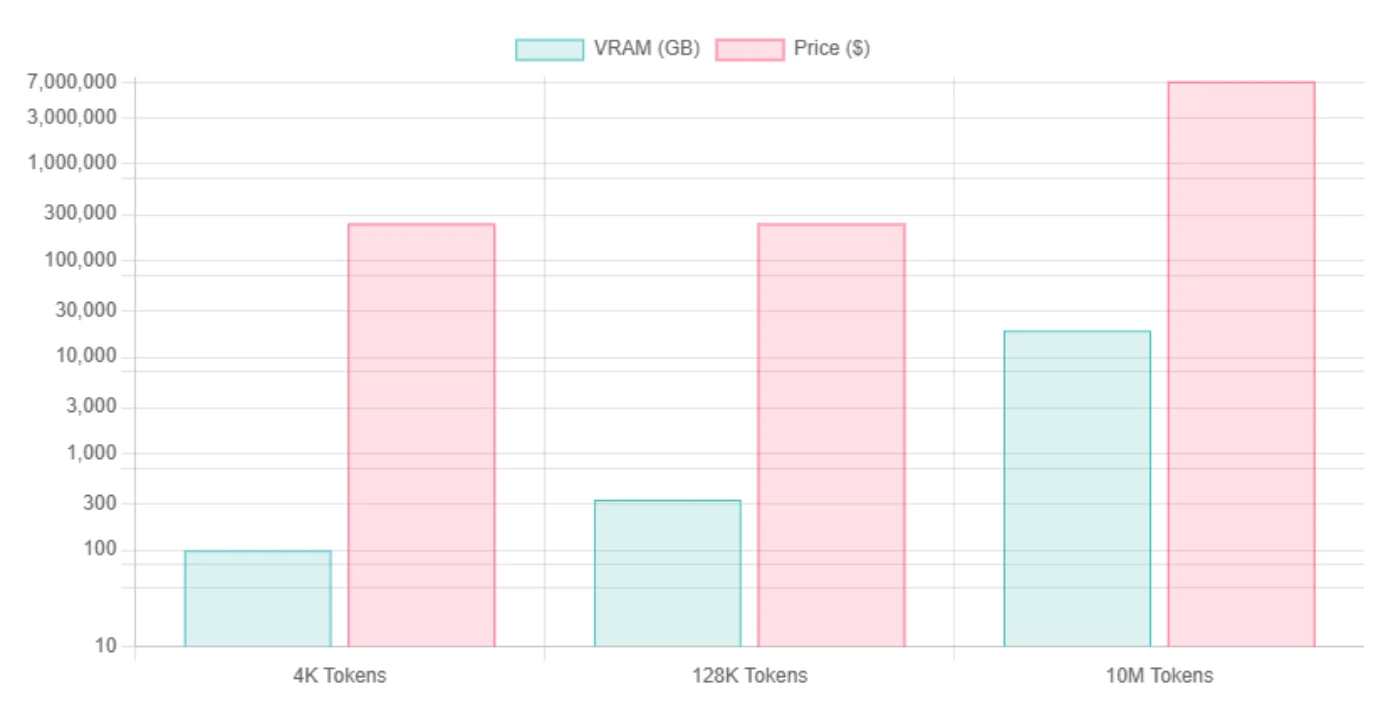
| Comprimento do contexto | Llama 4 Scout VRAM Int4 | Necessidades de GPU | Llama 4 Scout VRAM FP16 | Necessidades de GPU |
| 4K Tokens | ~99,5 GB / ~76,2 GB | H100 | ~345 GB | 8*H100 |
| 128K Tokens | ~334 GB | 8*H100 | ~579 GB | 8*H100 |
| 10M Tokens | Dominado pelo Cache KV, estimado ~18,8 TB | 240*H100 | Igual ao INT4, devido à dominância do KV | 240*H100 |
Desafios de Executar o Llama 4 Scout Localmente
1. Requisitos de Memória do Cache KV
- Contextos extremamente longos (por exemplo, 10M de Tokens) exigem memória massiva para armazenar o cache KV, necessitando de até 18,8 TB de VRAM mesmo em modo INT4. Isso exige um grande cluster de GPUs de 240 H100, levando a problemas de escalabilidade.
2. Sobrecarga de Comunicação Multi-GPU
- Com 8 ou 240 GPUs, a sobrecarga de comunicação para armazenamento e acesso distribuído do cache KV torna-se significativa, potencialmente diminuindo o desempenho geral.
3. Alto Custo e Consumo de Energia
- A execução de clusters de GPU em grande escala, especialmente para 10M de Tokens, resulta em custos extremamente altos de hardware, operação e energia, tornando-a impraticável para muitos casos de uso.
4. Eficiência de Inferência
- Para contextos extremamente longos (por exemplo, 128K ou 10M de Tokens), a complexidade computacional aumenta drasticamente. Isso pode resultar em latência significativa durante a inferência, que pode não atender aos requisitos em tempo real.
Soluções Potenciais para Executar o Llama 4 Scout Localmente
1. Otimizando o Cache KV
- Use cache KV distribuído para dividir os requisitos de memória entre várias GPUs.
- Explore técnicas de gerenciamento de memória mais eficientes, como comprimir o cache KV ou armazenar dados menos acessados em camadas de memória mais lentas.
2. Melhorando a Comunicação Multi-GPU
- Aproveite interconexões de alta largura de banda como NVIDIA NVLink ou Infiniband para reduzir latência e acelerar a comunicação entre GPUs.
- Otimize frameworks de computação distribuída como DeepSpeed ou Megatron-LM para minimizar a sobrecarga de comunicação e melhorar a escalabilidade.
3. Reduzindo Custo e Consumo de Energia
- Otimize a arquitetura do modelo usando técnicas como mecanismos de atenção esparsa para reduzir o uso de memória e a demanda computacional.
- Explore melhorias de hardware (por exemplo, futuras arquiteturas de GPU ou aceleradores de IA personalizados) que ofereçam maior eficiência.
4. Melhorando a Eficiência de Inferência
- Implemente mecanismos de atenção esparsa ou processamento em partes para lidar com contextos longos de forma mais eficiente.
- Use cache hierárquico ou estratégias de armazenamento em camadas para otimizar o gerenciamento do cache KV e reduzir a latência de inferência.
Acesso via API: Uma Escolha Econômica para Pequenos Desenvolvedores

Por que APIs São uma Solução Robusta
1. Requisitos de Cache KV e Memória GPU
- Solução da API: As APIs lidam com todos os requisitos de cache KV e memória em sua infraestrutura, eliminando a necessidade de você adquirir ou gerenciar GPUs. Elas alocam memória dinamicamente, mesmo para contextos extremamente longos como 10M de tokens.
- Por que é Importante: Isso elimina a necessidade de hardware caro e gerenciamento complexo de memória, permitindo que você se concentre apenas em usar o modelo.
2. Complexidade de Comunicação Multi-GPU
- Solução da API: As APIs otimizam a comunicação multi-GPU internamente usando interconexões avançadas como NVLink ou Infiniband, garantindo desempenho eficiente sem exigir sua intervenção.
- Por que é Importante: Você evita os desafios técnicos e operacionais de configurar e manter sistemas de GPU distribuídos, enquanto se beneficia de desempenho contínuo.
3. Altos Custos de Hardware e Manutenção
- Solução da API: Com APIs, você paga apenas pelo que usa por meio de um modelo de pagamento conforme o uso, evitando os custos iniciais de milhões de dólares na compra de hardware GPU e despesas contínuas de manutenção.
- Por que é Importante: As APIs tornam a IA de alto desempenho acessível e econômica, especialmente para empresas sem grandes orçamentos ou com necessidades de uso pouco frequente.
4. Escalabilidade para Grandes Cargas de Trabalho
- Solução da API: As APIs escalam automaticamente para atender às demandas da sua carga de trabalho, seja processando pequenas tarefas ou contextos massivos como 10M de tokens. O provedor aloca recursos dinamicamente conforme necessário.
- Por que é Importante: Isso garante que sua aplicação possa lidar com picos repentinos de demanda ou tarefas de grande escala sem exigir upgrades de infraestrutura ou tempo de inatividade.
5. Eficiência de Inferência
- Solução da API: As APIs empregam otimizações avançadas como atenção esparsa e paralelização para processar contextos longos de forma eficiente, entregando resultados mais rápido do que a maioria das configurações locais.
- Por que é Importante: Tempos de inferência mais rápidos melhoram a experiência do usuário e reduzem os tempos de espera, mesmo para aplicações exigentes que envolvem contextos muito longos.
6. Confiabilidade e Manutenção
- Solução da API: As APIs garantem alta confiabilidade ao lidar com falhas de hardware, atualizações e problemas de escalabilidade internamente. Os provedores garantem tempo de atividade e acesso contínuo às versões mais recentes do modelo.
- Por que é Importante: Você não precisa se preocupar com tempo de inatividade do sistema, manutenção de hardware ou atualizações manuais, garantindo serviço ininterrupto para sua aplicação.
Uma API Estável e Altamente Econômica – Novita AI
Passo 1: Faça Login e Acesse a Biblioteca de Modelos
Faça login em sua conta e clique no botão Model Library.

Experimente o Llama 4 Scout Agora!
Passo 2: Escolha Seu Modelo
Navegue pelas opções disponíveis e selecione o modelo que atende às suas necessidades.

Passo 3: Inicie Seu Teste Gratuito
Comece seu teste gratuito para explorar as capacidades do modelo selecionado.
Passo 4: Obtenha Sua Chave de API
Para autenticar com a API, forneceremos uma nova chave de API. Acesse a página “Settings“ e copie a chave de API conforme indicado na imagem.

Passo 5: Instale a API
Instale a API usando o gerenciador de pacotes específico para sua linguagem de programação.

Após a instalação, importe as bibliotecas necessárias para seu ambiente de desenvolvimento. Inicialize a API com sua chave de API para começar a interagir com o Novita AI LLM. Este é um exemplo de uso da API de chat completions para usuários Python.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<YOUR Novita AI API Key>",
)
model = "meta-llama/llama-4-scout-17b-16e-instruct"
stream = True # or False
max_tokens = 2048
system_content = """Be a helpful assistant"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Conclusão
A capacidade do Llama 4 Scout de lidar com contextos longos com eficiência incomparável o torna a melhor escolha para tarefas avançadas de IA. As APIs eliminam os desafios da implantação local, fornecendo uma solução confiável, escalável e econômica. Ao aproveitar o acesso via API, os desenvolvedores podem utilizar totalmente as capacidades do Llama 4 Scout enquanto evitam o fardo do gerenciamento de infraestrutura, permitindo que se concentrem na inovação e na entrega de valor.
Perguntas Frequentes
O que torna o Llama 4 Scout superior a outros modelos?
O Llama 4 Scout se destaca no processamento de contextos ultra-longos (por exemplo, 10M de tokens) com eficiência incomparável.
Por que é difícil executar o Llama 4 Scout localmente?
Executar o Llama 4 Scout localmente requer até 18,8 TB de VRAM e 240 GPUs H100, resultando em altos custos, problemas de escalabilidade e desafios complexos de comunicação GPU.
Como começo a usar o Llama 4 Scout via API?
Basta fazer login na Novita AI, selecionar o Llama 4 Scout na biblioteca de modelos, iniciar seu teste gratuito, gerar uma chave de API e integrá-la ao seu ambiente de desenvolvimento usando as ferramentas fornecidas.
Novita AI é uma plataforma de nuvem de IA que oferece aos desenvolvedores uma maneira fácil de implantar modelos de IA usando nossa API simples, além de fornecer uma nuvem GPU acessível e confiável para construir e escalar.



