

Основные моменты
Llama 4 Scout предлагает превосходную производительность благодаря возможности обработки чрезвычайно длинных контекстов, например 10 млн токенов, что делает её идеальной для продвинутых AI-приложений.
Она превосходит другие модели в обработке длинных контекстов, но требует до 18,8 ТБ VRAM и 240 GPU H100, что делает локальное развёртывание сложной задачей.
API предоставляют экономичное и масштабируемое решение, устраняя необходимость в дорогостоящем оборудовании, оптимизируя связь между несколькими GPU и обеспечивая надёжность.
Llama 4 Scout выделяется как передовая модель для обработки сверхдлинных контекстов, таких как 10 млн токенов, значительно превосходя возможности большинства моделей. Несмотря на её непревзойдённую производительность, экстремальные аппаратные требования делают локальное развёртывание непрактичным для многих пользователей.
Требования Llama 4 Scout к VRAM
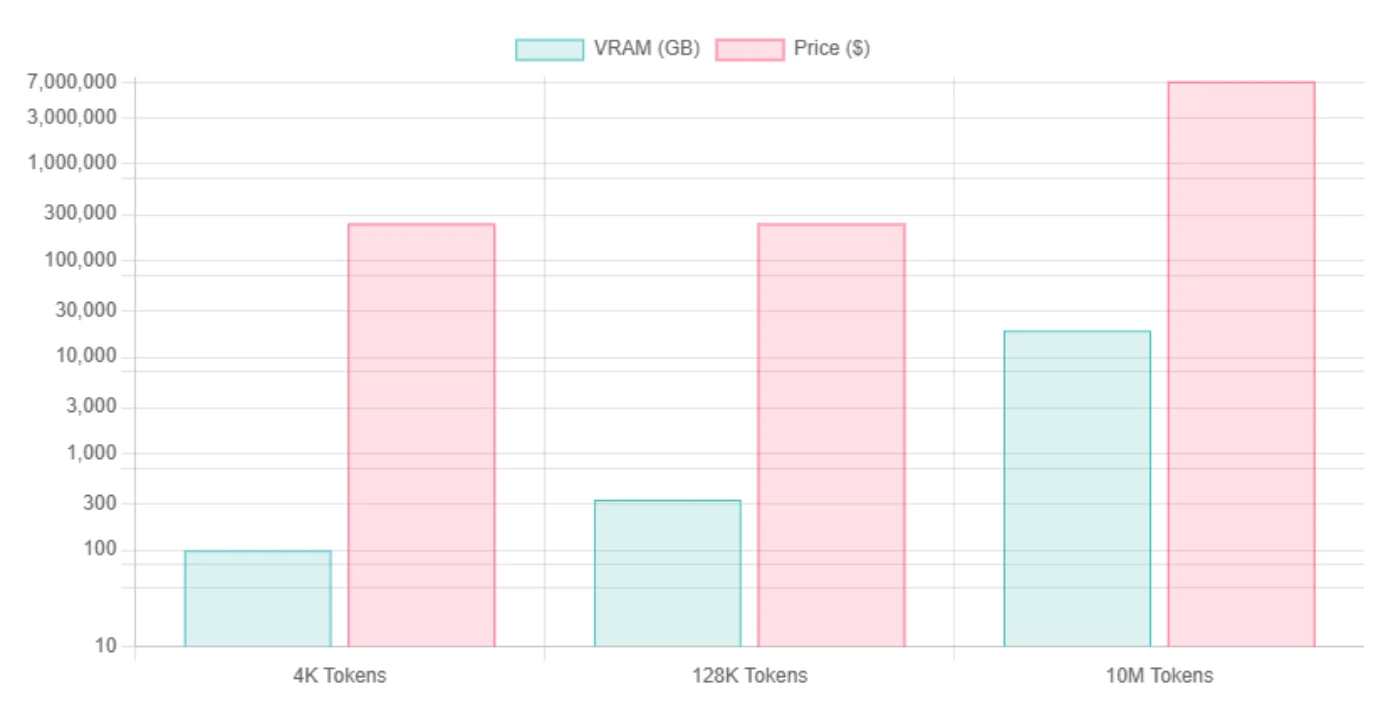
| Длина контекста | Llama 4 Scout Int4 VRAM | Необходимо GPU | Llama 4 Scout FP16 VRAM | Необходимо GPU |
| 4K токенов | ~99,5 ГБ / ~76,2 ГБ | H100 | ~345 ГБ | 8*H100 |
| 128K токенов | ~334 ГБ | 8*H100 | ~579 ГБ | 8*H100 |
| 10M токенов | Доминирует KV-кеш, приблизительно ~18,8 ТБ | 240*H100 | То же, что и INT4, из-за доминирования KV | 240*H100 |
Проблемы локального запуска Llama 4 Scout
1. Требования к памяти KV-кеша
- Чрезвычайно длинные контексты (например, 10 млн токенов) требуют огромного объёма памяти для хранения KV-кеша — до 18,8 ТБ VRAM даже в режиме INT4. Это требует использования большого кластера GPU из 240 H100, что приводит к проблемам масштабирования.
2. Накладные расходы на связь между несколькими GPU
- При использовании 8 или 240 GPU накладные расходы на передачу данных для распределённого хранения и доступа к KV-кешу становятся значительными, что может замедлить общую производительность.
3. Высокая стоимость и энергопотребление
- Запуск крупномасштабных кластеров GPU, особенно для 10 млн токенов, приводит к чрезвычайно высоким затратам на оборудование, эксплуатацию и электроэнергию, что делает его непрактичным для многих сценариев использования.
4. Эффективность инференса
- Для чрезвычайно длинных контекстов (например, 128K или 10M токенов) вычислительная сложность значительно возрастает. Это может привести к значительным задержкам при инференсе, что не соответствует требованиям реального времени.
Потенциальные решения для локального запуска Llama 4 Scout
1. Оптимизация KV-кеша
- Используйте распределённый KV-кеш для разделения требований к памяти между несколькими GPU.
- Изучите более эффективные методы управления памятью, такие как сжатие KV-кеша или хранение реже используемых данных на более медленных уровнях памяти.
2. Улучшение связи между несколькими GPU
- Используйте высокоскоростные межсоединения, такие как NVIDIA NVLink или Infiniband, для уменьшения задержки и ускорения обмена данными между GPU.
- Оптимизируйте распределённые вычислительные фреймворки, такие как DeepSpeed или Megatron-LM, чтобы минимизировать накладные расходы на связь и улучшить масштабируемость.
3. Снижение стоимости и энергопотребления
- Оптимизируйте архитектуру модели с помощью таких методов, как механизмы разреженного внимания, чтобы уменьшить использование памяти и вычислительные требования.
- Изучите аппаратные улучшения (например, будущие архитектуры GPU или специализированные AI-ускорители), обеспечивающие более высокую эффективность.
4. Повышение эффективности инференса
- Внедрите механизмы разреженного внимания или обработку чанками для более эффективной работы с длинными контекстами.
- Используйте стратегии иерархического кеширования или многоуровневого хранения для оптимизации управления KV-кешем и снижения задержки инференса.
API-доступ: экономичный выбор для небольших разработчиков

Почему API — это надёжное решение
1. Требования к KV-кешу и памяти GPU
- Решение через API: API берут на себя все требования к KV-кешу и памяти на своей инфраструктуре, избавляя вас от необходимости приобретать или управлять GPU. Они динамически выделяют память даже для чрезвычайно длинных контекстов, таких как 10 млн токенов.
- Почему это важно: Это устраняет необходимость в дорогом оборудовании и сложном управлении памятью, позволяя вам сосредоточиться исключительно на использовании модели.
2. Сложность связи между несколькими GPU
- Решение через API: API внутренне оптимизируют связь между несколькими GPU, используя передовые межсоединения, такие как NVLink или Infiniband, обеспечивая эффективную производительность без вашего вмешательства.
- Почему это важно: Вы избегаете технических и эксплуатационных проблем настройки и обслуживания распределённых GPU-систем, получая при этом бесшовную производительность.
3. Высокие затраты на оборудование и обслуживание
- Решение через API: С API вы платите только за то, что используете, по модели оплаты по мере использования, избегая многомиллионных первоначальных затрат на покупку GPU-оборудования и текущих расходов на обслуживание.
- Почему это важно: API делают высокопроизводительный AI доступным и экономически эффективным, особенно для компаний с ограниченным бюджетом или нерегулярными потребностями в использовании.
4. Масштабируемость для больших нагрузок
- Решение через API: API автоматически масштабируются в соответствии с вашими рабочими нагрузками, будь то небольшие задачи или огромные контексты, такие как 10 млн токенов. Провайдер динамически выделяет ресурсы по мере необходимости.
- Почему это важно: Это гарантирует, что ваше приложение сможет обрабатывать внезапные скачки спроса или крупномасштабные задачи без необходимости модернизации инфраструктуры или простоев.
5. Эффективность инференса
- Решение через API: API применяют передовые методы оптимизации, такие как разреженное внимание и параллельная обработка, для эффективной обработки длинных контекстов, обеспечивая результаты быстрее, чем большинство локальных установок.
- Почему это важно: Более быстрое время инференса улучшает пользовательский опыт и сокращает время ожидания даже для требовательных приложений, работающих с очень длинными контекстами.
6. Надёжность и обслуживание
- Решение через API: API обеспечивают высокую надёжность, беря на себя обработку сбоев оборудования, обновлений и проблем масштабирования. Провайдеры гарантируют бесперебойную работу и доступ к последним версиям моделей.
- Почему это важно: Вам не нужно беспокоиться о простоях системы, обслуживании оборудования или ручных обновлениях, что обеспечивает непрерывное обслуживание вашего приложения.
Стабильный и высокоэкономичный API — Novita AI
Шаг 1: Войдите в систему и откройте библиотеку моделей
Войдите в свою учётную запись и нажмите кнопку «Библиотека моделей».

Попробуйте Llama 4 Scout сейчас!
Шаг 2: Выберите модель
Просмотрите доступные варианты и выберите модель, соответствующую вашим потребностям.

Шаг 3: Начните бесплатную пробную версию
Начните бесплатную пробную версию, чтобы изучить возможности выбранной модели.
Шаг 4: Получите API-ключ
Для аутентификации в API мы предоставим вам новый API-ключ. Перейдя на страницу «Настройки», вы можете скопировать API-ключ, как показано на изображении.

Шаг 5: Установите API
Установите API с помощью менеджера пакетов, соответствующего вашему языку программирования.

После установки импортируйте необходимые библиотеки в вашу среду разработки. Инициализируйте API с вашим API-ключом, чтобы начать взаимодействие с Novita AI LLM. Ниже приведён пример использования API чат-дополнений для пользователей Python.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<YOUR Novita AI API Key>",
)
model = "meta-llama/llama-4-scout-17b-16e-instruct"
stream = True # or False
max_tokens = 2048
system_content = """Be a helpful assistant"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Заключение
Способность Llama 4 Scout обрабатывать длинные контексты с непревзойдённой эффективностью делает её лучшим выбором для продвинутых AI-задач. API устраняют проблемы локального развёртывания, предоставляя надёжное, масштабируемое и экономичное решение. Используя API-доступ, разработчики могут полностью реализовать возможности Llama 4 Scout, избегая бремени управления инфраструктурой, что позволяет сосредоточиться на инновациях и создании ценности.
Часто задаваемые вопросы
Что делает Llama 4 Scout лучше других моделей?
Llama 4 Scout превосходно обрабатывает сверхдлинные контексты (например, 10 млн токенов) с непревзойдённой эффективностью.
Почему локальный запуск Llama 4 Scout затруднён?
Локальный запуск Llama 4 Scout требует до 18,8 ТБ VRAM и 240 GPU H100, что приводит к высоким затратам, проблемам масштабирования и сложностям с коммуникацией между GPU.
Как начать использовать Llama 4 Scout через API?
Просто войдите в Novita AI, выберите Llama 4 Scout в библиотеке моделей, начните бесплатную пробную версию, сгенерируйте API-ключ и интегрируйте его в вашу среду разработки с помощью предоставленных инструментов.
Novita AI — это облачная AI-платформа, которая предоставляет разработчикам простой способ развёртывания AI-моделей через простой API, а также предлагает доступные и надёжные GPU-облака для создания и масштабирования.



