

النقاط الرئيسية
يقدم Llama 4 Scout أداءً متفوقًا بفضل قدرته على معالجة سياقات طويلة للغاية، مثل 10 ملايين رمز، مما يجعله مثاليًا لتطبيقات الذكاء الاصطناعي المتقدمة.
يتفوق على النماذج الأخرى في معالجة الاستدلال بالسياقات الطويلة، لكنه يتطلب ما يصل إلى 18.8 تيرابايت من VRAM و 240 وحدة معالجة رسومية H100، مما يجعل النشر المحلي تحديًا.
توفر واجهات API حلاً فعالاً من حيث التكلفة وقابلاً للتوسع، وتلغي الحاجة إلى أجهزة باهظة الثمن، وتحسن الاتصال بين وحدات معالجة رسومية متعددة، وتضمن الموثوقية.
يبرز Llama 4 Scout كنموذج متطور لمعالجة السياقات الطويلة للغاية مثل 10 ملايين رمز، متجاوزًا بكثير قدرات معظم النماذج. بينما أداؤه لا يُضاهى، إلا أن المتطلبات الصارمة من الأجهزة تجعل النشر المحلي غير عملي للعديد من المستخدمين.
متطلبات VRAM لـ Llama 4 Scout
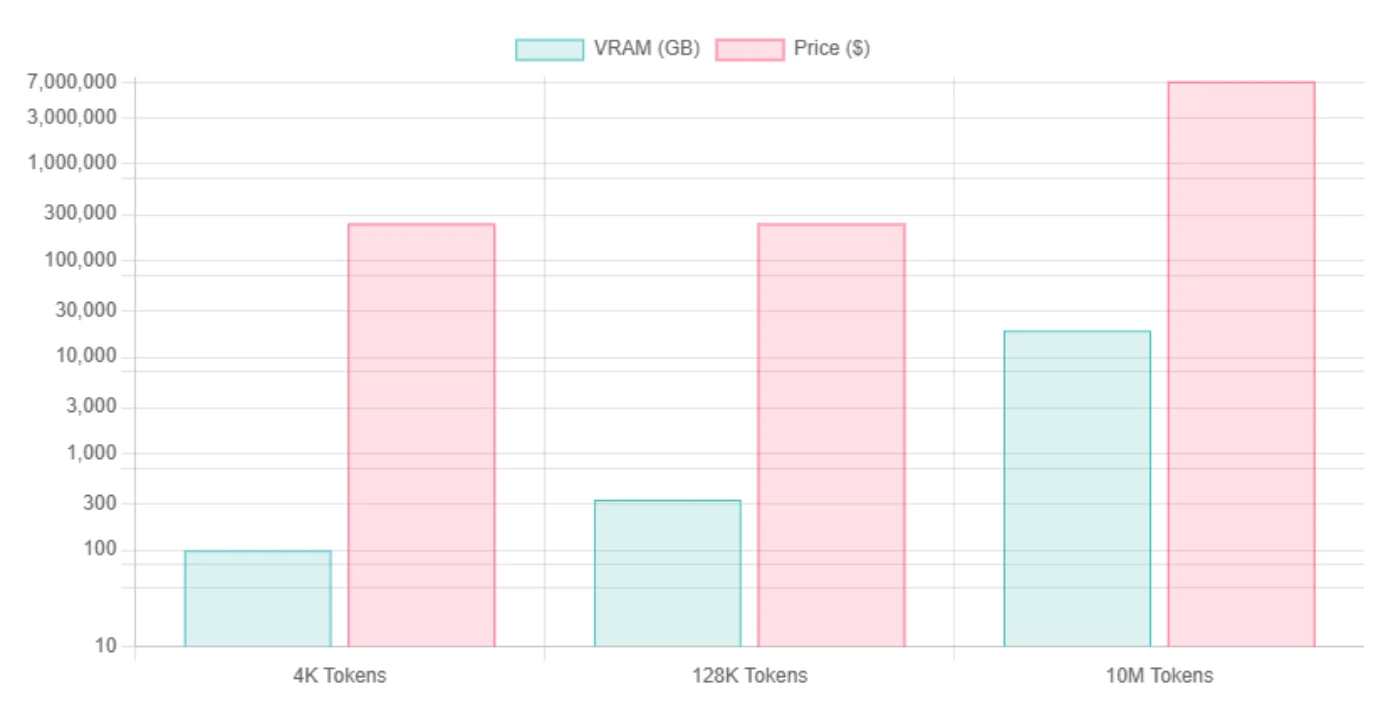
| طول السياق | Llama 4 Scout Int4 VRAM | احتياجات وحدات GPU | Llama 4 Scout FP16 VRAM | احتياجات وحدات GPU |
| 4K رمز | ~99.5 جيجابايت / ~76.2 جيجابايت | H100 | ~345 جيجابايت | 8*H100 |
| 128K رمز | ~334 جيجابايت | 8*H100 | ~579 جيجابايت | 8*H100 |
| 10M رمز | يهيمن عليها KV Cache، تقديريًا ~18.8 تيرابايت | 240*H100 | نفس INT4، بسبب هيمنة KV | 240*H100 |
تحديات تشغيل Llama 4 Scout محليًا
1. متطلبات ذاكرة KV Cache
- السياقات الطويلة للغاية (مثل 10 ملايين رمز) تتطلب ذاكرة ضخمة لتخزين KV cache، تصل إلى 18.8 تيرابايت من VRAM حتى في وضع INT4. وهذا يستلزم مجموعة كبيرة من وحدات GPU تضم 240 وحدة H100، مما يؤدي إلى مشاكل في قابلية التوسع.
2. عبء الاتصال بين وحدات GPU المتعددة
- مع 8 أو 240 وحدة GPU، يصبح عبء الاتصال لتوزيع تخزين KV cache والوصول إليه كبيرًا، مما قد يبطئ الأداء العام.
3. ارتفاع التكلفة واستهلاك الطاقة
- تشغيل مجموعات كبيرة من وحدات GPU، خاصة لـ 10 ملايين رمز، يؤدي إلى تكاليف عالية جدًا في الأجهزة والتشغيل والطاقة، مما يجعله غير عملي للعديد من حالات الاستخدام.
4. كفاءة الاستدلال
- بالنسبة للسياقات الطويلة للغاية (مثل 128K أو 10M رمز)، يزداد التعقيد الحسابي بشكل كبير. وهذا قد يؤدي إلى تأخير كبير أثناء الاستدلال، مما قد لا يلبي متطلبات الوقت الفعلي.
حلول محتملة لتشغيل Llama 4 Scout محليًا
1. تحسين KV Cache
- استخدام KV cache موزعة لتقسيم متطلبات الذاكرة عبر وحدات GPU متعددة.
- استكشاف تقنيات إدارة ذاكرة أكثر كفاءة، مثل ضغط KV cache أو تخزين البيانات الأقل وصولاً على مستويات ذاكرة أبطأ.
2. تحسين الاتصال بين وحدات GPU المتعددة
- الاستفادة من الوصلات عالية النطاق مثل NVIDIA NVLink أو Infiniband لتقليل زمن الوصول وتسريع الاتصال بين وحدات GPU.
- تحسين أطر الحوسبة الموزعة مثل DeepSpeed أو Megatron-LM لتقليل عبء الاتصال وتحسين قابلية التوسع.
3. تقليل التكلفة واستهلاك الطاقة
- تحسين بنية النموذج باستخدام تقنيات مثل آليات الانتباه المتناثر لتقليل استخدام الذاكرة والطلب الحسابي.
- استكشاف تحسينات الأجهزة (مثل بنى GPU المستقبلية أو مسرعات الذكاء الاصطناعي المخصصة) التي توفر كفاءة أعلى.
4. تعزيز كفاءة الاستدلال
- تنفيذ آليات الانتباه المتناثر أو المعالجة المجزأة للتعامل مع السياقات الطويلة بكفاءة أكبر.
- استخدام استراتيجيات التخزين المؤقت الهرمي أو التخزين متعدد المستويات لتحسين إدارة KV cache وتقليل زمن الاستدلال.
الوصول عبر API: خيار فعال من حيث التكلفة للمطورين الصغار

لماذا تعتبر واجهات API حلاً قوياً
1. متطلبات KV Cache وذاكرة GPU
- حل API: تتعامل واجهات API مع جميع متطلبات KV cache والذاكرة على بنيتها التحتية، مما يلغي حاجتك لشراء أو إدارة وحدات GPU. تقوم بتخصيص الذاكرة ديناميكيًا، حتى للسياقات الطويلة للغاية مثل 10 ملايين رمز.
- لماذا هو مهم: يزيل هذا الحاجة إلى أجهزة باهظة الثمن وإدارة ذاكرة معقدة، مما يسمح لك بالتركيز فقط على استخدام النموذج.
2. تعقيد الاتصال بين وحدات GPU المتعددة
- حل API: تعمل واجهات API على تحسين الاتصال بين وحدات GPU المتعددة داخليًا باستخدام وصلات متقدمة مثل NVLink أو Infiniband، مما يضمن أداءً فعالاً دون الحاجة لتدخلك.
- لماذا هو مهم: تتجنب التحديات التقنية والتشغيلية لتكوين وصيانة أنظمة GPU الموزعة مع الاستفادة من الأداء السلس.
3. ارتفاع تكاليف الأجهزة والصيانة
- حل API: مع واجهات API، تدفع فقط مقابل ما تستخدمه من خلال نموذج الدفع حسب الاستخدام، متجنبًا التكاليف الأولية التي تصل إلى ملايين الدولارات لشراء أجهزة GPU ونفقات الصيانة المستمرة.
- لماذا هو مهم: تجعل واجهات API الذكاء الاصطناعي عالي الأداء متاحًا وفعالاً من حيث التكلفة، خاصة للشركات ذات الميزانيات المحدودة أو احتياجات الاستخدام غير المتكررة.
4. قابلية التوسع لأعباء العمل الكبيرة
- حل API: تتوسع واجهات API تلقائيًا لتلبية متطلبات عبء العمل، سواء كنت تعالج مهام صغيرة أو سياقات ضخمة مثل 10 ملايين رمز. يقوم المزود بتخصيص الموارد ديناميكيًا حسب الحاجة.
- لماذا هو مهم: يضمن ذلك قدرة تطبيقك على التعامل مع الارتفاعات المفاجئة في الطلب أو المهام واسعة النطاق دون الحاجة لترقية البنية التحتية أو التوقف عن العمل.
5. كفاءة الاستدلال
- حل API: تستخدم واجهات API تحسينات متقدمة مثل الانتباه المتناثر والتوازي لمعالجة السياقات الطويلة بكفاءة، مما يوفر نتائج أسرع من معظم الإعدادات المحلية.
- لماذا هو مهم: أوقات الاستدلال الأسرع تحسن تجربة المستخدم وتقلل أوقات الانتظار، حتى للتطبيقات الصعبة التي تتضمن سياقات طويلة جدًا.
6. الموثوقية والصيانة
- حل API: تضمن واجهات API موثوقية عالية من خلال معالجة أعطال الأجهزة والتحديثات ومشكلات التوسع من جانبها. يضمن المزودون وقت تشغيل سلس ووصولاً إلى أحدث إصدارات النموذج.
- لماذا هو مهم: لا داعي للقلق بشأن توقف النظام أو صيانة الأجهزة أو التحديثات اليدوية، مما يضمن خدمة متواصلة لتطبيقك.
واجهة API مستقرة وفعالة من حيث التكلفة - Novita AI
الخطوة 1: تسجيل الدخول والوصول إلى مكتبة النماذج
سجل الدخول إلى حسابك وانقر على زر مكتبة النماذج.

الخطوة 2: اختر نموذجك
تصفح الخيارات المتاحة واختر النموذج الذي يناسب احتياجاتك.

الخطوة 3: ابدأ النسخة التجريبية المجانية
ابدأ نسختك التجريبية المجانية لاستكشاف إمكانيات النموذج المختار.
الخطوة 4: احصل على مفتاح API الخاص بك
للمصادقة مع API، سنزودك بمفتاح API جديد. بالدخول إلى صفحة “الإعدادات”، يمكنك نسخ مفتاح API كما هو موضح في الصورة.

الخطوة 5: تثبيت API
قم بتثبيت API باستخدام مدير الحزم الخاص بلغة البرمجة الخاصة بك.

بعد التثبيت، قم باستيراد المكتبات اللازمة في بيئة التطوير الخاصة بك. قم بتهيئة API باستخدام مفتاح API الخاص بك لبدء التفاعل مع Novita AI LLM. هذا مثال لاستخدام API إكمال الدردشة لمستخدمي Python.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<مفتاح API الخاص بك في Novita AI>",
)
model = "meta-llama/llama-4-scout-17b-16e-instruct"
stream = True # أو False
max_tokens = 2048
system_content = """كن مساعدًا مفيدًا"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "مرحبًا!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
الخاتمة
قدرة Llama 4 Scout على التعامل مع السياقات الطويلة بكفاءة لا مثيل لها تجعله الخيار الأفضل لمهام الذكاء الاصطناعي المتقدمة. تلغي واجهات API تحديات النشر المحلي، وتوفر حلاً موثوقًا وقابلاً للتطوير وفعالاً من حيث التكلفة. من خلال الاستفادة من الوصول عبر API، يمكن للمطورين الاستفادة الكاملة من إمكانيات Llama 4 Scout مع تجنب عبء إدارة البنية التحتية، مما يمكنهم من التركيز على الابتكار وتقديم القيمة.
الأسئلة الشائعة
ما الذي يجعل Llama 4 Scout متفوقًا على النماذج الأخرى؟
يتفوق Llama 4 Scout في معالجة السياقات الطويلة للغاية (مثل 10 ملايين رمز) بكفاءة لا تضاهى.
لماذا يعتبر تشغيل Llama 4 Scout محليًا صعبًا؟
يتطلب تشغيل Llama 4 Scout محليًا ما يصل إلى 18.8 تيرابايت من VRAM و 240 وحدة معالجة رسومية H100، مما يؤدي إلى تكاليف عالية ومشاكل في قابلية التوسع وتحديات معقدة في الاتصال بين وحدات GPU.
كيف أبدأ في استخدام Llama 4 Scout عبر API؟
ما عليك سوى تسجيل الدخول إلى Novita AI، واختيار Llama 4 Scout من مكتبة النماذج، وبدء نسختك التجريبية المجانية، وإنشاء مفتاح API، ودمجه في بيئة التطوير الخاصة بك باستخدام الأدوات المتوفرة.
Novita AI هي منصة سحابية للذكاء الاصطناعي تقدم للمطورين طريقة سهلة لنشر نماذج الذكاء الاصطناعي باستخدام API بسيط، مع توفير سحابة GPU ميسورة التكلفة وموثوقة للبناء والتوسع.



