

大型語言模型推理實現100倍加速的稀疏技術。探索激活稀疏性的魔力:無需重新訓練、低成本、高效率,顯著提升GPU推理速度!
在先前的討論「LLM 如何透過稀疏性加速推理」中,我們探討了第一部分「[大型模型如何剪枝](Unveiling LLM-Pruner Techniques: Doubling Inference Speed)」。這次,我們將繼續深入第二部分「如何利用激活稀疏性加速推理」,並在下次討論中探討第三部分「稀疏編譯器對 LLM 推理的影響」。
我們一直在尋找是否存在一種方法能夠滿足多項需求:不需要模型重新訓練,只需微調(低模型遷移成本)、維持模型性能(良好效果)、獲得現代硬體(GPU/CPU)的高度支援,並顯著減少 GPU 計算和 I/O 以優化延遲(快速推理速度)。
事實上,這樣的方法確實存在,而激活稀疏性正是滿足所有這些需求的方法之一。
值得注意的是,在神經網路中使用 ReLU 激活函數已知能誘發激活稀疏性,並已在多項先前工作中被採用。平均而言,所有層的激活稀疏性可顯著節省 GPU 與 CPU 之間的權重傳輸(I/O),影響約 95% 的投影層權重行。這種縮減直接轉化為計算節省,因為這些行的矩陣乘法運算結果將為零。
此外,與非結構化稀疏性(例如非結構化權重稀疏性)不同,此類稀疏性由於將更廣泛且結構化的區塊(如行或列)歸零,因此對硬體更為友善。
同樣地,參考下圖,我們簡要說明激活稀疏性在加速推理方面的有效性。
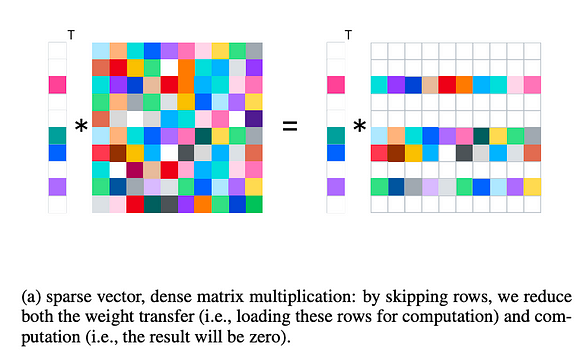
在激活稀疏性的情況下,推理時執行稀疏向量與稠密矩陣的乘法,而在訓練時則調整為稀疏矩陣與稠密矩陣的乘法。
- 減少計算負擔:這種半結構化稀疏性(不同於權重剪枝的非結構化稀疏性)允許跳過某些行,從而減少計算量。例如,cusparse 等函式庫已支援相應操作。
- 減少 I/O 傳輸:推理時 GPU I/O 是瓶頸(例如從 GPU 快取到 CPU 快取或從 GPU DRAM 到 GPU 快取)。這種方法允許跳過不必要的行,從而減少 I/O。
激活稀疏性的可行性
以下內容主要參考文獻 [5] 的數據,以證明在 LLM 上落地 ReLU 激活的可行性。
激活稀疏模型與非激活稀疏模型的比較
透過對三個模型的 FFN(前饋網路)進行測量與分析,分別是 OPT 6.7B、Llama 7B(使用 SiLU 激活)和 Falcon 7B(使用 GELU 激活),得出以下三個結論:
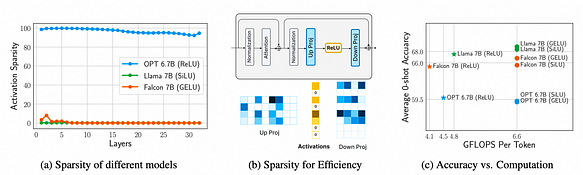
a. 比較 Llama 7B(SiLU 激活)、Falcon 7B(GELU 激活)和 OPT 6.7B(ReLU 激活)後發現,ReLU 誘發了超過 90% 的激活稀疏性,而 SiLU 和 GELU 誘發的激活稀疏性不到 10%,這表明 ReLU 可以誘發稀疏激活。
b. 激活稀疏性顯著節省了權重傳輸(I/O),影響約 95% 的下游投影層權重行。
c. 激活函數的選擇對準確率影響不大,因為 GELU、SiLU 或 ReLU 處於相同的精度水平。然而,ReLU 可以節省 32% 的計算負擔(FLOPS)。
降低訓練成本
許多現代 LLM(如 Llama 和 Falcon)已使用非 ReLU 激活進行訓練。從頭開始訓練並不划算;因此,需要考慮透過微調實現 ReLU 激活。模型透過以下兩個階段進行微調:
- 第一階段:保留現有的 ReLU 激活(在 OPT 的情況下),或將上投影層與下投影層之間的激活函數替換為 ReLU(在 Falcon 和 Llama 中,原使用 GELU 和 SiLU)。
- 第二階段:在歸一化層之後插入新的 ReLU 激活。
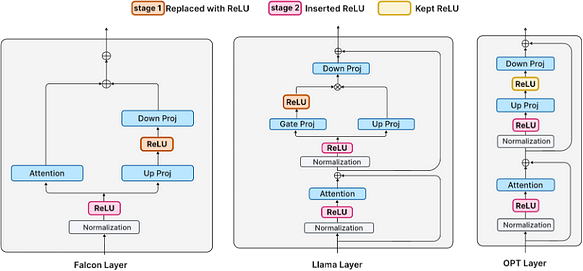
第一階段 — 替換非 ReLU 激活
將 FFN 層中的非 ReLU 激活替換為 ReLU。對於 Falcon 和 Llama 模型,這分別意味著替換 GELU 和 SiLU。值得注意的是,由於 OPT 模型已經使用 ReLU 激活,因此不做更改。在使用 300 億 tokens 的 RefinedWeb 資料集進行微調後,模型在激活中展現出顯著的稀疏性。

第二階段 — 插入新的 ReLU
在前一階段中,我們替換了非 ReLU 激活以獲得更多稀疏性。這使得下投影層的輸入變得稀疏,約佔總計算成本的 30%。然而,除了下投影之外,Transformer 解碼層中還有其他的矩陣向量乘法,例如 FFN 層中的上投影和注意力層中的 QKV 投影。這些矩陣向量乘法總共消耗約 55% 的總計算成本。
在現代 Transformer 層中,注意力層和 FFN 層的輸入都來自歸一化層,例如 LayerNorm 或 RMSNorm。這些層可以被視為 MLP 的一種特定形式,它們不應用任意可學習參數,而是學習縮放輸入。因此,我們在歸一化層之後應用 ReLU 以獲得稀疏激活,從而實現第二階段的目標。
測量結果
微調成本:第一階段和第二階段分別使用 300 億和 500 億 tokens 完成微調。與 Llama 訓練 1 兆 tokens 的成本相比,成本僅約 3–5%。
有效性:比較 Llama 和 Falcon 微調後的推理延遲,模型性能沒有明顯下降。然而,推理速度顯著提升了超過 30%。
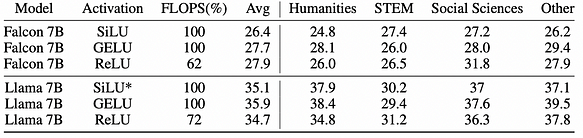
總體而言,結果證實透過微調實現激活稀疏性可以在各個階段和比率上減少推理 FLOPS,同時在不同任務上保持可比的性能。相應的稀疏激活模型可在該專案中找到:https://huggingface.co/SparseLLM。
如何加速推理
參考論文 [1] 中 DejaVu 的上下文稀疏性預測是一種極佳的方法。
如何充分利用結構化稀疏性進行加速
上下文稀疏性假設預訓練模型表現出上下文稀疏性,即注意力與 MLP 的稀疏化計算可達到與完整計算相同的效果。在此前提下,結構化稀疏模型中平均 85% 的上下文稀疏性可以使每個特定輸入的參數減少七倍,同時保持準確率,從而顯著提升推理性能。
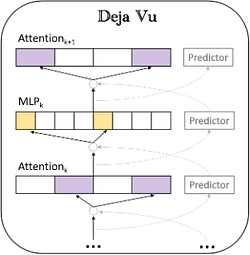
如上圖所示,基於上下文稀疏性設計了一個非同步稀疏預測器,提前預測下一層注意力與 MLP 的稀疏性。這種方法不僅確保了推理效率,還大大減少了計算和 I/O 開銷。
上下文稀疏性存在的驗證
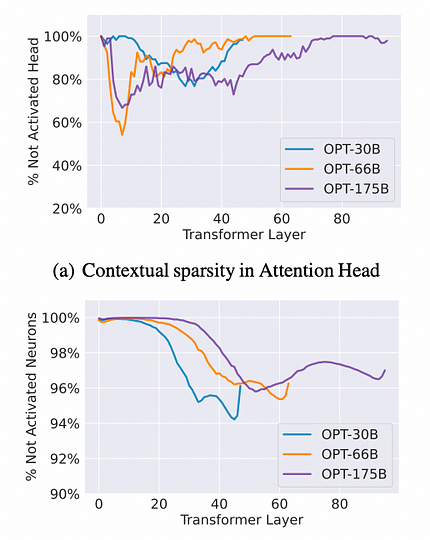
在 OPT-175B、66B 和 30B 模型上,使用 OpenBookQA 和 Wiki-Text 等多個下游資料集進行測試。該方法涉及兩次模型前向傳播,以識別每個輸入範例的上下文稀疏性。第一次前向傳播記錄參數子集,特別是那些對輸入產生較大輸出範數的注意力頭和 MLP 神經元。第二次前向傳播僅使用記錄的參數子集計算每個輸入範例。令人驚訝的是,兩次前向傳播在所有上下文學習和語言建模任務中產生了相似的預測或性能。
觀察結果:平均而言,注意力頭可實現高達 80% 的稀疏性,而 MLP 神經元可實現高達 95% 的稀疏性,總體稀疏性約為 85%,可帶來七倍的加速。具體參考數據請參閱下圖。
工程影響
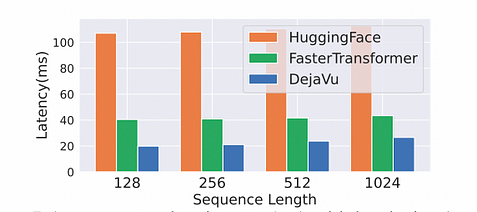
加速效果:由於 GPU 是區塊導向的設備,載入單一位元組記憶體所需的時間與載入同一地址附近記憶體區塊的時間相同。NVIDIA GPU 的區塊大小通常為 128 位元組。因此,進行了記憶體融合和算子融合等優化。在 batch_size=1 的前提下,與 FasterTransformer 相比,加速達到兩倍效果,實現了 2 倍的速度提升。
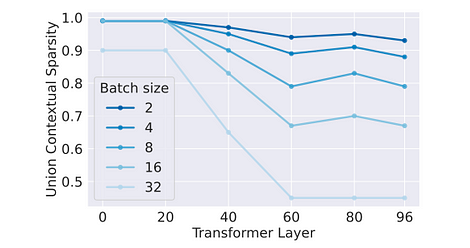
吞吐量影響:由於激活是每個 token 的函數,有效稀疏性也隨機分佈在各個 token 之間。因此,稀疏優化的效果隨著 batch size 的增加而指數衰減。這可以參考論文中進行的消融實驗。
降低推理門檻
整理當前部分卸載方法與 DejaVu 方法,如下表所示:
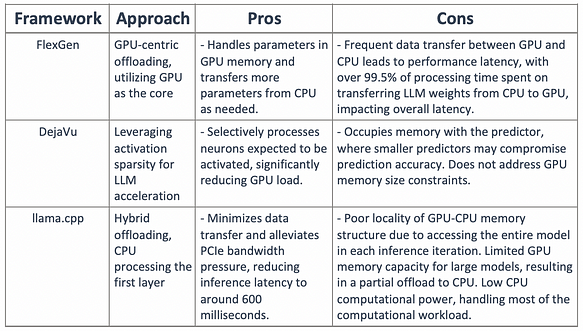
能否將激活稀疏性與卸載方法結合,設計一個 GPU-CPU 混合推理引擎:熱激活神經元預先載入到 GPU 以實現快速存取,而冷激活神經元則在 CPU 上計算,從而顯著減少 GPU 記憶體需求和 CPU-GPU 數據傳輸?
答案是,當然「可以」。
其中一種解決方案是 PowerInfer[10],它可以在單張 NVIDIA RTX 4090 GPU 上運行 OPT-175B,實現的 token 生成速度僅比頂級 A100 GPU 伺服器低 18%。除了卸載和激活稀疏性之外,Brainstorm[9]、SparTA[15] 和 Flash-llm[16] 等其他方面也具有參考價值。
概述:
PowerInfer 將頻繁激活的神經元的權重預先載入到 GPU,而較少激活的神經元的權重則保留在 CPU 上。
為了減少推理延遲,推理引擎僅計算在線預測器預測為活躍的神經元,跳過大部分非活躍神經元。此外,預載策略使 PowerInfer 能夠將大部分推理任務分配給 GPU,因為載入到 GPU 的熱激活神經元佔了激活的大多數。對於不在 GPU 記憶體中的冷激活神經元,PowerInfer 在 CPU 上進行計算,無需將權重傳輸到 GPU。
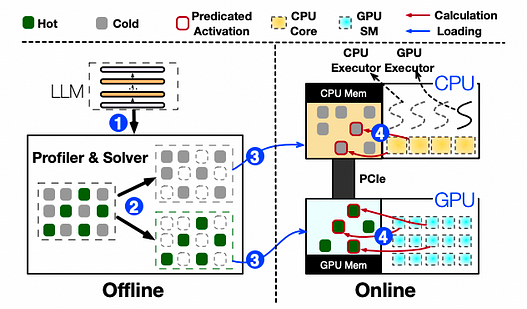
PowerInfer 的架構概覽與推理流程
PowerInfer 包含離線和在線組件。由於不同 LLM 的局部性屬性不同,離線組件分析 LLM 的激活稀疏性,區分熱神經元和冷神經元。在在線階段,推理引擎將兩類神經元分別載入 GPU 和 CPU,並在運行時以低延遲服務 LLM 請求。在處理用戶請求之前,在線引擎根據離線求解器的輸出將兩類神經元分配給各自的處理單元。運行時,引擎創建 GPU 和 CPU 執行器(在 CPU 端運行的線程),以管理並發的 CPU-GPU 計算。引擎還預測神經元激活並跳過非激活神經元。激活的神經元被預先載入 GPU 記憶體進行處理,而 CPU 則計算其神經元的結果並將其傳輸到 GPU 進行整合。引擎在 CPU 和 GPU 上都使用稀疏神經元感知算子,專注於矩陣內的單個神經元行/列。
專案連結:https://github.com/SJTU-IPADS/PowerInfer
單層計算優化
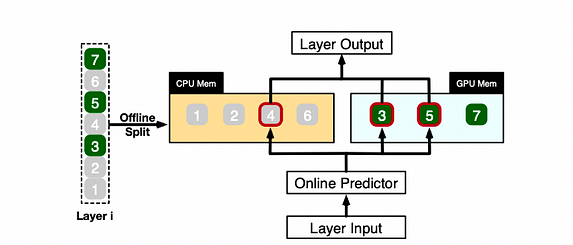
一個範例說明 PowerInfer 如何為一個 LLM 層計算不同的神經元
PowerInfer 協調 GPU 和 CPU 處理層內的神經元,方法是根據離線數據對神經元進行分類,將熱神經元(例如索引 3、5、7)分配給 GPU 記憶體,並將其他神經元分配給 CPU 記憶體。
收到輸入後,預測器識別當前層中哪些神經元可能被激活。例如,它預測神經元 3、4 和 5 的激活。值得注意的是,通過離線統計分析標記的熱神經元可能不完全符合運行時激活行為。例如,神經元 7 雖然被標記為熱,但在特定情境下可能處於非激活狀態。
隨後,CPU 和 GPU 都處理預測為激活的神經元,同時忽略非激活神經元。GPU 計算神經元 3 和 5,而 CPU 處理神經元 4。神經元 4 的計算完成後,其輸出被發送到 GPU 進行結果整合。
在線推理(神經元感知推理引擎)
- 自適應稀疏預測器
PowerInfer 中的在線推理引擎通過僅處理預測為激活的神經元來減少計算負載。這種方法也應用於 DejaVu,主張訓練一個固定大小的 MLP 預測器集合。在每個 Transformer 層中,DejaVu 利用兩個獨立的預測器來預測自注意力和 MLP 區塊中神經元的激活情況。
然而,在資源有限的本地部署中設計有效的預測器面臨挑戰,需要在預測精度和模型大小之間取得平衡。
PowerInfer 為每個 Transformer 層採用非固定大小預測器的迭代訓練方法。此過程首先根據層的稀疏性概況建立基準模型大小。然後,考慮內部激活偏斜,迭代調整模型大小以保持精度。MLP 預測器通常包括輸入層、隱藏層和輸出層。由於輸入層和輸出層的大小由 Transformer 層的結構決定,修改主要針對隱藏層。在迭代調整過程中,根據觀測到的偏斜度修改隱藏層的大小。對於偏斜度較大的層,隱藏層的大小逐漸減小,直到精度低於 95%。相反,對於偏斜度較小的層,則增加維度以提高精度。通過這種方法,PowerInfer 有效地將預測器參數限制在 LLM 總參數的 10% 以內。
- GPU-CPU 混合執行
推理之前,PowerInfer 構建一個計算有向無環圖(DAG),其中每個節點代表一個 LLM 推理運算算子,並將其存儲在 CPU 記憶體的全域佇列中。佇列中的每個運算算子都標記有其所需的運算算子。推理期間,兩種類型的執行器(由主機作業系統 pthread 創建)管理 CPU 和 GPU 上的計算。它們從全域佇列中提取運算算子,檢查依賴關係,並將其分配給適當的處理單元。GPU 和 CPU 使用各自的神經元感知運算算子,GPU 執行器使用 cudaLaunchKernel 等 API 啟動 GPU 運算算子,而 CPU 執行器則協調未使用的 CPU 核心進行計算。
實驗結論
性能比較
各種模型在 FP16 格式 PC-High 上的加速情況。X 軸表示輸出長度,Y 軸表示與 llama.cpp 相比的加速比。每條柱上方的數字代表端到端的生成速度(tokens/s)。圖中第一行配置的輸入長度約為 64,第二行約為 128。
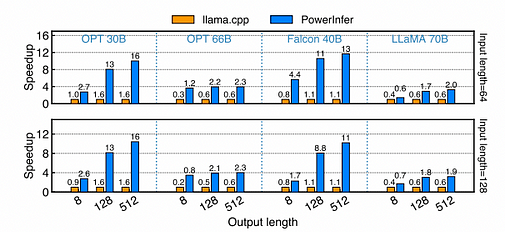
在配備 NVIDIA RTX 4090 的 PC-High 上,各種模型和輸入輸出配置呈現不同的生成速度。平均而言,PowerInfer 實現了 8.32 tokens/s 的生成速度,峰值達到 16.0 tokens/s,這顯著優於 llama.cpp,平均加速比為 7.23 倍,而 Falcon-40B 最高達到 11.69 倍。隨著輸出 token 數量的增加,PowerInfer 的性能優勢更加明顯,因為生成階段在整體推理時間中佔據更重要的角色。在此階段,CPU 和 GPU 上僅有少量神經元被激活,與 llama.cpp 相比減少了不必要的計算。例如,在 OPT-30B 的情況下,每個生成的 token 僅約 20% 的神經元被激活,且大多數在 GPU 上處理,展示了 PowerInfer 神經元感知推理引擎的優勢。
批次大小影響:
當 batch size 小於 32 時,PowerInfer 展現顯著優勢,與 llama.cpp 相比平均提升 6.08 倍。隨著 batch size 的增加,PowerInfer 提供的加速比降低。這種降低歸因於模型中聯合激活的稀疏性降低。然而,即使 batch size 設為 32,PowerInfer 仍然保持可觀的加速比,達到 4.38 倍的提升。
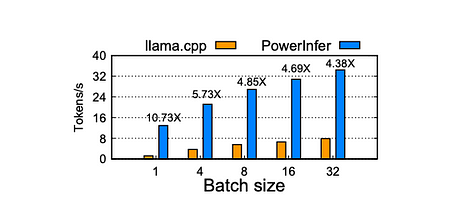
Falcon-40B 在 PC-High 上的批次推理加速。X 軸表示請求批次大小,Y 軸表示端到端 token 生成速度(tokens/s)。每條柱上方的數字顯示與 llama.cpp 相比的加速比。
負載比較
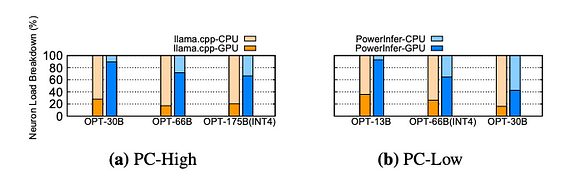
推理期間 CPU 和 GPU 上的神經元負載分佈。黃色區塊代表 llama.cpp,藍色區塊代表 PowerInfer
比較了 PowerInfer 和 llama.cpp 中 CPU 和 GPU 之間的神經元負載分佈。神經元負載指的是每個處理單元執行的激活神經元計算的比例。值得注意的是,在 PC-High 系統上,PowerInfer 顯著增加了 GPU 上的神經元負載份額,從平均 20% 上升到 70%。這表明 GPU 處理了 70% 的激活神經元。然而,當模型的記憶體需求遠遠超過 GPU 容量時,例如在 11GB 的 2080Ti GPU 上運行 60GB 的模型,GPU 上的神經元負載下降到 42%。這種下降是由於 GPU 記憶體有限,無法容納所有熱激活神經元,因此一部分熱激活神經元需要由 CPU 計算。
在涉及較長輸入提示和相對較短輸出長度的場景中,PowerInfer 僅表現出有限的性能提升。在這種情況下,同時處理大量 token 的階段成為決定推理速度的關鍵因素。這導致每個 token 激活一組獨特的神經元,顯著降低激活稀疏性。因此,CPU 成為推理過程的主要瓶頸,需要處理大量冷激活神經元但受到計算能力的限制。
結論
激活稀疏性技術為大型語言模型帶來了革命性的突破。通過稀疏化神經網路的激活來加速推理過程,同時減少 GPU 計算和 I/O 負載,從而提高推理速度和性能。這種方法不需要重新訓練,僅通過微調即可實現激活稀疏性,在保持模型性能的同時顯著降低成本。激活稀疏性技術的應用前景令人振奮,為深度學習領域帶來了更多可能性。我們期待這項技術的進一步發展和廣泛應用。
參考論文
[5]ReLU Strikes Back: Exploiting Activation Sparsity in Large Language Models
[7]Inducing and exploiting activation sparsity for fast inference on deep neural networks
[8]Sparse is enough in scaling transformers
novita.ai 提供 Stable Diffusion API 以及數百種快速且最便宜的 AI 圖像生成 API,支援 10,000 個模型。🎯 最快 2 秒生成,按量付費,每張標準圖像最低 $0.0015,您可以添加自己的模型並避免 GPU 維護。免費分享開源擴展。
推薦閱讀



