

Sparse Techniques for 100X Speedup in Large Language ModeI Inference. Discover the magic of activation sparsity: no retraining, low cost, and high efficiency, leading to a significant increase in GPU inference speed!
In the previous discussion on “How LLM Accelerates Inference Through Sparsity,” we explored the first part, “[How Large Models Prune](Unveiling LLM-Pruner Techniques: Doubling Inference Speed).” This time, we continue to delve into the second part, “How to Speed Up Inference Using Activation Sparsity,” and in the next discussion, we will examine the third part, “The Impact of Sparse Compilers on LLM Inference.”
We have been exploring whether there exists a method that can meet several requirements: not requiring model retraining but only fine-tuning (low model transfer cost), maintaining model performance (good effectiveness), being highly supported by modern hardware (GPU/CPU), and significantly reducing GPU compute and I/O to optimize latency (fast inference speed).
Indeed, such a method exists, and activation sparsity is one that fulfills all these requirements.
It is worth noting that using ReLU activation functions in neural networks is known to induce activation sparsity and has been adopted in various previous works. On average, this activation sparsity across all layers leads to significant savings in weight transfer (I/O) between GPUs and CPUs, affecting approximately 95% of the rows of the projection layer weights. This reduction directly translates into computational savings, as the results of matrix multiplication operations for these rows will be zero.
Furthermore, unlike unstructured sparsity (e.g., unstructured weight sparsity), this type of sparsity is more hardware-friendly due to zeroing out more extensive and structured blocks (such as rows or columns).
Similarly, referring to the figure below, we briefly illustrate the effectiveness of activation sparsity in accelerating inference.
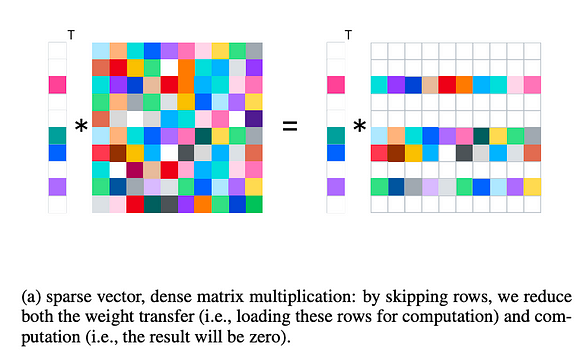
In the case of activation sparsity, sparse vector-dense matrix multiplication is performed during inference, while during training, it is adjusted to sparse matrix-dense matrix multiplication.
- Reduced computational workload: This semi-structured sparsity (unlike the unstructured sparsity of weight pruning) allows skipping certain rows, reducing computation. For example, libraries like cusparse already support corresponding operations.
- Reduced IO transfer: During inference, GPU I/O is a bottleneck (e.g., from GPU cache to CPU cache or from GPU DRAM to GPU cache). This method allows skipping unnecessary rows, thereby reducing I/O.
Feasibility of Activation Sparsity
The following content mainly refers to data from [5] to demonstrate the feasibility of landing ReLU activation on LLM.
Comparison between Activation Sparse and Non-Activation Sparse Models
Through measurement and analysis of the FFN (Feed-Forward Network) of three models, OPT 6.7B, Llama 7B (with SiLU activation), and Falcon 7B (with GELU activation), the following three conclusions are drawn:
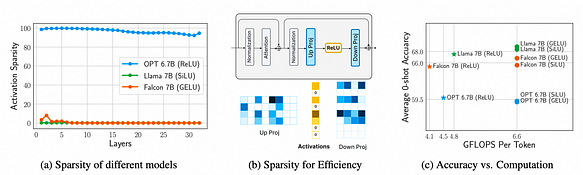
a. Comparison between Llama 7B (with SiLU activation), Falcon 7B (with GELU activation), and OPT 6.7B (with ReLU activation) reveals that ReLU induces over 90% activation sparsity, while SiLU and GELU induce less than 10% activation sparsity, demonstrating that ReLU can induce sparse activations.
b. Activation sparsity leads to significant savings in weight transmission (I/O), affecting approximately 95% of the rows of the downstream projection layer weights.
c. The choice of activation function does not significantly affect accuracy because GELU, SiLU, or ReLU are at the same level of precision. However, ReLU can save 32% of computational workload (FLOPS).
Reducing Training Costs
Many modern LLMs (such as Llama and Falcon) have been trained using non-ReLU activations. Training from scratch is not cost-effective; therefore, it is necessary to consider implementing ReLU activation through fine-tuning. The model is fine-tuned through the following two phases:
- In the first phase, existing ReLU activations (in the case of OPT) are retained, or the activation function between the up-projection and down-projection layers is replaced with ReLU (in the case of Falcon and Llama, where GELU and SiLU are used).
- In the second phase, new ReLU activations are inserted after normalization layers.
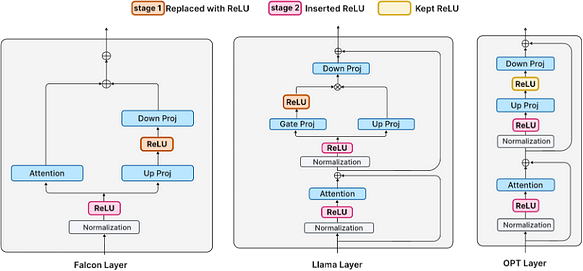
Phase One — Non-ReLU Activation Replacement
Replace non-ReLU activations with ReLU in the FFN layers. For Falcon and Llama models, this entails replacing GELU and SiLU, respectively. It is noted that since the OPT model already utilizes ReLU activations, no changes are made. After fine-tuning on 30B tokens of RefinedWeb, the model exhibits significant sparsity in activations.

Phase Two — Inserting New ReLU
In the previous phase, we replaced non-ReLU activations to attain more sparsity. This resulted in sparse inputs to the down-projection layer, accounting for approximately 30% of the total computational cost. However, besides the down-projection, there are other matrix-vector multiplications in the decode layers of the transformer, such as the up-projection in the FFN layer and the QKV projection in the attention layer. Collectively, these matrix-vector multiplications consume around 55% of the total computational cost.
In modern Transformer layers, the inputs to attention and FFN layers both come from normalization layers, such as LayerNorm or RMSNorm. These layers can be seen as a specific form of an MLP where they don’t apply any arbitrary learnable parameters but instead learn to scale the input. Therefore, we apply ReLU to obtain sparse activations after the normalization layers, achieving the goal of the second phase.
Measurement Results
Cost of Fine-tuning: Fine-tuning was completed with 30B and 50B tokens in phases one and two, respectively. Compared to the training cost of 1T tokens for Llama, the cost was only approximately 3–5%.
Effectiveness: Comparing the inference latency after fine-tuning for Llama and Falcon, there was no discernible decrease in model performance. However, there was a significant improvement of over 30% in inference speed.
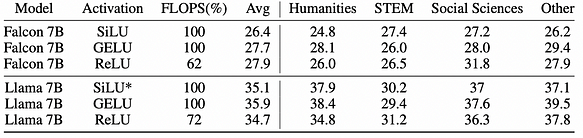
Overall, the results confirm that achieving activation sparsity through fine-tuning can reduce inference FLOPS across various stages and rates while maintaining comparable performance across different tasks. The corresponding sparse activation models can be found at the project: https://huggingface.co/SparseLLM.
How to Speed Up Inference
DejaVu’s context sparsity prediction, as outlined in the referenced paper [1], is an excellent approach.
How to Fully Utilize Structured Sparsity for Speedup
Context sparsity assumes that pretrained models exhibit context sparsity, meaning that sparsification computations for Attention and MLP achieve the same effect as full computations. With this premise, an average context sparsity of 85% in structured sparse models can result in a sevenfold reduction in parameters for each specific input while maintaining accuracy, thus significantly enhancing inference performance.
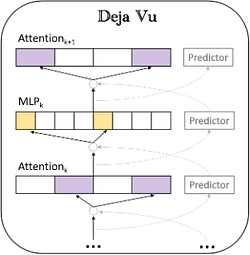
As shown in the above figure, a asynchronous sparse predictor is designed based on context sparsity, predicting the sparsity of the next layer’s Attention and MLP in advance. This approach not only ensures inference efficiency but also greatly reduces computational and I/O overhead.
Validation of Context Sparsity Existence
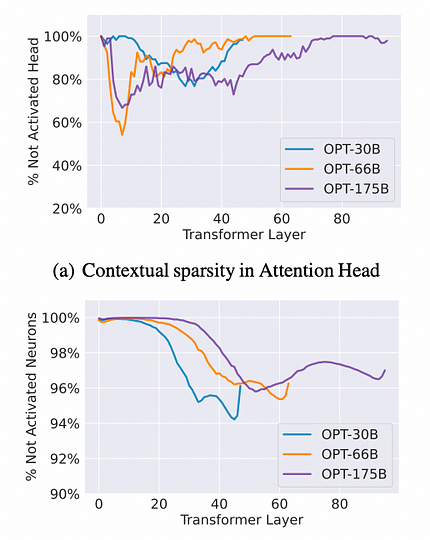
Testing was conducted on OPT-175B, 66B, and 30B models with various downstream datasets such as OpenBookQA and Wiki-Text. The method involved two forward passes of the model to identify the context sparsity for each input example. In the first pass, a subset of parameters, particularly those associated with Attention heads and MLP neurons generating large output norms for inputs, was recorded. In the second pass, each input example was computed using only the recorded parameter subset. Surprisingly, both forward passes yielded similar predictions or performance across all context learning and language modeling tasks.
Observation Results: On average, Attention heads can impose sparsity of up to 80%, while MLP neurons can achieve sparsity of up to 95%, resulting in an overall sparsity of about 85%, which can lead to a sevenfold speedup. For specific reference data, please refer to the figure below.
Engineering Impact
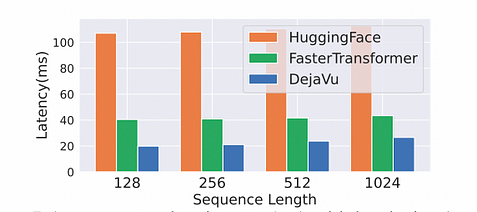
Speed-Up Effect: Since GPUs are block-oriented devices, the time required to load a single byte of memory is the same as loading the memory block around the same address. The block size of NVIDIA GPUs is typically 128 bytes. Therefore, optimizations such as memory fusion and operator fusion were performed. Under the premise of batch_size=1, compared with FasterTransformer, the speed-up reached a doubling effect, achieving a 2x improvement in speed.
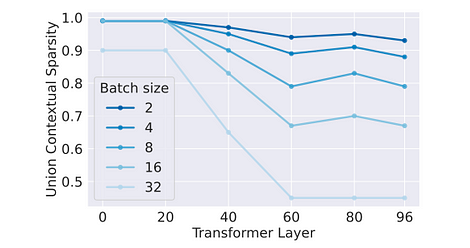
Throughput Impact: Since activations are functions of each token, effective sparsity is also randomly distributed across tokens. Therefore, the effectiveness of sparse optimization decays exponentially with increasing batch size. This can be referenced in the ablation experiments conducted in the paper.
Reducing Inference Threshold
Organizing the current partially offloading methods and the DejaVu method, as shown in the table below:
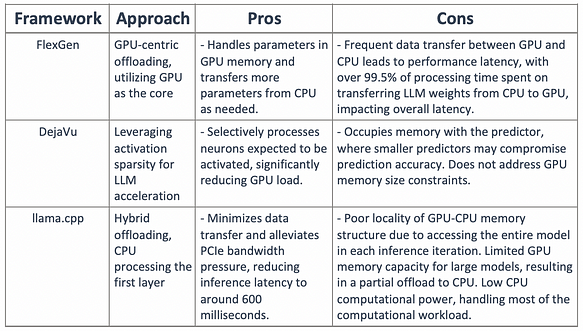
Can activation sparsity and offloading methods be combined to design a GPU-CPU hybrid inference engine: where hot-activated neurons are preloaded onto the GPU for fast access, while cold-activated neurons are computed on the CPU, significantly reducing GPU memory requirements and CPU-GPU data transfer?
The answer is, naturally, ‘YES’.
One such solution is PowerInfer[10], which can run OPT-175B on a single NVIDIA RTX 4090 GPU, achieving token generation speeds only 18% lower than top-tier A100 GPU servers. Besides offloading and activation sparsity, other aspects such as Brainstorm[9], SparTA[15], and Flash-llm[16] also hold reference value.
Overview:
PowerInfer preloads weights onto the GPU for frequently activated neurons, while weights for less active neurons are retained on the CPU.
To reduce inference latency, the inference engine only computes neurons predicted by the online predictor to be active, skipping most inactive neurons. Additionally, the preload strategy enables PowerInfer to allocate a significant portion of inference tasks to the GPU, as the hot-activated neurons loaded onto the GPU constitute the majority of activations. For cold-activated neurons not in GPU memory, PowerInfer performs computations on the CPU, eliminating the need to transfer weights to the GPU.
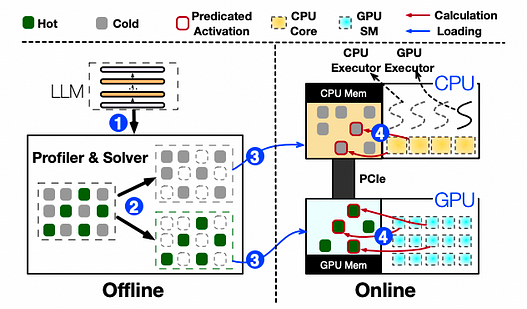
The architecture overview and inference workflow of PowerInfer
PowerInfer comprises offline and online components. Due to variations in locality properties among different LLMs, the offline component analyzes the activation sparsity of the LLM, distinguishing between hot and cold neurons. In the online phase, the inference engine loads both types of neurons into the GPU and CPU and serves LLM requests with low latency at runtime. Before processing user requests, the online engine assigns the two types of neurons to their respective processing units based on the output of the offline solver. At runtime, the engine creates GPU and CPU executors, which are threads running on the CPU side, to manage concurrent CPU-GPU computations. The engine also predicts neuron activations and skips inactive neurons. Activated neurons are preloaded into GPU memory for processing, while the CPU computes results for its neurons and transfers them to the GPU for integration. The engine uses sparse neuron-aware operators on both CPU and GPU, focusing on individual neuron rows/columns within matrices.
Project Link: https://github.com/SJTU-IPADS/PowerInfer
Single-layer computation optimization
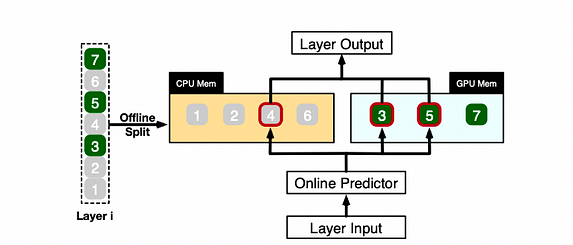
An illustrative example shows how PowerInfer calculates different neurons for one LLM layer
PowerInfer coordinates GPU and CPU to handle neurons in a layer by classifying neurons based on offline data, assigning hot neurons (e.g., index 3, 5, 7) to GPU memory, and allocating other neurons to CPU memory.
Upon receiving input, the predictor identifies which neurons in the current layer are likely to be activated. For example, it predicts the activation of neurons 3, 4, and 5. It’s worth noting that hot neurons identified through offline statistical analysis may not always align with runtime activation behavior. For instance, neuron 7, although marked as hot, may be inactive in a given scenario.
Subsequently, both CPU and GPU process the predicted active neurons while ignoring inactive ones. The GPU computes neurons 3 and 5, while the CPU handles neuron 4. Once the computation for neuron 4 is complete, its output is sent to the GPU for result integration.
Online Inference (Neuron-aware Inference Engine)
- Adaptive Sparse Predictor
The online inference engine in PowerInfer reduces computational load by only processing neurons predicted to be activated. This approach is also utilized in DejaVu, advocating for training a fixed-size set of MLP predictors. In each Transformer layer, DejaVu leverages two independent predictors to forecast the activation of neurons in self-attention and MLP blocks.
However, designing effective predictors for local deployment with limited resources poses challenges, necessitating a balance between prediction accuracy and model size.
PowerInfer employs an iterative training method for non-fixed-size predictors for each Transformer layer. This process first establishes a baseline model size based on the layer’s sparsity profile. Subsequently, considering internal activation skew, the model size is iteratively adjusted to maintain accuracy. MLP predictors typically comprise input, hidden, and output layers. Since the sizes of input and output layers are determined by the structure of the Transformer layer, modifications primarily target the hidden layer. During the iterative adjustment process, the size of the hidden layer is modified based on observed skewness. For layers exhibiting significant skewness, the size of the hidden layer gradually decreases until the accuracy drops below 95%. Conversely, for layers with minimal skewness, dimensions are increased to enhance accuracy. Through this approach, PowerInfer effectively confines predictor parameters to 10% of the total LLM parameters.
- GPU-CPU Hybrid Execution
Before inference, PowerInfer constructs a computational directed acyclic graph (DAG) where each node represents a computation LLM inference operator and stores it in a global queue in CPU memory. Each operator in the queue is labeled with its required operators. During inference, two types of executors (created by the host operating system pthread) manage computations on CPU and GPU. They extract operators from the global queue, check dependencies, and assign them to the appropriate processing units. GPU and CPU use their neuron-aware operators, with the GPU executor launching GPU operators using APIs like cudaLaunchKernel, while the CPU executor coordinates unused CPU cores for computation.
Experimental Conclusion
Performance Comparison
Various models’ speed-up on the FP16 format PC-High. The X-axis represents the output length, while the Y-axis indicates the speed-up ratio compared to llama.cpp. The number above each bar represents the end-to-end generation speed (tokens/s). The input length configured for the first row in the graph is approximately 64, while for the second row, it’s about 128.
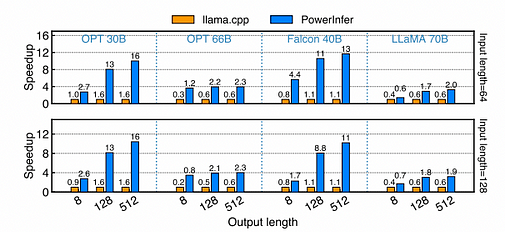
On a PC-High equipped with NVIDIA RTX 4090, various models and input-output configurations exhibit different generation speeds. On average, PowerInfer achieves a generation speed of 8.32 tokens/s, with a peak of 16.0 tokens/s, which is significantly superior to llama.cpp, with an average speed-up of 7.23 times, while Falcon-40B reaches up to 11.69 times. As the number of output tokens increases, the performance advantage of PowerInfer becomes more pronounced, as the generation phase plays a more important role in the overall inference time. During this stage, a small number of neurons are activated on both CPU and GPU, reducing unnecessary computations compared to llama.cpp. For example, in the case of OPT-30B, only about 20% of neurons are activated per generated token, with the majority processed on the GPU, showcasing the advantage of PowerInfer’s neuron-aware inference engine.
Batch size impact:
When the batch size is less than 32, PowerInfer demonstrates a significant advantage, with an average improvement of 6.08 times compared to llama.cpp. As the batch size increases, the speed-up ratio provided by PowerInfer decreases. This reduction is attributed to the decreased sparsity of joint activations in the model. However, even with a batch size set to 32, PowerInfer still maintains a considerable speed-up ratio, reaching a 4.38 times improvement.
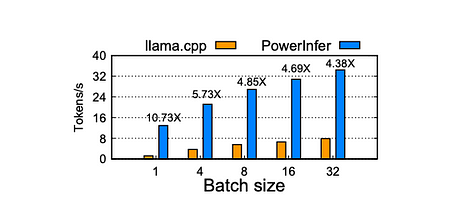
Batch inference speedup of Falcon-40B on PC-High. The X axis indicates the request batch size, the Y axis represents the end-to-end token generation speed (tokens/s). The number above each bar shows the speedup compared with
Load Comparison
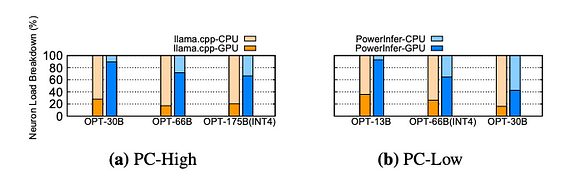
Neuron load distribution on CPU and GPU during inference. The yellow block refers to llama.cpp, and blue block refers to Powe
The distribution of neuron loads between CPU and GPU in PowerInfer and llama.cpp is compared. Neuron load refers to the proportion of activated neuron computations performed by each processing unit. It is worth noting that on a PC-High system, PowerInfer significantly increases the share of neuron load on the GPU, rising from an average of 20% to 70%. This indicates that the GPU handles 70% of activated neurons. However, when the model’s memory requirements far exceed the capacity of the GPU, such as running a 60GB model on an 11GB 2080Ti GPU, the neuron load on the GPU decreases to 42%. This decrease is due to the limited memory of the GPU, which is insufficient to accommodate all hot-activated neurons, necessitating CPU computation for a portion of these neurons.
In scenarios involving longer input prompts and relatively shorter output lengths, PowerInfer only exhibits limited performance improvements. In such cases, the stage of processing a large number of tokens concurrently becomes a key factor in determining the inference speed. This results in each token activating a unique set of neurons, significantly reducing activation sparsity. As a result, the CPU becomes the primary bottleneck in the inference process, tasked with processing a large number of cold-activated neurons but constrained by computational capacity.
Conclusion
Activation sparsity technology has brought revolutionary breakthroughs to large-scale language models. By sparsifying the activations of neural networks to accelerate the inference process while reducing GPU computation and I/O loads, inference speed and performance are improved. This approach does not require retraining and achieves activation sparsity only through fine-tuning, significantly reducing costs while maintaining model performance. The application prospects of activation sparsity technology are exciting, bringing more possibilities to the field of deep learning. We look forward to further development and widespread application of this technology.
Reference Papers
[5]ReLU Strikes Back:Exploiting Activation Sparsity in Large Language Models
[7]Inducing and exploiting activation sparsity for fast inference on deep neural networks
[8]Sparse is enough in scaling transformers
novita.ai provides Stable Diffusion API and hundreds of fast and cheapest AI image generation APIs for 10,000 models.🎯 Fastest generation in just 2s, Pay-As-You-Go, a minimum of $0.0015 for each standard image, you can add your own models and avoid GPU maintenance. Free to share open-source extensions.
Recommended reading



