

Sparse Techniques for 100X Speedup in Large Language ModeI Inference. Explore the secrets behind LLM-Pruner techniques, doubling the speed of inference for faster results.
Introduction
It is well known that there are three core factors affecting Large Language Model (LLM) performance on GPUs: (1) GPU computational power, (2) GPU input/output (I/O), and (3) GPU memory size. It’s worth noting that for today’s LLMs, factor (2) is the primary bottleneck during the inference stage.
This blog focuses on the feasibility of accelerating LLM inference on consumer-grade graphics cards through pruning or sparsity, based on the latest research papers and engineering practices.
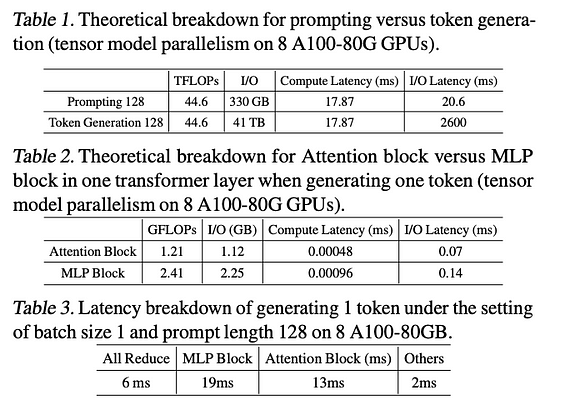
Firstly, referring to the analysis of LLM inference latency metrics in [1], the following three conclusions are drawn:
- In the prompting and token generation stages of LLM, the token generation stage takes much longer due to the I/O latency incurred by loading model parameters.
- In LLM inference, both the Attention and MLP modules are bottlenecks, with the MLP module accounting for about two-thirds of the I/O latency.
- The proportion of All Reduce (communication between GPUs) is relatively low, indicating that the main optimization direction lies within the transformer architecture itself.
For detailed data, please refer to the figure below:
To improve inference efficiency, various techniques have been explored, including quantization, inference decoding, distillation, and sparsity. This blog focuses on sparsity and provides an in-depth introduction.
Introduction to Sparsity.
Model pruning, also known as model sparsity, differs from model quantization in that instead of compressing each weight parameter, sparsity methods attempt to directly “remove” certain weight parameters. The principle of model pruning is to reduce the number of parameters and computational load in the model by eliminating “unimportant” weights while attempting to maintain the model’s accuracy.
The paper [17] first introduces the method of weight pruning: all weights below a certain threshold are pruned, followed by fine-tuning until the accuracy reaches the desired level. The authors of this paper conducted experiments on LeNet, AlexNet, and VGGNet to verify the effectiveness of pruning.
Another conclusion regarding L1 and L2 regularization suggests that L1 regularization performs better without fine-tuning, while L2 regularization performs better with fine-tuning. Additionally, earlier layers in the network are more sensitive to pruning, making an iterative pruning approach preferable. Furthermore, based on experiments, the authors propose the Lottery Ticket hypothesis.
The Lottery Ticket Hypothesis states that for a pre-trained network, there exists a subnetwork that can achieve similar accuracy to the original network without exceeding the original network’s training rounds. This subnetwork is similar to winning a lottery ticket.
To restore model accuracy, it is typically necessary to retrain the model after pruning. The typical three-stage pipeline for model pruning consists of training, pruning, and fine-tuning steps, with changes in network connectivity before and after pruning, as shown in the figure below.
Meanwhile, according to objects that can be sparsified in deep learning models, sparsity in deep neural networks mainly includes weight sparsity, activation sparsity, and gradient sparsity.
The above is a brief introduction to sparsity. Next, we will share in three parts the key proposition “How LLM Accelerates Inference through Sparsity.” The first part, “How Large Models Prune,” will be discussed. The second part will cover “How to Speed Up Inference Using Activation Sparsity,” and the third part will delve into “The Impact of Sparsity Compilers on LLM Inference.”
In this comprehensive guide, we will explore part one, “Unveiling LLM-Pruner Techniques: Doubling Inference Speed,” authored by Zachary from the novita.ai team.
How LLM re Pruned
LLMs often have scales of several hundred billion parameters, making conventional retraining or iterative pruning methods impractical. Therefore, methods such as iterative pruning and the lottery hypothesis [2,3] can only be applied to smaller-scale models.
Pruning can be effectively applied to vision and smaller-scale language models and tasks. However, the optimal pruning methods require extensive retraining of the model to recover accuracy loss caused by the removal of pruned elements. Therefore, when dealing with models of the scale of GPT, the cost also becomes prohibitively high. While there are some one-shot pruning methods that compress models without the need for retraining, their computational cost is too high to be applied to models with billions of parameters.
Recently, there have been breakthroughs in pruning techniques for LLMs, which will be discussed in turn in this blog.
SparseGPT
SparseGPT[12] is the first one-shot precise pruning technique in the LLM scenario that can effectively operate on models with scales of 100–1000 billion parameters. The working principle of SparseGPT simplifies the pruning problem into a large-scale sparse regression instance. It is based on new approximate sparse regression solvers for solving hierarchical compression problems, and its efficiency is sufficient to execute on the largest GPT model (175B parameters) using a single GPU in a matter of hours. Additionally, SparseGPT achieves high accuracy without requiring any fine-tuning, and the accuracy loss after pruning can be negligible. For example, when executed on the largest publicly available generative language models (OPT-175B and BLOOM-176B), SparseGPT achieves 50–60% sparsity in one-shot testing, with minimal loss in accuracy measured by perplexity or zero-shot testing accuracy.
For engineering code, refer to the project: https://github.com/IST-DASLab/sparsegpt
Figure 1 presents the experimental results, highlighting two key points: firstly, as shown in Figure 1 (left), SparseGPT is capable of pruning up to 60% uniform layer-wise sparsity in the 175B parameter variants of the OPT family, with minimal loss in accuracy. In contrast, the only known one-shot baseline working at this scale — Magnitude Pruning — maintains accuracy only up to 10% sparsity and completely collapses beyond 30% sparsity.
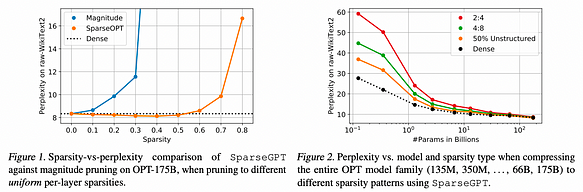
Secondly, as illustrated in Figure 2 (right), SparseGPT can also accurately enforce sparsity in more stringent but hardware-friendly 2:4 and 4:8 semi-structured sparse patterns. While these patterns often entail additional accuracy loss compared to dense baselines, particularly for smaller models, computational speed-ups can be directly inferred from these sparse patterns. Additionally, the sparsity induced by the technique can blend well with additional compression obtained through quantization.
LLM-Pruner
LLM-Pruner[13] is a structured pruning method that selectively removes non-essential coupling structures based on gradient information, maximizing sparsity while retaining most of the functionality of LLM. LLM-Pruner, through LoRA, efficiently restores the performance of pruned models with just 3 hours and 50K data.
LLM-Pruner is the first framework designed specifically for structured pruning of LLMs, with the advantages summarized as follows: (i) Task-agnostic compression, where compressed language models retain their ability as multitask solvers. (ii) Reduced demand for original training corpora, with compression requiring only 50,000 publicly available samples, significantly reducing the budget for acquiring training data. (iii) Rapid compression, with the compression process completed within three hours. (iv) Automatic structural pruning framework, where all structural dependencies are grouped without the need for any manual design.
To evaluate the effectiveness of LLM-Pruner, extensive experiments were conducted on three large-scale language models: LLaMA-7B, Vicuna-7B, and ChatGLM-6B. Compressed models were evaluated using nine datasets to assess the generation quality and zero-shot classification performance of pruned models.
Referencing the table below, pruning LLaMA-7B by 20% using LLM-Pruner with 2.59 million samples resulted in minimal decrease in model performance but a notable 18% increase in inference speed.

Results of LLM-Pruner with 2.59M samples
Wanda
Wanda[14], a pruning method based on weights and activations, is a novel, simple, and effective approach aimed at inducing sparsity in pre-trained LLMs. Inspired by recent observations of significant value features in LLMs, Wanda prunes weights by multiplying each output with the corresponding input activation by the minimum quantized value. Notably, Wanda does not require retraining or weight updates, and pruned LLMs can be used as-is. Evaluation of Wanda on LLaMA and LLaMA-2 validates its superiority over established magnitude pruning baselines, demonstrating competitiveness compared to recent methods involving dense weight updates.
For the engineering code, please refer to the project: https://github.com/locuslab/wanda
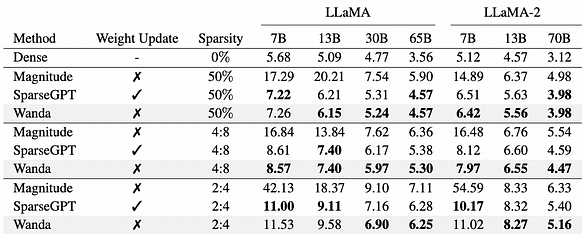
WikiText perplexity of pruned LLaMA and LLaMA-2 models. Wanda performs competitively against prior best method SparseGPT, without introducing any weight update.
Referring to the above figure, Wanda and SparseGPT demonstrate comparable performance in model pruning.
Drawbacks of Conventional Pruning Methods:
- Hardware Support: Achieving clock-time acceleration through non-structured sparsity is challenging due to known difficulties with modern hardware. For instance, recent developments like SparseGPT have achieved 60% non-structured sparsity through zero-shot pruning, yet have not resulted in any significant clock-time acceleration effects.
- Deployment Challenges: Meeting specific requirements through model sparsity in contexts like In-Context Learning presents challenges. While many works have demonstrated the effectiveness of task-specific pruning, maintaining different models for each task conflicts with the positioning of LLM itself, posing deployment obstacles.
Conclusion:
In summary, innovative pruning methods such as SparseGPT, LLM-Pruner, and Wanda offer new perspectives and technical means for pruning large models while maintaining high performance. However, further research and exploration are still needed to address challenges in hardware support and practical applications. In the next blog post, we will explore the second part: “How to Speed Up Inference Using Activation Sparsity.”
Reference paper
[1]Deja Vu: Contextual Sparsity for Efficient LLMs at Inference Time
[4]The Hardware Lottery
[6]Rethinking the Role of Scale for In-Context Learning: An Interpretability-based Case Study at 66 Billion Scale
[12]SparseGPT: Massive Language Models Can Be Accurately Pruned in One-Shot
[13]LLM-Pruner: On the Structural Pruning of Large Language Models
[14]A Simple and Effective Pruning Approach for Large Language Models
[17]Learning both Weights and Connections for Efficient Neural Networks
novita.ai provides Stable Diffusion API and hundreds of fast and cheapest AI image generation APIs for 10,000 models.🎯 Fastest generation in just 2s, Pay-As-You-Go, a minimum of $0.0015 for each standard image, you can add your own models and avoid GPU maintenance. Free to share open-source extensions.
Recommended reading



