

Techniques parcimonieuses pour un accélération 100X de l’inférence des grands modèles de langage. Découvrez la magie de la parcimonie d’activation : pas de réentraînement, faible coût et haute efficacité, menant à une augmentation significative de la vitesse d’inférence GPU !
Dans la discussion précédente sur « Comment les LLM accélèrent l’inférence grâce à la parcimonie », nous avons exploré la première partie, « [Comment les grands modèles élaguent](Unveiling LLM-Pruner Techniques: Doubling Inference Speed) ». Cette fois, nous continuons à plonger dans la deuxième partie, « Comment accélérer l’inférence en utilisant la parcimonie d’activation », et dans la prochaine discussion, nous examinerons la troisième partie, « L’impact des compilateurs parcimonieux sur l’inférence des LLM ».
Nous nous demandons s’il existe une méthode qui puisse répondre à plusieurs exigences : ne pas nécessiter de réentraînement du modèle mais seulement un fine-tuning (faible coût de transfert du modèle), maintenir les performances du modèle (bonne efficacité), être bien supportée par le matériel moderne (GPU/CPU), et réduire significativement les calculs GPU et les E/S pour optimiser la latence (vitesse d’inférence rapide).
En effet, une telle méthode existe, et la parcimonie d’activation en est une qui remplit toutes ces exigences.
Il convient de noter que l’utilisation de fonctions d’activation ReLU dans les réseaux de neurones induit une parcimonie d’activation et a été adoptée dans divers travaux antérieurs. En moyenne, cette parcimonie d’activation sur toutes les couches entraîne des économies significatives dans le transfert de poids (E/S) entre GPU et CPU, affectant environ 95 % des lignes des poids de la couche de projection. Cette réduction se traduit directement par des économies de calcul, car les résultats des opérations de multiplication matricielle pour ces lignes seront nuls.
De plus, contrairement à la parcimonie non structurée (par exemple, la parcimonie des poids non structurée), ce type de parcimonie est plus compatible avec le matériel car il annule des blocs plus étendus et structurés (comme des lignes ou des colonnes).
De même, en se référant à la figure ci-dessous, nous illustrons brièvement l’efficacité de la parcimonie d’activation pour accélérer l’inférence.
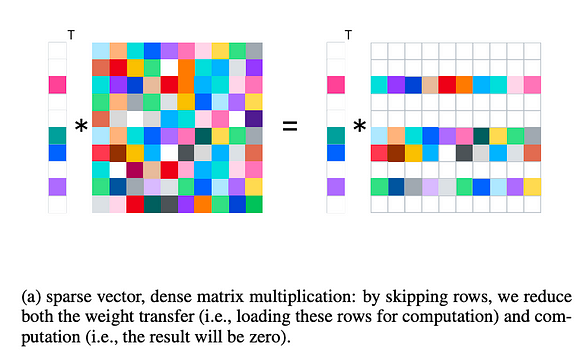
Dans le cas de la parcimonie d’activation, une multiplication vecteur parcimonieux - matrice dense est effectuée pendant l’inférence, tandis que pendant l’entraînement, elle est ajustée en multiplication matrice parcimonieuse - matrice dense.
- Réduction de la charge de calcul : Cette parcimonie semi-structurée (contrairement à la parcimonie non structurée de l’élagage des poids) permet de sauter certaines lignes, réduisant ainsi le calcul. Par exemple, des bibliothèques comme cusparse prennent déjà en charge les opérations correspondantes.
- Réduction des transferts E/S : Pendant l’inférence, les E/S GPU sont un goulot d’étranglement (par exemple, du cache GPU au cache CPU ou de la DRAM GPU au cache GPU). Cette méthode permet de sauter les lignes inutiles, réduisant ainsi les E/S.
Faisabilité de la parcimonie d’activation
Le contenu suivant se réfère principalement aux données de [5] pour démontrer la faisabilité de l’application de l’activation ReLU sur les LLM.
Comparaison entre modèles avec et sans parcimonie d’activation
En mesurant et analysant la FFN (Feed-Forward Network) de trois modèles, OPT 6.7B, Llama 7B (avec activation SiLU) et Falcon 7B (avec activation GELU), les trois conclusions suivantes sont tirées :
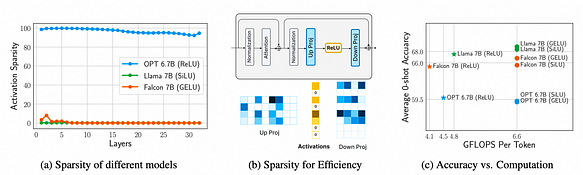
a. La comparaison entre Llama 7B (avec SiLU), Falcon 7B (avec GELU) et OPT 6.7B (avec ReLU) révèle que ReLU induit plus de 90 % de parcimonie d’activation, tandis que SiLU et GELU induisent moins de 10 % de parcimonie d’activation, démontrant que ReLU peut induire des activations parcimonieuses.
b. La parcimonie d’activation entraîne des économies significatives dans la transmission des poids (E/S), affectant environ 95 % des lignes des poids de la projection aval.
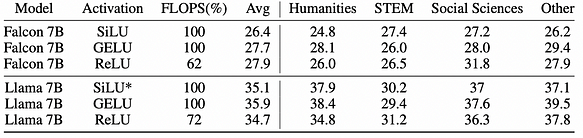
c. Le choix de la fonction d’activation n’affecte pas significativement la précision car GELU, SiLU ou ReLU sont au même niveau de précision. Cependant, ReLU peut économiser 32 % de la charge de calcul (FLOPS).
Réduction des coûts d’entraînement
De nombreux LLM modernes (tels que Llama et Falcon) ont été entraînés en utilisant des activations non ReLU. Un entraînement à partir de zéro n’est pas rentable ; il est donc nécessaire d’envisager la mise en œuvre de l’activation ReLU par fine-tuning. Le modèle est affiné à travers les deux phases suivantes :
- Première phase : les activations ReLU existantes (dans le cas d’OPT) sont conservées, ou la fonction d’activation entre la projection montante et la projection descendante est remplacée par ReLU (dans le cas de Falcon et Llama, où GELU et SiLU sont utilisés).
- Deuxième phase : de nouvelles activations ReLU sont insérées après les couches de normalisation.
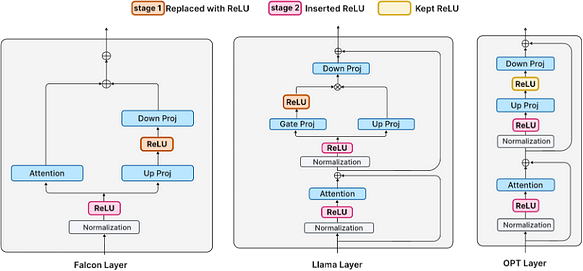
Première phase — Remplacement des activations non ReLU
Remplacer les activations non ReLU par ReLU dans les couches FFN. Pour les modèles Falcon et Llama, cela implique de remplacer respectivement GELU et SiLU. Il est noté que puisque le modèle OPT utilise déjà des activations ReLU, aucun changement n’est apporté. Après un fine-tuning sur 30B tokens de RefinedWeb, le modèle présente une parcimonie significative dans les activations.

Deuxième phase — Insertion de nouvelles ReLU
Dans la phase précédente, nous avons remplacé les activations non ReLU pour obtenir plus de parcimonie. Cela a donné des entrées parcimonieuses pour la couche de projection descendante, représentant environ 30 % du coût de calcul total. Cependant, outre la projection descendante, il existe d’autres multiplications matrice-vecteur dans les couches de décodage du transformer, comme la projection montante dans la couche FFN et la projection QKV dans la couche d’attention. Collectivement, ces multiplications matrice-vecteur consomment environ 55 % du coût de calcul total.
Dans les couches Transformer modernes, les entrées des couches d’attention et FFN proviennent toutes deux de couches de normalisation, telles que LayerNorm ou RMSNorm. Ces couches peuvent être considérées comme une forme spécifique de MLP où elles n’appliquent pas de paramètres apprenables arbitraires mais apprennent à mettre à l’échelle l’entrée. Par conséquent, nous appliquons ReLU pour obtenir des activations parcimonieuses après les couches de normalisation, atteignant ainsi l’objectif de la deuxième phase.
Résultats de mesure
Coût du fine-tuning : Le fine-tuning a été réalisé avec 30B et 50B tokens dans les phases une et deux respectivement. Comparé au coût d’entraînement de 1T tokens pour Llama, le coût n’était que d’environ 3 à 5 %.
Efficacité : En comparant la latence d’inférence après fine-tuning pour Llama et Falcon, aucune diminution perceptible des performances du modèle n’a été observée. Cependant, une amélioration significative de plus de 30 % de la vitesse d’inférence a été constatée.
Globalement, les résultats confirment que l’obtention d’une parcimonie d’activation par fine-tuning peut réduire les FLOPS d’inférence à différents stades et taux tout en maintenant des performances comparables sur différentes tâches. Les modèles d’activation parcimonieuse correspondants sont disponibles sur le projet : https://huggingface.co/SparseLLM.
Comment accélérer l’inférence
La prédiction de parcimonie contextuelle de DejaVu, comme décrit dans l’article référencé [1], est une excellente approche.
Comment utiliser pleinement la parcimonie structurée pour l’accélération
La parcimonie contextuelle suppose que les modèles pré-entraînés présentent une parcimonie contextuelle, ce qui signifie que les calculs de parcimonie pour l’Attention et le MLP atteignent le même effet que les calculs complets. Avec cette prémisse, une parcimonie contextuelle moyenne de 85 % dans les modèles parcimonieux structurés peut entraîner une réduction septuple des paramètres pour chaque entrée spécifique tout en maintenant la précision, améliorant ainsi significativement les performances d’inférence.
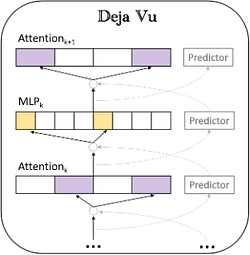
Comme le montre la figure ci-dessus, un prédicteur parcimonieux asynchrone est conçu sur la base de la parcimonie contextuelle, prédisant à l’avance la parcimonie de l’Attention et du MLP de la couche suivante. Cette approche garantit non seulement l’efficacité de l’inférence, mais réduit également considérablement les charges de calcul et d’E/S.
Validation de l’existence de la parcimonie contextuelle
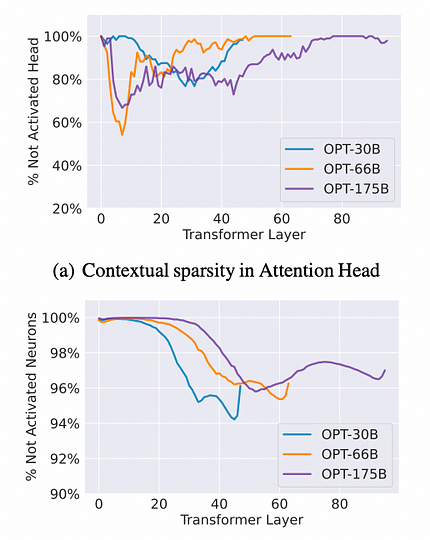
Des tests ont été effectués sur les modèles OPT-175B, 66B et 30B avec divers ensembles de données aval tels que OpenBookQA et Wiki-Text. La méthode consistait en deux passages avant du modèle pour identifier la parcimonie contextuelle pour chaque exemple d’entrée. Lors du premier passage, un sous-ensemble de paramètres, en particulier ceux associés aux têtes d’Attention et aux neurones MLP générant de grandes normes de sortie pour les entrées, a été enregistré. Lors du second passage, chaque exemple d’entrée a été calculé en utilisant uniquement le sous-ensemble de paramètres enregistré. Étonnamment, les deux passages avant ont donné des prédictions ou des performances similaires pour toutes les tâches d’apprentissage contextuel et de modélisation du langage.
Observations : En moyenne, les têtes d’Attention peuvent imposer une parcimonie allant jusqu’à 80 %, tandis que les neurones MLP peuvent atteindre une parcimonie allant jusqu’à 95 %, ce qui donne une parcimonie globale d’environ 85 %, pouvant conduire à une accélération septuple. Pour des données de référence spécifiques, veuillez vous référer à la figure ci-dessous.
Impact technique
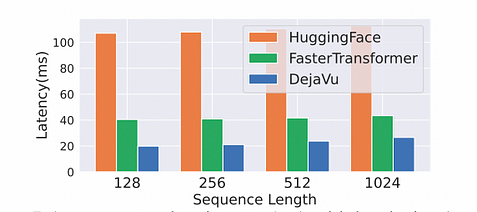
Effet d’accélération : Comme les GPU sont des dispositifs orientés blocs, le temps nécessaire pour charger un seul octet de mémoire est le même que pour charger le bloc mémoire autour de la même adresse. La taille de bloc des GPU NVIDIA est généralement de 128 octets. Par conséquent, des optimisations telles que la fusion mémoire et la fusion d’opérateurs ont été effectuées. Sous la condition batch_size=1, par rapport à FasterTransformer, l’accélération a atteint un effet de doublement, soit une amélioration de 2x de la vitesse.
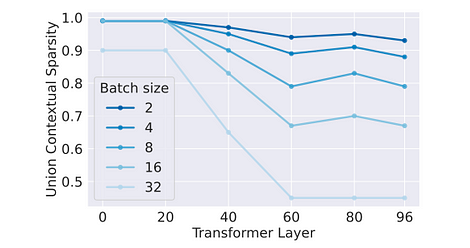
Impact sur le débit : Comme les activations sont fonctions de chaque token, la parcimonie effective est également distribuée aléatoirement entre les tokens. Par conséquent, l’efficacité de l’optimisation parcimonieuse décroît exponentiellement avec l’augmentation de la taille du lot. Cela peut être consulté dans les expériences d’ablation menées dans l’article.
Réduction du seuil d’inférence
Organisation des méthodes de déchargement partiel actuelles et de la méthode DejaVu, comme indiqué dans le tableau ci-dessous :
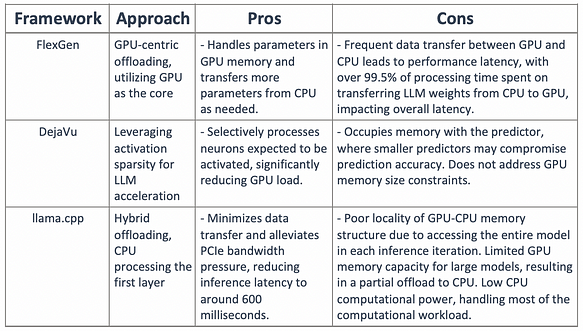
Peut-on combiner la parcimonie d’activation et les méthodes de déchargement pour concevoir un moteur d’inférence hybride GPU-CPU : où les neurones chauds activés sont préchargés sur le GPU pour un accès rapide, tandis que les neurones froids activés sont calculés sur le CPU, réduisant considérablement les besoins en mémoire GPU et le transfert de données CPU-GPU ?
La réponse est, naturellement, « OUI ».
Une telle solution est PowerInfer[10], qui peut exécuter OPT-175B sur un seul NVIDIA RTX 4090, atteignant des vitesses de génération de tokens seulement 18 % inférieures à celles des serveurs GPU A100 haut de gamme. Outre le déchargement et la parcimonie d’activation, d’autres aspects tels que Brainstorm[9], SparTA[15] et Flash-llm[16] ont également une valeur de référence.
Aperçu :
PowerInfer précharge les poids sur le GPU pour les neurones fréquemment activés, tandis que les poids des neurones moins actifs sont conservés sur le CPU.
Pour réduire la latence d’inférence, le moteur d’inférence ne calcule que les neurones prédits comme actifs par le prédicteur en ligne, sautant la plupart des neurones inactifs. De plus, la stratégie de préchargement permet à PowerInfer d’allouer une grande partie des tâches d’inférence au GPU, car les neurones chauds activés chargés sur le GPU constituent la majorité des activations. Pour les neurones froids activés qui ne sont pas en mémoire GPU, PowerInfer effectue les calculs sur le CPU, éliminant ainsi le besoin de transférer les poids vers le GPU.
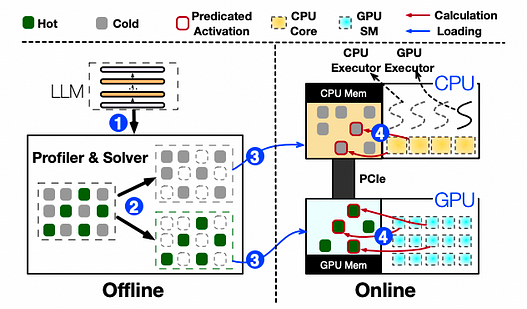
Aperçu de l’architecture et flux de travail d’inférence de PowerInfer
PowerInfer comprend des composants hors ligne et en ligne. En raison des variations des propriétés de localité entre différents LLM, le composant hors ligne analyse la parcimonie d’activation du LLM, distinguant les neurones chauds et froids. Dans la phase en ligne, le moteur d’inférence charge les deux types de neurones dans le GPU et le CPU et sert les requêtes LLM avec une faible latence à l’exécution. Avant de traiter les requêtes utilisateur, le moteur en ligne attribue les deux types de neurones à leurs unités de traitement respectives en fonction de la sortie du solveur hors ligne. À l’exécution, le moteur crée des exécuteurs GPU et CPU, qui sont des threads s’exécutant côté CPU, pour gérer les calculs CPU-GPU simultanés. Le moteur prédit également les activations des neurones et saute les neurones inactifs. Les neurones activés sont préchargés en mémoire GPU pour traitement, tandis que le CPU calcule les résultats pour ses neurones et les transfère au GPU pour intégration. Le moteur utilise des opérateurs parcimonieux conscients des neurones à la fois sur CPU et GPU, se concentrant sur les lignes/colonnes individuelles des neurones dans les matrices.
Lien du projet : https://github.com/SJTU-IPADS/PowerInfer
Optimisation du calcul par couche unique
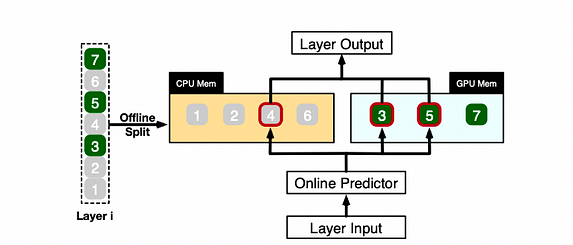
Un exemple illustratif montre comment PowerInfer calcule différents neurones pour une couche LLM
PowerInfer coordonne le GPU et le CPU pour traiter les neurones d’une couche en classifiant les neurones en fonction des données hors ligne, en attribuant les neurones chauds (par exemple, indices 3, 5, 7) à la mémoire GPU, et en allouant les autres neurones à la mémoire CPU.
À la réception de l’entrée, le prédicteur identifie quels neurones de la couche actuelle sont susceptibles d’être activés. Par exemple, il prédit l’activation des neurones 3, 4 et 5. Il est à noter que les neurones chauds identifiés par analyse statistique hors ligne peuvent ne pas toujours correspondre au comportement d’activation à l’exécution. Par exemple, le neurone 7, bien que marqué comme chaud, peut être inactif dans un scénario donné.
Ensuite, le CPU et le GPU traitent les neurones actifs prédits tout en ignorant les inactifs. Le GPU calcule les neurones 3 et 5, tandis que le CPU traite le neurone 4. Une fois le calcul du neurone 4 terminé, sa sortie est envoyée au GPU pour intégration des résultats.
Inférence en ligne (moteur d’inférence conscient des neurones)
- Prédicteur parcimonieux adaptatif
Le moteur d’inférence en ligne de PowerInfer réduit la charge de calcul en ne traitant que les neurones prédits comme activés. Cette approche est également utilisée dans DejaVu, qui préconise l’entraînement d’un ensemble de prédicteurs MLP de taille fixe. Dans chaque couche Transformer, DejaVu utilise deux prédicteurs indépendants pour prévoir l’activation des neurones dans les blocs d’auto-attention et MLP.
Cependant, la conception de prédicteurs efficaces pour un déploiement local avec des ressources limitées pose des défis, nécessitant un équilibre entre précision de prédiction et taille du modèle.
PowerInfer utilise une méthode d’entraînement itérative pour des prédicteurs de taille non fixe pour chaque couche Transformer. Ce processus établit d’abord une taille de modèle de base basée sur le profil de parcimonie de la couche. Ensuite, en tenant compte de l’asymétrie d’activation interne, la taille du modèle est ajustée itérativement pour maintenir la précision. Les prédicteurs MLP comprennent généralement des couches d’entrée, cachée et de sortie. Étant donné que les tailles des couches d’entrée et de sortie sont déterminées par la structure de la couche Transformer, les modifications ciblent principalement la couche cachée. Pendant le processus d’ajustement itératif, la taille de la couche cachée est modifiée en fonction de l’asymétrie observée. Pour les couches présentant une asymétrie significative, la taille de la couche cachée diminue progressivement jusqu’à ce que la précision tombe en dessous de 95 %. Inversement, pour les couches avec une asymétrie minimale, les dimensions sont augmentées pour améliorer la précision. Grâce à cette approche, PowerInfer confine efficacement les paramètres du prédicteur à 10 % du total des paramètres LLM.
- Exécution hybride GPU-CPU
Avant l’inférence, PowerInfer construit un graphe acyclique dirigé (DAG) de calcul où chaque nœud représente un opérateur d’inférence LLM et le stocke dans une file d’attente globale en mémoire CPU. Chaque opérateur dans la file est étiqueté avec ses opérateurs requis. Pendant l’inférence, deux types d’exécuteurs (créés par le pthread du système d’exploitation hôte) gèrent les calculs sur CPU et GPU. Ils extraient les opérateurs de la file globale, vérifient les dépendances et les assignent aux unités de traitement appropriées. Le GPU et le CPU utilisent leurs opérateurs conscients des neurones, l’exécuteur GPU lançant les opérateurs GPU à l’aide d’API telles que cudaLaunchKernel, tandis que l’exécuteur CPU coordonne les cœurs CPU inutilisés pour le calcul.
Conclusion expérimentale
Comparaison des performances
Accélération de divers modèles sur le format FP16 PC-High. L’axe X représente la longueur de sortie, tandis que l’axe Y indique le ratio d’accélération par rapport à llama.cpp. Le nombre au-dessus de chaque barre représente la vitesse de génération de bout en bout (tokens/s). La longueur d’entrée configurée pour la première rangée dans le graphique est d’environ 64, tandis que pour la deuxième rangée, elle est d’environ 128.
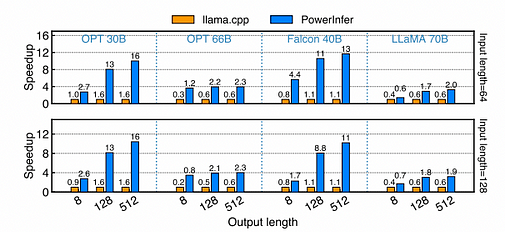
Sur un PC-High équipé d’un NVIDIA RTX 4090, divers modèles et configurations d’entrée-sortie présentent différentes vitesses de génération. En moyenne, PowerInfer atteint une vitesse de génération de 8,32 tokens/s, avec un pic de 16,0 tokens/s, ce qui est nettement supérieur à llama.cpp, avec une accélération moyenne de 7,23 fois, tandis que Falcon-40B atteint jusqu’à 11,69 fois. À mesure que le nombre de tokens de sortie augmente, l’avantage de performance de PowerInfer devient plus prononcé, car la phase de génération joue un rôle plus important dans le temps total d’inférence. Pendant cette étape, un petit nombre de neurones sont activés à la fois sur CPU et GPU, réduisant les calculs inutiles par rapport à llama.cpp. Par exemple, dans le cas d’OPT-30B, seulement environ 20 % des neurones sont activés par token généré, la majorité étant traitée sur le GPU, montrant l’avantage du moteur d’inférence conscient des neurones de PowerInfer.
Impact de la taille du lot :
Lorsque la taille du lot est inférieure à 32, PowerInfer présente un avantage significatif, avec une amélioration moyenne de 6,08 fois par rapport à llama.cpp. À mesure que la taille du lot augmente, le ratio d’accélération fourni par PowerInfer diminue. Cette réduction est attribuée à la diminution de la parcimonie des activations conjointes dans le modèle. Cependant, même avec une taille de lot fixée à 32, PowerInfer maintient un ratio d’accélération considérable, atteignant une amélioration de 4,38 fois.
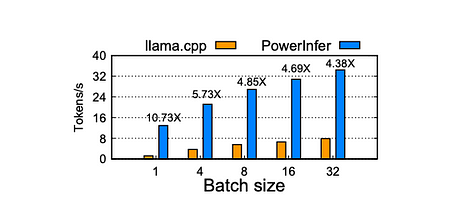
Accélération par lot de Falcon-40B sur PC-High. L’axe X indique la taille du lot de requêtes, l’axe Y représente la vitesse de génération de tokens de bout en bout (tokens/s). Le nombre au-dessus de chaque barre montre l’accélération par rapport à
Comparaison de charge
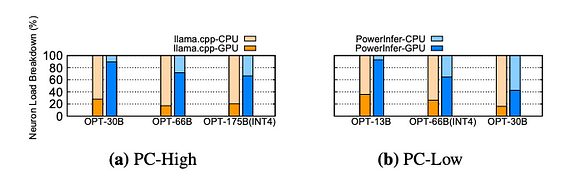
Distribution de la charge des neurones sur CPU et GPU pendant l’inférence. Le bloc jaune fait référence à llama.cpp, et le bloc bleu à PowerInfer
La distribution des charges des neurones entre CPU et GPU dans PowerInfer et llama.cpp est comparée. La charge des neurones fait référence à la proportion de calculs de neurones activés effectuée par chaque unité de traitement. Il est à noter que sur un système PC-High, PowerInfer augmente significativement la part de charge des neurones sur le GPU, passant d’une moyenne de 20 % à 70 %. Cela indique que le GPU gère 70 % des neurones activés. Cependant, lorsque les besoins en mémoire du modèle dépassent largement la capacité du GPU, par exemple en exécutant un modèle de 60 Go sur un GPU 2080Ti de 11 Go, la charge des neurones sur le GPU diminue à 42 %. Cette diminution est due à la mémoire limitée du GPU, insuffisante pour accueillir tous les neurones chauds activés, ce qui oblige le CPU à calculer une partie de ces neurones.
Dans les scénarios impliquant des invites d’entrée plus longues et des longueurs de sortie relativement plus courtes, PowerInfer ne présente que des améliorations de performance limitées. Dans de tels cas, l’étape de traitement d’un grand nombre de tokens simultanément devient un facteur clé déterminant la vitesse d’inférence. Cela entraîne l’activation d’un ensemble unique de neurones pour chaque token, réduisant considérablement la parcimonie d’activation. Par conséquent, le CPU devient le principal goulot d’étranglement dans le processus d’inférence, chargé de traiter un grand nombre de neurones froids activés mais limité par sa capacité de calcul.
Conclusion
La technologie de parcimonie d’activation a apporté des percées révolutionnaires aux grands modèles de langage. En rendant parcimonieuses les activations des réseaux de neurones pour accélérer le processus d’inférence tout en réduisant les charges de calcul et d’E/S du GPU, la vitesse et les performances d’inférence sont améliorées. Cette approche ne nécessite pas de réentraînement et atteint la parcimonie d’activation uniquement par fine-tuning, réduisant considérablement les coûts tout en maintenant les performances du modèle. Les perspectives d’application de la technologie de parcimonie d’activation sont passionnantes, apportant plus de possibilités au domaine de l’apprentissage profond. Nous attendons avec impatience le développement ultérieur et l’application généralisée de cette technologie.
Articles de référence
[5]ReLU Strikes Back:Exploiting Activation Sparsity in Large Language Models
[7]Inducing and exploiting activation sparsity for fast inference on deep neural networks
[8]Sparse is enough in scaling transformers
novita.ai fournit une API Stable Diffusion et des centaines d’API de génération d’images IA rapides et économiques pour 10 000 modèles. 🎯 Génération la plus rapide en seulement 2s, paiement à l’utilisation, à partir de 0,0015 $ par image standard, vous pouvez ajouter vos propres modèles et éviter la maintenance GPU. Partage gratuit d’extensions open source.
Lectures recommandées



