

大規模言語モデル推論における100倍高速化のためのスパース手法。活性化スパース性の魔法を発見:再トレーニング不要、低コスト、高効率で、GPU推論速度を大幅に向上!
前回の「LLMがスパース性を通じて推論を高速化する方法」に関する議論では、最初のパート「[大規模モデルの枝刈り方法](Unveiling LLM-Pruner Techniques: Doubling Inference Speed)」を探りました。今回は、第二のパート「活性化スパース性を用いて推論を高速化する方法」についてさらに掘り下げ、次回の議論では第三のパート「スパースコンパイラがLLM推論に与える影響」を検討します。
私たちは、いくつかの要件を満たす方法が存在するかどうかを探求してきました。それは、モデルの再トレーニングを必要とせず、微調整のみで(低いモデル移行コスト)、モデル性能を維持し(有効性が高い)、現代のハードウェア(GPU/CPU)で十分にサポートされ、GPU計算とI/Oを大幅に削減してレイテンシを最適化する(高速な推論速度)方法です。
実際、そのような方法は存在し、活性化スパース性はこれらの要件をすべて満たすものの一つです。
注目すべきは、ニューラルネットワークでReLU活性化関数を使用すると活性化スパース性が誘発されることが知られており、過去のさまざまな研究で採用されてきました。全層にわたるこの活性化スパース性は、平均してGPUとCPU間の重み転送(I/O)を大幅に節約し、プロジェクション層の重みの約95%の行に影響を与えます。この削減は直接計算量の節約につながります。なぜなら、これらの行に関する行列乗算演算の結果はゼロになるからです。
さらに、非構造化スパース性(例:非構造化重みスパース性)とは異なり、このタイプのスパース性は、より広範囲で構造化されたブロック(行や列など)をゼロにするため、ハードウェアにより適しています。
同様に、下の図を参照して、推論の高速化における活性化スパース性の有効性を簡単に示します。
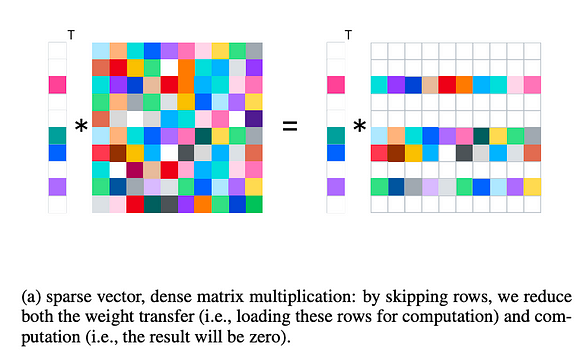
活性化スパース性の場合、推論時にはスパースベクトルと密行列の乗算が実行され、トレーニング時にはスパース行列と密行列の乗算に調整されます。
- 計算負荷の低減:この半構造化スパース性(重み枝刈りの非構造化スパース性とは異なる)により、特定の行をスキップでき、計算が削減されます。例えば、cusparseなどのライブラリはすでに対応する演算をサポートしています。
- IO転送の削減:推論時、GPU I/Oがボトルネックになります(例:GPUキャッシュからCPUキャッシュへ、またはGPU DRAMからGPUキャッシュへ)。この方法では不要な行をスキップできるため、I/Oが削減されます。
活性化スパース性の実現可能性
以下の内容は主に文献 [5] のデータを参照し、LLMにReLU活性化を導入する実現可能性を示します。
活性化スパースモデルと非活性化スパースモデルの比較
3つのモデル、OPT 6.7B、Llama 7B(SiLU活性化)、Falcon 7B(GELU活性化)のFFN(フィードフォワードネットワーク)を測定・分析した結果、以下の3つの結論が得られました。
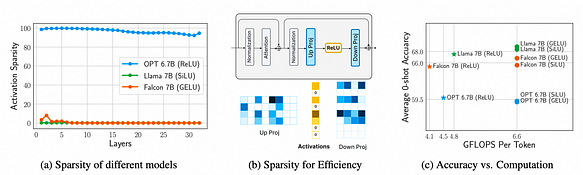
a. Llama 7B(SiLU活性化)、Falcon 7B(GELU活性化)、OPT 6.7B(ReLU活性化)の比較から、ReLUは90%以上の活性化スパース性を誘発するのに対し、SiLUとGELUは10%未満の活性化スパース性しか誘発せず、ReLUがスパースな活性化を誘発できることが示されています。
b. 活性化スパース性は、重み伝送(I/O)の大幅な節約につながり、下流のプロジェクション層の重みの行の約95%に影響を与えます。
c. 活性化関数の選択は精度に大きな影響を与えません。GELU、SiLU、ReLUは同程度の精度だからです。しかし、ReLUは計算負荷(FLOPS)を32%節約できます。
トレーニングコストの削減
多くの現代のLLM(LlamaやFalconなど)は非ReLU活性化を使用してトレーニングされています。スクラッチからのトレーニングは費用対効果が良くないため、微調整によってReLU活性化を実装することを検討する必要があります。モデルは以下の2段階で微調整されます。
- 第1段階:既存のReLU活性化(OPTの場合)を保持するか、アッププロジェクション層とダウンプロジェクション層の間の活性化関数をReLUに置き換えます(FalconとLlamaの場合、GELUとSiLUが使用されています)。
- 第2段階:正規化層の後に新しいReLU活性化を挿入します。
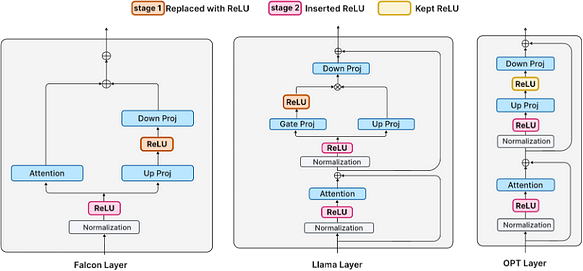
第1段階 — 非ReLU活性化の置き換え
FFN層の非ReLU活性化をReLUに置き換えます。FalconとLlamaモデルの場合、それぞれGELUとSiLUを置き換えることになります。OPTモデルはすでにReLU活性化を使用しているため、変更は行われないことに注意してください。30BトークンのRefinedWebで微調整した後、モデルは活性化に顕著なスパース性を示します。

第2段階 — 新しいReLUの挿入
前の段階では、非ReLU活性化を置き換えてより多くのスパース性を獲得しました。その結果、ダウンプロジェクション層への入力がスパースになり、総計算コストの約30%を占めました。しかし、ダウンプロジェクション以外にも、トランスフォーマーのデコード層には他の行列ベクトル乗算があります。例えば、FFN層のアッププロジェクションやアテンション層のQKVプロジェクションなどです。これらすべての行列ベクトル乗算を合わせると、総計算コストの約55%を消費します。
現代のTransformer層では、アテンション層とFFN層への入力はどちらも正規化層(LayerNormやRMSNormなど)からのものです。これらの層は、任意の学習可能パラメータを適用せず、入力をスケーリングすることを学習するMLPの特定の形式と見なすことができます。したがって、正規化層の後にReLUを適用してスパースな活性化を取得し、第2段階の目標を達成します。
測定結果
微調整のコスト:第1段階と第2段階でそれぞれ30Bトークンと50Bトークンで微調整が完了しました。Llamaのトレーニングコストである1Tトークンと比較すると、コストはわずか約3〜5%でした。
有効性:LlamaとFalconの微調整後の推論レイテンシを比較すると、モデル性能の低下は見られませんでした。しかし、推論速度は30%以上大幅に向上しました。
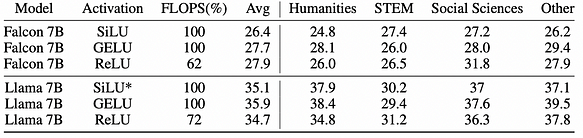
全体として、微調整による活性化スパース性の達成は、さまざまな段階と速度で推論FLOPSを削減し、さまざまなタスクで同等のパフォーマンスを維持できることが結果から確認されました。対応するスパース活性化モデルは、プロジェクトで入手できます:https://huggingface.co/SparseLLM。
推論を高速化する方法
参照論文 [1] で概説されているDejaVuのコンテキストスパース性予測は、優れたアプローチです。
構造化スパース性を活用して高速化する方法
コンテキストスパース性は、事前学習済みモデルがコンテキストスパース性を示すことを前提としています。つまり、AttentionとMLPのスパース化計算が完全計算と同じ効果を達成するということです。この前提のもと、構造化スパースモデルで平均85%のコンテキストスパース性が得られれば、特定の入力ごとにパラメータを7分の1に削減しつつ精度を維持でき、推論性能を大幅に向上させることができます。
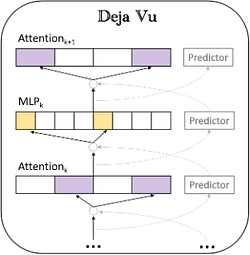
上の図に示すように、コンテキストスパース性に基づいて非同期スパース予測器が設計され、次の層のAttentionとMLPのスパース性を事前に予測します。このアプローチは推論効率を確保するだけでなく、計算とI/Oのオーバーヘッドを大幅に削減します。
コンテキストスパース性の存在の検証
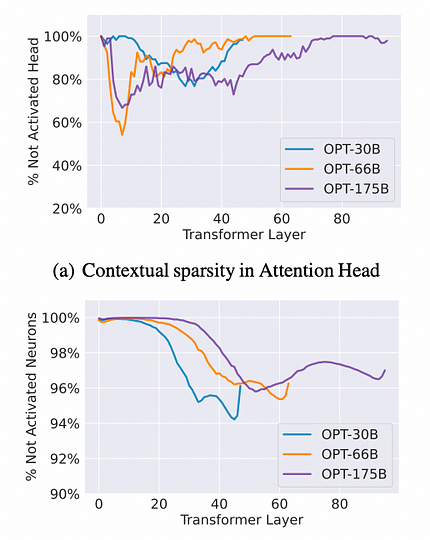
OPT-175B、66B、30Bモデルで、OpenBookQAやWiki-Textなどのさまざまなダウンストリームデータセットを用いてテストが行われました。方法は、モデルを2回フォワードパスして、各入力例のコンテキストスパース性を特定するというものです。1回目のパスでは、パラメータのサブセット、特に大きな出力ノルムを生成するAttentionヘッドとMLPニューロンに関連するものを記録しました。2回目のパスでは、各入力例を記録されたパラメータサブセットのみを使用して計算しました。驚くべきことに、両方のフォワードパスは、すべてのコンテキスト学習および言語モデリングタスクにおいて、同様の予測またはパフォーマンスを示しました。
観察結果:平均して、Attentionヘッドは最大80%のスパース性を課すことができ、MLPニューロンは最大95%のスパース性を達成でき、全体的なスパース性は約85%となり、7倍の高速化につながります。具体的な参考データは下図を参照してください。
エンジニアリングへの影響
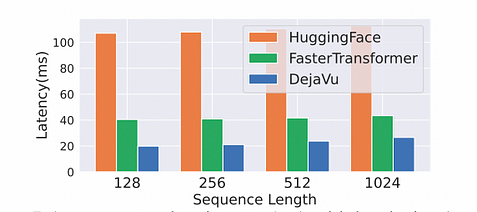
高速化効果:GPUはブロック指向のデバイスであるため、1バイトのメモリをロードするのに必要な時間は、同じアドレス周辺のメモリブロックをロードするのと同じです。NVIDIA GPUのブロックサイズは通常128バイトです。そのため、メモリ融合やオペレーター融合などの最適化が行われました。batch_size=1の前提で、FasterTransformerと比較して、速度は2倍になりました。
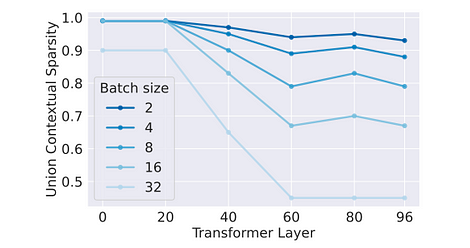
スループットへの影響:活性化は各トークンの関数であるため、有効なスパース性もトークン間でランダムに分布します。したがって、スパース最適化の効果はバッチサイズが大きくなるにつれて指数関数的に減少します。これは論文のアブレーション実験で参照できます。
推論閾値の低減
現在の部分オフロード手法とDejaVu手法を整理したものを以下の表に示します。
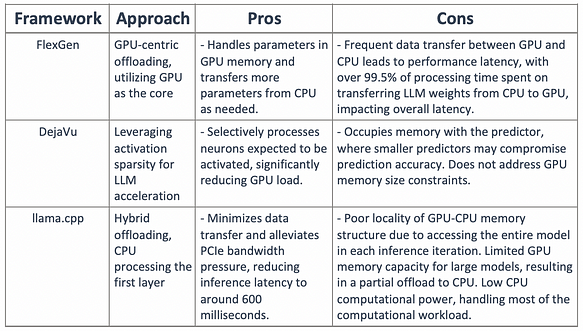
活性化スパース性とオフロード手法を組み合わせて、GPU-CPUハイブリッド推論エンジンを設計できるでしょうか。つまり、ホットな活性化ニューロンをGPUにプリロードして高速アクセスを実現し、コールドな活性化ニューロンはCPUで計算することで、GPUメモリ要件とCPU-GPUデータ転送を大幅に削減するというものです。
答えはもちろん「YES」です。
そのようなソリューションの一つがPowerInfer[10]で、OPT-175Bを単一のNVIDIA RTX 4090 GPUで実行でき、トークン生成速度はトップクラスのA100 GPUサーバーと比較してわずか18%低いだけです。オフロードと活性化スパース性に加えて、Brainstorm[9]、SparTA[15]、Flash-llm[16]などの他の側面も参考になります。
概要:
PowerInferは、頻繁に活性化されるニューロンの重みをGPUにプリロードし、活性化の少ないニューロンの重みはCPUに保持します。
推論レイテンシを削減するために、推論エンジンはオンライン予測器によって活性化されると予測されたニューロンのみを計算し、ほとんどの非アクティブなニューロンをスキップします。さらに、プリロード戦略により、GPUにロードされたホットな活性化ニューロンが活性化の大部分を占めるため、PowerInferは推論タスクの大部分をGPUに割り当てることができます。GPUメモリにないコールドな活性化ニューロンの場合、PowerInferはCPUで計算を実行し、重みをGPUに転送する必要がありません。
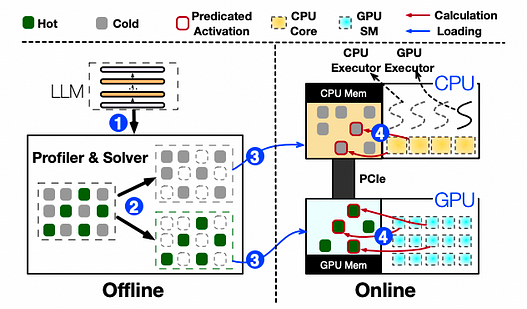
PowerInferのアーキテクチャ概要と推論ワークフロー
PowerInferはオフラインコンポーネントとオンラインコンポーネントで構成されています。LLM間で局所性特性が異なるため、オフラインコンポーネントはLLMの活性化スパース性を分析し、ホットニューロンとコールドニューロンを区別します。オンラインフェーズでは、推論エンジンが両方のタイプのニューロンをGPUとCPUにロードし、実行時に低レイテンシでLLMリクエストを処理します。ユーザーリクエストを処理する前に、オンラインエンジンはオフラインソルバーの出力に基づいて、2種類のニューロンをそれぞれの処理ユニットに割り当てます。実行時には、エンジンはGPUエグゼキュータとCPUエグゼキュータ(CPU側で実行されるスレッド)を作成し、CPU-GPU計算の同時実行を管理します。また、エンジンはニューロンの活性化を予測し、非アクティブなニューロンをスキップします。活性化されたニューロンはGPUメモリにプリロードされて処理され、CPUは自身のニューロンの結果を計算し、統合のためにGPUに転送します。エンジンはCPUとGPUの両方でスパースニューロン認識オペレーターを使用し、行列内の個々のニューロンの行/列に焦点を当てます。
プロジェクトリンク:https://github.com/SJTU-IPADS/PowerInfer
単一層の計算最適化
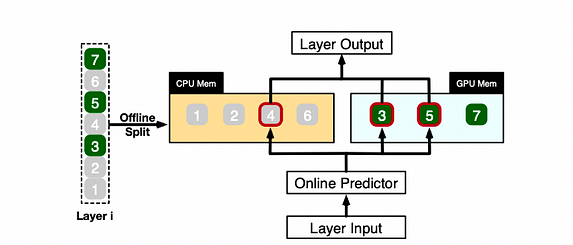
PowerInferが1つのLLM層に対して異なるニューロンをどのように計算するかを示す実例
PowerInferは、オフラインデータに基づいてニューロンを分類し、ホットニューロン(例:インデックス3、5、7)をGPUメモリに割り当て、その他のニューロンをCPUメモリに割り当てることで、GPUとCPUを調整して1つの層内のニューロンを処理します。
入力を受信すると、予測器は現在の層のどのニューロンが活性化される可能性が高いかを特定します。例えば、ニューロン3、4、5の活性化を予測します。オフラインの統計分析によって特定されたホットニューロンは、実行時の活性化動作と常に一致するとは限らないことに注意してください。例えば、ニューロン7はホットとしてマークされていますが、特定のシナリオでは非アクティブになる可能性があります。
その後、CPUとGPUの両方が予測されたアクティブニューロンを処理し、非アクティブなニューロンは無視します。GPUはニューロン3と5を計算し、CPUはニューロン4を処理します。ニューロン4の計算が完了すると、その出力は結果統合のためにGPUに送信されます。
オンライン推論(ニューロン認識推論エンジン)
- 適応型スパース予測器
PowerInferのオンライン推論エンジンは、活性化されると予測されたニューロンのみを処理することで計算負荷を削減します。このアプローチはDejaVuでも使用されており、固定サイズのMLP予測器のセットをトレーニングすることを推奨しています。各Transformer層で、DejaVuは2つの独立した予測器を活用して、セルフアテンションとMLPブロックのニューロンの活性化を予測します。
しかし、リソースが限られたローカルデプロイメント向けに効果的な予測器を設計するには、予測精度とモデルサイズのバランスを取る必要があるため、課題があります。
PowerInferは、各Transformer層に対して非固定サイズの予測器の反復トレーニング手法を採用しています。このプロセスでは、まず層のスパース性プロファイルに基づいてベースラインモデルサイズを確立します。次に、内部活性化の偏りを考慮して、モデルサイズを反復的に調整し、精度を維持します。MLP予測器は通常、入力層、隠れ層、出力層で構成されます。入力層と出力層のサイズはTransformer層の構造によって決まるため、変更は主に隠れ層を対象とします。反復調整プロセスでは、観測された歪度に基づいて隠れ層のサイズが変更されます。大きな歪度を示す層では、精度が95%を下回るまで隠れ層のサイズを徐々に減らします。逆に、歪度が最小の層では、精度を向上させるために次元を増やします。このアプローチにより、PowerInferは予測器のパラメータをLLM全体のパラメータの10%以内に効果的に制限します。
- GPU-CPUハイブリッド実行
推論の前に、PowerInferは計算有向非巡回グラフ(DAG)を構築します。各ノードは計算LLM推論オペレーターを表し、CPUメモリ内のグローバルキューに格納します。キュー内の各オペレーターには、その必要なオペレーターのラベルが付けられます。推論中、2種類のエグゼキュータ(ホストOSのpthreadによって作成)がCPUとGPUでの計算を管理します。それらはグローバルキューからオペレーターを抽出し、依存関係をチェックし、適切な処理ユニットに割り当てます。GPUとCPUはそれぞれのニューロン認識オペレーターを使用し、GPUエグゼキュータはcudaLaunchKernelなどのAPIを使用してGPUオペレーターを起動します。一方、CPUエグゼキュータは未使用のCPUコアを調整して計算を行います。
実験結果
パフォーマンス比較
FP16フォーマットのPC-Highでのさまざまなモデルの高速化率。X軸は出力長、Y軸はllama.cppと比較した高速化率を示します。各棒の上の数値はエンドツーエンドの生成速度(トークン/秒)です。グラフの最初の行に設定された入力長は約64、2行目は約128です。
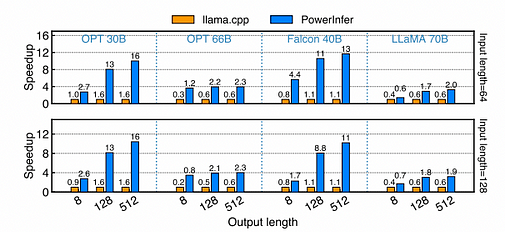
NVIDIA RTX 4090を搭載したPC-Highでは、さまざまなモデルと入出力構成で異なる生成速度を示します。平均して、PowerInferは8.32トークン/秒の生成速度を達成し、ピークは16.0トークン/秒であり、llama.cppよりも大幅に優れており、平均高速化率は7.23倍、Falcon-40Bでは最大11.69倍に達します。出力トークン数が増えるにつれて、PowerInferのパフォーマンス上の利点はより顕著になります。これは、生成フェーズが全推論時間においてより重要な役割を果たすためです。この段階では、CPUとGPUの両方で少数のニューロンが活性化され、llama.cppと比較して不要な計算が削減されます。例えば、OPT-30Bの場合、生成トークンごとに約20%のニューロンのみが活性化され、その大部分がGPUで処理され、PowerInferのニューロン認識推論エンジンの利点を示しています。
バッチサイズの影響:
バッチサイズが32未満の場合、PowerInferは顕著な優位性を示し、llama.cppと比較して平均6.08倍の改善を示します。バッチサイズが増加するにつれて、PowerInferが提供する高速化率は低下します。この減少は、モデル内の結合活性化のスパース性が低下することに起因します。ただし、バッチサイズを32に設定した場合でも、PowerInferは依然としてかなりの高速化率(4.38倍の改善)を維持します。
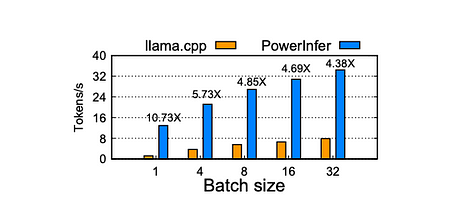
PC-HighでのFalcon-40Bのバッチ推論高速化。X軸はリクエストバッチサイズ、Y軸はエンドツーエンドのトークン生成速度(トークン/秒)を示します。各棒の上の数値は、llama.cppと比較した高速化率を示します。
負荷比較
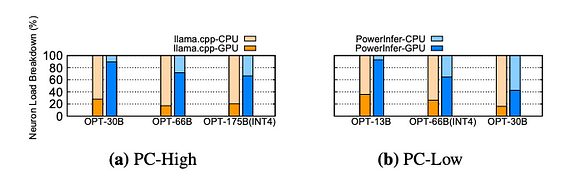
推論中のCPUとGPUにおけるニューロン負荷の分布。黄色のブロックはllama.cpp、青色のブロックはPowerInferを示します。
PowerInferとllama.cppにおけるCPUとGPU間のニューロン負荷の分布を比較します。ニューロン負荷とは、各処理ユニットによって実行される活性化ニューロン計算の割合を指します。PC-Highシステムでは、PowerInferはGPU上のニューロン負荷の割合を平均20%から70%に大幅に増加させていることに注目してください。これは、GPUが活性化ニューロンの70%を処理していることを示しています。ただし、モデルのメモリ要件がGPUの容量を大幅に超える場合(例えば、60GBモデルを11GBの2080Ti GPUで実行する場合)、GPU上のニューロン負荷は42%に低下します。この減少は、GPUのメモリが限られており、すべてのホット活性化ニューロンを収容できないため、これらのニューロンの一部をCPUで計算する必要があるためです。
長い入力プロンプトと比較的短い出力長を伴うシナリオでは、PowerInferは限られたパフォーマンス向上しか示しません。そのような場合、大量のトークンを同時に処理する段階が推論速度を決定する重要な要素になります。その結果、各トークンが一意のニューロンセットを活性化し、活性化スパース性が大幅に低下します。その結果、CPUは推論プロセスにおける主要なボトルネックとなり、大量のコールド活性化ニューロンを処理する必要があるものの、計算能力によって制約されます。
結論
活性化スパース性技術は、大規模言語モデルに革命的な進歩をもたらしました。ニューラルネットワークの活性化をスパース化して推論プロセスを高速化し、GPU計算とI/O負荷を削減することで、推論速度とパフォーマンスを向上させます。このアプローチは再トレーニングを必要とせず、微調整のみで活性化スパース性を実現するため、コストを大幅に削減しながらモデルパフォーマンスを維持します。活性化スパース性技術の応用展望は非常に魅力的であり、深層学習の分野にさらなる可能性をもたらします。この技術のさらなる発展と広範な応用を期待しています。
参考論文
[5]ReLU Strikes Back:Exploiting Activation Sparsity in Large Language Models
[7]Inducing and exploiting activation sparsity for fast inference on deep neural networks
[8]Sparse is enough in scaling transformers
novita.ai は、Stable Diffusion APIと、10,000モデル向けの数百の高速かつ最も安価なAI画像生成APIを提供しています。🎯 最速生成はわずか2秒、従量課金制、標準画像1枚あたり最低$0.0015、独自モデルの追加が可能でGPUメンテナンスは不要。オープンソースの拡張機能を自由に共有できます。
おすすめの記事



