

Методы разреженности для 100-кратного ускорения инференса больших языковых моделей. Откройте магию разреженности активаций: никакого переобучения, низкая стоимость и высокая эффективность, ведущие к значительному увеличению скорости инференса на GPU!
В предыдущем обсуждении «Как LLM ускоряет инференс с помощью разреженности» мы рассмотрели первую часть: «[Как большие модели подвергаются прунингу (Unveiling LLM-Pruner Techniques: Doubling Inference Speed)](Unveiling LLM-Pruner Techniques: Doubling Inference Speed)». На этот раз мы продолжаем углубляться во вторую часть: «Как ускорить инференс с помощью разреженности активаций», а в следующем обсуждении рассмотрим третью часть: «Влияние разрежающих компиляторов на инференс LLM».
Мы всё время искали, существует ли метод, который удовлетворяет нескольким требованиям: не требует переобучения модели, а только дообучения (низкая стоимость переноса модели), сохраняет производительность модели (хорошая эффективность), хорошо поддерживается современным оборудованием (GPU/CPU) и значительно сокращает вычисления на GPU и операции ввода-вывода для оптимизации задержки (высокая скорость инференса).
Действительно, такой метод существует, и разреженность активаций — один из тех, что удовлетворяет всем этим требованиям.
Стоит отметить, что использование функций активации ReLU в нейронных сетях, как известно, вызывает разреженность активаций и было применено в различных предыдущих работах. В среднем эта разреженность активаций по всем слоям приводит к значительной экономии при передаче весов (I/O) между GPU и CPU, затрагивая примерно 95% строк весов проекционного слоя. Это сокращение напрямую преобразуется в экономию вычислений, так как результаты операций умножения матриц для этих строк будут равны нулю.
Более того, в отличие от неструктурированной разреженности (например, неструктурированной разреженности весов), этот тип разреженности более дружественен к оборудованию благодаря обнулению более крупных и структурированных блоков (таких как строки или столбцы).
Аналогично, обращаясь к рисунку ниже, мы кратко иллюстрируем эффективность разреженности активаций в ускорении инференса.
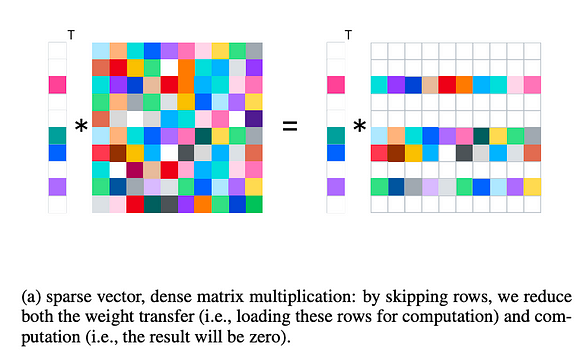
В случае разреженности активаций во время инференса выполняется умножение разреженного вектора на плотную матрицу, а во время обучения оно заменяется на умножение разреженной матрицы на плотную матрицу.
- Снижение вычислительной нагрузки: эта полуструктурированная разреженность (в отличие от неструктурированной разреженности при прунинге весов) позволяет пропускать некоторые строки, уменьшая объём вычислений. Например, библиотеки типа cusparse уже поддерживают соответствующие операции.
- Уменьшение передачи I/O: во время инференса узким местом является ввод-вывод GPU (например, из кэша GPU в кэш CPU или из DRAM GPU в кэш GPU). Этот метод позволяет пропускать ненужные строки, тем самым уменьшая I/O.
Осуществимость разреженности активаций
Следующее содержание в основном опирается на данные из [5] для демонстрации возможности применения активации ReLU в LLM.
Сравнение моделей с разреженностью активаций и без неё
Путём измерения и анализа FFN (сеть прямой связи) трёх моделей: OPT 6.7B, Llama 7B (с активацией SiLU) и Falcon 7B (с активацией GELU), были сделаны следующие три вывода:
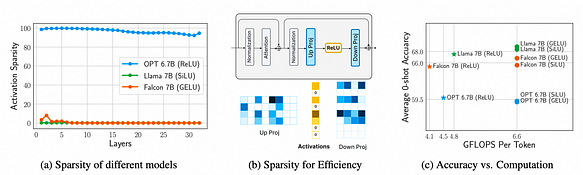
a. Сравнение Llama 7B (SiLU), Falcon 7B (GELU) и OPT 6.7B (ReLU) показывает, что ReLU вызывает более 90% разреженности активаций, тогда как SiLU и GELU — менее 10%, что демонстрирует способность ReLU создавать разреженные активации.
b. Разреженность активаций приводит к значительной экономии при передаче весов (I/O), затрагивая примерно 95% строк весов последующего проекционного слоя.
c. Выбор функции активации существенно не влияет на точность, так как GELU, SiLU и ReLU находятся на одном уровне точности. Однако ReLU позволяет сэкономить 32% вычислительной нагрузки (FLOPS).
Снижение затрат на обучение
Многие современные LLM (такие как Llama и Falcon) были обучены с использованием не-ReLU активаций. Обучение с нуля нецелесообразно; поэтому необходимо рассмотреть реализацию активации ReLU путём дообучения. Модель дообучается в два этапа:
- На первом этапе сохраняются существующие активации ReLU (в случае OPT) или функция активации между up-projection и down-projection слоями заменяется на ReLU (в случае Falcon и Llama, где используются GELU и SiLU).
- На втором этапе новые активации ReLU вставляются после слоёв нормализации.
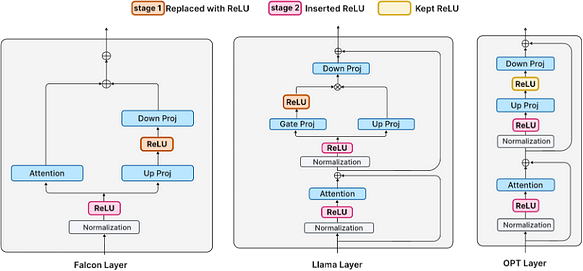
Первый этап — замена не-ReLU активаций
Замена не-ReLU активаций на ReLU в слоях FFN. Для моделей Falcon и Llama это означает замену GELU и SiLU соответственно. Отмечается, что поскольку модель OPT уже использует активации ReLU, изменения не вносятся. После дообучения на 30B токенах RefinedWeb модель демонстрирует значительную разреженность активаций.

Второй этап — вставка новых ReLU
На предыдущем этапе мы заменили не-ReLU активации для достижения большей разреженности. Это привело к разреженным входам для down-projection слоя, составляющим примерно 30% от общей вычислительной стоимости. Однако, помимо down-projection, в слоях декодера трансформера есть и другие умножения матрицы на вектор, такие как up-projection в слое FFN и QKV проекция в слое внимания. В совокупности эти умножения матрицы на вектор потребляют около 55% от общей вычислительной стоимости.
В современных слоях трансформера входы слоёв внимания и FFN поступают из слоёв нормализации, таких как LayerNorm или RMSNorm. Эти слои можно рассматривать как частную форму MLP, где они не применяют произвольные обучаемые параметры, а обучаются масштабировать вход. Поэтому мы применяем ReLU для получения разреженных активаций после слоёв нормализации, достигая цели второго этапа.
Результаты измерений
Стоимость дообучения: дообучение было завершено на 30B и 50B токенах на первом и втором этапах соответственно. По сравнению с затратами на обучение Llama в 1T токенов, стоимость составила всего около 3–5%.
Эффективность: сравнение задержки инференса после дообучения для Llama и Falcon не показало заметного снижения производительности модели. Однако наблюдалось значительное улучшение скорости инференса более чем на 30%.
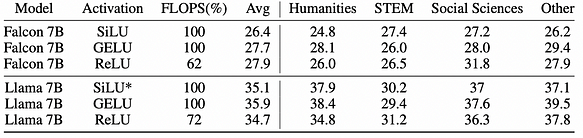
В целом результаты подтверждают, что достижение разреженности активаций путём дообучения может уменьшить FLOPS инференса на различных этапах и скоростях, сохраняя при этом сравнимую производительность на разных задачах. Соответствующие модели с разреженными активациями можно найти в проекте: https://huggingface.co/SparseLLM.
Как ускорить инференс
Прогнозирование контекстной разреженности DejaVu, описанное в ссылочной статье [1], является отличным подходом.
Как полностью использовать структурированную разреженность для ускорения
Контекстная разреженность предполагает, что предобученные модели демонстрируют контекстную разреженность, то есть разреженные вычисления для Attention и MLP дают тот же эффект, что и полные вычисления. Исходя из этого, средняя контекстная разреженность в 85% в структурированных разреженных моделях может привести к семикратному сокращению параметров для каждого конкретного входа при сохранении точности, тем самым значительно улучшая производительность инференса.
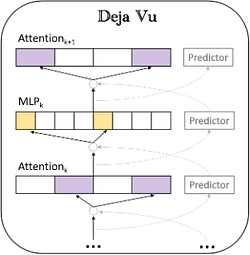
Как показано на рисунке выше, на основе контекстной разреженности разрабатывается асинхронный разреженный предиктор, который заранее предсказывает разреженность следующего слоя Attention и MLP. Этот подход не только обеспечивает эффективность инференса, но и значительно снижает вычислительную нагрузку и I/O.
Подтверждение существования контекстной разреженности
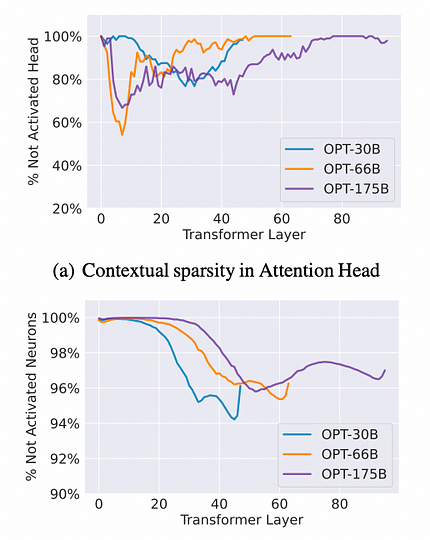
Тестирование проводилось на моделях OPT-175B, 66B и 30B с различными downstream наборами данных, такими как OpenBookQA и Wiki-Text. Метод включал два прямых прохода модели для определения контекстной разреженности для каждого входного примера. В первом проходе записывалось подмножество параметров, особенно тех, которые связаны с головами внимания и нейронами MLP, генерирующими большие нормы выходов для входов. Во втором проходе каждый входной пример вычислялся с использованием только записанного подмножества параметров. Удивительно, но оба прямых прохода дали схожие предсказания или производительность во всех задачах контекстного обучения и языкового моделирования.
Результаты наблюдений: в среднем головы внимания могут накладывать разреженность до 80%, а нейроны MLP — до 95%, что даёт общую разреженность около 85%, что может привести к семикратному ускорению. Для конкретных справочных данных смотрите рисунок ниже.
Инженерное влияние
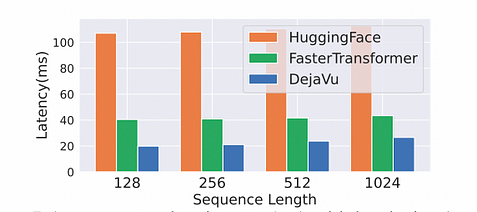
Эффект ускорения: поскольку GPU являются блочно-ориентированными устройствами, время, необходимое для загрузки одного байта памяти, такое же, как и для загрузки блока памяти вокруг того же адреса. Размер блока GPU NVIDIA обычно составляет 128 байт. Поэтому были выполнены оптимизации, такие как слияние памяти и слияние операторов. При условии batch_size=1 по сравнению с FasterTransformer ускорение достигло двукратного эффекта, т.е. улучшение скорости в 2 раза.
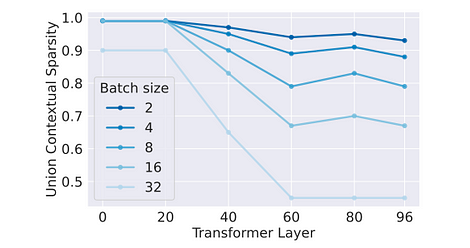
Влияние на пропускную способность: поскольку активации являются функциями каждого токена, эффективная разреженность также случайным образом распределяется по токенам. Поэтому эффективность разреженной оптимизации экспоненциально убывает с увеличением размера батча. Это можно посмотреть в абляционных экспериментах, проведённых в статье.
Снижение порога инференса
Организация текущих методов частичной выгрузки (offloading) и метода DejaVu представлена в таблице ниже:
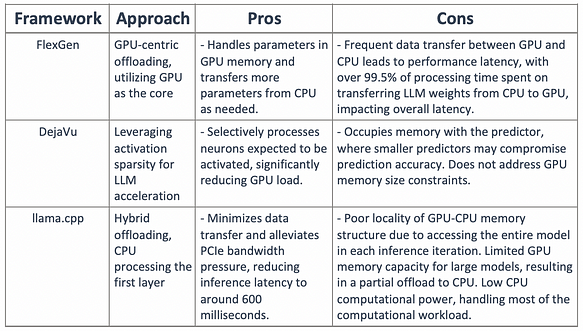
Можно ли объединить разреженность активаций и методы выгрузки, чтобы спроектировать гибридный движок инференса GPU-CPU: где горячие активированные нейроны предварительно загружаются на GPU для быстрого доступа, а холодные активированные нейроны вычисляются на CPU, значительно снижая требования к памяти GPU и передаче данных CPU-GPU?
Ответ, естественно, «ДА».
Одним из таких решений является PowerInfer[10], который может запускать OPT-175B на одном NVIDIA RTX 4090, достигая скорости генерации токенов всего на 18% ниже, чем топовые серверы A100 GPU. Помимо выгрузки и разреженности активаций, другие аспекты, такие как Brainstorm[9], SparTA[15] и Flash-llm[16], также представляют интерес.
Обзор:
PowerInfer предварительно загружает веса на GPU для часто активируемых нейронов, в то время как веса для менее активных нейронов остаются на CPU.
Для уменьшения задержки инференса движок вычисляет только нейроны, предсказанные онлайн-предиктором как активные, пропуская большинство неактивных нейронов. Кроме того, стратегия предварительной загрузки позволяет PowerInfer выделять значительную часть задач инференса на GPU, так как загруженные на GPU горячие нейроны составляют большинство активаций. Для холодных нейронов, отсутствующих в памяти GPU, PowerInfer выполняет вычисления на CPU, устраняя необходимость передачи весов на GPU.
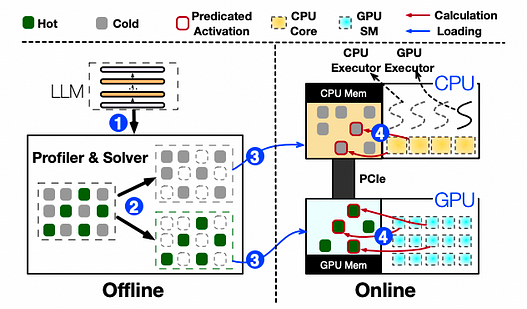
Обзор архитектуры и рабочий процесс инференса PowerInfer
PowerInfer состоит из офлайн- и онлайн-компонентов. Из-за различий в свойствах локальности среди разных LLM офлайн-компонент анализирует разреженность активаций LLM, различая горячие и холодные нейроны. В онлайн-фазе движок инференса загружает оба типа нейронов в GPU и CPU и обслуживает запросы LLM с низкой задержкой во время выполнения. Перед обработкой пользовательских запросов онлайн-движок назначает два типа нейронов своим соответствующим обрабатывающим блокам на основе выходных данных офлайн-решателя. Во время выполнения движок создаёт исполнители GPU и CPU, которые являются потоками, работающими на стороне CPU, для управления одновременными вычислениями CPU-GPU. Движок также предсказывает активации нейронов и пропускает неактивные нейроны. Активированные нейроны предварительно загружаются в память GPU для обработки, в то время как CPU вычисляет результаты для своих нейронов и передаёт их на GPU для интеграции. Движок использует разреженные операторы, учитывающие нейроны, как на CPU, так и на GPU, фокусируясь на отдельных строках/столбцах нейронов в матрицах.
Ссылка на проект: https://github.com/SJTU-IPADS/PowerInfer
Оптимизация вычислений одного слоя
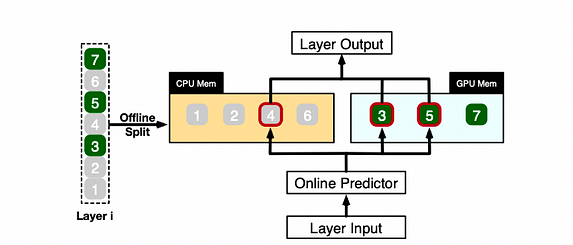
Иллюстративный пример показывает, как PowerInfer вычисляет разные нейроны для одного слоя LLM
PowerInfer координирует работу GPU и CPU для обработки нейронов в слое, классифицируя нейроны на основе офлайн-данных: назначая горячие нейроны (например, индексы 3, 5, 7) в память GPU, а остальные нейроны — в память CPU.
Получив вход, предиктор определяет, какие нейроны в текущем слое, вероятно, будут активированы. Например, он предсказывает активацию нейронов 3, 4 и 5. Стоит отметить, что горячие нейроны, выявленные путём офлайн-статистического анализа, не всегда могут совпадать с поведением активации во время выполнения. Например, нейрон 7, хотя и помечен как горячий, может быть неактивен в данном сценарии.
Затем и CPU, и GPU обрабатывают предсказанные активные нейроны, игнорируя неактивные. GPU вычисляет нейроны 3 и 5, а CPU обрабатывает нейрон 4. После завершения вычисления нейрона 4 его выход отправляется на GPU для интеграции результатов.
Онлайн-инференс (движок инференса, учитывающий нейроны)
- Адаптивный разреженный предиктор
Онлайн-движок инференса в PowerInfer сокращает вычислительную нагрузку, обрабатывая только нейроны, предсказанные как активированные. Этот подход также используется в DejaVu, который предлагает обучать фиксированный набор MLP-предикторов. В каждом слое трансформера DejaVu использует два независимых предиктора для прогнозирования активации нейронов в блоках самовнимания и MLP.
Однако разработка эффективных предикторов для локального развёртывания с ограниченными ресурсами создаёт проблемы, требуя баланса между точностью предсказаний и размером модели.
PowerInfer использует итеративный метод обучения для предикторов нефиксированного размера для каждого слоя трансформера. Этот процесс сначала устанавливает базовый размер модели на основе профиля разреженности слоя. Затем, учитывая внутреннюю асимметрию активаций, размер модели итеративно корректируется для поддержания точности. MLP-предикторы обычно состоят из входного, скрытого и выходного слоёв. Поскольку размеры входного и выходного слоёв определяются структурой слоя трансформера, модификации в первую очередь касаются скрытого слоя. В процессе итеративной настройки размер скрытого слоя изменяется на основе наблюдаемой асимметрии. Для слоёв, демонстрирующих значительную асимметрию, размер скрытого слоя постепенно уменьшается, пока точность не упадёт ниже 95%. И наоборот, для слоёв с минимальной асимметрией размеры увеличиваются для повышения точности. Благодаря такому подходу PowerInfer эффективно ограничивает параметры предиктора 10% от общего числа параметров LLM.
- Гибридное выполнение GPU-CPU
Перед инференсом PowerInfer строит вычислительный ориентированный ациклический граф (DAG), где каждый узел представляет оператор вычисления LLM, и сохраняет его в глобальной очереди в памяти CPU. Каждый оператор в очереди помечен необходимыми ему операторами. Во время инференса два типа исполнителей (создаваемых pthread операционной системы хоста) управляют вычислениями на CPU и GPU. Они извлекают операторы из глобальной очереди, проверяют зависимости и назначают их соответствующим обрабатывающим блокам. GPU и CPU используют свои операторы, учитывающие нейроны: исполнитель GPU запускает операторы GPU с помощью API, таких как cudaLaunchKernel, в то время как исполнитель CPU координирует неиспользуемые ядра CPU для вычислений.
Экспериментальное заключение
Сравнение производительности
Ускорение различных моделей в формате FP16 на ПК-High. Ось X представляет длину выхода, ось Y — коэффициент ускорения по сравнению с llama.cpp. Число над каждым столбцом обозначает сквозную скорость генерации (токенов/с). Длина входа, настроенная для первой строки на графике, составляет примерно 64, для второй строки — около 128.
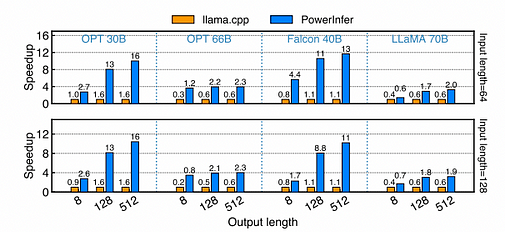
На ПК-High с NVIDIA RTX 4090 различные модели и конфигурации ввода-вывода демонстрируют разную скорость генерации. В среднем PowerInfer достигает скорости генерации 8,32 токенов/с, с пиком 16,0 токенов/с, что значительно превосходит llama.ccpp со средним ускорением в 7,23 раза, при этом Falcon-40B достигает 11,69 раза. С увеличением количества выходных токенов преимущество в производительности PowerInfer становится более заметным, так как этап генерации играет более важную роль в общем времени инференса. На этом этапе на CPU и GPU активируется небольшое количество нейронов, что уменьшает ненужные вычисления по сравнению с llama.cpp. Например, в случае OPT-30B на каждый сгенерированный токен активируется только около 20% нейронов, при этом большинство обрабатывается на GPU, что демонстрирует преимущество учитывающего нейроны движка инференса PowerInfer.
Влияние размера батча
Когда размер батча меньше 32, PowerInfer демонстрирует значительное преимущество, в среднем улучшение в 6,08 раза по сравнению с llama.cpp. С увеличением размера батча коэффициент ускорения, обеспечиваемый PowerInfer, снижается. Это снижение объясняется уменьшением разреженности совместных активаций в модели. Однако даже при размере батча 32 PowerInfer сохраняет значительный коэффициент ускорения, достигая улучшения в 4,38 раза.
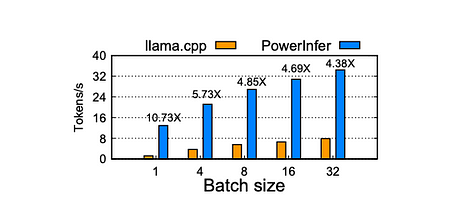
Ускорение пакетного инференса Falcon-40B на ПК-High. Ось X — размер батча запросов, ось Y — сквозная скорость генерации токенов (токенов/с). Число над каждым столбцом показывает ускорение по сравнению с llama.cpp.
Сравнение нагрузки
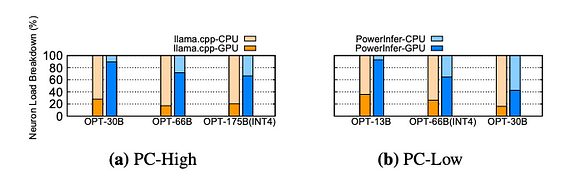
Распределение нагрузки нейронов на CPU и GPU во время инференса. Жёлтый блок — llama.cpp, синий — PowerInfer
Сравнивается распределение нагрузки нейронов между CPU и GPU в PowerInfer и llama.cpp. Нагрузка нейронов означает долю вычислений активированных нейронов, выполняемых каждым обрабатывающим блоком. Стоит отметить, что на ПК-High PowerInfer значительно увеличивает долю нагрузки нейронов на GPU, возрастая в среднем с 20% до 70%. Это указывает на то, что GPU обрабатывает 70% активированных нейронов. Однако, когда требования модели к памяти значительно превышают ёмкость GPU, например, при запуске модели объёмом 60 ГБ на GPU 2080Ti с 11 ГБ, нагрузка на GPU снижается до 42%. Это снижение связано с ограниченной памятью GPU, которой недостаточно для размещения всех горячих нейронов, что приводит к необходимости вычисления части этих нейронов на CPU.
В сценариях с более длинными входными промптами и относительно короткой выходной длиной PowerInfer демонстрирует лишь ограниченные улучшения производительности. В таких случаях этап обработки большого количества токенов одновременно становится ключевым фактором, определяющим скорость инференса. Это приводит к тому, что каждый токен активирует уникальный набор нейронов, значительно снижая разреженность активаций. В результате CPU становится основным узким местом в процессе инференса, будучи вынужденным обрабатывать большое количество холодных нейронов, но ограниченным вычислительной мощностью.
Заключение
Технология разреженности активаций принесла революционные прорывы в большие языковые модели. Разреживая активации нейронных сетей для ускорения процесса инференса при одновременном снижении вычислительной нагрузки и операций ввода-вывода на GPU, удаётся улучшить скорость и производительность инференса. Этот подход не требует переобучения и достигает разреженности активаций только путём дообучения, значительно снижая затраты при сохранении производительности модели. Перспективы применения технологии разреженности активаций впечатляют, открывая новые возможности в области глубокого обучения. Мы с нетерпением ждём дальнейшего развития и широкого применения этой технологии.
Ссылочные статьи
[5] ReLU Strikes Back: Exploiting Activation Sparsity in Large Language Models
[7] Inducing and exploiting activation sparsity for fast inference on deep neural networks
[8] Sparse is enough in scaling transformers
novita.ai предоставляет Stable Diffusion API и сотни быстрых и недорогих API для генерации AI-изображений на основе 10 000 моделей. 🎯 Самая быстрая генерация всего за 2 секунды, оплата по мере использования, минимум $0,0015 за каждое стандартное изображение. Вы можете добавлять свои собственные модели и избежать затрат на обслуживание GPU. Бесплатный доступ к open-source расширениям.
Рекомендуемые статьи



