

Técnicas esparsas para aceleração de 100x na inferência de grandes modelos de linguagem. Descubra a magia da esparsidade de ativação: sem retreinamento, baixo custo e alta eficiência, levando a um aumento significativo na velocidade de inferência em GPU!
Na discussão anterior sobre “Como o LLM acelera a inferência através da esparsidade”, exploramos a primeira parte, “[Como grandes modelos fazem poda](Unveiling LLM-Pruner Techniques: Doubling Inference Speed)”. Desta vez, continuamos mergulhando na segunda parte, “Como acelerar a inferência usando esparsidade de ativação”, e na próxima discussão, examinaremos a terceira parte, “O impacto dos compiladores esparsos na inferência de LLM”.
Temos explorado se existe um método que atenda a vários requisitos: não exigir retreinamento do modelo, mas apenas fine-tuning (baixo custo de transferência do modelo), manter o desempenho do modelo (boa eficácia), ter alto suporte de hardware moderno (GPU/CPU) e reduzir significativamente o processamento e I/O da GPU para otimizar a latência (velocidade de inferência rápida).
De fato, tal método existe, e a esparsidade de ativação é um deles que atende a todos esses requisitos.
Vale notar que o uso de funções de ativação ReLU em redes neurais induz esparsidade de ativação e já foi adotado em diversos trabalhos anteriores. Em média, essa esparsidade de ativação em todas as camadas leva a economias significativas na transferência de pesos (I/O) entre GPU e CPU, afetando aproximadamente 95% das linhas dos pesos da camada de projeção. Essa redução se traduz diretamente em economia computacional, pois os resultados das operações de multiplicação de matrizes para essas linhas serão zero.
Além disso, diferentemente da esparsidade não estruturada (por exemplo, esparsidade de peso não estruturada), esse tipo de esparsidade é mais amigável ao hardware por zerar blocos mais extensos e estruturados (como linhas ou colunas).
Da mesma forma, referindo-se à figura abaixo, ilustramos brevemente a eficácia da esparsidade de ativação na aceleração da inferência.
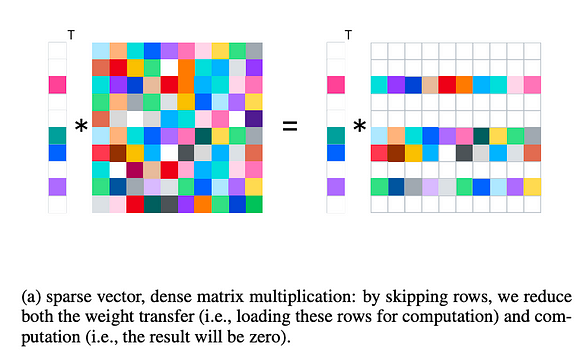
No caso da esparsidade de ativação, a multiplicação de vetor esparso por matriz densa é realizada durante a inferência, enquanto durante o treinamento, ela é ajustada para multiplicação de matriz esparsa por matriz densa.
- Carga de trabalho computacional reduzida: Essa esparsidade semiestruturada (ao contrário da esparsidade não estruturada da poda de pesos) permite pular certas linhas, reduzindo o cálculo. Por exemplo, bibliotecas como cusparse já suportam operações correspondentes.
- Transferência de E/S reduzida: Durante a inferência, a E/S da GPU é um gargalo (por exemplo, do cache da GPU para o cache da CPU ou da DRAM da GPU para o cache da GPU). Este método permite pular linhas desnecessárias, reduzindo assim a E/S.
Viabilidade da Esparsidade de Ativação
O conteúdo a seguir refere-se principalmente a dados de [5] para demonstrar a viabilidade de aplicar ReLU em LLMs.
Comparação entre Modelos com e sem Esparsidade de Ativação
Através da medição e análise da FFN (Feed-Forward Network) de três modelos, OPT 6.7B, Llama 7B (com ativação SiLU) e Falcon 7B (com ativação GELU), as três conclusões a seguir são tiradas:
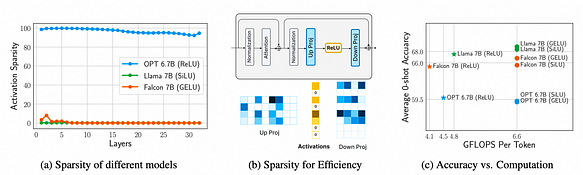
a. A comparação entre Llama 7B (com SiLU), Falcon 7B (com GELU) e OPT 6.7B (com ReLU) revela que a ReLU induz mais de 90% de esparsidade de ativação, enquanto SiLU e GELU induzem menos de 10%, demonstrando que a ReLU pode induzir ativações esparsas.
b. A esparsidade de ativação leva a economias significativas na transmissão de pesos (I/O), afetando aproximadamente 95% das linhas dos pesos da camada de projeção downstream.
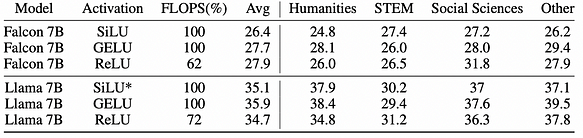
c. A escolha da função de ativação não afeta significativamente a precisão, pois GELU, SiLU ou ReLU estão no mesmo nível de precisão. No entanto, a ReLU pode economizar 32% da carga de trabalho computacional (FLOPS).
Reduzindo Custos de Treinamento
Muitos LLMs modernos (como Llama e Falcon) foram treinados usando ativações não-ReLU. Treinar do zero não é econômico; portanto, é necessário considerar a implementação de ReLU através de fine-tuning. O modelo é ajustado através das duas fases a seguir:
- Na primeira fase, as ativações ReLU existentes (no caso do OPT) são mantidas, ou a função de ativação entre as camadas up-projection e down-projection é substituída por ReLU (no caso do Falcon e Llama, onde GELU e SiLU são usados).
- Na segunda fase, novas ativações ReLU são inseridas após as camadas de normalização.
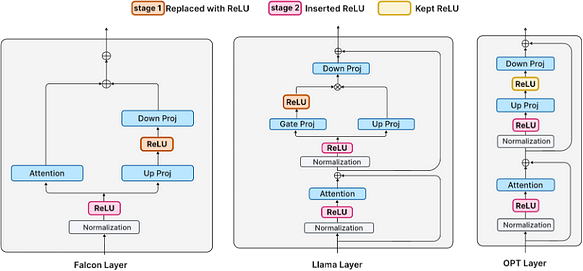
Primeira Fase — Substituição de Ativação Não-ReLU
Substitua ativações não-ReLU por ReLU nas camadas FFN. Para modelos Falcon e Llama, isso envolve substituir GELU e SiLU, respectivamente. Nota-se que, como o modelo OPT já utiliza ativações ReLU, nenhuma alteração é feita. Após fine-tuning em 30B tokens do RefinedWeb, o modelo exibe esparsidade significativa nas ativações.

Segunda Fase — Inserindo Novas ReLU
Na fase anterior, substituímos as ativações não-ReLU para obter mais esparsidade. Isso resultou em entradas esparsas para a camada down-projection, representando aproximadamente 30% do custo computacional total. No entanto, além da down-projection, existem outras multiplicações matriz-vetor nas camadas de decodificação do transformer, como a up-projection na camada FFN e a projeção QKV na camada de atenção. Coletivamente, essas multiplicações matriz-vetor consomem cerca de 55% do custo computacional total.
Em camadas Transformer modernas, as entradas para as camadas de atenção e FFN vêm de camadas de normalização, como LayerNorm ou RMSNorm. Essas camadas podem ser vistas como uma forma específica de MLP onde não aplicam parâmetros aprendíveis arbitrários, mas aprendem a escalar a entrada. Portanto, aplicamos ReLU para obter ativações esparsas após as camadas de normalização, alcançando o objetivo da segunda fase.
Resultados das Medições
Custo do Fine-tuning: O fine-tuning foi concluído com 30B e 50B tokens nas fases um e dois, respectivamente. Comparado ao custo de treinamento de 1T tokens para Llama, o custo foi de aproximadamente apenas 3–5%.
Eficácia: Comparando a latência de inferência após fine-tuning para Llama e Falcon, não houve diminuição perceptível no desempenho do modelo. No entanto, houve uma melhoria significativa de mais de 30% na velocidade de inferência.
No geral, os resultados confirmam que alcançar esparsidade de ativação através de fine-tuning pode reduzir os FLOPS de inferência em vários estágios e taxas, mantendo um desempenho comparável em diferentes tarefas. Os modelos de ativação esparsa correspondentes podem ser encontrados no projeto: https://huggingface.co/SparseLLM.
Como Acelerar a Inferência
A previsão de esparsidade de contexto do DejaVu, conforme descrito no artigo de referência [1], é uma excelente abordagem.
Como Utilizar Totalmente a Esparsidade Estruturada para Aceleração
A esparsidade de contexto assume que modelos pré-treinados exibem esparsidade de contexto, o que significa que os cálculos de esparsificação para Atenção e MLP alcançam o mesmo efeito que os cálculos completos. Com essa premissa, uma esparsidade de contexto média de 85% em modelos esparsos estruturados pode resultar em uma redução de sete vezes nos parâmetros para cada entrada específica, mantendo a precisão, melhorando assim significativamente o desempenho da inferência.
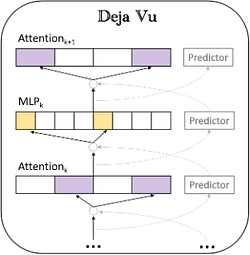
Como mostrado na figura acima, um preditor esparso assíncrono é projetado com base na esparsidade de contexto, prevendo a esparsidade da próxima camada de Atenção e MLP com antecedência. Essa abordagem não apenas garante a eficiência da inferência, mas também reduz bastante a sobrecarga computacional e de E/S.
Validação da Existência de Esparsidade de Contexto
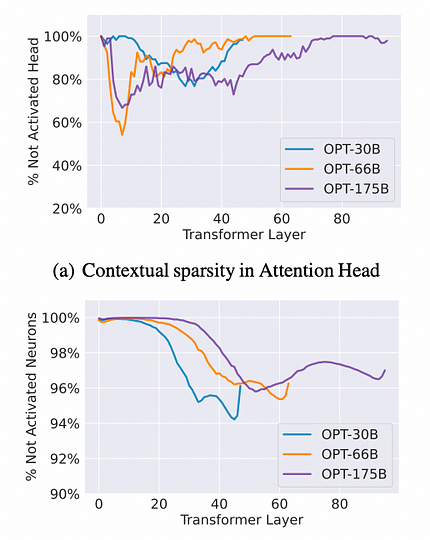
Testes foram realizados nos modelos OPT-175B, 66B e 30B com vários conjuntos de dados downstream, como OpenBookQA e Wiki-Text. O método envolveu duas passagens diretas do modelo para identificar a esparsidade de contexto para cada exemplo de entrada. Na primeira passagem, um subconjunto de parâmetros, particularmente aqueles associados a cabeças de Atenção e neurônios MLP que geram grandes normas de saída para as entradas, foi registrado. Na segunda passagem, cada exemplo de entrada foi calculado usando apenas o subconjunto de parâmetros registrado. Surpreendentemente, ambas as passagens diretas produziram previsões ou desempenho semelhantes em todas as tarefas de aprendizado de contexto e modelagem de linguagem.
Resultados da Observação: Em média, cabeças de Atenção podem impor esparsidade de até 80%, enquanto neurônios MLP podem alcançar esparsidade de até 95%, resultando em uma esparsidade geral de cerca de 85%, o que pode levar a uma aceleração de sete vezes. Para dados de referência específicos, consulte a figura abaixo.
Impacto na Engenharia
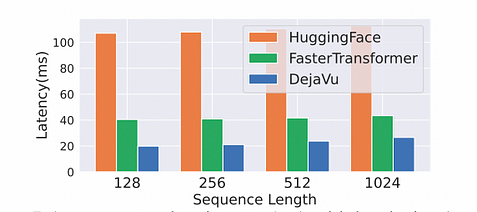
Efeito de Aceleração: Como as GPUs são dispositivos orientados a blocos, o tempo necessário para carregar um único byte de memória é o mesmo que carregar o bloco de memória em torno do mesmo endereço. O tamanho do bloco das GPUs NVIDIA é tipicamente 128 bytes. Portanto, foram realizadas otimizações como fusão de memória e fusão de operadores. Sob a premissa de batch_size=1, em comparação com o FasterTransformer, a aceleração atingiu um efeito de duplicação, alcançando uma melhoria de 2x na velocidade.
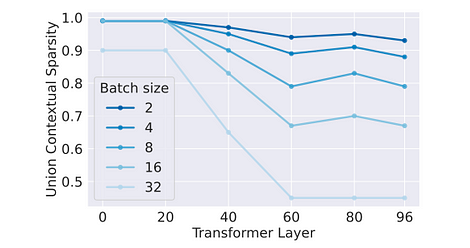
Impacto no Throughput: Como as ativações são funções de cada token, a esparsidade efetiva também é distribuída aleatoriamente entre os tokens. Portanto, a eficácia da otimização esparsa decai exponencialmente com o aumento do tamanho do lote. Isso pode ser consultado nos experimentos de ablação realizados no artigo.
Reduzindo o Limiar de Inferência
Organizando os métodos atuais de offloading parcial e o método DejaVu, conforme mostrado na tabela abaixo:
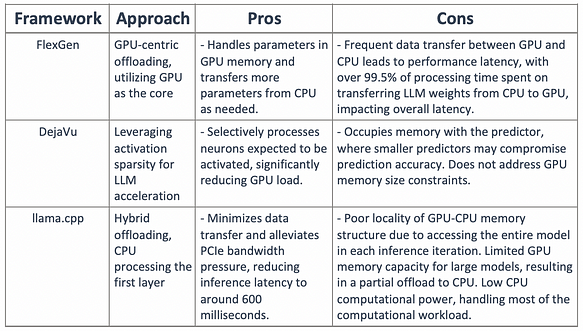
A esparsidade de ativação e os métodos de offloading podem ser combinados para projetar um mecanismo de inferência híbrido GPU-CPU: onde neurônios com ativação quente são pré-carregados na GPU para acesso rápido, enquanto neurônios com ativação fria são processados na CPU, reduzindo significativamente os requisitos de memória da GPU e a transferência de dados CPU-GPU?
A resposta é, naturalmente, ‘SIM’.
Uma dessas soluções é o PowerInfer[10], que pode executar OPT-175B em uma única NVIDIA RTX 4090, alcançando velocidades de geração de tokens apenas 18% menores do que servidores GPU A100 de alto nível. Além do offloading e da esparsidade de ativação, outros aspectos como Brainstorm[9], SparTA[15] e Flash-llm[16] também possuem valor de referência.
Visão Geral:
O PowerInfer pré-carrega pesos na GPU para neurônios frequentemente ativados, enquanto os pesos para neurônios menos ativos são mantidos na CPU.
Para reduzir a latência de inferência, o mecanismo de inferência calcula apenas neurônios previstos pelo preditor online como ativos, pulando a maioria dos neurônios inativos. Além disso, a estratégia de pré-carregamento permite que o PowerInfer aloque uma parte significativa das tarefas de inferência para a GPU, já que os neurônios de ativação quente carregados na GPU constituem a maioria das ativações. Para neurônios de ativação fria que não estão na memória da GPU, o PowerInfer realiza cálculos na CPU, eliminando a necessidade de transferir pesos para a GPU.
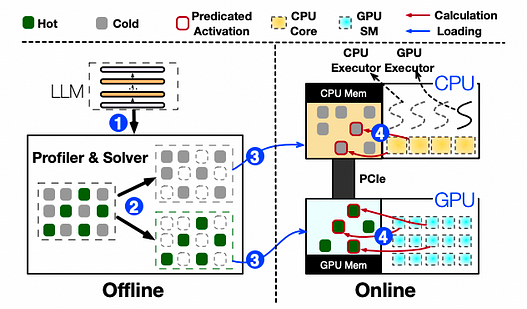
Visão geral da arquitetura e fluxo de trabalho de inferência do PowerInfer
O PowerInfer compreende componentes offline e online. Devido a variações nas propriedades de localidade entre diferentes LLMs, o componente offline analisa a esparsidade de ativação do LLM, distinguindo entre neurônios quentes e frios. Na fase online, o mecanismo de inferência carrega ambos os tipos de neurônios na GPU e CPU e atende a solicitações de LLM com baixa latência em tempo de execução. Antes de processar as solicitações do usuário, o mecanismo online atribui os dois tipos de neurônios às suas respectivas unidades de processamento com base na saída do solver offline. Em tempo de execução, o mecanismo cria executores de GPU e CPU, que são threads executados no lado da CPU, para gerenciar cálculos concorrentes CPU-GPU. O mecanismo também prevê ativações de neurônios e pula neurônios inativos. Neurônios ativados são pré-carregados na memória da GPU para processamento, enquanto a CPU calcula os resultados para seus neurônios e os transfere para a GPU para integração. O mecanismo usa operadores esparsos conscientes de neurônios tanto na CPU quanto na GPU, focando em linhas/colunas individuais de neurônios dentro das matrizes.
Link do Projeto: https://github.com/SJTU-IPADS/PowerInfer
Otimização de Cálculo de Camada Única
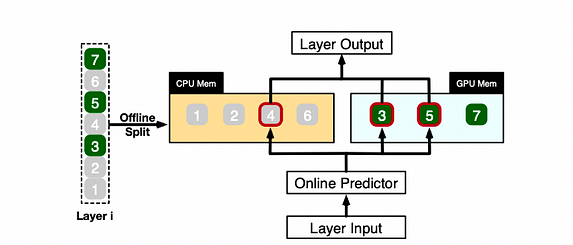
Um exemplo ilustrativo mostra como o PowerInfer calcula diferentes neurônios para uma camada de LLM
O PowerInfer coordena GPU e CPU para lidar com neurônios em uma camada, classificando-os com base em dados offline, atribuindo neurônios quentes (por exemplo, índice 3, 5, 7) à memória da GPU e alocando outros neurônios à memória da CPU.
Ao receber a entrada, o preditor identifica quais neurônios na camada atual provavelmente serão ativados. Por exemplo, ele prevê a ativação dos neurônios 3, 4 e 5. Vale notar que neurônios quentes identificados por análise estatística offline podem nem sempre estar alinhados com o comportamento de ativação em tempo de execução. Por exemplo, o neurônio 7, embora marcado como quente, pode estar inativo em um determinado cenário.
Posteriormente, tanto a CPU quanto a GPU processam os neurônios ativos previstos, ignorando os inativos. A GPU calcula os neurônios 3 e 5, enquanto a CPU lida com o neurônio 4. Assim que o cálculo do neurônio 4 é concluído, sua saída é enviada para a GPU para integração dos resultados.
Inferência Online (Mecanismo de Inferência Consciente de Neurônios)
- Preditor Esparso Adaptativo
O mecanismo de inferência online no PowerInfer reduz a carga computacional processando apenas neurônios previstos para serem ativados. Essa abordagem também é utilizada no DejaVu, que defende o treinamento de um conjunto de tamanho fixo de preditores MLP. Em cada camada Transformer, o DejaVu utiliza dois preditores independentes para prever a ativação de neurônios nos blocos de self-attention e MLP.
No entanto, projetar preditores eficazes para implantação local com recursos limitados apresenta desafios, exigindo um equilíbrio entre precisão de previsão e tamanho do modelo.
O PowerInfer emprega um método de treinamento iterativo para preditores de tamanho não fixo para cada camada Transformer. Esse processo primeiro estabelece um tamanho de modelo de base com base no perfil de esparsidade da camada. Em seguida, considerando a assimetria de ativação interna, o tamanho do modelo é ajustado iterativamente para manter a precisão. Preditores MLP geralmente compreendem camadas de entrada, oculta e saída. Como os tamanhos das camadas de entrada e saída são determinados pela estrutura da camada Transformer, as modificações visam principalmente a camada oculta. Durante o processo de ajuste iterativo, o tamanho da camada oculta é modificado com base na assimetria observada. Para camadas que exibem assimetria significativa, o tamanho da camada oculta diminui gradualmente até que a precisão caia abaixo de 95%. Por outro lado, para camadas com assimetria mínima, as dimensões são aumentadas para melhorar a precisão. Através dessa abordagem, o PowerInfer efetivamente confina os parâmetros do preditor a 10% do total de parâmetros do LLM.
- Execução Híbrida GPU-CPU
Antes da inferência, o PowerInfer constrói um grafo acíclico direcionado (DAG) computacional onde cada nó representa um operador de inferência LLM e o armazena em uma fila global na memória da CPU. Cada operador na fila é rotulado com seus operadores necessários. Durante a inferência, dois tipos de executores (criados pelo pthread do sistema operacional host) gerenciam cálculos na CPU e GPU. Eles extraem operadores da fila global, verificam dependências e os atribuem às unidades de processamento apropriadas. GPU e CPU usam seus operadores conscientes de neurônios, com o executor da GPU lançando operadores da GPU usando APIs como cudaLaunchKernel, enquanto o executor da CPU coordena núcleos de CPU não utilizados para cálculo.
Conclusão Experimental
Comparação de Desempenho
Aceleração de vários modelos no formato FP16 PC-High. O eixo X representa o comprimento da saída, enquanto o eixo Y indica a taxa de aceleração em comparação com o llama.cpp. O número acima de cada barra representa a velocidade de geração ponta a ponta (tokens/s). O comprimento da entrada configurado para a primeira linha no gráfico é de aproximadamente 64, enquanto para a segunda linha, é de cerca de 128.
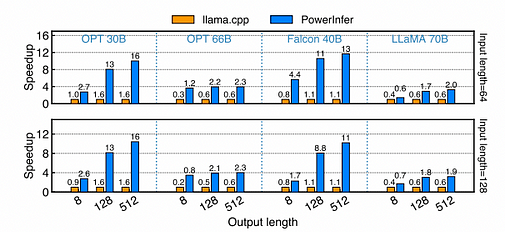
Em um PC-High equipado com NVIDIA RTX 4090, vários modelos e configurações de entrada-saída exibem diferentes velocidades de geração. Em média, o PowerInfer atinge uma velocidade de geração de 8,32 tokens/s, com um pico de 16,0 tokens/s, que é significativamente superior ao llama.cpp, com uma aceleração média de 7,23 vezes, enquanto o Falcon-40B atinge até 11,69 vezes. À medida que o número de tokens de saída aumenta, a vantagem de desempenho do PowerInfer se torna mais pronunciada, pois a fase de geração desempenha um papel mais importante no tempo total de inferência. Durante este estágio, um pequeno número de neurônios é ativado tanto na CPU quanto na GPU, reduzindo cálculos desnecessários em comparação com o llama.cpp. Por exemplo, no caso do OPT-30B, apenas cerca de 20% dos neurônios são ativados por token gerado, com a maioria processada na GPU, mostrando a vantagem do mecanismo de inferência consciente de neurônios do PowerInfer.
Impacto do Tamanho do Lote:
Quando o tamanho do lote é inferior a 32, o PowerInfer demonstra uma vantagem significativa, com uma melhoria média de 6,08 vezes em comparação com o llama.cpp. À medida que o tamanho do lote aumenta, a taxa de aceleração fornecida pelo PowerInfer diminui. Essa redução é atribuída à diminuição da esparsidade das ativações conjuntas no modelo. No entanto, mesmo com um tamanho de lote definido para 32, o PowerInfer ainda mantém uma taxa de aceleração considerável, alcançando uma melhoria de 4,38 vezes.
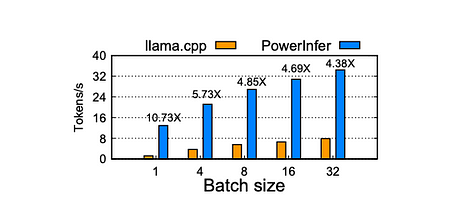
Aceleração de inferência em lote do Falcon-40B no PC-High. O eixo X indica o tamanho do lote de requisição, o eixo Y representa a velocidade de geração de token ponta a ponta (tokens/s). O número acima de cada barra mostra a aceleração em comparação com o llama.cpp.
Comparação de Carga
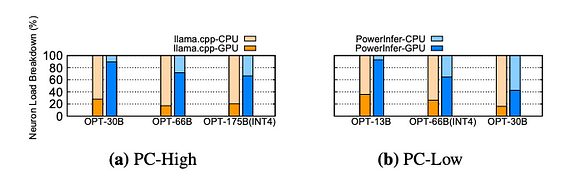
Distribuição de carga de neurônios na CPU e GPU durante a inferência. O bloco amarelo refere-se ao llama.cpp, e o bloco azul refere-se ao PowerInfer.
A distribuição das cargas de neurônios entre CPU e GPU no PowerInfer e no llama.cpp é comparada. Carga de neurônio refere-se à proporção de cálculos de neurônios ativados realizados por cada unidade de processamento. Vale notar que, em um sistema PC-High, o PowerInfer aumenta significativamente a participação da carga de neurônios na GPU, subindo de uma média de 20% para 70%. Isso indica que a GPU lida com 70% dos neurônios ativados. No entanto, quando os requisitos de memória do modelo excedem em muito a capacidade da GPU, como executar um modelo de 60GB em uma GPU 2080Ti de 11GB, a carga de neurônios na GPU diminui para 42%. Essa diminuição se deve à memória limitada da GPU, que é insuficiente para acomodar todos os neurônios quentes ativados, exigindo processamento na CPU para uma parte desses neurônios.
Em cenários envolvendo prompts de entrada mais longos e comprimentos de saída relativamente mais curtos, o PowerInfer apresenta apenas melhorias de desempenho limitadas. Nesses casos, o estágio de processar um grande número de tokens simultaneamente torna-se um fator determinante para a velocidade de inferência. Isso resulta em cada token ativando um conjunto único de neurônios, reduzindo significativamente a esparsidade de ativação. Como resultado, a CPU se torna o principal gargalo no processo de inferência, encarregada de processar um grande número de neurônios de ativação fria, mas limitada pela capacidade computacional.
Conclusão
A tecnologia de esparsidade de ativação trouxe avanços revolucionários para modelos de linguagem em larga escala. Ao esparsificar as ativações das redes neurais para acelerar o processo de inferência, enquanto reduz as cargas computacionais e de E/S da GPU, melhora-se a velocidade e o desempenho da inferência. Essa abordagem não requer retreinamento e alcança esparsidade de ativação apenas através de fine-tuning, reduzindo significativamente os custos enquanto mantém o desempenho do modelo. As perspectivas de aplicação da tecnologia de esparsidade de ativação são empolgantes, trazendo mais possibilidades para o campo do aprendizado profundo. Aguardamos ansiosamente o desenvolvimento adicional e a ampla aplicação dessa tecnologia.
Artigos de Referência
[5]ReLU Strikes Back: Exploiting Activation Sparsity in Large Language Models
[7]Inducing and exploiting activation sparsity for fast inference on deep neural networks
[8]Sparse is enough in scaling transformers
novita.ai fornece API Stable Diffusion e centenas de APIs de geração de imagem AI rápidas e baratas para 10.000 modelos.🎯 Geração mais rápida em apenas 2s, pagamento conforme o uso, a partir de US$0,0015 por imagem padrão, você pode adicionar seus próprios modelos e evitar manutenção de GPU. Grátis para compartilhar extensões de código aberto.
Leitura recomendada



