

NVIDIA H100 SXM 80GB 代表了 AI 加速技术的巅峰。现在 Novita AI 通过竞价实例(Spot)定价,以史无前例的每小时0.9美元的价格提供这款高端 GPU。这一极具竞争力的价格,让追求极致性能的企业和开发者都能用上全球最先进的 AI 加速器。
H100 在大语言模型训练、计算机视觉和高性能计算工作负载上表现卓越。它配备 80GB HBM3 显存和第 4 代 Tensor Core,推理速度相比上一代最高提升 30 倍。Novita AI 的智能竞价实例定价模型在提供突破性性能的同时,还能保证成本效益。
为什么 H100 是机器学习训练与推理的理想选择?
全新 GPU 架构
H100 SXM 80GB 基于 NVIDIA 革命性的 Hopper 架构打造,采用 5nm 工艺制程,集成超过 800 亿个晶体管,为 AI 和高性能计算(HPC)工作负载带来前所未有的性能。这款 GPU 配备 16896 个 CUDA 核心、528 个第 4 代 Tensor Core 以及 80GB 高带宽 HBM3 显存。
其显存系统提供 3.35TB/s 的显存带宽,可实现极速数据访问。突破性的 Transformer Engine 可在 FP8 和 FP16 精度之间自动切换,在保持基于 Transformer 的架构的模型精度的同时,吞吐量最高提升 4 倍。
H100 GPU 在核心 AI 应用场景中的表现
变革性 AI 训练:H100 的第 4 代 Tensor Core 和支持 FP8 精度的 Transformer Engine,可让 GPT-3 等大模型的 AI 训练速度相比上一代最高提升 4 倍。900GB/s NVLink 和 NDR InfiniBand 等先进互联技术,支持从企业级系统到大规模 GPU 集群的高效扩展,让所有研究人员都能用上百亿亿次高性能计算和万亿参数级 AI 技术。
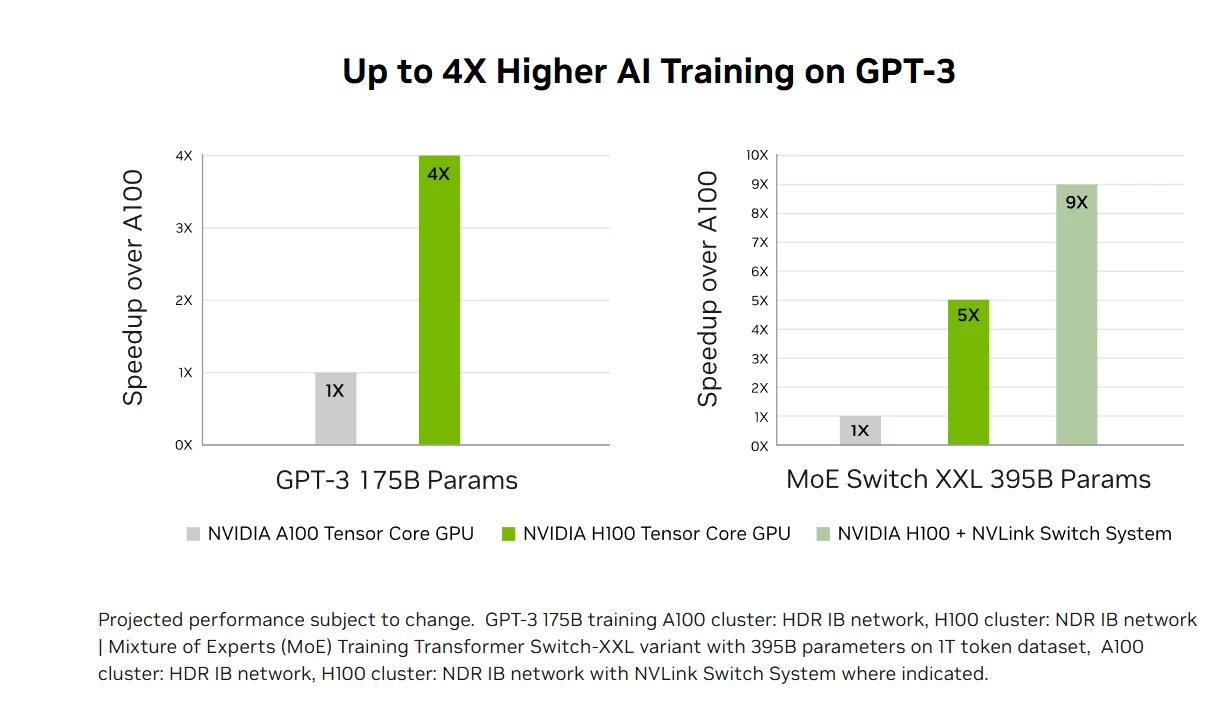
加速 AI 推理性能:H100 搭载支持从 FP64 到全新 FP8 格式所有精度的第 4 代 Tensor Core,可提供业界领先的 AI 推理性能,最高加速 30 倍且延迟最低。这种多用途的能力让 H100 能够加速各类业务应用中的不同神经网络架构,同时降低大语言模型的内存占用、保持模型精度,是实时深度学习推理挑战的全面解决方案。
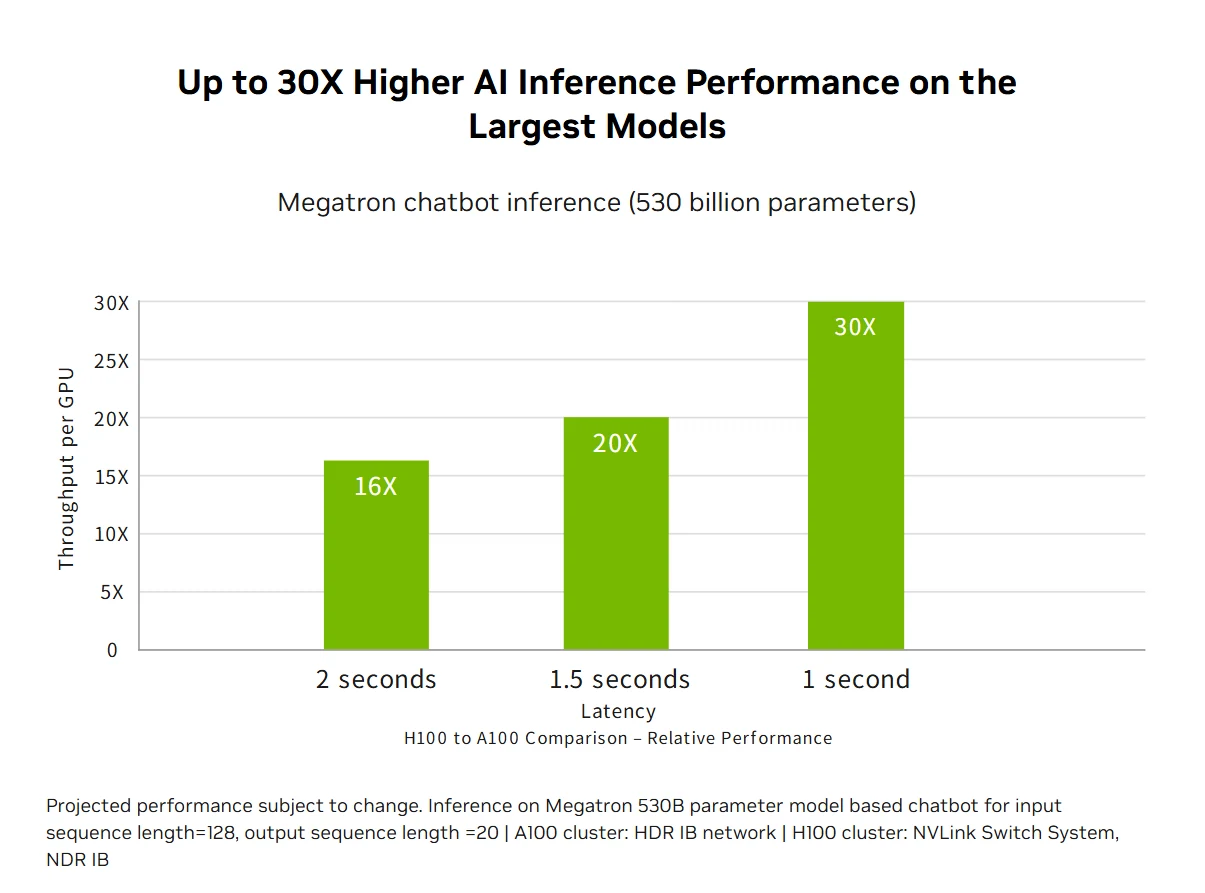
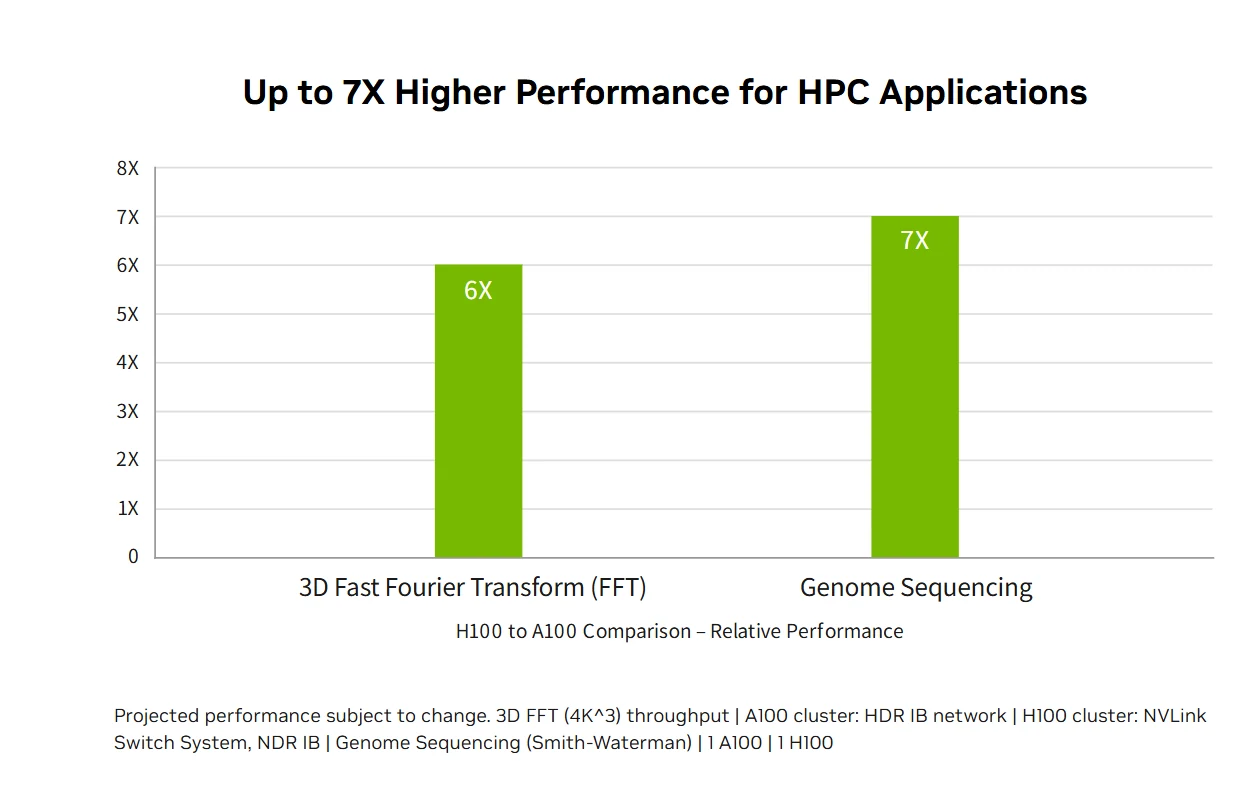
百亿亿次 HPC 性能:NVIDIA H100 数据中心平台的百亿亿次 HPC 性能超越了摩尔定律,双精度计算性能提升至 60 TFLOPS FP64,同时支持 AI 融合应用在无需修改任何代码的情况下,使用 TF32 精度实现 1 PFLOPS 的吞吐量。全新的 DPX 指令集让 Smith-Waterman DNA 测序等动态规划算法的运行速度相比 A100 提升 7 倍、相比 CPU 提升 40 倍,将传统 HPC 与突破性的 AI 能力相结合,加速全球最重要研究领域的科学发现。
80GB 显存:大模型容量规划
80GB HBM3 显存容量决定了哪些模型可以完全放入 GPU 显存中运行。
单 GPU 部署:使用 FP16 精度时,可支持最高约 700-750 亿参数的模型运行,包括 Llama 2 70B、Code Llama 70B 等热门模型及类似架构。使用 FP8 精度时,有效显存容量翻倍,可支持单张 H100 部署接近 1400-1500 亿参数的模型。
多 GPU 扩展:更大规模的模型则需要多 GPU 扩展。使用张量并行(Tensor Parallelism)技术时,2 张 H100 SXM GPU 在 FP16 精度下可支持最高 1500 亿参数的模型运行;4 张 GPU 则可支持超过 3000 亿参数模型的训练与推理。高带宽 NVLink 互联技术确保了 GPU 之间的高效通信,在多设备上可保持接近线性的扩展性能。
显存密集型应用:除模型参数外,大语言模型的长上下文窗口也属于显存密集型场景。需要 32K 以上 token 上下文窗口的应用,尤其能受益于 H100 的大容量显存池。高分辨率图像处理和科学数据集处理也会充分利用其充足的显存容量。
H100 SXM 与 PCIe 版本:性能与定价差异
| Specification | H100 SXM | H100 PCIe |
|---|---|---|
| CUDA Cores | 16,896 | 14,592 |
| Tensor Cores | 528 | 456 |
| GPU Memory | 80GB HBM3 | 80GB HBM2e |
| Memory Bandwidth | 3.35TB/s | 2.0TB/s |
| TF32 Performance | 989 TFLOPS | 756 TFLOPS |
| FP16 Performance | 1,979 TFLOPS | 1,513 TFLOPS |
| FP8 Performance | 3,958 TFLOPS | 3,026 TFLOPS |
| Max TDP | 700W | 350W |
| Interconnect | NVLink 900GB/s | NVLink 600GB/s |
| Form Factor | SXM5 Module | PCIe Dual-Slot |
SXM5 版本因其为极致性能密度设计的卓越架构,定价更高。SXM 形态规格可直接集成到专用服务器主板上,实现最优的供电和散热效果。相比 PCIe 版本,该设计显存带宽高 67%、Tensor Core 数量多 30%,多 GPU 通信速度也显著更快。
H100 与 A100 对比:哪款 GPU 更适合您的工作负载?
| Specification | NVIDIA A100 | NVIDIA H100 SXM5 |
|---|---|---|
| Form Factor | SXM4 | SXM5 |
| Streaming Multiprocessors (SMs) | 108 | 132 |
| TPCs | 54 | 66 |
| FP32 Cores per SM | 64 | 128 |
| Total FP32 Cores | 6,912 | 16,896 |
| FP64 Cores per SM (excl. Tensor) | 32 | 64 |
| Total FP64 Cores (excl. Tensor) | 3,456 | 8,448 |
| Tensor Cores | 432 | 528 |
| Memory Interface | 5120-bit HBM2 | 5120-bit HBM3 |
| Transistors | 54.2 billion | 80 billion |
| Memory Bandwidth | 1,555 GB/s | 3,000 GB/s |
| Max TDP | 400 W | 700 W |
相比 A100,H100 的处理核心数量多 2.4 倍,显存速度接近翻倍(3000GB/s 对比 1555GB/s),晶体管数量多 48%。不过其功耗也高出 75%(700W 对比 400W)。
H100 与 A100 成本对比
| Provider/GPU Model | Spot Pricing | On-Demand |
|---|---|---|
| Novita AI H100 SXM 80GB | $0.90/hr | $1.80/hr |
| RunPod H100 SXM 80GB | $1.75/hr | $2.69/hr |
| Novita AI A100 SXM 80GB | $0.80/hr | $1.60/hr |
| RunPod A100 SXM 80GB | $0.95/hr | $1.74/hr |
竞价实例 vs 按需实例:如何选择
选择竞价实例的场景:当您的工作负载可以容忍偶尔的中断,且正在进行开发工作时,适合选择竞价实例。带检查点(Checkpointing)功能的训练任务、研究项目、对成本敏感的应用都非常适合使用竞价实例。对于大多数开发和批量处理场景来说,50% 的成本节省足以抵消偶尔重启带来的影响。
选择按需实例的场景:当您需要运行生产级推理服务,或进行有严格截止时间的时效性训练时,适合选择按需实例。按需实例能提供稳定的性能,无中断风险,这对于面向客户的应用和需要保障可用性的关键任务工作负载来说至关重要。
混合策略:许多组织会通过将竞价实例用于开发和非关键工作负载来优化成本,同时预留按需实例容量用于生产服务。这种方式既能最大化成本节省,又能在需要时保障服务的可靠交付。
如何在 Novita AI 上找到 H100 SXM 80GB 竞价实例
在 Novita AI 上启动 H100 竞价实例的流程与其他 GPU 部署的简化流程一致,已得到广泛验证。
访问控制台
登录您的Novita AI GPU 控制台。仪表盘会实时展示 GPU 可用性、当前竞价实例容量以及您最近的部署记录,帮助您做出更明智的部署时机和位置决策。
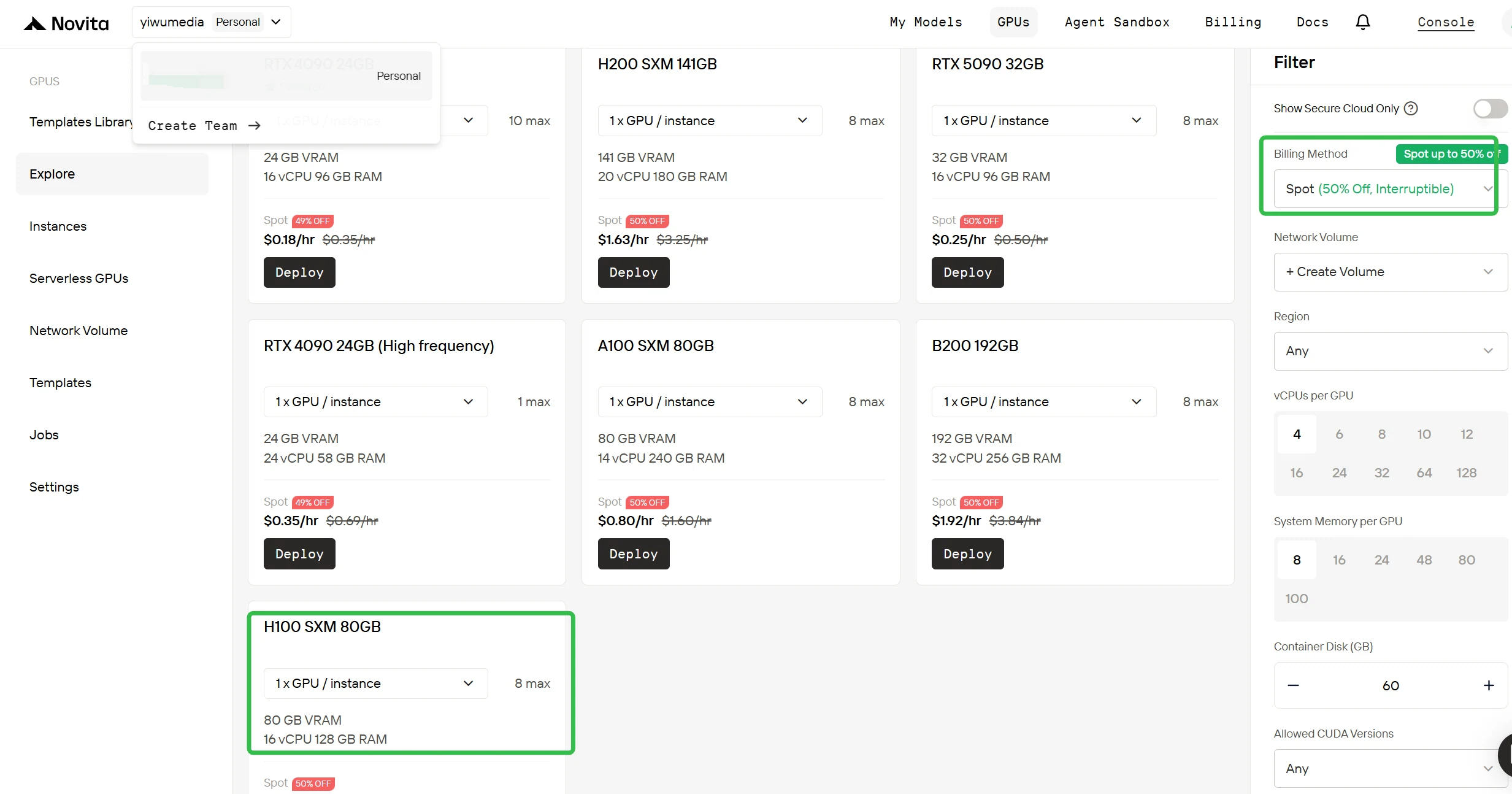
切换至竞价计费模式
在右侧边栏的筛选区域,将计费方式从“按需”切换为“竞价”,即可查看折扣后的价格。界面会立即更新,显示 H100 每小时仅需 0.9 美元。这种透明的定价机制确保您在部署前就能明确知晓所需费用。
Novita AI 竞价实例是如何运作的?
竞价实例使用的是 Novita AI 的闲置 GPU 容量,因此价格更低——当按需实例的需求上升时,这部分容量会被回收。
核心特性
可用性波动:当 Novita AI 需要回收容量时,竞价实例可能会被中断。但这并非随机终止——平台会遵循结构化流程,并提前发送通知。
大幅成本节省:可享受比按需实例最高低 50% 的价格,获得完全相同的 GPU 性能。硬件配置和性能表现完全一致,仅可用性保障不同。
保护期:每台竞价实例在启动后都有 1 小时的保护窗口,在此期间无论容量需求如何,您的实例都不会被中断。
提前通知:您会在容量回收前 1 小时收到中断通知,还会额外收到 5 分钟的最终提醒。这些通知让您有时间保存工作、生成检查点,并优雅地关闭应用。
与按需实例对比
| Feature | Spot Instances | On-Demand Instances |
|---|---|---|
| Pricing | Up to 50% less | Standard rates |
| Availability | Subject to capacity | Always available |
| Interruption risk | May be reclaimed with notice | No interruptions |
| Protection period | 1 hour after launch | Continuous |
| Use case | Flexible, fault-tolerant workloads | Critical, uninterruptible workloads |
通过为合适的工作负载选择竞价实例,您既能获得同样强大的 GPU 资源,又能优化计算成本。
了解更多: Novita AI 竞价实例指南
适合部署竞价实例的智能工作负载
开发与实验:这类工作负载是竞价定价的理想适用场景。模型原型开发、超参数调优、研究实验等任务都可以利用竞价实例的成本优势,同时容忍偶尔的中断。这类工作负载通常适合采用检查点策略,中断后可以高效恢复。
批量处理与训练:具备容错设计的批量处理与训练任务非常适合使用竞价实例。大规模数据处理、带定期检查点的模型训练、分布式计算任务等都可以实现大幅成本节省。PyTorch、TensorFlow 等现代深度学习框架内置了检查点机制,可以无缝集成。
时间灵活型工作负载:没有严格完成截止时间的工作负载可以最大化竞价定价的优势。夜间训练任务、周末批量处理、非关键推理任务等都可以完全使用竞价实例,在保持高性能标准的同时实现成本最优化。
总结
Novita AI 上每小时 0.9 美元的 H100 SXM 80GB 竞价实例,是当前市面上最具性价比的高端 AI 加速器获取方案。相比 A100 具备突破性的性能提升,同时拥有完善的软件栈集成,这一产品方案让企业无需受预算限制,即可应对高要求的 AI 工作负载。第 4 代 Tensor Core、80GB HBM3 显存与智能竞价定价的结合,让高级 AI 开发变得触手可及。
无论是训练大语言模型、开发计算机视觉应用,还是开展科学研究,H100 SXM 都能为下一代 AI 项目提供所需的性能。立即使用全球最先进的 AI 加速器开始构建——在 Novita AI 上部署您的 H100 SXM 80GB 竞价实例,以无与伦比的价格体验卓越性能。
常见问题解答
H100 SXM 和 PCIe 版本有什么区别? H100 SXM 性能更优,显存带宽高 67%(3.35TB/s 对比 2.0TB/s),Tensor Core 数量也更多(528 个对比 456 个)。SXM 形态规格可直接集成到服务器主板上,实现最优的供电和散热效果。PCIe 版本使用标准扩展槽,性能有所降低。
竞价实例用于 AI 训练的可靠性如何? Novita AI 的竞价实例具备企业级可靠性特性,包括 1 小时保障保护期。用户会提前 60 分钟收到中断通知,以及 5 分钟的最终提醒。现代 AI 框架支持透明检查点机制,训练任务可以在任何中断后无缝恢复。
H100 SXM 可以用于推理工作负载吗? 完全可以。H100 SXM 在推理工作负载上表现卓越,推理速度相比上一代最高提升 30 倍。Transformer Engine 和 FP8 精度支持为大语言模型提供了极高的吞吐量。80GB 显存支持大批次和复杂模型部署,即使纯推理应用使用竞价实例也非常划算。
如果我的竞价实例被中断了怎么办? 您会在中断前提前 60 分钟收到通知,以及 5 分钟的最终提醒,有充足的时间保存工作、生成检查点、优雅地关闭应用。现代 AI 框架通过内置的检查点机制自动处理中断,您可以使用保存的检查点立即重新启动任务。
H100 和 A100 相比如何? 得益于 FP8 支持和 Transformer Engine,H100 的训练速度最高比 A100 快 6 倍,推理速度最高快 30 倍。其显存带宽为 3.35TB/s,而 A100 约为 2TB/s,减少了数据瓶颈。虽然 A100 在小规模任务上仍具成本效益,但 H100 在大规模、时效性强的工作负载上性能更优,总成本更低。
Novita AI 是一个 AI 云平台,为开发者提供简单的 API 来轻松部署 AI 模型,同时提供高性价比、可靠的 GPU 云服务,用于 AI 应用的构建与扩展。



