

NVIDIA H100 SXM 80GBはAIアクセラレーション技術の最高峰です。Novita AIはこのプレミアムGPUをスポット価格で前代未聞の1時間あたり0.90ドルで提供します。この競争力のある料金により、最大限のパフォーマンスを求める企業や開発者が世界最高峰のAIアクセラレーターを利用できるようになります。
H100は大規模言語モデルのトレーニング、コンピュータビジョン、HPCワークロードで卓越したパフォーマンスを発揮します。80GBのHBM3メモリと第4世代Tensor Coresを搭載し、前世代比最大30倍の高速な推論を実現します。Novita AIのインテリジェントなスポット価格モデルは、画期的なパフォーマンスを提供しつつ、コスト効率も維持します。
なぜH100がMLトレーニングと推論に最適なのか?
完全に新しいGPUアーキテクチャ
H100 SXM 80GBはNVIDIAの革新的なHopperアーキテクチャをベースに開発されました。5nmプロセスノードに800億個以上のトランジスタを搭載し、AIおよびHPCワークロードで前代未聞のパフォーマンスを提供します。このGPUは16,896個のCUDAコア、528個の第4世代Tensor Cores、80GBの高速HBM3メモリを搭載しています。
メモリシステムは3.35TB/sのメモリ帯域幅を提供し、超高速なデータアクセスを実現します。画期的なTransformer EngineはFP8とFP16の精度を自動的に切り替え、トランスフォーマーベースのアーキテクチャのモデル精度を維持しつつ、スループットを最大4倍向上させます。
主要AIアプリケーションにおけるH100 GPUのパフォーマンス
変革的なAIトレーニング:第4世代Tensor CoresとFP8精度対応のTransformer Engineを搭載したH100は、GPT-3のような大規模モデルのAIトレーニングを前世代比最大4倍高速化します。900GB/sのNVLinkやNDR InfiniBandなどの先進的なインターコネクトにより、エンタープライズシステムから大規模GPUクラスタへの効率的なスケーリングが可能になり、エクサスケールHPCや1兆パラメータ級のAIがすべての研究者にとって利用可能になります。
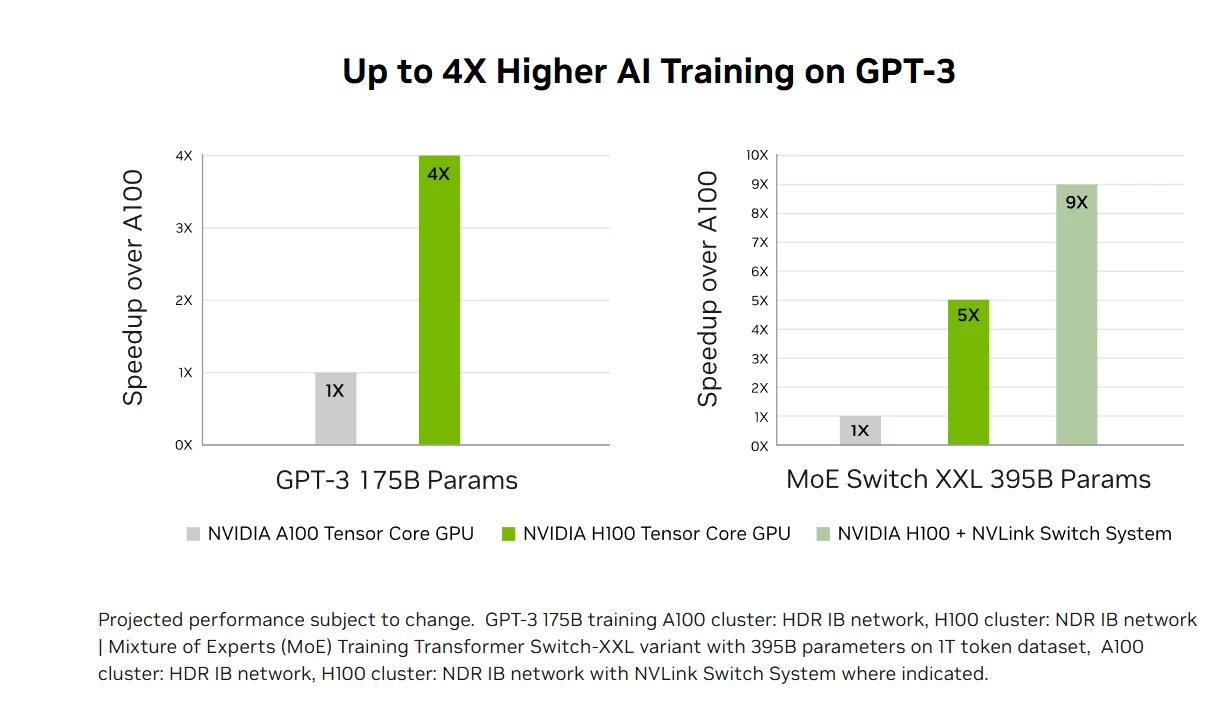
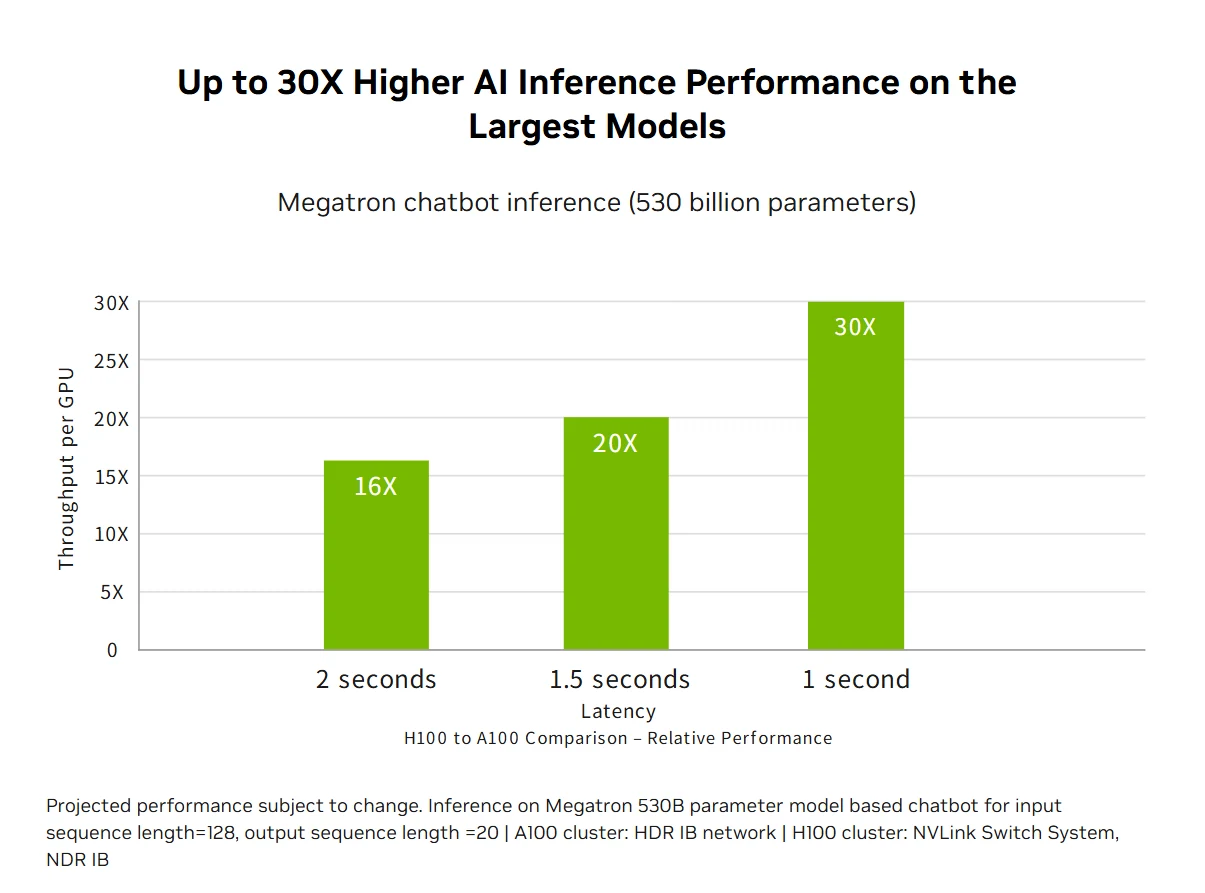
高速化されたAI推論パフォーマンス:第4世代Tensor CoresはFP64から新しいFP8フォーマットまでの全精度をサポートし、H100は最大30倍の加速と最低レイテンシで市場をリードするAI推論パフォーマンスを提供します。この多様性により、H100はビジネスアプリケーション全体の多様なニューラルネットワークアーキテクチャを加速させ、大規模言語モデルの精度を維持しつつメモリ使用量を削減し、リアルタイム深層学習推論の課題に対する包括的なソリューションとなります。
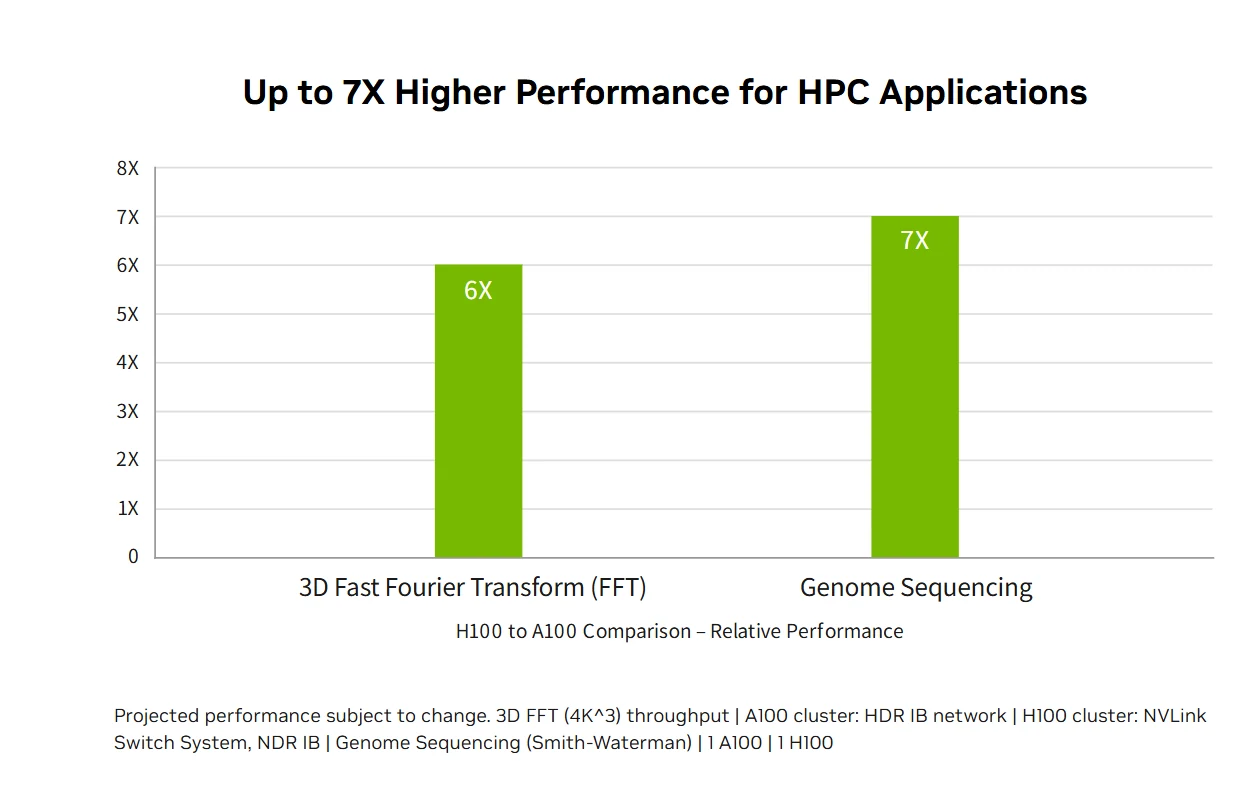
エクサスケールHPCパフォーマンス:NVIDIA H100データセンター・プラットフォームはムーアの法則を超えるエクサスケールHPCパフォーマンスを提供し、倍精度演算を60テラフロップスのFP64に3倍に引き上げ、コード変更なしでTF32精度を使用したAI融合アプリケーションが1ペタフロップのスループットを実現可能にします。新しいDPX命令は、Smith-Waterman DNAシーケンシングのような動的計画法アルゴリズムにおいて、A100比7倍、CPU比40倍の高速化を提供し、従来のHPCと画期的なAI機能を組み合わせることで、世界で最も重要な研究課題における科学的発見を加速します。
80GBメモリ:大規模モデル向けの容量計画
80GBのHBM3メモリ容量は、GPUメモリに完全に収まるモデルの規模を決定します。
単一GPUデプロイメントでは、FP16精度を使用して最大約700億~750億パラメータのモデルを処理可能です。これにはLlama 2 70B、Code Llama 70Bなどの人気モデルや同様のアーキテクチャが含まれます。
FP8精度を使用することで容量は実質的に2倍になり、単一のH100で1400億~1500億パラメータに近いモデルのデプロイが可能になります。
マルチGPUスケーリングは、より大規模なモデルに必要になります。テンソル並列処理を使用することで、2つのH100 SXM GPUでFP16精度下で最大1500億パラメータのモデルを処理可能です。
4つのGPUを使用することで、3000億パラメータを超えるモデルのトレーニングと推論が可能になります。高速なNVLinkインターコネクトはGPU間の効率的な通信を保証し、複数デバイス間でほぼ線形なスケーリングパフォーマンスを維持します。
メモリ集約型アプリケーション:モデルパラメータ以外のメモリ集約型アプリケーションとしては、言語モデルの大規模コンテキストウィンドウが挙げられます。32Kトークンを超えるコンテキストウィンドウを必要とするアプリケーションは、特にH100の大容量メモリプールの恩恵を受けます。高解像度画像処理や科学データセットも、この広大なメモリ容量を活用します。
H100 SXMとPCIeの比較:パフォーマンスと価格の違い
| 仕様 | H100 SXM | H100 PCIe |
|---|---|---|
| CUDAコア | 16,896 | 14,592 |
| Tensorコア | 528 | 456 |
| GPUメモリ | 80GB HBM3 | 80GB HBM2e |
| メモリ帯域幅 | 3.35TB/s | 2.0TB/s |
| TF32性能 | 989 TFLOPS | 756 TFLOPS |
| FP16性能 | 1,979 TFLOPS | 1,513 TFLOPS |
| FP8性能 | 3,958 TFLOPS | 3,026 TFLOPS |
| 最大TDP | 700W | 350W |
| インターコネクト | NVLink 900GB/s | NVLink 600GB/s |
| フォームファクタ | SXM5モジュール | PCIeデュアルスロット |
SXM5 variantは最大パフォーマンス密度を目的とした優れたアーキテクチャのため、プレミアム価格が設定されています。SXMフォームファクタは専用のサーバーマザーボードに直接統合され、最適な電力供給と冷却を可能にします。この設計により、PCIe版と比較して67%高いメモリ帯域幅、30%多いTensorコア、はるかに高速なマルチGPU通信を実現します。
H100とA100の比較:どのGPUがワークロードに適しているか?
| 仕様 | NVIDIA A100 | NVIDIA H100 SXM5 |
|---|---|---|
| フォームファクタ | SXM4 | SXM5 |
| ストリーミングマルチプロセッサ(SM) | 108 | 132 |
| TPC | 54 | 66 |
| SMあたりFP32コア | 64 | 128 |
| 合計FP32コア | 6,912 | 16,896 |
| SMあたりFP64コア(Tensorコア除く) | 32 | 64 |
| 合計FP64コア(Tensorコア除く) | 3,456 | 8,448 |
| Tensorコア | 432 | 528 |
| メモリインターフェース | 5120ビットHBM2 | 5120ビットHBM3 |
| トランジスタ数 | 542億個 | 800億個 |
| メモリ帯域幅 | 1,555 GB/s | 3,000 GB/s |
| 最大TDP | 400 W | 700 W |
H100はA100と比較して2.4倍多くのプロセッシングコア、ほぼ2倍のメモリ速度(3,000 GB/s対1,555 GB/s)、48%多いトランジスタを搭載しています。ただし、消費電力は75%多い(700W対400W)という特徴があります。
H100とA100のコスト比較
| プロバイダ/GPUモデル | スポット価格 | オンデマンド |
|---|---|---|
| Novita AI H100 SXM 80GB | 1時間あたり0.90ドル | 1時間あたり1.80ドル |
| RunPod H100 SXM 80GB | 1時間あたり1.75ドル | 1時間あたり2.69ドル |
| Novita AI A100 SXM 80GB | 1時間あたり0.80ドル | 1時間あたり1.60ドル |
| RunPod A100 SXM 80GB | 1時間あたり0.95ドル | 1時間あたり1.74ドル |
スポット価格とオンデマンドの使い分け
スポット価格を選ぶべきケース:ワークロードが偶発的な中断を許容できる場合、開発作業を行っている場合に適しています。スポット価格はチェックポイント付きのトレーニング実行、研究プロジェクト、コスト重視のアプリケーションに最適です。50%のコスト削減は、ほとんどの開発やバッチ処理シナリオで偶発的な再起動を正当化します。
オンデマンドを選ぶべきケース:本番環境の推論サービスの実行や、厳しい締め切りのある時間依存型のトレーニングを行う場合です。オンデマンドインスタンスは中断リスクなしで安定したパフォーマンスを提供するため、顧客向けアプリケーションや稼働保証が必要なミッションクリティカルなワークロードに不可欠です。
ハイブリッド戦略:多くの組織は、開発や非クリティカルなワークロードにスポットインスタンスを使用することでコストを最適化しています。本番サービスにはオンデマンドのキャパシティを確保しておくことで、必要な箇所で信頼性の高いサービス提供を保証しつつ、コスト削減を最大化します。
Novita AIでH100 SXM 80GBスポットインスタンスを見つける方法
Novita AIでのH100スポットインスタンスの起動は、他のGPUデプロイメントで実績のある同じスムーズなプロセスに従います。
コンソールにアクセス
Novita AI GPUコンソールにログインしてください。ダッシュボードにはGPUのリアルタイム稼働状況、現在のスポットインスタンスのキャパシティ、最近のデプロイメントが表示されます。この概要は、インスタンスをデプロイするタイミングと場所を判断するのに役立ちます。
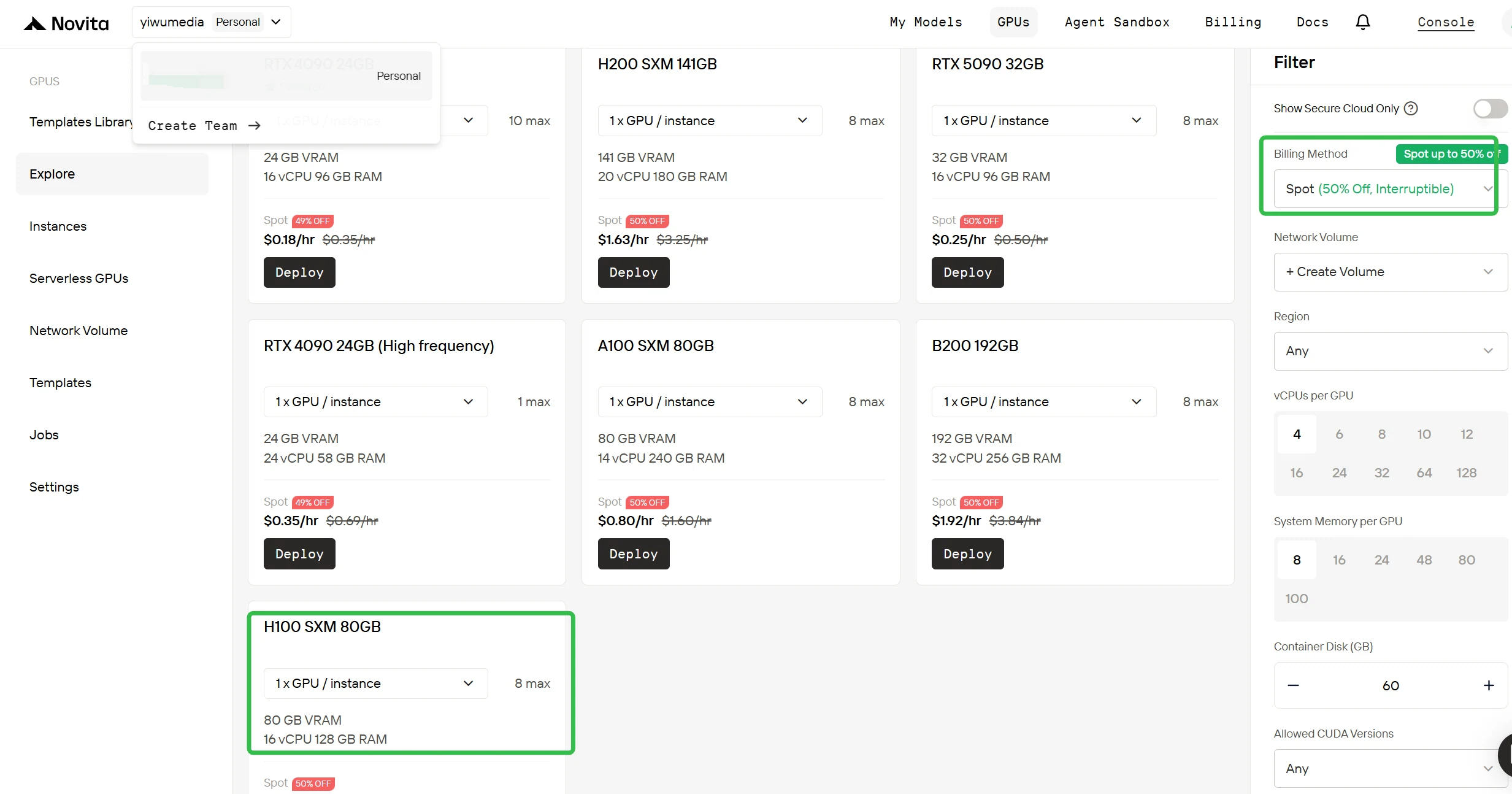
スポット課金に切り替え
右サイドバーの[フィルター]項目で、課金方法を「オンデマンド」から「スポット」に変更すると、割引価格を確認できます。インターフェースはすぐに更新され、H100が1時間あたり0.90ドルで表示されます。この透明性により、デプロイ前に支払い金額を正確に把握できます。
Novita AIのスポットインスタンスの仕組み
スポットインスタンスはNovita AIの余剰GPUキャパシティを利用するもので、通常のインスタンスの需要が高まった際にキャパシティを回収できるため、低価格で提供されています。
主な特徴
稼働状況の変動:Novita AIがキャパシティを回収する必要が生じた場合、スポットインスタンスは中断される可能性があります。ただし、これはランダムな強制終了を意味するものではなく、プラットフォームは事前通知を含む構造化されたプロセスに従います。
大幅なコスト削減:オンデマンド価格と比較して最大50%安い価格で同じGPUパフォーマンスを利用できます。ハードウェアとパフォーマンスは全く同じで、異なるのは稼働保証のみです。
保護期間:各スポットインスタンスには、起動後1時間の保護ウィンドウが設けられています。この期間中は、キャパシティの需要が高まった場合でもインスタンスが中断されることはありません。
事前通知:キャパシティ回収の1時間前に中断通知を受け取り、さらに5分前に追加の警告が表示されます。これらの通知により、作業の保存、進捗のチェックポイント作成、アプリケーションの正常なシャットダウンが可能です。
オンデマンドインスタンスとの比較
| 特徴 | スポットインスタンス | オンデマンドインスタンス |
|---|---|---|
| 価格 | 最大50%安い | 標準料金 |
| 稼働状況 | キャパシティに依存 | 常に利用可能 |
| 中断リスク | 事前通知の上で回収される可能性あり | 中断なし |
| 保護期間 | 起動後1時間 | 継続的 |
| 用途 | 柔軟でフォールトトレラントなワークロード | クリティカルで中断不可能なワークロード |
適切なワークロードにスポットインスタンスを選択することで、同じ強力なGPUリソースを利用しつつ、コンピューティングコストを最適化できます。
詳細はこちら: Novita AIスポットインスタンスガイド
スポットインスタンスのデプロイに適したスマートなワークロード
開発と実験のワークロードは、スポット価格の理想的な用途です。モデルのプロトタイピング、ハイパーパラメータチューニング、研究実験は、偶発的な中断を許容しつつコスト削減を活用できます。これらのワークロードは通常、チェックポイント戦略の恩恵を受け、中断後に効率的に再開可能です。
バッチ処理とトレーニングのジョブは、フォールトトレランスを考慮して設計されている場合、スポットインスタンスと非常に相性が良いです。大規模データ処理、定期的なチェックポイント付きのモデルトレーニング、分散コンピューティングタスクは、大幅なコスト削減を実現できます。PyTorchやTensorFlowなどの最新の深層学習フレームワークには、シームレスに統合可能な組み込みのチェックポイント機構が搭載されています。
時間的に柔軟なワークロード:厳しい完了期限のない時間的に柔軟なワークロードは、スポット価格のメリットを最大化します。夜間のトレーニング実行、週末のバッチ処理、非クリティカルな推論タスクは、スポットインスタンスを独占的に利用可能です。これにより、高いパフォーマンス基準を維持しつつ、コスト最適化を最大限に実現します。
結論
Novita AIで提供されている1時間あたり0.90ドルのスポット価格のNVIDIA H100 SXM 80GBは、現在利用可能なプレミアムAIアクセラレーションへの最もコスト効率の高いアクセス手段です。A100を上回る画期的なパフォーマンス向上と包括的なソフトウェアスタック統合により、このオファリングは企業が予算の制約なく要求の厳しいAIワークロードに取り組むことを可能にします。第4世代Tensor Cores、80GB HBM3メモリ、インテリジェントなスポット価格の組み合わせにより、先進的なAI開発が誰にとっても利用可能になります。
大規模言語モデルのトレーニング、コンピュータビジョンアプリケーションの開発、科学研究の実施を問わず、H100 SXMは次世代AIプロジェクトに必要なパフォーマンスを提供します。今日から世界最高峰のAIアクセラレーターを使って開発を始めましょう——**Novita AIでH100 SXM 80GBスポットインスタンスをデプロイ**し、破格の価格で比類のないパフォーマンスを体験してください。
よくある質問
H100 SXMとPCIeの違いは何ですか? H100 SXMは67%高いメモリ帯域幅(3.35TB/s対2.0TB/s)とより多くのTensorコア(528個対456個)により、優れたパフォーマンスを提供します。SXMフォームファクタはサーバーマザーボードに直接統合され、最適な電力供給と冷却を実現します。PCIe版は標準の拡張スロットを使用するため、パフォーマンスが低下しています。
AIトレーニングにおけるスポットインスタンスの信頼性はどの程度ですか? Novita AIのスポットインスタンスには、1時間の保証保護期間を含むエンタープライズグレードの信頼性機能が搭載されています。ユーザーは60分の事前中断通知と5分の最終警告を受け取ります。最新のAIフレームワークは透過的なチェックポイントをサポートしているため、トレーニングジョブは中断後もシームレスに再開可能です。
H100 SXMを推論ワークロードに使用できますか? もちろんです。H100 SXMは推論ワークロードに優れており、前世代比最大30倍の高速なパフォーマンスを提供します。Transformer EngineとFP8精度サポートにより、言語モデルで卓越したスループットを実現します。80GBのメモリにより大規模バッチサイズや複雑なモデルのデプロイが可能になるため、推論専用のアプリケーションでもスポット価格はコスト効率が高いです。
スポットインスタンスが中断された場合はどうなりますか? 中断の60分前に事前通知を受け取り、さらに5分前に最終警告が表示されます。これにより、作業の保存、チェックポイントの作成、アプリケーションの正常なシャットダウンに十分な時間があります。最新のAIフレームワークは組み込みのチェックポイント機構を通じて中断を自動的に処理するため、保存したチェックポイントを使って即座に再起動可能です。
H100とA100の比較はどうですか? FP8サポートとTransformer Engineにより、H100はA100と比較してトレーニングで最大6倍、推論で最大30倍高速です。また、メモリ帯域幅は3.35TB/sで、A100の約2TB/sと比較してデータボトルネックを削減します。A100は小規模なジョブでも依然としてコスト効率が高いですが、大規模で時間依存型のワークロードではH100がより優れたパフォーマンスと低い総所有コストを提供します。
Novita AIは、シンプルなAPIを使ってAIモデルをデプロイする簡単な方法を開発者に提供するとともに、構築とスケーリングのための手頃で信頼性の高いGPUクラウドを提供するAIクラウドプラットフォームです。



