

- ¿Por qué la H100 es ideal para el entrenamiento y la inferencia de ML?
- H100 SXM vs PCIe: diferencias de rendimiento y precio
- H100 vs A100: ¿qué GPU se adapta a tu carga de trabajo?
- Compara el coste de la H100 y la A100
- Cómo encontrar instancias spot H100 SXM 80GB en Novita AI
- ¿Cómo funcionan las instancias spot de Novita AI?
- Cargas de trabajo ideales para el despliegue de instancias spot
- Conclusión
La NVIDIA H100 SXM 80GB representa la cúspide de la tecnología de aceleración de IA. Novita AI ahora ofrece esta GPU premium a un precio sin precedentes de $0.90/hora mediante precios spot. Esta tarifa competitiva hace que el acelerador de IA más avanzado del mundo sea accesible para empresas y desarrolladores que buscan el máximo rendimiento.
La H100 ofrece un rendimiento excepcional para entrenamiento de modelos de lenguaje grandes, visión por computadora y cargas de trabajo de computación de alto rendimiento. Con 80GB de memoria HBM3 y Tensor Cores de 4.ª generación, proporciona una inferencia hasta 30 veces más rápida que las generaciones anteriores. El modelo de precios spot inteligente de Novita AI mantiene la eficiencia de costos a la vez que ofrece un rendimiento revolucionario.
Despliega tu instancia spot H100 ahora
¿Por qué la H100 es ideal para el entrenamiento y la inferencia de ML?
Una arquitectura de GPU completamente nueva
La H100 SXM 80GB se basa en la revolucionaria arquitectura Hopper de NVIDIA. Integra más de 80 mil millones de transistores en un nodo de proceso de 5 nm, ofreciendo un rendimiento sin precedentes para cargas de trabajo de IA y HPC. La GPU cuenta con 16.896 núcleos CUDA, 528 Tensor Cores de 4.ª generación y 80GB de memoria HBM3 de alto ancho de banda.
El sistema de memoria proporciona un ancho de banda de 3,35 TB/s para un acceso a datos ultrarrápido. El revolucionario Transformer Engine cambia automáticamente entre las precisiones FP8 y FP16. Esto permite un rendimiento hasta 4 veces mayor manteniendo la precisión del modelo para arquitecturas basadas en transformadores.
Rendimiento de la GPU H100 en aplicaciones clave de IA
Entrenamiento de IA transformacional: Los Tensor Cores de cuarta generación de la H100 y el Transformer Engine con precisión FP8 aceleran el entrenamiento de IA hasta 4 veces más rápido que las generaciones anteriores para modelos grandes como GPT-3. Interconexiones avanzadas como NVLink de 900 GB/s e InfiniBand NDR permiten una escalabilidad eficiente desde sistemas empresariales hasta clústeres masivos de GPU, haciendo que la HPC de exaescala y la IA de billones de parámetros sean accesibles para todos los investigadores.
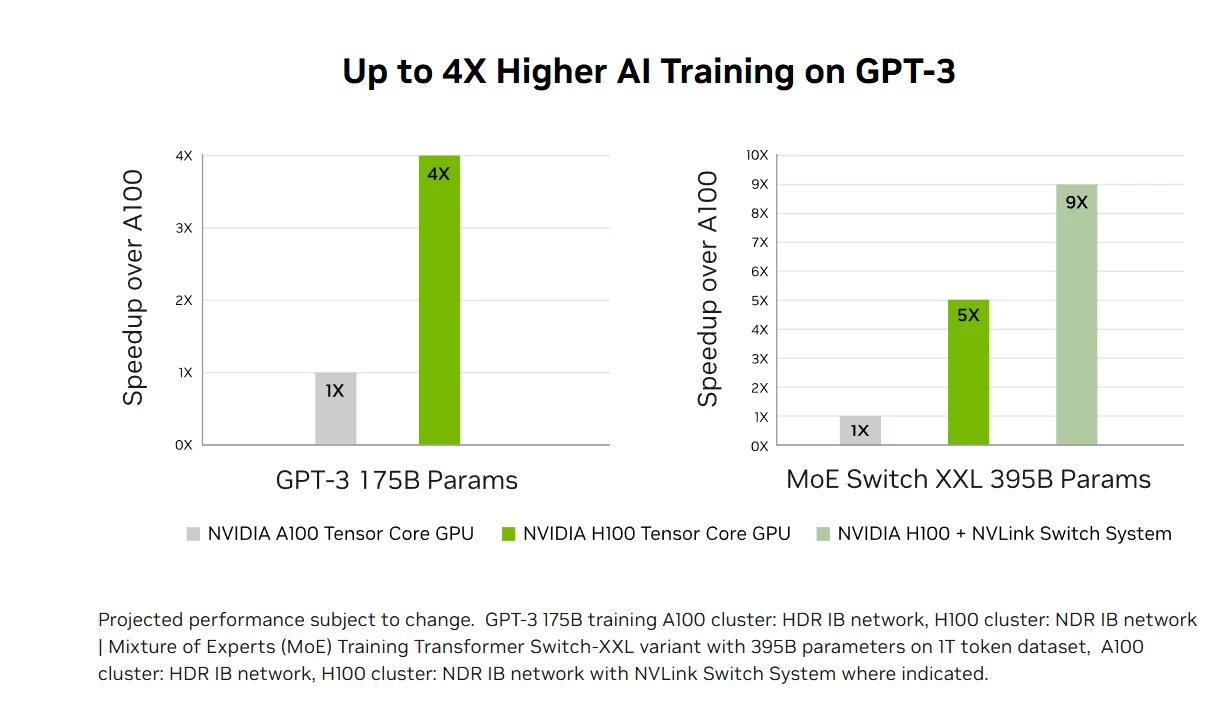
Rendimiento de inferencia de IA acelerado: La H100 ofrece un rendimiento de inferencia de IA líder en el mercado con una aceleración de hasta 30 veces y la menor latencia gracias a los Tensor Cores de cuarta generación que admiten todas las precisiones desde FP64 hasta el nuevo formato FP8. Esta versatilidad permite a la H100 acelerar diversas arquitecturas de redes neuronales en aplicaciones empresariales, reduciendo el uso de memoria y manteniendo la precisión para modelos de lenguaje grandes, lo que la convierte en una solución integral para los desafíos de inferencia de aprendizaje profundo en tiempo real.
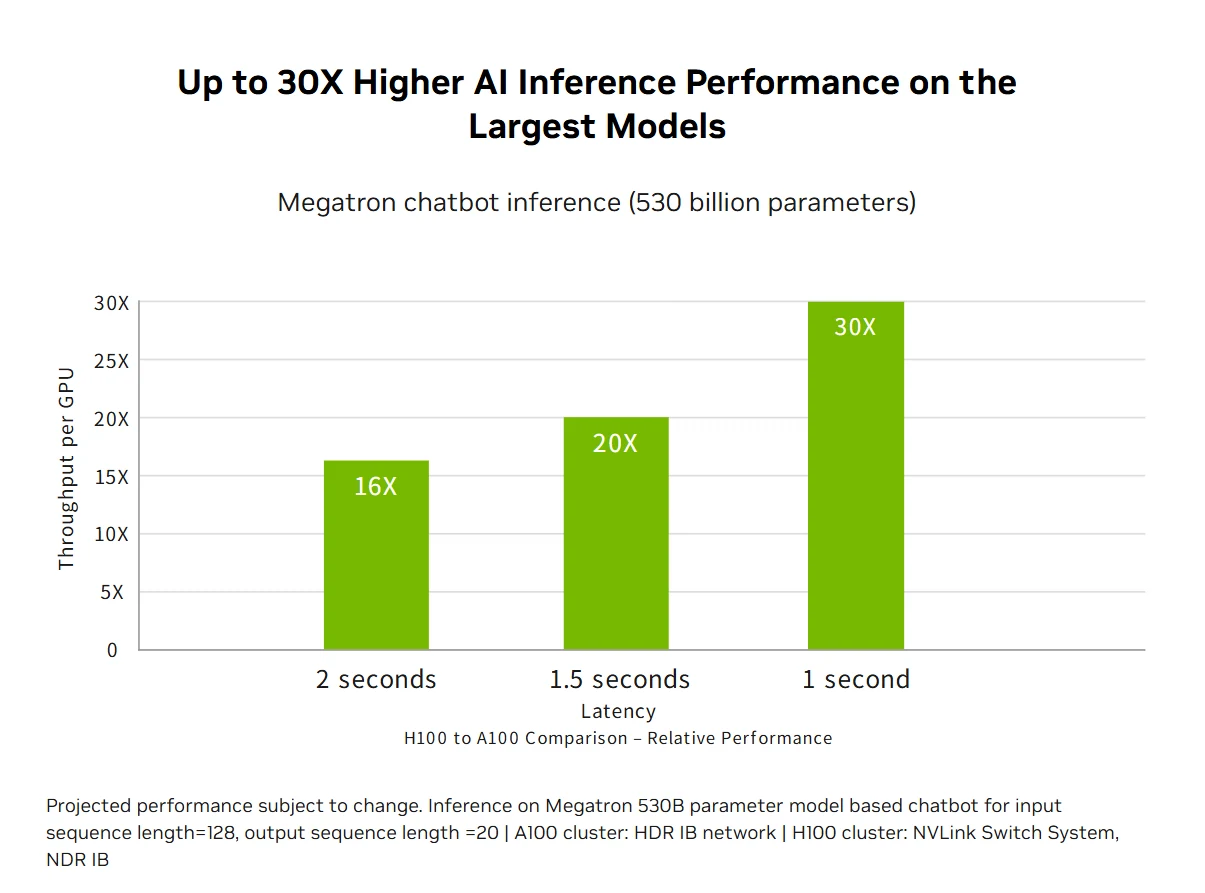
Rendimiento HPC de exaescala: La plataforma de centros de datos NVIDIA H100 ofrece un rendimiento HPC de exaescala que supera la ley de Moore, triplicando la computación de doble precisión hasta 60 teraflops FP64, a la vez que permite que las aplicaciones fusionadas con IA alcancen un rendimiento de un petaflop usando precisión TF32 sin necesidad de cambios de código. Las nuevas instrucciones DPX ofrecen aceleraciones 7 veces superiores a la A100 y 40 veces superiores a las CPU para algoritmos de programación dinámica como la secuenciación de ADN Smith-Waterman, combinando HPC tradicional con capacidades de IA revolucionarias para acelerar el descubrimiento científico en los desafíos de investigación más importantes del mundo.
Memoria de 80GB: planificación de capacidad para modelos grandes
La capacidad de memoria HBM3 de 80GB determina qué modelos pueden caber completamente en la memoria de la GPU.
Despliegues de GPU única pueden manejar modelos de hasta aproximadamente 70-75 mil millones de parámetros usando precisión FP16. Esto incluye modelos populares como Llama 2 70B, Code Llama 70B y arquitecturas similares.
La precisión FP8 duplica efectivamente esta capacidad, permitiendo el despliegue de modelos de hasta 140-150 mil millones de parámetros en una sola H100.
Escalabilidad multigpu se vuelve necesaria para modelos más grandes. Usando paralelismo de tensores, dos GPUs H100 SXM pueden manejar modelos de hasta 150 mil millones de parámetros en FP16.
Cuatro GPUs permiten el entrenamiento y la inferencia de modelos de más de 300 mil millones de parámetros. El interconector NVLink de alto ancho de banda garantiza una comunicación eficiente entre las GPUs. Esto mantiene un rendimiento de escalabilidad casi lineal en múltiples dispositivos.
Aplicaciones intensivas en memoria más allá de los parámetros del modelo incluyen ventanas de contexto grandes para modelos de lenguaje. Las aplicaciones que requieren ventanas de contexto de más de 32K tokens se benefician especialmente del amplio grupo de memoria de la H100. El procesamiento de imágenes de alta resolución y los conjuntos de datos científicos también aprovechan la extensa capacidad de memoria.
H100 SXM vs PCIe: diferencias de rendimiento y precio
| Especificación | H100 SXM | H100 PCIe |
|---|---|---|
| CUDA Cores | 16,896 | 14,592 |
| Tensor Cores | 528 | 456 |
| GPU Memory | 80GB HBM3 | 80GB HBM2e |
| Memory Bandwidth | 3,35 TB/s | 2,0 TB/s |
| TF32 Performance | 989 TFLOPS | 756 TFLOPS |
| FP16 Performance | 1,979 TFLOPS | 1,513 TFLOPS |
| FP8 Performance | 3,958 TFLOPS | 3,026 TFLOPS |
| Max TDP | 700W | 350W |
| Interconnect | NVLink 900GB/s | NVLink 600GB/s |
| Form Factor | SXM5 Module | PCIe Dual-Slot |
La variante SXM5 tiene un precio premium debido a su arquitectura superior diseñada para la máxima densidad de rendimiento. El factor de forma SXM se integra directamente en placas base de servidores especializadas, permitiendo una entrega de energía y refrigeración óptimas. Este diseño ofrece un 67% más de ancho de banda de memoria, un 30% más de Tensor Cores y una comunicación multigpu significativamente más rápida en comparación con la versión PCIe.
H100 vs A100: ¿qué GPU se adapta a tu carga de trabajo?
| Especificación | NVIDIA A100 | NVIDIA H100 SXM5 |
|---|---|---|
| Form Factor | SXM4 | SXM5 |
| Streaming Multiprocessors (SMs) | 108 | 132 |
| TPCs | 54 | 66 |
| FP32 Cores per SM | 64 | 128 |
| Total FP32 Cores | 6,912 | 16,896 |
| FP64 Cores per SM (excl. Tensor) | 32 | 64 |
| Total FP64 Cores (excl. Tensor) | 3,456 | 8,448 |
| Tensor Cores | 432 | 528 |
| Memory Interface | 5120-bit HBM2 | 5120-bit HBM3 |
| Transistors | 54,2 mil millones | 80 mil millones |
| Memory Bandwidth | 1,555 GB/s | 3,000 GB/s |
| Max TDP | 400 W | 700 W |
La H100 ofrece un 2,4 veces más núcleos de procesamiento, casi el doble de velocidad de memoria (3.000 frente a 1.555 GB/s) y un 48% más de transistores que la A100. Sin embargo, consume un 75% más de energía (700W frente a 400W).
Compara el coste de la H100 y la A100
| Proveedor/Modelo de GPU | Precio spot | Bajo demanda |
|---|---|---|
| Novita AI H100 SXM 80GB | $0.90/hr | $1.80/hr |
| RunPod H100 SXM 80GB | $1.75/hr | $2.69/hr |
| Novita AI A100 SXM 80GB | $0.80/hr | $1.60/hr |
| RunPod A100 SXM 80GB | $0.95/hr | $1.74/hr |
Precio spot vs bajo demanda: cuándo elegir cada uno
Elige el precio spot cuando: tus cargas de trabajo pueden soportar interrupciones ocasionales y estás realizando trabajo de desarrollo. El precio spot funciona excelentemente para ejecuciones de entrenamiento con puntos de control, proyectos de investigación y aplicaciones sensibles al coste. El 50% de ahorro justifica reinicios ocasionales en la mayoría de escenarios de desarrollo y procesamiento por lotes.
Elige el precio bajo demanda cuando: ejecutas servicios de inferencia en producción o realizas entrenamientos con plazos ajustados y críticos en el tiempo. Las instancias bajo demanda ofrecen un rendimiento constante sin riesgo de interrupción. Esto es esencial para aplicaciones orientadas al cliente y cargas de trabajo críticas que requieren disponibilidad garantizada.
Estrategias híbridas: muchas organizaciones optimizan los costes usando instancias spot para desarrollo y cargas de trabajo no críticas. Reservan capacidad bajo demanda para servicios de producción. Este enfoque maximiza el ahorro de costes a la vez que garantiza una entrega de servicio fiable donde se necesite.
Cómo encontrar instancias spot H100 SXM 80GB en Novita AI
Lanzar una instancia spot H100 en Novita AI sigue el mismo proceso simplificado que ha demostrado ser exitoso en otros despliegues de GPU.
Accede a tu consola
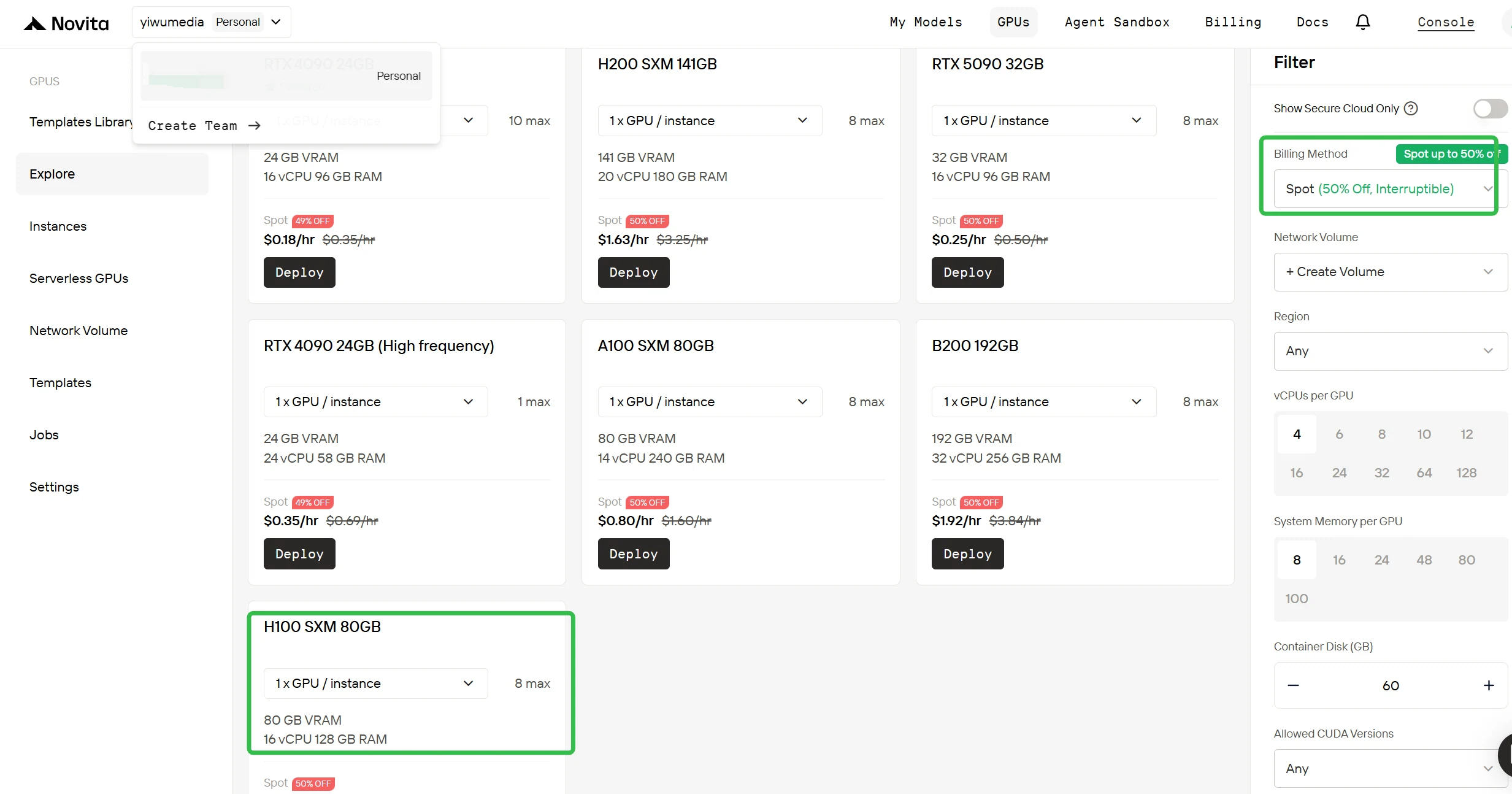
Inicia sesión en tu Consola de GPU de Novita AI. El panel muestra la disponibilidad de GPUs en tiempo real, la capacidad actual de instancias spot y tus despliegues recientes. Esta descripción general te ayuda a tomar decisiones informadas sobre cuándo y dónde desplegar tus instancias.
Cambia a facturación spot
En la barra lateral derecha, en Filtro, cambia el método de facturación de «Bajo demanda» a «Spot» para ver los precios con descuento. La interfaz se actualiza inmediatamente para mostrar la H100 a $0.90/hora. Esta transparencia garantiza que sepas exactamente lo que estás pagando antes del despliegue.
¿Cómo funcionan las instancias spot de Novita AI?
Las instancias spot utilizan la capacidad de GPU sobrante de Novita AI, por lo que esta capacidad está disponible a precios más bajos, ya que se puede reclamar cuando aumenta la demanda de instancias regulares.
Características clave
Disponibilidad variable: las instancias spot pueden ser interrumpidas cuando Novita AI necesite recuperar la capacidad. Sin embargo, esto no significa una terminación aleatoria: la plataforma sigue un proceso estructurado con notificaciones previas.
Ahorro de costes significativo: accede al mismo rendimiento de GPU con hasta un 50% menos que los precios bajo demanda. El hardware y el rendimiento son idénticos; solo difiere la garantía de disponibilidad.
Período de protección: cada instancia spot incluye una ventana de protección de 1 hora después del lanzamiento. Durante este tiempo, tu instancia no puede ser interrumpida independientemente de las demandas de capacidad.
Notificaciones previas: recibe notificaciones de interrupción 1 hora antes de la reclamación, con una advertencia adicional de 5 minutos. Estas notificaciones te permiten guardar el trabajo, crear puntos de control y cerrar las aplicaciones de forma ordenada.
Comparación con instancias bajo demanda
| Característica | Instancias spot | Instancias bajo demanda |
|---|---|---|
| Precio | Hasta un 50% menos | Tarifas estándar |
| Disponibilidad | Sujeta a capacidad | Siempre disponible |
| Riesgo de interrupción | Pueden ser reclamadas con aviso | Sin interrupciones |
| Período de protección | 1 hora después del lanzamiento | Continuo |
| Caso de uso | Cargas de trabajo flexibles y tolerantes a fallos | Cargas de trabajo críticas e ininterrumpibles |
Al elegir instancias spot para cargas de trabajo adecuadas, accedes a los mismos potentes recursos de GPU a la vez que optimizas los costes de computación.
Más información: Guía de instancias spot de Novita AI
Cargas de trabajo ideales para el despliegue de instancias spot
Las cargas de trabajo de desarrollo y experimentación representan el caso de uso ideal para el precio spot. La creación de prototipos de modelos, el ajuste de hiperparámetros y los experimentos de investigación pueden aprovechar el ahorro de costes a la vez que aceptan interrupciones ocasionales. Estas cargas de trabajo suelen beneficiarse de estrategias de puntos de control y pueden reanudarse de forma eficiente después de las interrupciones.
Los trabajos de procesamiento por lotes y entrenamiento funcionan excelentemente con instancias spot cuando se diseñan con tolerancia a fallos. El procesamiento de datos a gran escala, el entrenamiento de modelos con puntos de control regulares y las tareas de computación distribuida pueden lograr un ahorro de costes significativo. Los marcos de aprendizaje profundo modernos como PyTorch y TensorFlow incluyen mecanismos de puntos de control integrados que se integran de forma perfecta.
Las cargas de trabajo flexibles en el tiempo sin plazos de finalización estrictos maximizan los beneficios del precio spot. Las ejecuciones de entrenamiento nocturnas, el procesamiento por lotes de fin de semana y las tareas de inferencia no críticas pueden utilizar instancias spot de forma exclusiva. Esto logra una optimización máxima de costes a la vez que mantiene estándares de alto rendimiento.
Conclusión
La NVIDIA H100 SXM 80GB con precio spot de $0.90/hora en Novita AI representa el acceso más rentable a la aceleración de IA premium disponible hoy en día. Con mejoras de rendimiento revolucionarias frente a la A100 e integración completa de la pila de software, esta oferta permite a las empresas abordar cargas de trabajo de IA exigentes sin restricciones presupuestarias. La combinación de Tensor Cores de 4.ª generación, memoria HBM3 de 80GB y precios spot inteligentes hace que el desarrollo de IA avanzado sea accesible.
Ya sea que entrenes modelos de lenguaje grandes, desarrolles aplicaciones de visión por computadora o realices investigación científica, la H100 SXM ofrece el rendimiento necesario para proyectos de IA de próxima generación. Empieza a construir con el acelerador de IA más avanzado del mundo hoy mismo: despliega tu instancia spot H100 SXM 80GB en Novita AI y experimenta un rendimiento inigualable a precios imbatibles.
Preguntas frecuentes
¿Cuál es la diferencia entre la H100 SXM y la PCIe? La H100 SXM ofrece un rendimiento superior con un 67% más de ancho de banda de memoria (3,35 TB/s frente a 2,0 TB/s) y más Tensor Cores (528 frente a 456). El factor de forma SXM se integra directamente en placas base de servidores para una entrega de energía y refrigeración óptimas. Las versiones PCIe usan ranuras de expansión estándar con capacidades de rendimiento reducidas.
¿Qué fiabilidad tienen las instancias spot para el entrenamiento de IA? Las instancias spot de Novita AI incluyen funciones de fiabilidad de nivel empresarial, como períodos de protección garantizados de 1 hora. Los usuarios reciben notificaciones de interrupción con 60 minutos de antelación y advertencias finales de 5 minutos. Los marcos de IA modernos admiten puntos de control transparentes, lo que permite que los trabajos de entrenamiento se reanuden sin problemas después de cualquier interrupción.
¿Puedo usar la H100 SXM para cargas de trabajo de inferencia? Por supuesto. La H100 SXM destaca en cargas de trabajo de inferencia, ofreciendo un rendimiento hasta 30 veces más rápido que las generaciones anteriores. El Transformer Engine y la compatibilidad con precisión FP8 proporcionan un rendimiento excepcional para modelos de lenguaje. La memoria de 80GB permite tamaños de lote grandes y despliegues de modelos complejos, lo que hace que el precio spot sea rentable incluso para aplicaciones exclusivas de inferencia.
¿Qué pasa si se interrumpe mi instancia spot? Recibirás una notificación previa de 60 minutos seguida de una advertencia final de 5 minutos antes de cualquier interrupción. Esto proporciona tiempo suficiente para guardar el trabajo, crear puntos de control y cerrar las aplicaciones de forma ordenada. Los marcos de IA modernos gestionan automáticamente las interrupciones mediante mecanismos de puntos de control integrados, lo que permite relanzar inmediatamente con los puntos de control guardados.
¿Cómo se compara la H100 con la A100? La H100 es hasta 6 veces más rápida para entrenamiento y 30 veces más rápida para inferencia que la A100, gracias a la compatibilidad con FP8 y el Transformer Engine. También tiene un ancho de banda de memoria de 3,35 TB/s frente a los ~2 TB/s de la A100, lo que reduce los cuellos de botella de datos. Aunque la A100 sigue siendo rentable para trabajos más pequeños, la H100 ofrece un mejor rendimiento y un coste total menor para cargas de trabajo grandes y sensibles al tiempo.
Novita AI es una plataforma de cloud de IA que ofrece a los desarrolladores una forma sencilla de desplegar modelos de IA mediante nuestra API simple, además de proporcionar un cloud de GPU asequible y fiable para construir y escalar.



