

- Warum ist die H100 ideal für ML-Training und Inferenz?
- H100 SXM vs. PCIe: Leistungs- und Preisunterschiede
- H100 vs. A100: Welche GPU passt zu Ihrem Workload?
- Kostenvergleich von H100 und A100
- So finden Sie H100 SXM 80-GB-Spot-Instanzen bei Novita AI
- Wie funktionieren Novita AI Spot-Instanzen?
- Optimale Workloads für die Bereitstellung von Spot-Instanzen
- Fazit
Die NVIDIA H100 SXM 80 GB stellt die Spitze der KI-Beschleunigungstechnologie dar. Novita AI bietet diese erstklassige GPU jetzt zu einem beispiellosen 0,90 $/h im Spot-Preismodell an. Dieser wettbewerbsfähige Preis macht den weltweit fortschrittlichsten KI-Beschleuniger für Unternehmen und Entwickler zugänglich, die maximale Leistung suchen.
Die H100 liefert außergewöhnliche Leistung für das Training großer Sprachmodelle, Computer Vision und Hochleistungsrechen-Workloads. Mit 80 GB HBM3-Speicher und Tensor Cores der 4. Generation bietet sie eine bis zu 30 Mal schnellere Inferenz als vorherige Generationen. Das intelligente Spot-Preismodell von Novita AI gewährleistet Kosteneffizienz bei gleichzeitig bahnbrechender Leistung.
Starten Sie jetzt Ihre H100-Spot-Instanz
Warum ist die H100 ideal für ML-Training und Inferenz?
Eine vollständig neue GPU-Architektur
Die H100 SXM 80 GB basiert auf der revolutionären Hopper-Architektur von NVIDIA. Sie beherbergt über 80 Milliarden Transistoren in einem 5-nm-Prozessknoten und liefert beispiellose Leistung für KI- und HPC-Workloads. Die GPU verfügt über 16.896 CUDA-Kerne, 528 Tensor Cores der 4. Generation und 80 GB HBM3-Speicher mit hoher Bandbreite.
Das Speichersystem bietet eine Speicherbandbreite von 3,35 TB/s für blitzschnellen Datenzugriff. Die bahnbrechende Transformer Engine wechselt automatisch zwischen FP8- und FP16-Präzision. Dies ermöglicht einen bis zu 4 Mal höheren Durchsatz bei gleichbleibender Modellgenauigkeit für Transformer-basierte Architekturen.
H100-GPU-Leistung in wichtigen KI-Anwendungsbereichen
Transformatives KI-Training: Die Tensor Cores der vierten Generation und die Transformer Engine mit FP8-Präzision der H100 beschleunigen das KI-Training für große Modelle wie GPT-3 um bis zu 4 Mal schneller als vorherige Generationen. Fortschrittliche Interconnects wie NVLink mit 900 GB/s und NDR InfiniBand ermöglichen eine effiziente Skalierung von Unternehmenssystemen bis hin zu massiven GPU-Clustern, wodurch Exascale-HPC und KI mit Billionen von Parametern für alle Forscher zugänglich wird.
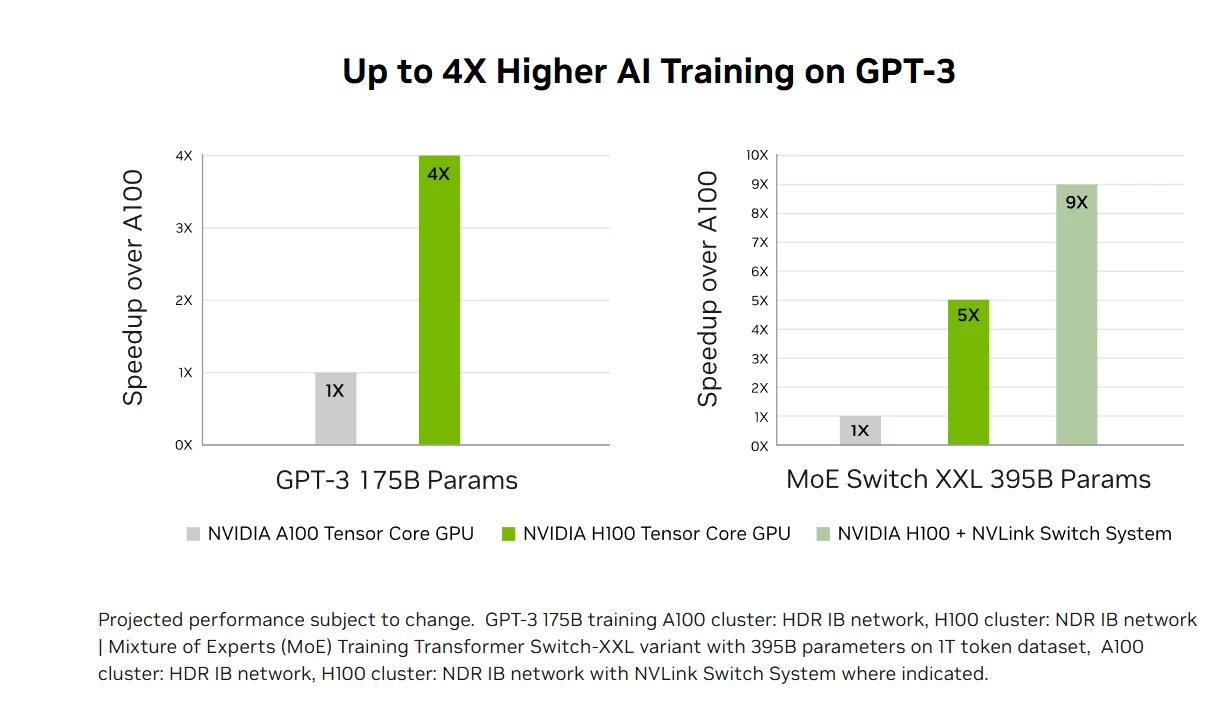
Beschleunigte KI-Inferenzleistung: Die H100 liefert marktführende KI-Inferenzleistung mit bis zu 30-facher Beschleunigung und niedrigster Latenz durch Tensor Cores der vierten Generation, die alle Präzisionen von FP64 bis zum neuen FP8-Format unterstützen. Diese Vielseitigkeit ermöglicht es der H100, unterschiedliche neuronale Netzarchitekturen in Unternehmensanwendungen zu beschleunigen, gleichzeitig den Speicherverbrauch zu senken und die Genauigkeit für große Sprachmodelle beizubehalten, was sie zu einer umfassenden Lösung für Echtzeit-Deep-Learning-Inferenz-Herausforderungen macht.
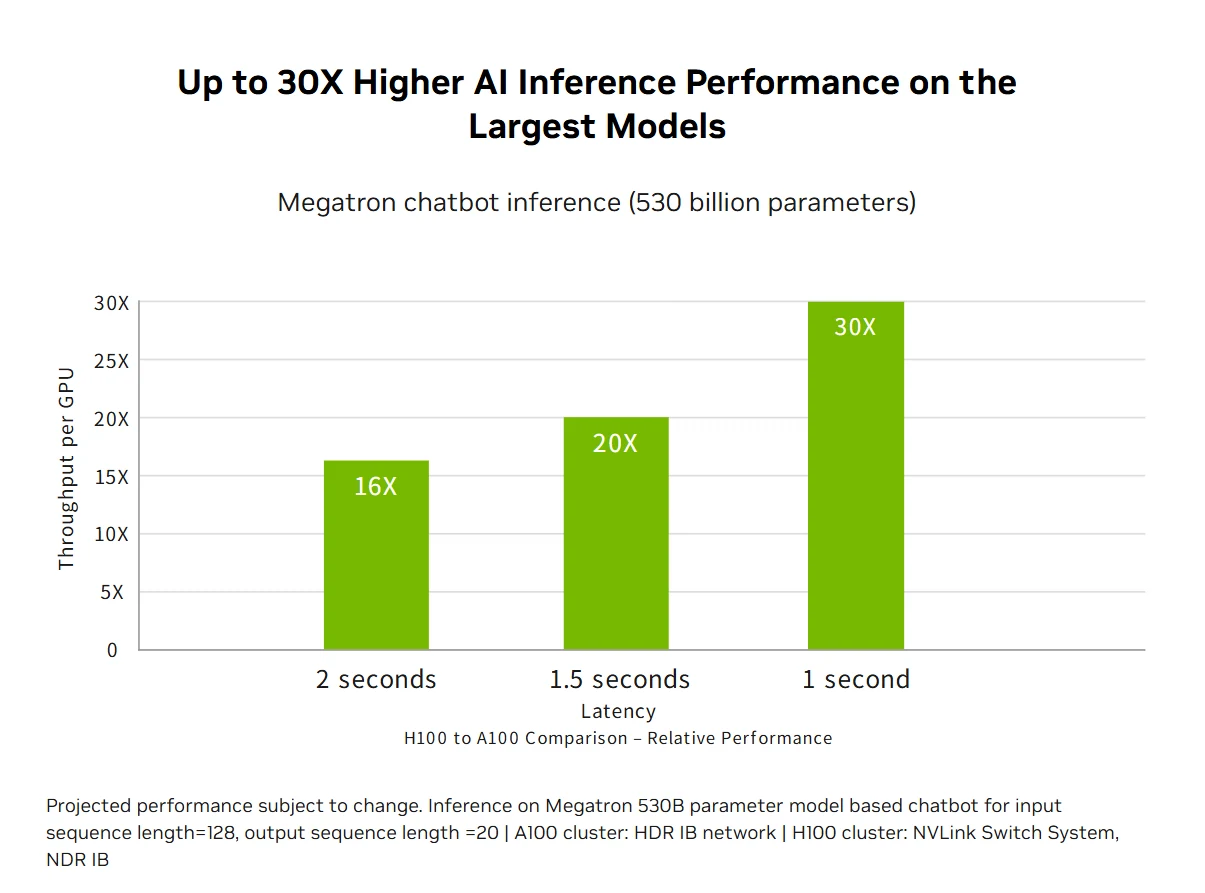
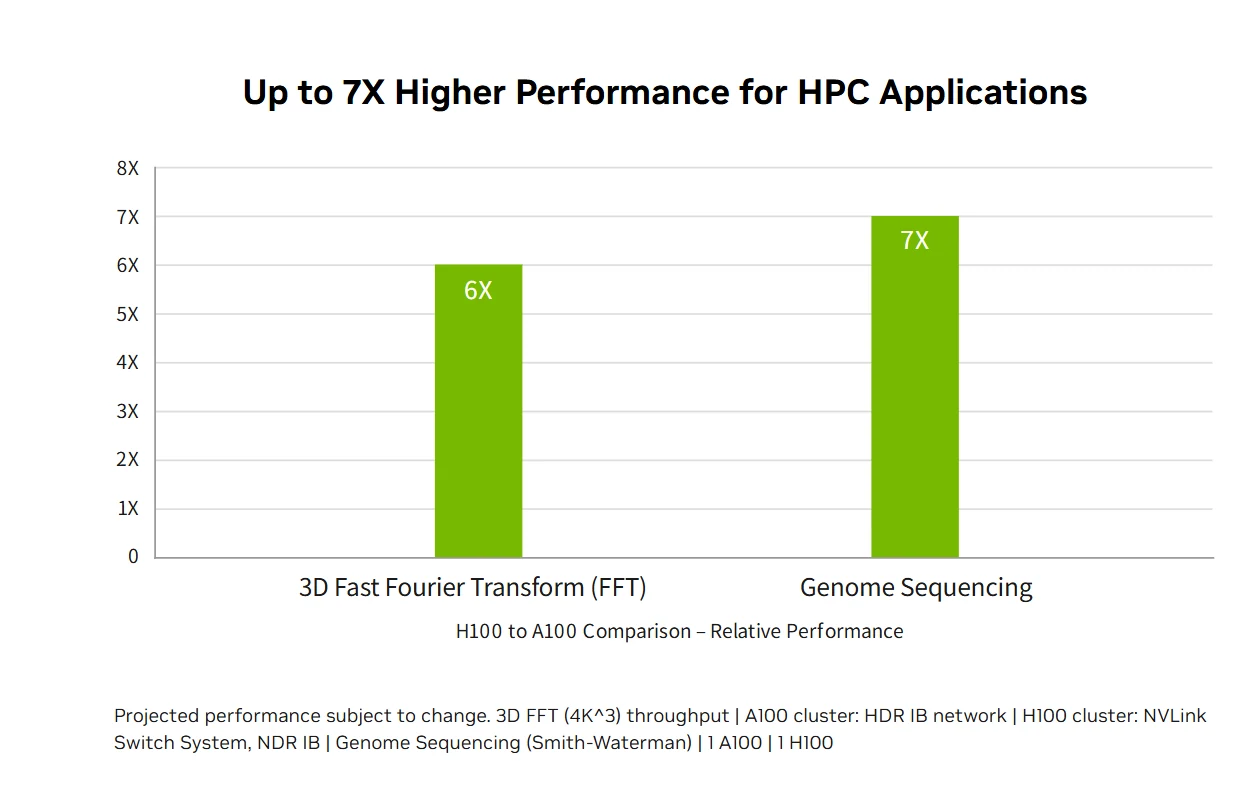
Exascale-HPC-Leistung: Die NVIDIA H100-Rechenzentrumsplattform liefert Exascale-HPC-Leistung, die das Mooresche Gesetz übertrifft, die Double-Precision-Berechnung auf 60 Teraflops FP64 verdreifacht und KI-fusionierte Anwendungen in die Lage versetzt, einen Durchsatz von einem Petaflop mit TF32-Präzision ohne Codeänderungen zu erreichen. Neue DPX-Anweisungen bieten eine 7-fache Beschleunigung gegenüber der A100 und eine 40-fache Beschleunigung gegenüber CPUs für dynamische Programmieralgorithmen wie die Smith-Waterman-DNA-Sequenzierung, kombinieren traditionelles HPC mit bahnbrechenden KI-Fähigkeiten und beschleunigen so wissenschaftliche Entdeckungen bei den wichtigsten Forschungsherausforderungen der Welt.
80 GB Speicher: Kapazitätsplanung für große Modelle
Die 80-GB-HBM3-Speicherkapazität bestimmt, welche Modelle vollständig in den GPU-Speicher passen.
Einzel-GPU-Bereitstellungen können Modelle mit bis zu etwa 70–75 Milliarden Parametern unter Verwendung von FP16-Präzision verarbeiten. Dazu gehören beliebte Modelle wie Llama 2 70B, Code Llama 70B und ähnliche Architekturen.
FP8-Präzision verdoppelt diese Kapazität effektiv und ermöglicht die Bereitstellung von Modellen mit bis zu 140–150 Milliarden Parametern auf einer einzelnen H100.
Multi-GPU-Skalierung wird für größere Modelle erforderlich. Mit Tensor-Parallelität können zwei H100 SXM GPUs Modelle mit bis zu 150 Milliarden Parametern in FP16 verarbeiten.
Vier GPUs ermöglichen das Training und die Inferenz von Modellen mit mehr als 300 Milliarden Parametern. Der hochbandbreitete NVLink-Interconnect gewährleistet eine effiziente Kommunikation zwischen den GPUs. Dadurch bleibt eine fast lineare Skalierungsleistung über mehrere Geräte hinweg erhalten.
Speicherintensive Anwendungen jenseits von Modellparametern umfassen große Kontextfenster für Sprachmodelle. Anwendungen, die Kontextfenster von mehr als 32K Tokens erfordern, profitieren besonders von dem großen Speicherpool der H100. Hochauflösende Bildverarbeitung und wissenschaftliche Datensätze nutzen ebenfalls die umfangreiche Speicherkapazität.
H100 SXM vs. PCIe: Leistungs- und Preisunterschiede
| Spezifikation | H100 SXM | H100 PCIe |
|---|---|---|
| CUDA-Kerne | 16.896 | 14.592 |
| Tensor Cores | 528 | 456 |
| GPU-Speicher | 80 GB HBM3 | 80 GB HBM2e |
| Speicherbandbreite | 3,35 TB/s | 2,0 TB/s |
| TF32-Leistung | 989 TFLOPS | 756 TFLOPS |
| FP16-Leistung | 1.979 TFLOPS | 1.513 TFLOPS |
| FP8-Leistung | 3.958 TFLOPS | 3.026 TFLOPS |
| Maximale TDP | 700 W | 350 W |
| Interconnect | NVLink 900 GB/s | NVLink 600 GB/s |
| Formfaktor | SXM5-Modul | PCIe-Dual-Slot |
Die SXM5-Variante hat einen Premiumpreis aufgrund ihrer überlegenen Architektur, die für maximale Leistungsdichte ausgelegt ist. Der SXM-Formfaktor wird direkt in spezielle Server-Motherboards integriert, was eine optimale Stromversorgung und Kühlung ermöglicht. Dieses Design bietet eine 67 % höhere Speicherbandbreite, 30 % mehr Tensor Cores und deutlich schnellere Multi-GPU-Kommunikation im Vergleich zur PCIe-Version.
H100 vs. A100: Welche GPU passt zu Ihrem Workload?
| Spezifikation | NVIDIA A100 | NVIDIA H100 SXM5 |
|---|---|---|
| Formfaktor | SXM4 | SXM5 |
| Streaming-Multiprozessoren (SMs) | 108 | 132 |
| TPCs | 54 | 66 |
| FP32-Kerne pro SM | 64 | 128 |
| Gesamtzahl FP32-Kerne | 6.912 | 16.896 |
| FP64-Kerne pro SM (ohne Tensor) | 32 | 64 |
| Gesamtzahl FP64-Kerne (ohne Tensor) | 3.456 | 8.448 |
| Tensor Cores | 432 | 528 |
| Speicherschnittstelle | 5120-Bit-HBM2 | 5120-Bit-HBM3 |
| Transistoren | 54,2 Milliarden | 80 Milliarden |
| Speicherbandbreite | 1.555 GB/s | 3.000 GB/s |
| Maximale TDP | 400 W | 700 W |
Die H100 bietet 2,4 Mal mehr Verarbeitungskerne, fast doppelt so hohe Speichergeschwindigkeit (3.000 vs. 1.555 GB/s) und 48 % mehr Transistoren als die A100. Allerdings verbraucht sie 75 % mehr Strom (700 W vs. 400 W).
Kostenvergleich von H100 und A100
| Anbieter/GPU-Modell | Spot-Preis | On-Demand |
|---|---|---|
| Novita AI H100 SXM 80 GB | 0,90 $/h | 1,80 $/h |
| RunPod H100 SXM 80 GB | 1,75 $/h | 2,69 $/h |
| Novita AI A100 SXM 80 GB | 0,80 $/h | 1,60 $/h |
| RunPod A100 SXM 80 GB | 0,95 $/h | 1,74 $/h |
Spot vs. On-Demand: Wann Sie welche Option wählen sollten
Wählen Sie Spot-Preise, wenn: Ihre Workloads gelegentliche Unterbrechungen verkraften können und Sie Entwicklungsarbeit durchführen. Spot-Preise eignen sich hervorragend für Trainingsläufe mit Checkpointing, Forschungsprojekte und kostensensitive Anwendungen. Die 50 %ige Ersparnis rechtfertigen gelegentliche Neustarts für die meisten Entwicklungs- und Batch-Verarbeitungsszenarien.
Wählen Sie On-Demand, wenn: Sie Produktions-Inferenzdienste betreiben oder zeitkritisches Training mit engen Fristen durchführen. On-Demand-Instanzen bieten konsistente Leistung ohne Unterbrechungsrisiko. Dies ist unerlässlich für kundenorientierte Anwendungen und geschäftskritische Workloads, die garantierte Verfügbarkeit erfordern.
Hybridstrategien: Viele Organisationen optimieren Kosten, indem sie Spot-Instanzen für Entwicklung und nicht geschäftskritische Workloads verwenden. Sie reservieren On-Demand-Kapazität für Produktionsdienste. Dieser Ansatz maximiert Kosteneinsparungen und gewährleistet gleichzeitig eine zuverlässige Servicebereitstellung dort, wo sie benötigt wird.
So finden Sie H100 SXM 80-GB-Spot-Instanzen bei Novita AI
Das Starten einer H100-Spot-Instanz bei Novita AI folgt dem gleichen optimierten Prozess, der sich bereits bei anderen GPU-Bereitstellungen bewährt hat.
Zugriff auf Ihre Konsole
Melden Sie sich bei Ihrer Novita AI GPU-Konsole an. Das Dashboard zeigt die Echtzeit-GPU-Verfügbarkeit, die aktuelle Spot-Instanz-Kapazität und Ihre letzten Bereitstellungen an. Diese Übersicht hilft Ihnen, fundierte Entscheidungen darüber zu treffen, wann und wo Sie Ihre Instanzen bereitstellen.
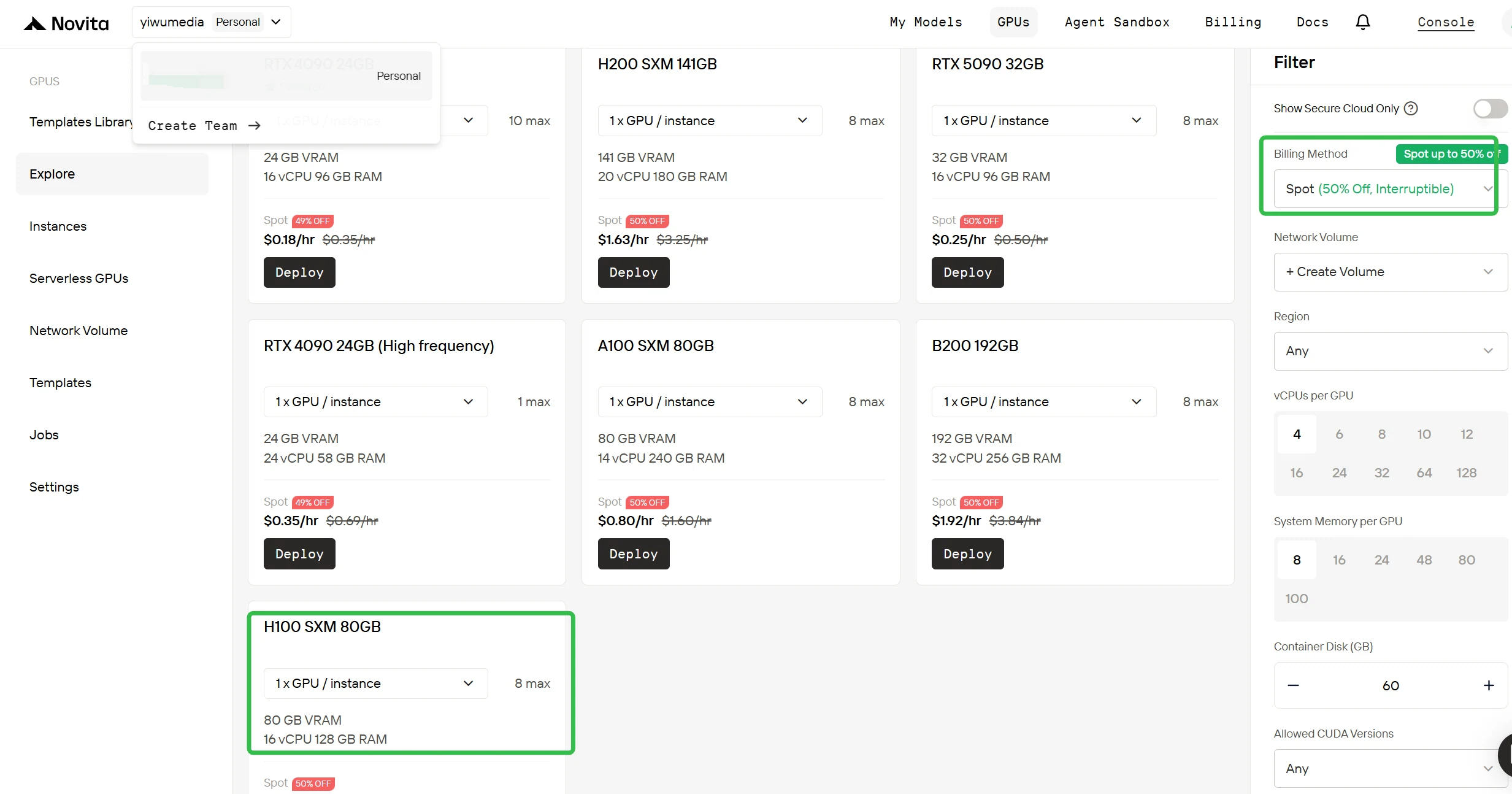
Wechseln Sie zur Spot-Abrechnung
Ändern Sie in der rechten Seitenleiste unter Filter die Abrechnungsmethode von „On-Demand“ zu „Spot“, um rabattierte Preise zu sehen. Die Oberfläche aktualisiert sich sofort und zeigt die H100 für 0,90 $/h an. Diese Transparenz stellt sicher, dass Sie genau wissen, was Sie vor der Bereitstellung zahlen.
Wie funktionieren Novita AI Spot-Instanzen?
Spot-Instanzen nutzen die freie GPU-Kapazität von Novita AI, die zu niedrigeren Preisen verfügbar gemacht wird, da sie zurückgefordert werden kann, wenn die Nachfrage nach regulären Instanzen steigt.
Wichtige Merkmale
Variable Verfügbarkeit: Spot-Instanzen können unterbrochen werden, wenn Novita AI die Kapazität zurückfordert. Dies bedeutet jedoch keine zufällige Beendigung – die Plattform folgt einem strukturierten Prozess mit Vorankündigungen.
Erhebliche Kosteneinsparungen: Greifen Sie auf die gleiche GPU-Leistung zu, die bis zu 50 % günstiger ist als On-Demand-Preise. Hardware und Leistung sind identisch; nur die Verfügbarkeitsgarantie unterscheidet sich.
Schutzzeitraum: Jede Spot-Instanz verfügt über ein 1-stündiges Schutzfenster nach dem Start. In dieser Zeit kann Ihre Instanz unabhängig von Kapazitätsanforderungen nicht unterbrochen werden.
Vorankündigungen: Sie erhalten Unterbrechungsbenachrichtigungen 1 Stunde vor der Rückforderung, zusätzlich gefolgt von einer 5-minütigen Warnung. Diese Benachrichtigungen ermöglichen es Ihnen, Arbeit zu speichern, Fortschritte zu checkpointen und Anwendungen ordnungsgemäß herunterzufahren.
Vergleich mit On-Demand-Instanzen
| Funktion | Spot-Instanzen | On-Demand-Instanzen |
|---|---|---|
| Preisgestaltung | Bis zu 50 % günstiger | Standardpreise |
| Verfügbarkeit | Kapazitätsabhängig | Immer verfügbar |
| Unterbrechungsrisiko | Kann mit Vorankündigung zurückgefordert werden | Keine Unterbrechungen |
| Schutzzeitraum | 1 Stunde nach dem Start | Dauerhaft |
| Anwendungsfall | Flexible, fehlertolerante Workloads | Kritische, unterbrechungsfreie Workloads |
Durch die Wahl von Spot-Instanzen für geeignete Workloads greifen Sie auf die gleichen leistungsstarken GPU-Ressourcen zu und optimieren gleichzeitig Ihre Rechenkosten.
Mehr erfahren: Novita AI-Leitfaden zu Spot-Instanzen
Optimale Workloads für die Bereitstellung von Spot-Instanzen
Entwicklungs- und Experimentier-Workloads stellen den idealen Anwendungsfall für Spot-Preise dar. Modellprototyping, Hyperparameter-Tuning und Forschungsexperimente können die Kosteneinsparungen nutzen und gleichzeitig gelegentliche Unterbrechungen akzeptieren. Diese Workloads profitieren typischerweise von Checkpointing-Strategien und können nach Unterbrechungen effizient fortgesetzt werden.
Batch-Verarbeitungs- und Trainingsjobs eignen sich hervorragend für Spot-Instanzen, wenn sie mit Fehlertoleranz ausgelegt sind. Große Datenverarbeitung, Modelltraining mit regelmäßigen Checkpoints und verteilte Rechenaufgaben können erhebliche Kosteneinsparungen erzielen. Moderne Deep-Learning-Frameworks wie PyTorch und TensorFlow verfügen über integrierte Checkpointing-Mechanismen, die sich nahtlos integrieren lassen.
Zeitflexible Workloads ohne strenge Fertigstellungsfristen maximieren die Vorteile von Spot-Preisen. Über-Nacht-Trainingsläufe, Wochenend-Batch-Verarbeitung und nicht geschäftskritische Inferenzaufgaben können ausschließlich Spot-Instanzen nutzen. Dies erreicht eine maximale Kostenoptimierung bei gleichbleibend hohen Leistungsstandards.
Fazit
Die NVIDIA H100 SXM 80 GB zum Spot-Preis von 0,90 $/h bei Novita AI stellt den kostengünstigsten Zugang zu erstklassiger KI-Beschleunigung dar, der heute verfügbar ist. Mit bahnbrechenden Leistungsverbesserungen gegenüber der A100 und umfassender Software-Stack-Integration ermöglicht dieses Angebot Unternehmen, anspruchsvolle KI-Workloads ohne Budgetbeschränkungen zu bewältigen. Die Kombination aus Tensor Cores der 4. Generation, 80 GB HBM3-Speicher und intelligentem Spot-Preismodell macht fortgeschrittene KI-Entwicklung zugänglich.
Ob Sie große Sprachmodelle trainieren, Computer-Vision-Anwendungen entwickeln oder wissenschaftliche Forschung betreiben – die H100 SXM liefert die Leistung, die für KI-Projekte der nächsten Generation benötigt wird. Beginnen Sie noch heute mit dem weltweit fortschrittlichsten KI-Beschleuniger zu arbeiten – stellen Sie Ihre H100 SXM 80-GB-Spot-Instanz bei Novita AI bereit und erleben Sie unübertroffene Leistung zu unschlagbaren Preisen.
Häufig gestellte Fragen
Was ist der Unterschied zwischen H100 SXM und PCIe? H100 SXM bietet überlegene Leistung mit 67 % höherer Speicherbandbreite (3,35 TB/s vs. 2,0 TB/s) und mehr Tensor Cores (528 vs. 456). Der SXM-Formfaktor wird direkt in Server-Motherboards integriert, was eine optimale Stromversorgung und Kühlung ermöglicht. PCIe-Versionen verwenden Standard-Erweiterungssteckplätze mit reduzierten Leistungsfähigkeiten.
Wie zuverlässig sind Spot-Instanzen für KI-Training? Die Spot-Instanzen von Novita AI verfügen über unternehmensweite Zuverlässigkeitsfunktionen, einschließlich 1-stündiger garantierter Schutzzeiträume. Benutzer erhalten 60-minütige Vorankündigungen von Unterbrechungen und 5-minütige Endwarnungen. Moderne KI-Frameworks unterstützen transparentes Checkpointing, sodass Trainingsjobs nach jeder Unterbrechung nahtlos fortgesetzt werden können.
Kann ich H100 SXM für Inferenz-Workloads verwenden? Absolut. H100 SXM zeichnet sich durch Inferenz-Workloads aus und liefert eine bis zu 30 Mal schnellere Leistung als vorherige Generationen. Die Transformer Engine und die FP8-Präzisionsunterstützung bieten einen außergewöhnlichen Durchsatz für Sprachmodelle. Der 80-GB-Speicher ermöglicht große Batch-Größen und komplexe Modellbereitstellungen, wodurch Spot-Preise sogar für reine Inferenzanwendungen kosteneffektiv sind.
Was passiert, wenn meine Spot-Instanz unterbrochen wird? Sie erhalten 60 Minuten vor der Unterbrechung eine Vorankündigung, gefolgt von einer 5-minütigen Endwarnung. Dies bietet ausreichend Zeit, um Arbeit zu speichern, Checkpoints zu erstellen und Anwendungen ordnungsgemäß herunterzufahren. Moderne KI-Frameworks verarbeiten Unterbrechungen automatisch über integrierte Checkpointing-Mechanismen, sodass ein sofortiger Neustart mit gespeicherten Checkpoints möglich ist.
Wie vergleicht sich die H100 mit der A100? Die H100 ist bis zu 6 Mal schneller beim Training und bis zu 30 Mal schneller bei der Inferenz als die A100, dank FP8-Unterstützung und der Transformer Engine. Außerdem hat sie eine Speicherbandbreite von 3,35 TB/s im Vergleich zu ~2 TB/s der A100, was Datenengpässe reduziert. Während die A100 für kleinere Jobs nach wie vor kosteneffizient ist, bietet die H100 eine bessere Leistung und niedrigere Gesamtkosten für große, zeitkritische Workloads.
Novita AI ist eine KI-Cloud-Plattform, die Entwicklern eine einfache Möglichkeit bietet, KI-Modelle über unsere einfache API bereitzustellen, und gleichzeitig eine erschwingliche und zuverlässige GPU-Cloud zum Erstellen und Skalieren bereitstellt.



