

- لماذا تعتبر H100 مثالية لتدريب واستدلال نماذج التعلم الآلي؟
- الفرق بين H100 SXM و PCIe: اختلافات الأداء والتسعير
- الفرق بين H100 و A100: أي وحدة معالجة رسوميات تناسب أعباء العمل الخاصة بك؟
- مقارنة تكلفة H100 و A100
- كيفية العثور على عناصر H100 SXM 80GB الفورية على منصة Novita AI
- كيف تعمل العناصر الفورية (Spot) لـ Novita AI؟
- أعباء العمل الذكية لنشر العناصر الفورية (Spot)
- الخلاصة
تمثل وحدة معالجة الرسوميات NVIDIA H100 SXM 80GB قمة تقنية تسريع الذكاء الاصطناعي. تقدم منصة Novita AI الآن هذه الوحدة المتميزة بسعر قياسي منخفض غير مسبوق يبلغ 0.90 دولار/ساعة عبر نظام التسعير الفوري (Spot Pricing). يجعل هذا السعر التنافسي أسرع مسرع ذكاء اصطناعي في العالم متاحًا للشركات والمطورين الذين يسعون لتحقيق أقصى أداء.
تقدم وحدة H100 أداءً استثنائيًا لتدريب نماذج اللغة الكبيرة، والرؤية الحاسوبية، وأعباء عمل الحوسبة عالية الأداء. بذاكرة HBM3 سعة 80 جيجابايت وقلوب Tensor من الجيل الرابع، توفر سرعة استدلال تصل إلى 30 ضعفًا مقارنة بالأجيال السابقة. يحافظ نموذج التسعير الفوري الذكي لـ Novita AI على الكفاءة من حيث التكلفة مع تقديم أداء مبتكر.
انشر عنصر H100 الفوري الخاص بك الآن
لماذا تعتبر H100 مثالية لتدريب واستدلال نماذج التعلم الآلي؟
بنية GPU جديدة بالكامل
تم بناء وحدة H100 SXM 80GB على بنية Hopper الثورية من NVIDIA. تحتوي على أكثر من 80 مليار ترانزستور في عقدة معالجة 5 نانومتر، مما يوفر أداءً غير مسبوق لأعباء عمل الذكاء الاصطناعي والحوسبة عالية الأداء (HPC). تتميز الوحدة بـ 16896 نواة CUDA، و528 قلب Tensor من الجيل الرابع، وذاكرة HBM3 عالية النطاق سعة 80 جيجابايت.
يوفر نظام الذاكرة نطاقًا ذاكريًا يبلغ 3.35 تيرابايت/ثانية للوصول السريع للغاية إلى البيانات. يقوم محول Transformer Engine المبتكر بالتبديل تلقائيًا بين دقة FP8 و FP16. يتيح ذلك زيادة تدفق البيانات تصل إلى 4 أضعاف مع الحفاظ على دقة النموذج للبنيات القائمة على Transformer.
أداء وحدة H100 عبر تطبيقات الذكاء الاصطناعي الرئيسية
تدريب الذكاء الاصطناعي التحويلي: تعمل قلوب Tensor من الجيل الرابع لـ H100 ومحرك Transformer Engine بدقة FP8 على تسريع تدريب الذكاء الاصطناعي يصل إلى 4 أضعاف مقارنة بالأجيال السابقة للنماذج الكبيرة مثل GPT-3. تتيح الوصلات المتقدمة بما في ذلك NVLink بسرعة 900 جيجابايت/ثانية و NDR InfiniBand التوسع الفعال من أنظمة المؤسسات إلى مجموعات GPU الضخمة، مما يجعل الحوسبة عالية الأداء من فئة إكساسكيل والذكاء الاصطناعي بمعامل تريليون متاحًا لجميع الباحثين.
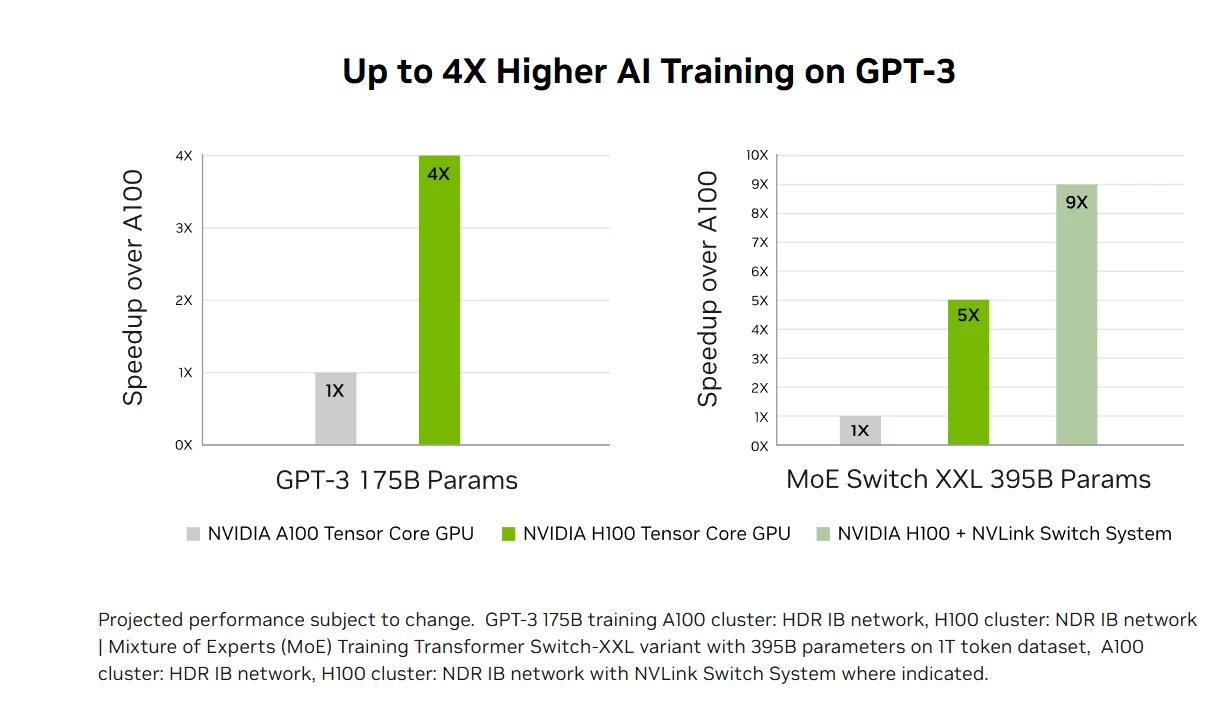
أداء استدلال الذكاء الاصطناعي المسرع: تقدم H100 أداء استدلال ذكاء اصطناعي رائدًا في السوق مع تسريع يصل إلى 30 ضعفًا وأدنى زمن استجابة عبر قلوب Tensor من الجيل الرابع التي تدعم جميع الدقائق من FP64 إلى تنسيق FP8 الجديد. تتيح هذه المرونة لـ H100 تسريع بنيات الشبكات العصبية المتنوعة عبر تطبيقات الأعمال مع تقليل استخدام الذاكرة والحفاظ على دقة نماذج اللغة الكبيرة، مما يجعلها حلاً شاملاً لتحديات استدلال التعلم العميق في الوقت الفعلي.
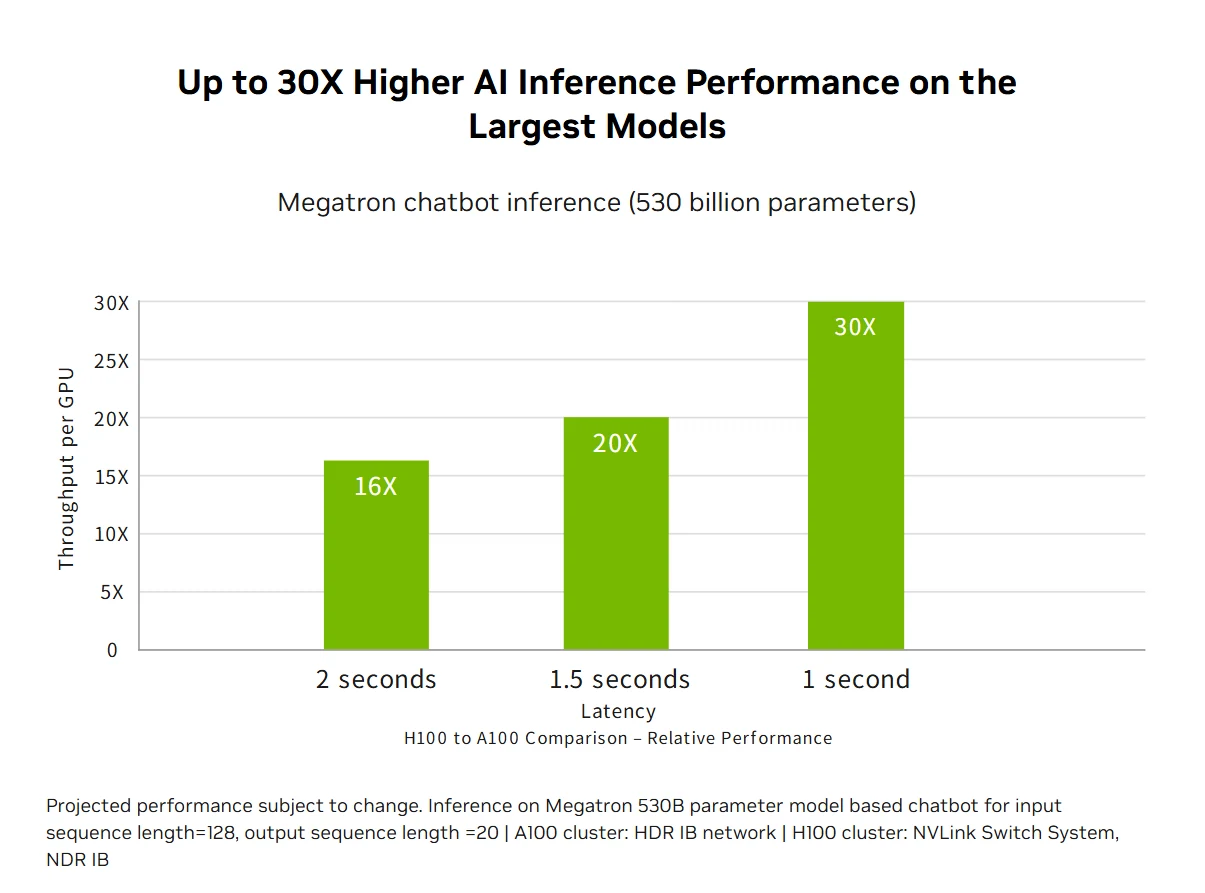
أداء الحوسبة عالية الأداء (HPC) من فئة إكساسكيل: تقدم منصة مركز بيانات NVIDIA H100 أداء HPC من فئة إكساسكيل يتجاوز قانون مور، حيث يضاعف الحوسبة ذات الدقة المزدوجة ثلاث مرات ليصل إلى 60 تيرافلوبس من نوع FP64، مع تمكين تطبيقات الذكاء الاصطناعي المدمجة من تحقيق تدفق بيانات يبلغ واحد بيتافلوبس باستخدام دقة TF32 دون أي تغييرات في الكود. توفر تعليمات DPX الجديدة تسريعًا يصل إلى 7 أضعاف مقارنة بـ A100 و 40 ضعفًا مقارنة بوحدات المعالجة المركزية (CPUs) لخوارزميات البرمجة الديناميكية مثل تسلسل الحمض النووي Smith-Waterman، مما يجمع بين HPC التقليدية وقدرات الذكاء الاصطناعي المبتكرة لتسريع الاكتشاف العلمي عبر أهم تحديات البحث في العالم.
ذاكرة 80 جيجابايت: تخطيط السعة للنماذج الكبيرة
تحدد سعة ذاكرة HBM3 البالغة 80 جيجابايت النماذج التي يمكن أن تناسب بالكامل في ذاكرة GPU.
عمليات نشر GPU واحدة يمكنها التعامل مع نماذج يصل عدد معاملاتها إلى حوالي 70-75 مليار معامل باستخدام دقة FP16. يتضمن ذلك النماذج الشائعة مثل Llama 2 70B، و Code Llama 70B، والبنيات المماثلة.
تضاعف دقة FP8 هذه السعة بشكل فعال، مما يتيح نشر نماذج يصل عدد معاملاتها إلى ما يقرب من 140-150 مليار معامل على وحدة H100 واحدة.
التوسع باستخدام وحدات GPU متعددة يصبح ضروريًا للنماذج الأكبر حجمًا. باستخدام tensor parallelism، يمكن لوحدتي GPU من نوع H100 SXM التعامل مع نماذج يصل عدد معاملاتها إلى 150 مليار معامل بدقة FP16.
تتيح أربع وحدات GPU تدريب واستدلال النماذج التي يتجاوز عدد معاملاتها 300 مليار معامل. يضمن موصل NVLink عالي النطاق اتصالًا فعالًا بين وحدات GPU. يحافظ ذلك على أداء توسع شبه خطي عبر الأجهزة المتعددة.
التطبيقات كثيفة الاستخدام للذاكرة التي تتجاوز معاملات النموذج تتضمن نوافذ سياق كبيرة لنماذج اللغة. تستفيد التطبيقات التي تتطلب نوافذ سياق تتجاوز 32 ألف رمز (token) بشكل خاص من تجمع الذاكرة الكبير لـ H100. تستفيد أيضًا معالجة الصور عالية الدقة ومجموعات البيانات العلمية من السعة الذاكرة الواسعة.
الفرق بين H100 SXM و PCIe: اختلافات الأداء والتسعير
| المواصفات | H100 SXM | H100 PCIe |
|---|---|---|
| نوى CUDA | 16,896 | 14,592 |
| قلوب Tensor | 528 | 456 |
| ذاكرة GPU | 80GB HBM3 | 80GB HBM2e |
| نطاق الذاكرة | 3.35TB/s | 2.0TB/s |
| أداء TF32 | 989 TFLOPS | 756 TFLOPS |
| أداء FP16 | 1,979 TFLOPS | 1,513 TFLOPS |
| أداء FP8 | 3,958 TFLOPS | 3,026 TFLOPS |
| أقصى TDP | 700W | 350W |
| الموصل | NVLink 900GB/s | NVLink 600GB/s |
| شكل النموذج | SXM5 Module | PCIe Dual-Slot |
يتميز متغير SXM5 بتسعير متميز بسبب بنيته الفائقة المصممة لأقصى كثافة أداء. يتكامل شكل النموذج SXM مباشرة في لوحات أم الخوادم المتخصصة، مما يتيح توصيل طاقة وتبريدًا مثاليين. يوفر هذا التصميم نطاق ذاكرة أعلى بنسبة 67٪، و30٪ المزيد من قلوب Tensor، واتصالًا أسرع بكثير بين وحدات GPU المتعددة مقارنة بإصدار PCIe.
الفرق بين H100 و A100: أي وحدة معالجة رسوميات تناسب أعباء العمل الخاصة بك؟
| المواصفات | NVIDIA A100 | NVIDIA H100 SXM5 |
|---|---|---|
| شكل النموذج | SXM4 | SXM5 |
| وحدات المعالجة المتدفقة (SMs) | 108 | 132 |
| TPCs | 54 | 66 |
| نوى FP32 لكل SM | 64 | 128 |
| إجمالي نوى FP32 | 6,912 | 16,896 |
| نوى FP64 لكل SM (باستثناء Tensor) | 32 | 64 |
| إجمالي نوى FP64 (باستثناء Tensor) | 3,456 | 8,448 |
| قلوب Tensor | 432 | 528 |
| واجهة الذاكرة | 5120-bit HBM2 | 5120-bit HBM3 |
| الترانزستورات | 54.2 مليار | 80 مليار |
| نطاق الذاكرة | 1,555 GB/s | 3,000 GB/s |
| أقصى TDP | 400 W | 700 W |
توفر H100 عددًا من النوى المعالجة يزيد بنسبة 2.4 ضعفًا، وسرعة ذاكرة تقارب الضعف (3000 مقابل 1555 جيجابايت/ثانية)، و48٪ المزيد من الترانزستورات مقارنة بـ A100. لكنها تستهلك 75٪ طاقة إضافية (700 واط مقابل 400 واط).
مقارنة تكلفة H100 و A100
| مزود الخدمة/نموذج GPU | التسعير الفوري (Spot) | عند الطلب (On-Demand) |
|---|---|---|
| Novita AI H100 SXM 80GB | 0.90 دولار/ساعة | 1.80 دولار/ساعة |
| RunPod H100 SXM 80GB | 1.75 دولار/ساعة | 2.69 دولار/ساعة |
| Novita AI A100 SXM 80GB | 0.80 دولار/ساعة | 1.60 دولار/ساعة |
| RunPod A100 SXM 80GB | 0.95 دولار/ساعة | 1.74 دولار/ساعة |
التسعير الفوري مقابل عند الطلب: متى تختار كل منهما؟
اختر التسعير الفوري (Spot) عندما: يمكن لأعباء العمل الخاصة بك التعامل مع انقطاعات عرضية، وتقوم بعمل تطوير. يعمل التسعير الفوري بشكل ممتاز لعمليات التدريب التي تحتوي على نقاط تفتيش (checkpointing)، ومشاريع البحث، والتطبيقات الحساسة للتكلفة. تبرر التوفير بنسبة 50٪ عمليات إعادة التشغيل العرضية لمعظم سيناريوهات التطوير ومعالجة الدفعات.
اختر التسعير عند الطلب (On-Demand) عندما: تقوم بتشغيل خدمات استدلال الإنتاج أو إجراء تدريب حساس للوقت مع مواعيد نهائية صارمة. توفر العناصر عند الطلب أداءً متسقًا دون خطر انقطاع. هذا ضروري للتطبيقات الموجهة للعملاء وأعباء العمل الحرجة التي تتطلب توفرًا مضمونًا.
الاستراتيجيات المختلطة: تعمل العديد من المؤسسات على تحسين التكاليف باستخدام العناصر الفورية (Spot) للتطوير وأعباء العمل غير الحرجة. تحجز سعة عند الطلب للخدمات الإنتاجية. تزيد هذه المقاربة من وفورات التكاليف إلى أقصى حد مع ضمان تسليم خدمات موثوقة حيثما دعت الحاجة.
كيفية العثور على عناصر H100 SXM 80GB الفورية على منصة Novita AI
يتبع إطلاق عنصر H100 الفوري على Novita AI نفس العملية المبسطة التي ثبت نجاحها مع عمليات نشر GPU الأخرى.
الوصول إلى وحدة التحكم الخاصة بك
قم بتسجيل الدخول إلى وحدة تحكم GPU لـ Novita AI. تعرض لوحة المعلومات توفر GPU في الوقت الفعلي، وسعة العناصر الفورية الحالية، وعمليات النشر الأخيرة الخاصة بك. تساعدك هذه النظرة العامة على اتخاذ قرارات مستنيرة حول وقت ومكان نشر عناصرك.
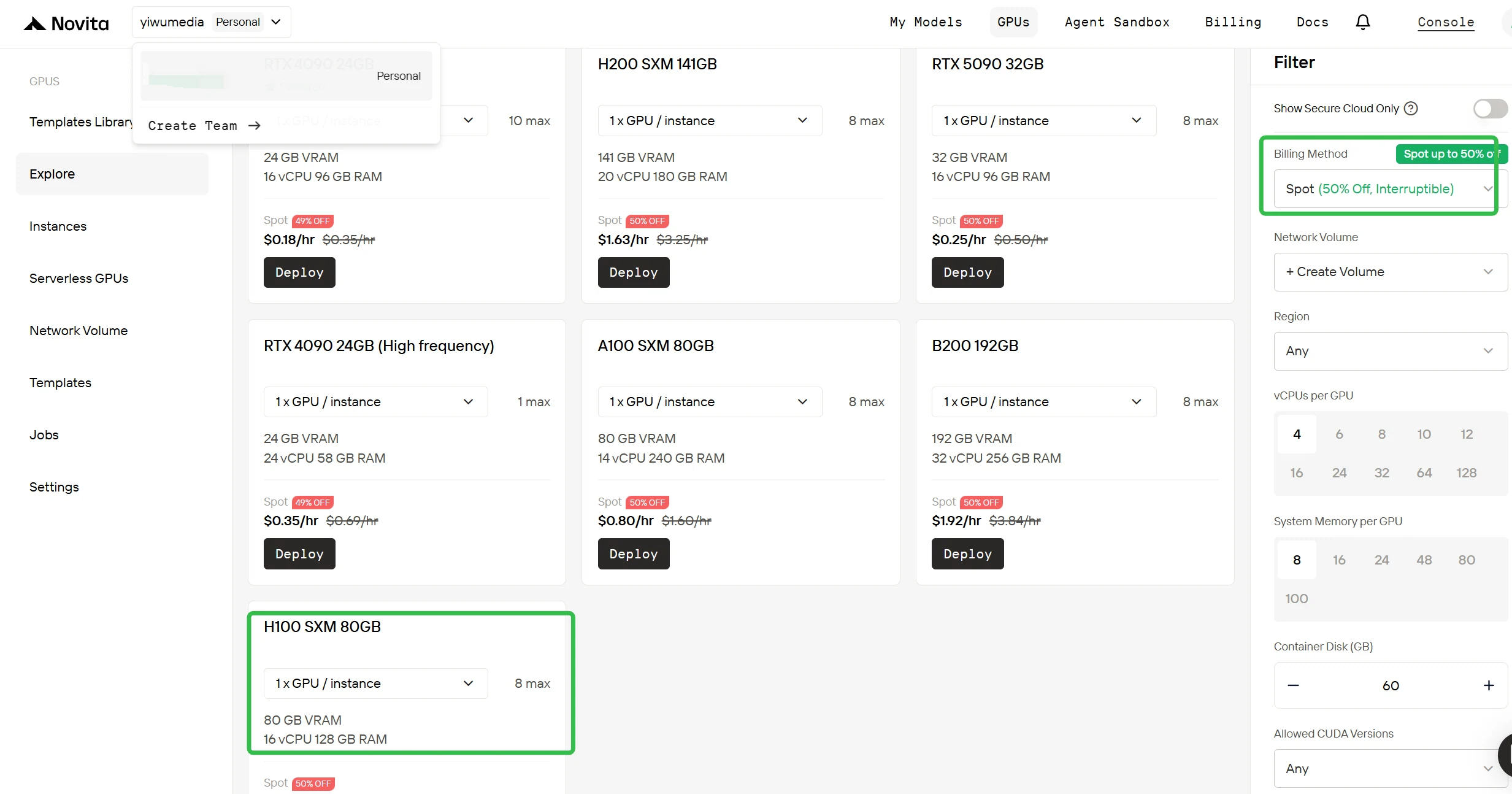
التبديل إلى الفوترة الفورية (Spot)
في الشريط الجانبي الأيمن تحت قسم التصفية، قم بتغيير طريقة الفوترة من “عند الطلب (On-Demand)” إلى “فوري (Spot)” لرؤية الأسعار المخفضة. يقوم الواجهة بالتحديث فورًا لعرض H100 بسعر 0.90 دولار/ساعة. تضمن هذه الشفافية أنك تعرف بالضبط ما تدفعه قبل النشر.
كيف تعمل العناصر الفورية (Spot) لـ Novita AI؟
تستخدم العناصر الفورية (Spot) سعة GPU الاحتياطية لـ Novita AI، مما يجعل هذه السعة متاحة بأسعار أقل لأنه يمكن استعادتها عندما يزيد الطلب على العناصر العادية.
الخصائص الرئيسية
توفر متغير: قد يتم مقاطعة العناصر الفورية (Spot) عندما تحتاج Novita AI إلى استعادة السعة. لكن هذا لا يعني إنهاءً عشوائيًا - تتبع المنصة عملية منظمة مع إشعارات مسبقة.
وفورات تكلفة كبيرة: احصل على نفس أداء GPU بأسعار أقل تصل إلى 50٪ مقارنة بأسعار عند الطلب. الأجهزة والأداء متطابقان؛ فقط ضمان التوفر يختلف.
فترة الحماية: يتضمن كل عنصر فوري (Spot) نافذة حماية مدتها ساعة واحدة بعد الإطلاق. خلال هذه الفترة، لا يمكن مقاطعة عنصرك بغض النظر عن متطلبات السعة.
إشعارات مسبقة: تتلقى إشعارات انقطاع قبل ساعة واحدة من الاستعادة، مع تحذير إضافي مدته 5 دقائق. تتيح لك هذه الإشعارات حفظ العمل، وإنشاء نقاط تفتيش، وإيقاف التطبيقات بشكل منظم.
مقارنة مع العناصر عند الطلب (On-Demand)
| الميزة | العناصر الفورية (Spot) | العناصر عند الطلب (On-Demand) |
|---|---|---|
| التسعير | أقل بنسبة تصل إلى 50٪ | الأسعار القياسية |
| التوفر | خاضع للسعة | متاح دائمًا |
| خطر الانقطاع | قد يتم استعادته مع إشعار | لا انقطاعات |
| فترة الحماية | ساعة واحدة بعد الإطلاق | مستمر |
| حالة الاستخدام | أعباء عمل مرنة ومتسامحة مع الأخطاء | أعباء عمل حرجة وغير قابلة للانقطاع |
باختيار العناصر الفورية (Spot) لأعباء العمل المناسبة، يمكنك الوصول إلى نفس موارد GPU القوية مع تحسين تكاليف الحوسبة.
معرفة المزيد: دليل العناصر الفورية (Spot) لـ Novita AI
أعباء العمل الذكية لنشر العناصر الفورية (Spot)
أعباء عمل التطوير والتجريب تمثل حالة الاستخدام المثالية للتسعير الفوري. يمكن لنمذجة النماذج الأولية، وضبط المعلمات الفائقة، وتجارب البحث الاستفادة من وفورات التكلفة مع قبول انقطاعات عرضية. تستفيد هذه الأعباء العمل عادةً من استراتيجيات نقاط التفتيح ويمكنها الاستئناف بكفاءة بعد الانقطاعات.
وظائف معالجة الدفعات والتدريب تعمل بشكل ممتاز مع العناصر الفورية عند تصميمها مع تحمل الأخطاء. يمكن لمعالجة البيانات على نطاق واسع، وتدريب النماذج مع نقاط تفتيش منتظمة، ومهام الحوسبة الموزعة تحقيق وفورات تكلفة كبيرة. تتضمن أطر التعلم العميق الحديثة مثل PyTorch و TensorFlow آليات نقاط تفتيش مدمجة تتكامل بسلاسة.
أعباء العمل المرنة من حيث الوقت التي لا تحتوي على مواعيد نهائية صارمة للإنجاز تعظم فوائد التسعير الفوري. يمكن لعمليات التدريب التي تعمل طوال الليل، ومعالجة الدفعات في عطلة نهاية الأسبوع، ومهام الاستدلال غير الحرجة استخدام العناصر الفورية حصريًا. يحقق ذلك أقصى تحسين للتكاليف مع الحفاظ على معايير أداء عالية.
الخلاصة
تمثل وحدة NVIDIA H100 SXM 80GB بسعر 0.90 دولار/ساعة كتسعير فوري على Novita AI الوصول الأكثر فعالية من حيث التكلفة إلى تسريع ذكاء اصطناعي متميز متاح اليوم. مع تحسينات أداء مبتكرة مقارنة بـ A100 وتكامل شامل لمكدس البرامج، يتيح هذا العرض للشركات التعامل مع أعباء عمل الذكاء الاصطناعي الصعبة دون قيود ميزانية. يجعل الجمع بين قلوب Tensor من الجيل الرابع، وذاكرة HBM3 سعة 80 جيجابايت، والتسعير الفوري الذكي من تطوير الذكاء الاصطناعي المتقدم متاحًا للجميع.
سواء كنت تدرب نماذج لغة كبيرة، أو تطور تطبيقات رؤية حاسوبية، أو تجري بحثًا علميًا، توفر H100 SXM الأداء المطلوب لمشاريع الذكاء الاصطناعي من الجيل التالي. ابدأ البناء اليوم باستخدام أسرع مسرع ذكاء اصطناعي في العالم - انشر عنصر H100 SXM 80GB الفوري الخاص بك على Novita AI واختبر أداءً لا مثيل له بأسعار لا تُضاهى.
الأسئلة الشائعة
ما هو الفرق بين H100 SXM و PCIe؟ تقدم H100 SXM أداءً فائقًا مع نطاق ذاكرة أعلى بنسبة 67٪ (3.35 تيرابايت/ثانية مقابل 2.0 تيرابايت/ثانية) وعدد أكبر من قلوب Tensor (528 مقابل 456). يتكامل شكل النموذج SXM مباشرة في لوحات أم الخوادم لتوصيل طاقة وتبريد مثاليين. تستخدم إصدارات PCIe فتحات توسيع قياسية مع قدرات أداء مخفضة.
ما مدى موثوقية العناصر الفورية لتدريب الذكاء الاصطناعي؟ تتضمن العناصر الفورية لـ Novita AI ميزات موثوقية من فئة المؤسسات بما في ذلك فترات حماية مضمونة مدتها ساعة واحدة. يتلقى المستخدمون إشعارات انقطاع مسبقة مدتها 60 دقيقة وتحذيرات نهائية مدتها 5 دقائق. تدعم أطر الذكاء الاصطناعي الحديثة نقاط التفتيش الشفافة، مما يتيح لوظائف التدريب الاستئناف بسلاسة بعد أي انقطاعات.
هل يمكنني استخدام H100 SXM لأعباء عمل الاستدلال؟ بالتأكيد. تتفوق H100 SXM في أعباء عمل الاستدلال، حيث توفر أداءً أسرع يصل إلى 30 ضعفًا مقارنة بالأجيال السابقة. يوفر محرك Transformer Engine ودعم دقة FP8 تدفقًا استثنائيًا لنماذج اللغة. تتيح الذاكرة سعة 80 جيجابايت أحجام دفعات كبيرة ونماذج معقدة للنشر، مما يجعل التسعير الفوري فعالاً من حيث التكلفة حتى للتطبيقات المخصصة للاستدلال فقط.
ماذا يحدث إذا تم مقاطعة عنصري الفوري؟ تتلقى إشعارًا مسبقًا مدته 60 دقيقة يليه تحذير نهائي مدته 5 دقائق قبل أي انقطاع. يوفر هذا وقتًا كافيًا لحفظ العمل، وإنشاء نقاط تفتيش، وإيقاف التطبيقات بشكل منظم. تتعامل أطر الذكاء الاصطناعي الحديثة تلقائيًا مع الانقطاعات من خلال آليات نقاط التفتيش المدمجة، مما يتيح إعادة الإطلاق فورًا باستخدام نقاط التفتيش المحفوظة.
كيف تقارن H100 بـ A100؟ تعتبر H100 أسرع حتى 6 أضعاف للتدريب و 30 ضعفًا للاستدلال مقارنة بـ A100، بفضل دعم FP8 ومحرك Transformer Engine. كما أن لديها نطاق ذاكرة يبلغ 3.35 تيرابايت/ثانية مقابل ~2 تيرابايت/ثانية لـ A100، مما يقلل من اختناقات البيانات. بينما لا تزال A100 فعالة من حيث التكلفة للوظائف الأصغر حجمًا، تقدم H100 أداءً أفضل وتكلفة إجمالية أقل لأعباء العمل الكبيرة والحساسة للوقت.
Novita AI هي منصة سحابة للذكاء الاصطناعي تقدم للمطورين طريقة سهلة لنشر نماذج الذكاء الاصطناعي باستخدام API البسيط الخاص بنا، مع توفير سحابة GPU بأسعار معقولة وموثوقة للبناء والتوسع.



