

- Por que a H100 é ideal para treinamento e inferência de ML?
- H100 SXM vs PCIe: diferenças de desempenho e preços
- H100 vs A100: qual GPU se adapta à sua carga de trabalho?
- Compare o custo da H100 e da A100
- Como encontrar instâncias spot H100 SXM 80GB na Novita AI
- Como funcionam as instâncias spot da Novita AI?
- Cargas de trabalho ideais para implantação de instâncias spot
- Conclusão
A NVIDIA H100 SXM 80GB representa o auge da tecnologia de aceleração de IA. A Novita AI agora oferece essa GPU premium a um preço sem precedentes de $0,90/hora por meio de preços spot. Essa taxa competitiva torna o acelerador de IA mais avançado do mundo acessível para empresas e desenvolvedores que buscam o máximo desempenho.
A H100 oferece desempenho excepcional para treinamento de modelos de linguagem grandes, visão computacional e cargas de trabalho de computação de alto desempenho. Com 80GB de memória HBM3 e Tensor Cores de 4ª geração, oferece inferência até 30x mais rápida do que as gerações anteriores. O modelo de preços spot inteligente da Novita AI mantém a eficiência de custos enquanto entrega desempenho revolucionário.
Implante sua instância spot H100 agora
Por que a H100 é ideal para treinamento e inferência de ML?
Uma arquitetura de GPU totalmente nova
A H100 SXM 80GB é construída sobre a arquitetura revolucionária Hopper da NVIDIA. Ela abriga mais de 80 bilhões de transistores em um nó de processo de 5nm, entregando desempenho sem precedentes para cargas de trabalho de IA e HPC. A GPU conta com 16.896 núcleos CUDA, 528 Tensor Cores de 4ª geração e 80GB de memória HBM3 de alta largura de banda.
O sistema de memória oferece largura de banda de 3,35TB/s para acesso a dados ultrarrápido. O Transformer Engine revolucionário alterna automaticamente entre as precisões FP8 e FP16. Isso permite até 4x mais throughput, mantendo a precisão do modelo para arquiteturas baseadas em transformer.
Desempenho da GPU H100 em principais aplicações de IA
Treinamento de IA transformacional: Os Tensor Cores de quarta geração da H100 e o Transformer Engine com precisão FP8 aceleram o treinamento de IA até 4x mais rápido do que as gerações anteriores para modelos grandes como o GPT-3. Interconexões avançadas, incluindo NVLink de 900 GB/s e InfiniBand NDR, permitem escalonamento eficiente de sistemas empresariais para clusters massivos de GPUs, tornando HPC exascale e IA com trilhões de parâmetros acessível para todos os pesquisadores.
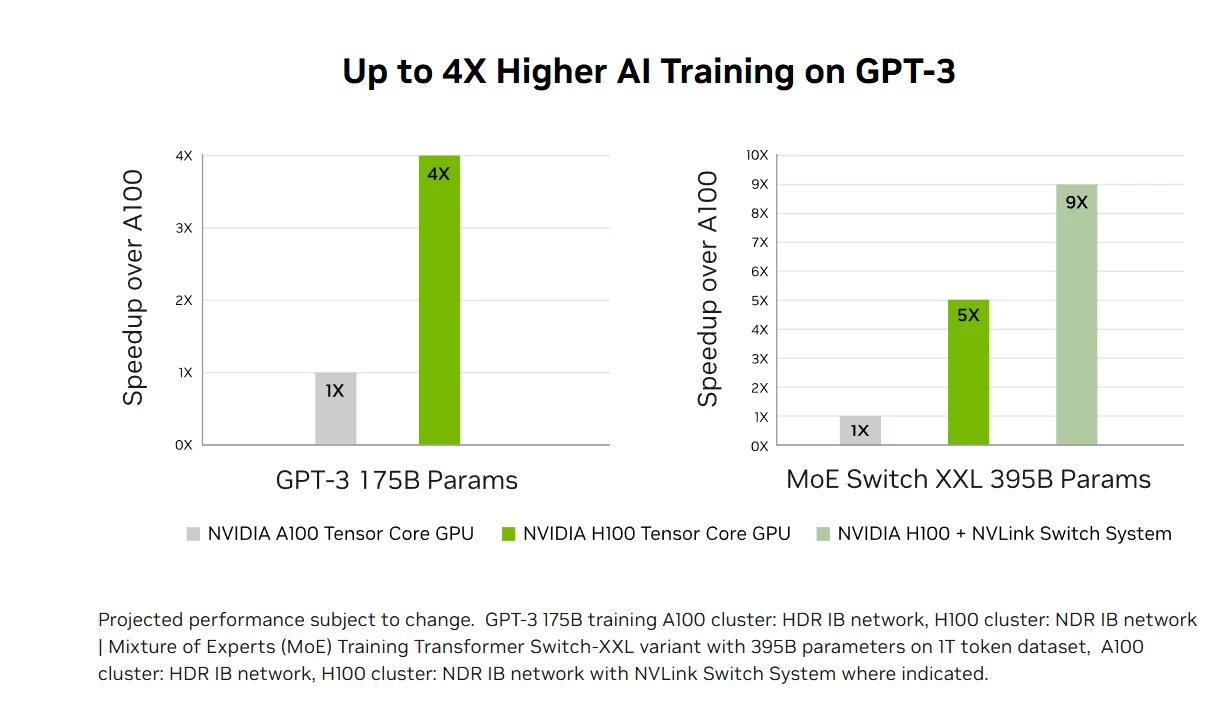
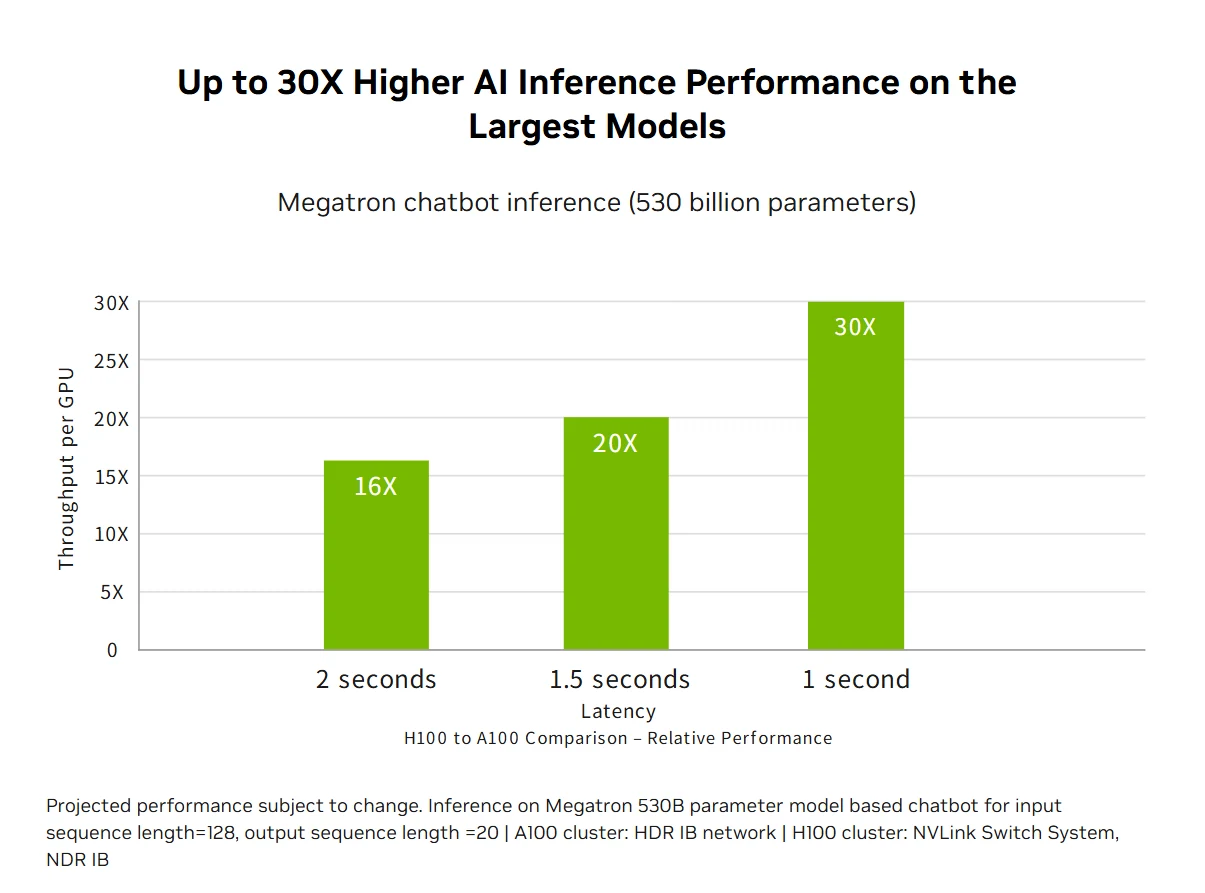
Desempenho de inferência de IA acelerado: A H100 oferece desempenho de inferência de IA líder de mercado com aceleração de até 30x e menor latência, graças aos Tensor Cores de quarta geração que suportam todas as precisões, de FP64 ao novo formato FP8. Essa versatilidade permite que a H100 acelere diversas arquiteturas de redes neurais em aplicações empresariais, reduzindo o uso de memória e mantendo a precisão para modelos de linguagem grandes, tornando-a uma solução completa para desafios de inferência de aprendizado profundo em tempo real.
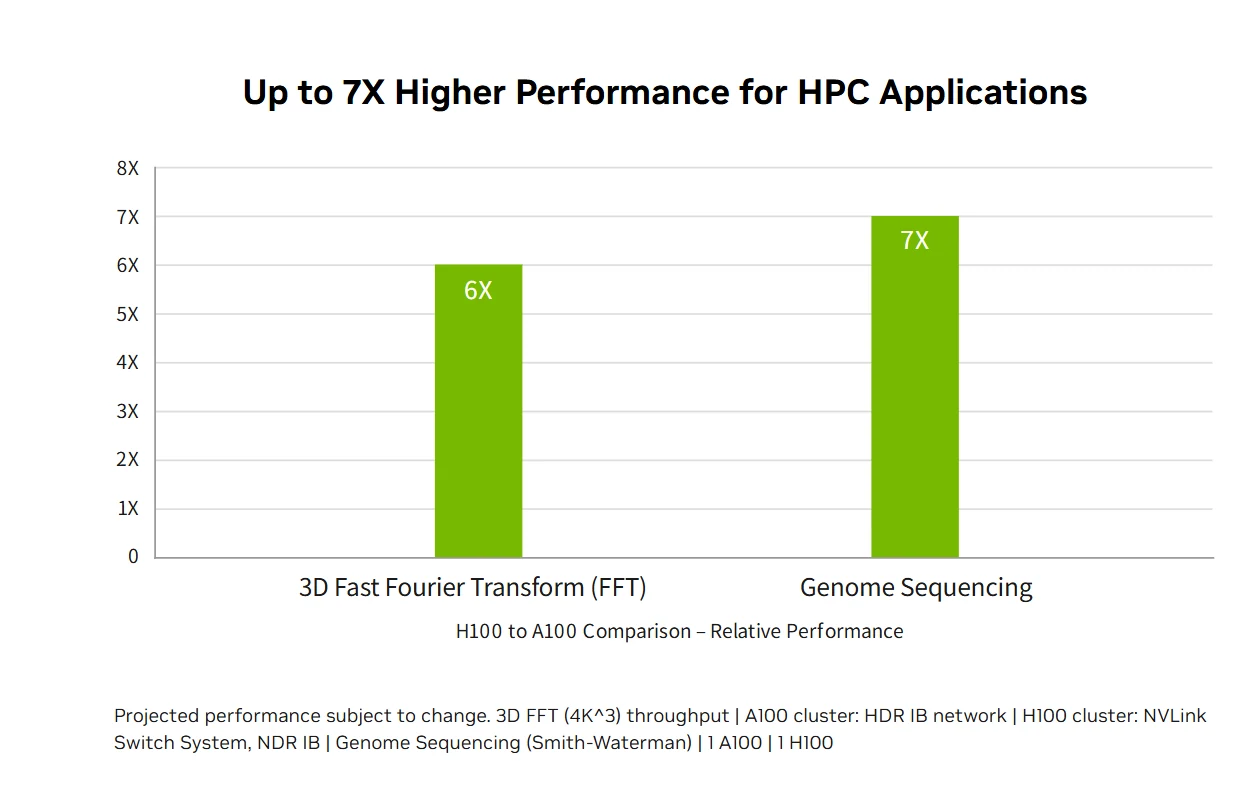
Desempenho HPC exascale: A plataforma de data center NVIDIA H100 oferece desempenho HPC exascale que supera a lei de Moore, triplicando a computação de dupla precisão para 60 teraflops FP64, além de permitir que aplicações fundidas com IA atinjam throughput de um petaflop usando precisão TF32 sem alterações de código. As novas instruções DPX oferecem aceleração de 7x em relação à A100 e 40x em relação a CPUs para algoritmos de programação dinâmica como a sequenciação de DNA Smith-Waterman, combinando HPC tradicional com capacidades revolucionárias de IA para acelerar descobertas científicas nos desafios de pesquisa mais importantes do mundo.
Memória de 80GB: planejamento de capacidade para modelos grandes
A capacidade de memória HBM3 de 80GB determina quais modelos cabem inteiramente na memória da GPU.
Implantações de GPU única podem lidar com modelos de até aproximadamente 70 a 75 bilhões de parâmetros usando precisão FP16. Isso inclui modelos populares como Llama 2 70B, Code Llama 70B e arquiteturas semelhantes.
A precisão FP8 dobra efetivamente essa capacidade, permitindo a implantação de modelos de até 140 a 150 bilhões de parâmetros em uma única H100.
Escalonamento multi-GPU se torna necessário para modelos maiores. Usando paralelismo de tensores, duas GPUs H100 SXM podem lidar com modelos de até 150 bilhões de parâmetros em FP16.
Quatro GPUs permitem o treinamento e a inferência de modelos com mais de 300 bilhões de parâmetros. A interconexão NVLink de alta largura de banda garante comunicação eficiente entre as GPUs. Isso mantém um desempenho de escalonamento quase linear em vários dispositivos.
Aplicações intensivas em memória além dos parâmetros do modelo incluem janelas de contexto grandes para modelos de linguagem. Aplicações que exigem janelas de contexto além de 32K tokens se beneficiam particularmente do grande pool de memória da H100. Processamento de imagens de alta resolução e conjuntos de dados científicos também aproveitam a extensa capacidade de memória.
H100 SXM vs PCIe: diferenças de desempenho e preços
| Especificação | H100 SXM | H100 PCIe |
|---|---|---|
| CUDA Cores | 16.896 | 14.592 |
| Tensor Cores | 528 | 456 |
| Memória da GPU | 80GB HBM3 | 80GB HBM2e |
| Largura de banda da memória | 3,35TB/s | 2,0TB/s |
| Desempenho TF32 | 989 TFLOPS | 756 TFLOPS |
| Desempenho FP16 | 1.979 TFLOPS | 1.513 TFLOPS |
| Desempenho FP8 | 3.958 TFLOPS | 3.026 TFLOPS |
| TDP máximo | 700W | 350W |
| Interconexão | NVLink 900GB/s | NVLink 600GB/s |
| Fator de forma | Módulo SXM5 | Slot duplo PCIe |
A variante SXM5 tem preço premium devido à sua arquitetura superior projetada para densidade máxima de desempenho. O fator de forma SXM se integra diretamente a placas-mãe de servidor especializadas, permitindo entrega ideal de energia e resfriamento. Esse design oferece 67% mais largura de banda de memória, 30% mais Tensor Cores e comunicação multi-GPU significativamente mais rápida em comparação com a versão PCIe.
H100 vs A100: qual GPU se adapta à sua carga de trabalho?
| Especificação | NVIDIA A100 | NVIDIA H100 SXM5 |
|---|---|---|
| Fator de forma | SXM4 | SXM5 |
| Multiprocessadores de streaming (SMs) | 108 | 132 |
| TPCs | 54 | 66 |
| Núcleos FP32 por SM | 64 | 128 |
| Total de núcleos FP32 | 6.912 | 16.896 |
| Núcleos FP64 por SM (excl. Tensor) | 32 | 64 |
| Total de núcleos FP64 (excl. Tensor) | 3.456 | 8.448 |
| Tensor Cores | 432 | 528 |
| Interface de memória | 5120-bit HBM2 | 5120-bit HBM3 |
| Transistores | 54,2 bilhões | 80 bilhões |
| Largura de banda da memória | 1.555 GB/s | 3.000 GB/s |
| TDP máximo | 400 W | 700 W |
A H100 oferece 2,4x mais núcleos de processamento, quase o dobro da velocidade de memória (3.000 vs 1.555 GB/s) e 48% mais transistores do que a A100. No entanto, consome 75% mais energia (700W vs 400W).
Compare o custo da H100 e da A100
| Provedor/Modelo de GPU | Preço spot | Sob demanda |
|---|---|---|
| Novita AI H100 SXM 80GB | $0,90/hora | $1,80/hora |
| RunPod H100 SXM 80GB | $1,75/hora | $2,69/hora |
| Novita AI A100 SXM 80GB | $0,80/hora | $1,60/hora |
| RunPod A100 SXM 80GB | $0,95/hora | $1,74/hora |
Spot vs Sob demanda: quando escolher cada um
Escolha preço spot quando: Suas cargas de trabalho podem lidar com interrupções ocasionais, e você está realizando trabalho de desenvolvimento. O preço spot funciona excepcionalmente para execuções de treinamento com checkpointing, projetos de pesquisa e aplicações sensíveis a custos. A economia de 50% justifica reinicializações ocasionais para a maioria dos cenários de desenvolvimento e processamento em lote.
Escolha sob demanda quando: Executar serviços de inferência de produção ou realizar treinamento com prazo crítico e prazos apertados. As instâncias sob demanda oferecem desempenho consistente sem risco de interrupção. Isso é essencial para aplicações voltadas para o cliente e cargas de trabalho críticas que exigem disponibilidade garantida.
Estratégias híbridas: Muitas organizações otimizam custos usando instâncias spot para desenvolvimento e cargas de trabalho não críticas. Elas reservam capacidade sob demanda para serviços de produção. Essa abordagem maximiza a economia de custos enquanto garante a entrega confiável de serviços onde necessário.
Como encontrar instâncias spot H100 SXM 80GB na Novita AI
Lançar uma instância spot H100 na Novita AI segue o mesmo processo simplificado que se mostrou bem-sucedido em outras implantações de GPU.
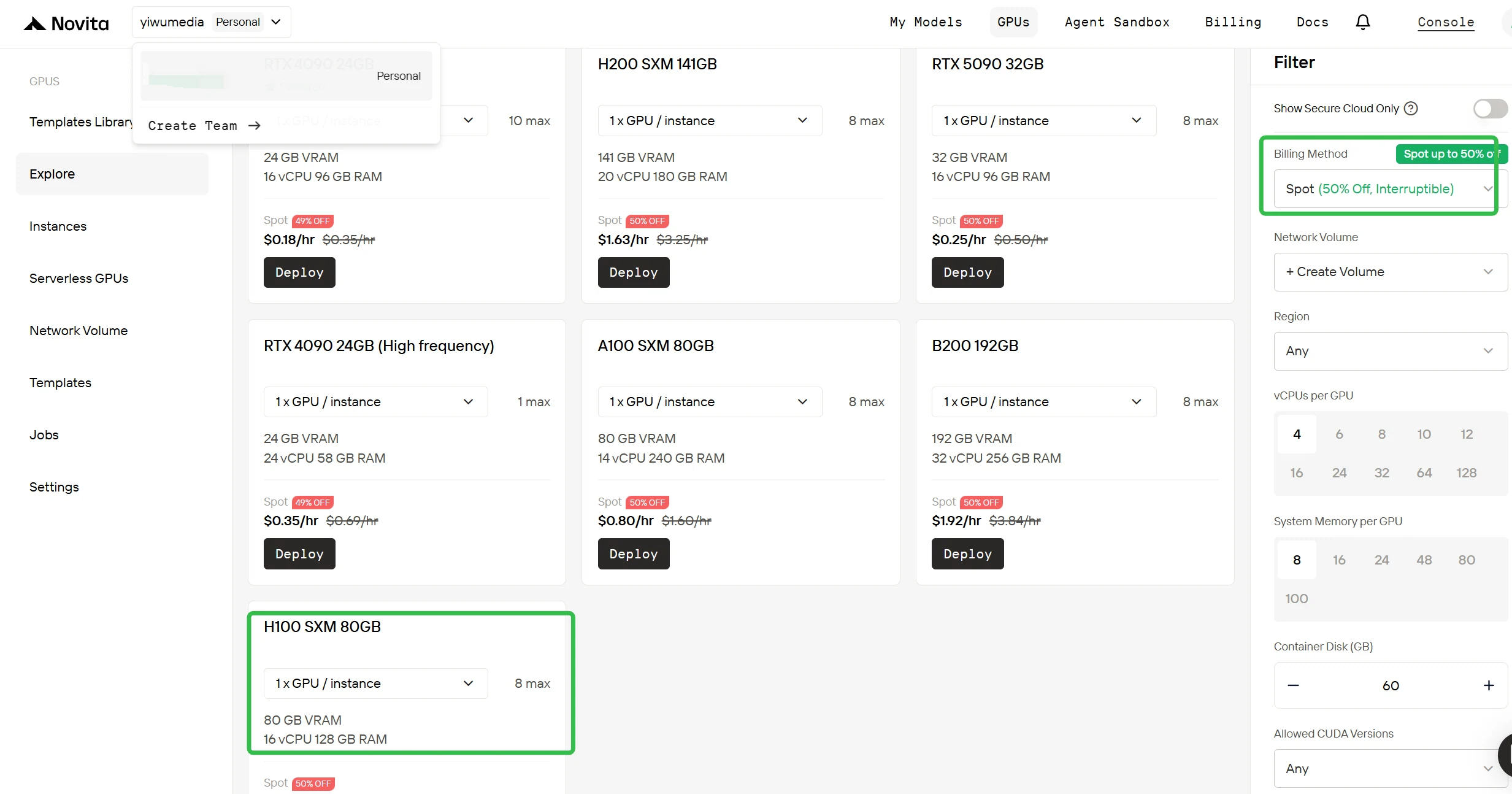
Acesse seu console
Faça login no seu Console de GPU da Novita AI. O painel exibe a disponibilidade de GPUs em tempo real, a capacidade atual de instâncias spot e suas implantações recentes. Essa visão geral ajuda você a tomar decisões informadas sobre quando e onde implantar suas instâncias.
Alterne para faturamento spot
Na barra lateral direita, em Filtro, altere o método de faturamento de “Sob demanda” para “Spot” para ver os preços com desconto. A interface é atualizada imediatamente para mostrar a H100 a $0,90/hora. Essa transparência garante que você saiba exatamente o que está pagando antes da implantação.
Como funcionam as instâncias spot da Novita AI?
As instâncias spot utilizam a capacidade de GPU spare da Novita AI, disponibilizando essa capacidade a preços mais baixos, pois ela pode ser recuperada quando a demanda por instâncias regulares aumenta.
Características principais
Disponibilidade variável: As instâncias spot podem ser interrompidas quando a Novita AI precisar da capacidade de volta. No entanto, isso não significa encerramento aleatório: a plataforma segue um processo estruturado com notificações prévias.
Economia de custos significativa: Acesse o mesmo desempenho de GPU com até 50% menos do que os preços sob demanda. O hardware e o desempenho são idênticos; apenas a garantia de disponibilidade difere.
Período de proteção: Cada instância spot inclui uma janela de proteção de 1 hora após o lançamento. Durante esse período, sua instância não pode ser interrompida, independentemente das demandas de capacidade.
Notificações prévias: Receba notificações de interrupção 1 hora antes da recuperação, com um aviso adicional de 5 minutos. Essas notificações permitem que você salve o trabalho, crie checkpoints de progresso e encerre os aplicativos de forma graceful.
Comparação com instâncias sob demanda
| Recurso | Instâncias spot | Instâncias sob demanda |
|---|---|---|
| Preço | Até 50% menos | Taxas padrão |
| Disponibilidade | Sujeita à capacidade | Sempre disponível |
| Risco de interrupção | Pode ser recuperada com aviso | Sem interrupções |
| Período de proteção | 1 hora após o lançamento | Contínuo |
| Caso de uso | Cargas de trabalho flexíveis e tolerantes a falhas | Cargas de trabalho críticas e ininterruptas |
Ao escolher instâncias spot para cargas de trabalho adequadas, você acessa os mesmos recursos de GPU poderosos enquanto otimiza os custos de computação.
Saiba mais: Guia de instâncias spot da Novita AI
Cargas de trabalho ideais para implantação de instâncias spot
Cargas de trabalho de desenvolvimento e experimentação representam o caso de uso ideal para preços spot. Criação de protótipos de modelos, ajuste de hiperparâmetros e experimentos de pesquisa podem aproveitar a economia de custos enquanto aceitam interrupções ocasionais. Essas cargas de trabalho geralmente se beneficiam de estratégias de checkpointing e podem retomar o funcionamento de forma eficiente após interrupções.
Processamento em lote e treinamento funcionam excepcionalmente com instâncias spot quando projetados com tolerância a falhas. Processamento de dados em larga escala, treinamento de modelos com checkpoints regulares e tarefas de computação distribuída podem alcançar economia de custos significativa. Frameworks modernos de aprendizado profundo como PyTorch e TensorFlow incluem mecanismos de checkpointing integrados que funcionam perfeitamente.
Cargas de trabalho com horário flexível sem prazos de conclusão rigorosos maximizam os benefícios dos preços spot. Execuções de treinamento noturnas, processamento em lote de fim de semana e tarefas de inferência não críticas podem usar instâncias spot exclusivamente. Isso alcança a máxima otimização de custos enquanto mantém padrões de alto desempenho.
Conclusão
A NVIDIA H100 SXM 80GB com preço spot de $0,90/hora na Novita AI representa o acesso mais econômico a aceleração de IA premium disponível hoje. Com melhorias de desempenho revolucionárias em relação à A100 e integração abrangente com a pilha de software, essa oferta permite que empresas lidem com cargas de trabalho de IA exigentes sem restrições orçamentárias. A combinação de Tensor Cores de 4ª geração, memória HBM3 de 80GB e preços spot inteligentes torna o desenvolvimento avançado de IA acessível.
Seja treinando modelos de linguagem grandes, desenvolvendo aplicações de visão computacional ou realizando pesquisa científica, a H100 SXM entrega o desempenho necessário para projetos de IA de próxima geração. Comece a construir com o acelerador de IA mais avançado do mundo hoje — implante sua instância spot H100 SXM 80GB na Novita AI e experimente um desempenho incomparável a preços imbatíveis.
Perguntas frequentes
Qual a diferença entre a H100 SXM e a PCIe? A H100 SXM oferece desempenho superior com 67% mais largura de banda de memória (3,35TB/s vs 2,0TB/s) e mais Tensor Cores (528 vs 456). O fator de forma SXM se integra diretamente a placas-mãe de servidor para entrega ideal de energia e resfriamento. As versões PCIe usam slots de expansão padrão com capacidades de desempenho reduzidas.
Quão confiáveis são as instâncias spot para treinamento de IA? As instâncias spot da Novita AI incluem recursos de confiabilidade de nível empresarial, incluindo períodos de proteção garantidos de 1 hora. Os usuários recebem notificações de interrupção prévia de 60 minutos e avisos finais de 5 minutos. Frameworks modernos de IA suportam checkpointing transparente, permitindo que trabalhos de treinamento retomem de forma contínua após qualquer interrupção.
Posso usar a H100 SXM para cargas de trabalho de inferência? Com certeza. A H100 SXM se destaca em cargas de trabalho de inferência, oferecendo desempenho até 30x mais rápido do que as gerações anteriores. O Transformer Engine e o suporte a precisão FP8 oferecem throughput excepcional para modelos de linguagem. A memória de 80GB permite tamanhos de lote grandes e implantações de modelos complexas, tornando o preço spot econômico mesmo para aplicações exclusivas de inferência.
O que acontece se minha instância spot for interrompida? Você recebe uma notificação prévia de 60 minutos, seguida de um aviso final de 5 minutos antes de qualquer interrupção. Isso fornece tempo suficiente para salvar o trabalho, criar checkpoints e encerrar os aplicativos de forma graceful. Frameworks modernos de IA lidam automaticamente com interrupções por meio de mecanismos de checkpointing integrados, permitindo o relançamento imediato com checkpoints salvos.
Como a H100 se compara à A100? A H100 é até 6x mais rápida para treinamento e 30x mais rápida para inferência do que a A100, graças ao suporte a FP8 e ao Transformer Engine. Ela também tem largura de banda de memória de 3,35TB/s contra os ~2TB/s da A100, reduzindo gargalos de dados. Embora a A100 ainda seja econômica para trabalhos menores, a H100 oferece melhor desempenho e custo total menor para cargas de trabalho grandes e sensíveis ao tempo.
Novita AI é uma plataforma de nuvem de IA que oferece aos desenvolvedores uma maneira fácil de implantar modelos de IA usando nossa API simples, além de fornecer uma nuvem de GPU acessível e confiável para construir e escalar.



