

- Pourquoi le H100 est-il idéal pour l'entraînement et l'inférence en ML ?
- H100 SXM vs PCIe : différences de performances et de tarification
- H100 vs A100 : quel GPU correspond à votre charge de travail ?
- Comparaison des coûts du H100 et de l'A100
- Comment trouver des instances spot H100 SXM 80 Go sur Novita AI
- Comment fonctionnent les instances spot Novita AI ?
- Charges de travail adaptées au déploiement d'instances spot
- Conclusion
Le NVIDIA H100 SXM 80 Go représente le summum de la technologie d’accélération IA. Novita AI propose désormais ce GPU haut de gamme à un tarif sans précédent de 0,90 $/h via la tarification spot. Ce tarif compétitif rend l’accélérateur IA le plus avancé au monde accessible aux entreprises et aux développeurs à la recherche de performances maximales.
Le H100 offre des performances exceptionnelles pour l’entraînement de modèles de langage volumineux, la vision par ordinateur et les charges de travail de calcul haute performance. Doté de 80 Go de mémoire HBM3 et de cœurs Tensor de 4e génération, il permet une inférence jusqu’à 30 fois plus rapide que les générations précédentes. Le modèle de tarification spot intelligent de Novita AI maintient une efficacité des coûts tout en offrant des performances révolutionnaires.
Déployez votre instance spot H100 dès maintenant
Pourquoi le H100 est-il idéal pour l’entraînement et l’inférence en ML ?
Une architecture GPU entièrement nouvelle
Le H100 SXM 80 Go est basé sur l’architecture Hopper révolutionnaire de NVIDIA. Il intègre plus de 80 milliards de transistors sur un nœud de processus de 5 nm, offrant des performances sans précédent pour les charges de travail IA et HPC. Le GPU dispose de 16 896 cœurs CUDA, 528 cœurs Tensor de 4e génération et 80 Go de mémoire HBM3 à haute bande passante.
Le système mémoire offre une bande passante de 3,35 To/s pour un accès aux données ultra-rapide. Le Transformer Engine révolutionnaire bascule automatiquement entre les précisions FP8 et FP16. Cela permet un débit jusqu’à 4 fois plus élevé tout en maintenant la précision des modèles pour les architectures basées sur des transformateurs.
Performances du GPU H100 sur les principales applications IA
Entraînement IA transformationnel : Les cœurs Tensor de 4e génération du H100 et le Transformer Engine avec précision FP8 accélèrent l’entraînement IA jusqu’à 4 fois plus vite que les générations précédentes pour les grands modèles comme GPT-3. Les interconnexions avancées, notamment NVLink à 900 Go/s et InfiniBand NDR, permettent une mise à l’échelle efficace des systèmes d’entreprise aux clusters GPU massifs, rendant le HPC exascale et l’IA à billions de paramètres accessibles à tous les chercheurs.
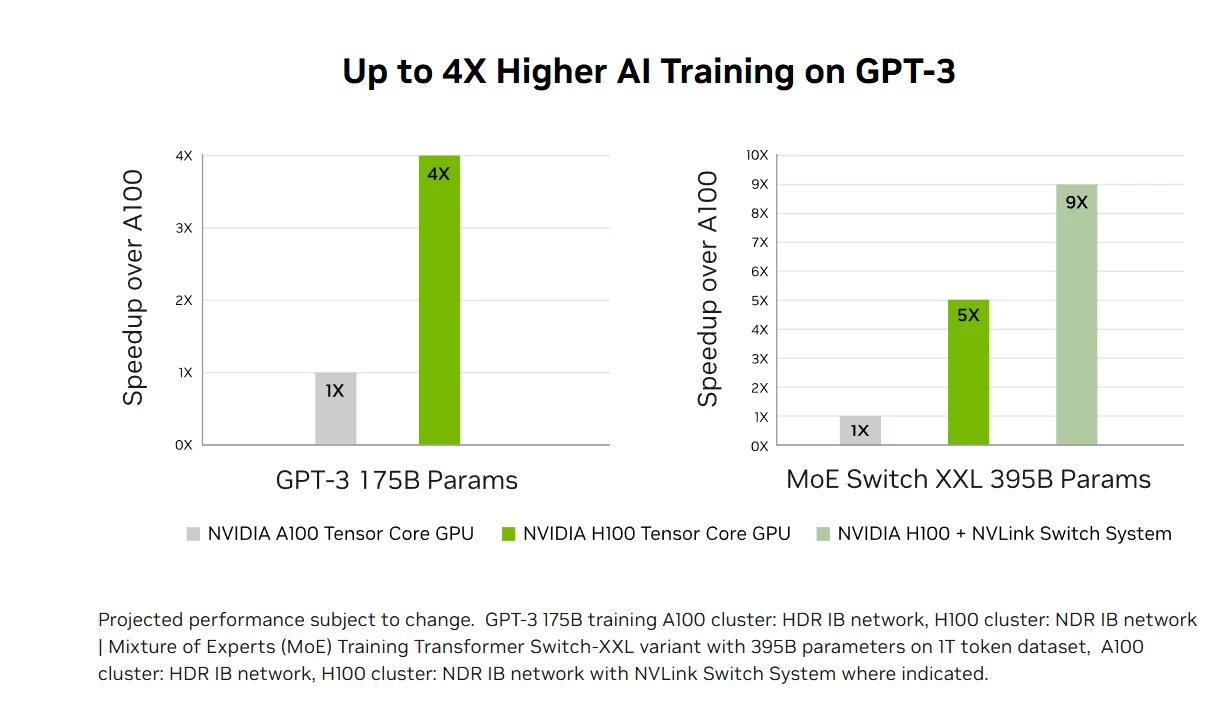
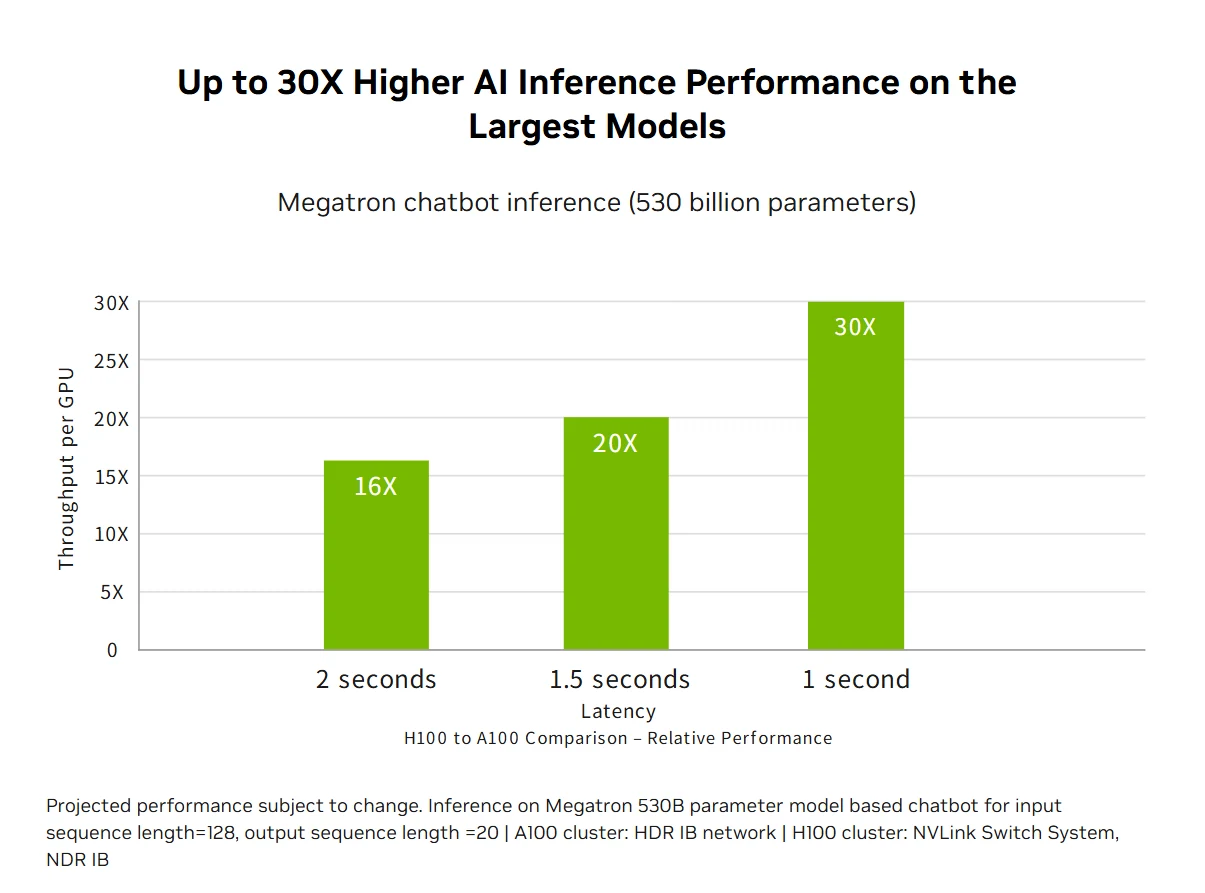
Performances d’inférence IA accélérées : Le H100 offre des performances d’inférence IA leaders sur le marché, avec une accélération jusqu’à 30X et la latence la plus faible grâce aux cœurs Tensor de 4e génération qui prennent en charge toutes les précisions de FP64 au nouveau format FP8. Cette polyvalence permet au H100 d’accélérer diverses architectures de réseaux de neurones dans les applications professionnelles tout en réduisant l’utilisation de la mémoire et en maintenant la précision des grands modèles de langage, ce qui en fait une solution complète pour les défis d’inférence d’apprentissage profond en temps réel.
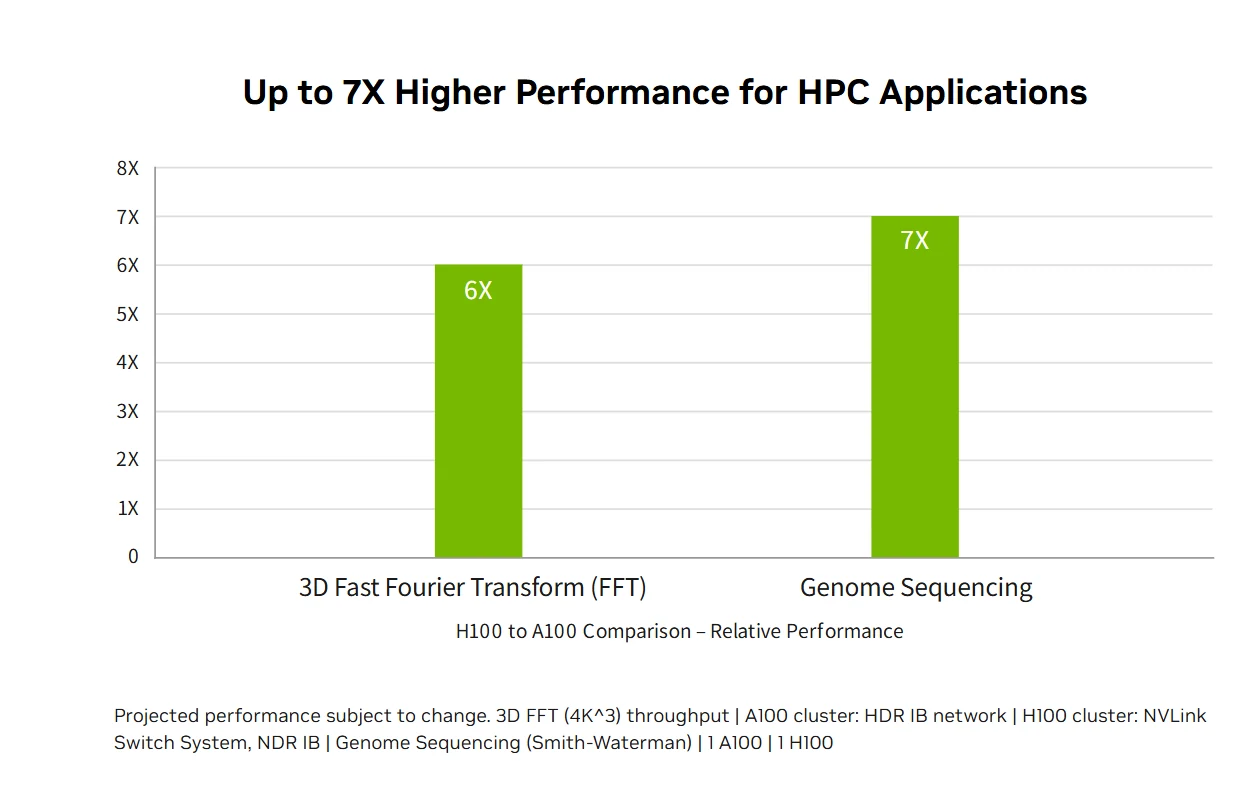
Performances HPC exascale : La plateforme de centre de données NVIDIA H100 offre des performances HPC exascale qui dépassent la loi de Moore, triplant la puissance de calcul en double précision à 60 téraflops FP64 tout en permettant aux applications fusionnées à l’IA d’atteindre un débit d’un pétaflop en utilisant la précision TF32 sans aucune modification de code. Les nouvelles instructions DPX offrent des accélérations 7X supérieures à l’A100 et 40X supérieures aux CPU pour les algorithmes de programmation dynamique comme le séquençage d’ADN Smith-Waterman, combinant le HPC traditionnel à des capacités IA révolutionnaires pour accélérer la découverte scientifique sur les défis de recherche les plus importants au monde.
Mémoire 80 Go : planification de capacité pour les grands modèles
La capacité de mémoire HBM3 de 80 Go détermine quels modèles peuvent être entièrement chargés dans la mémoire GPU.
Les déploiements sur GPU unique peuvent prendre en charge des modèles allant jusqu’à environ 70 à 75 milliards de paramètres en utilisant la précision FP16. Cela inclut les modèles populaires comme Llama 2 70B, Code Llama 70B et des architectures similaires.
La précision FP8 double efficacement cette capacité, permettant le déploiement de modèles approchant les 140 à 150 milliards de paramètres sur un seul H100.
La mise à l’échelle multi-GPU devient nécessaire pour les modèles plus volumineux. En utilisant le parallélisme de tenseurs, deux GPU H100 SXM peuvent prendre en charge des modèles allant jusqu’à 150 milliards de paramètres en FP16.
Quatre GPU permettent l’entraînement et l’inférence de modèles dépassant les 300 milliards de paramètres. L’interconnexion NVLink à haute bande passante assure une communication efficace entre les GPU. Cela maintient des performances de mise à l’échelle quasi linéaires sur plusieurs appareils.
Les applications gourmandes en mémoire au-delà des paramètres de modèle incluent les grandes fenêtres contextuelles pour les modèles de langage. Les applications nécessitant des fenêtres contextuelles de plus de 32K tokens bénéficient particulièrement du vaste pool de mémoire du H100. Le traitement d’images haute résolution et les ensembles de données scientifiques exploitent également la capacité mémoire étendue.
H100 SXM vs PCIe : différences de performances et de tarification
| Spécification | H100 SXM | H100 PCIe |
|---|---|---|
| Cœurs CUDA | 16 896 | 14 592 |
| Cœurs Tensor | 528 | 456 |
| Mémoire GPU | 80 Go HBM3 | 80 Go HBM2e |
| Bande passante mémoire | 3,35 To/s | 2,0 To/s |
| Performance TF32 | 989 TFLOPS | 756 TFLOPS |
| Performance FP16 | 1 979 TFLOPS | 1 513 TFLOPS |
| Performance FP8 | 3 958 TFLOPS | 3 026 TFLOPS |
| TDP max | 700 W | 350 W |
| Interconnexion | NVLink 900 Go/s | NVLink 600 Go/s |
| Facteur de forme | Module SXM5 | PCIe double emplacement |
La variante SXM5 bénéficie d’un tarif premium en raison de son architecture supérieure conçue pour une densité de performance maximale. Le facteur de forme SXM s’intègre directement dans des cartes mères de serveur spécialisées, permettant une alimentation électrique et un refroidissement optimaux. Cette conception offre une bande passante mémoire 67 % plus élevée, 30 % de cœurs Tensor supplémentaires et une communication multi-GPU significativement plus rapide par rapport à la version PCIe.
H100 vs A100 : quel GPU correspond à votre charge de travail ?
| Spécification | NVIDIA A100 | NVIDIA H100 SXM5 |
|---|---|---|
| Facteur de forme | SXM4 | SXM5 |
| Multiprocesseurs de streaming (SMs) | 108 | 132 |
| TPCs | 54 | 66 |
| Cœurs FP32 par SM | 64 | 128 |
| Total cœurs FP32 | 6 912 | 16 896 |
| Cœurs FP64 par SM (hors Tensor) | 32 | 64 |
| Total cœurs FP64 (hors Tensor) | 3 456 | 8 448 |
| Cœurs Tensor | 432 | 528 |
| Interface mémoire | HBM2 5120 bits | HBM3 5120 bits |
| Transistors | 54,2 milliards | 80 milliards |
| Bande passante mémoire | 1 555 Go/s | 3 000 Go/s |
| TDP max | 400 W | 700 W |
Le H100 dispose de 2,4 fois plus de cœurs de traitement, une vitesse mémoire presque double (3 000 contre 1 555 Go/s) et 48 % de transistors supplémentaires par rapport à l’A100. En revanche, il consomme 75 % de puissance en plus (700 W contre 400 W).
Comparaison des coûts du H100 et de l’A100
| Fournisseur/Modèle GPU | Tarification spot | À la demande |
|---|---|---|
| Novita AI H100 SXM 80 Go | 0,90 $/h | 1,80 $/h |
| RunPod H100 SXM 80 Go | 1,75 $/h | 2,69 $/h |
| Novita AI A100 SXM 80 Go | 0,80 $/h | 1,60 $/h |
| RunPod A100 SXM 80 Go | 0,95 $/h | 1,74 $/h |
Spot vs à la demande : quand choisir chaque option ?
Choisissez la tarification spot quand : vos charges de travail peuvent supporter des interruptions occasionnelles et que vous effectuez des travaux de développement. La tarification spot fonctionne parfaitement pour les runs d’entraînement avec point de reprise, les projets de recherche et les applications sensibles aux coûts. Les 50 % d’économies justifient des redémarrages occasionnels pour la plupart des scénarios de développement et de traitement par lots.
Choisissez l’option à la demande quand : vous exécutez des services d’inférence en production ou que vous effectuez un entraînement critique dans le temps avec des délais serrés. Les instances à la demande offrent des performances constantes sans risque d’interruption. C’est essentiel pour les applications orientées client et les charges de travail critiques nécessitant une disponibilité garantie.
Stratégies hybrides : De nombreuses organisations optimisent leurs coûts en utilisant des instances spot pour le développement et les charges de travail non critiques. Elles réservent la capacité à la demande pour les services de production. Cette approche maximise les économies de coûts tout en garantissant une livraison de services fiable là où c’est nécessaire.
Comment trouver des instances spot H100 SXM 80 Go sur Novita AI
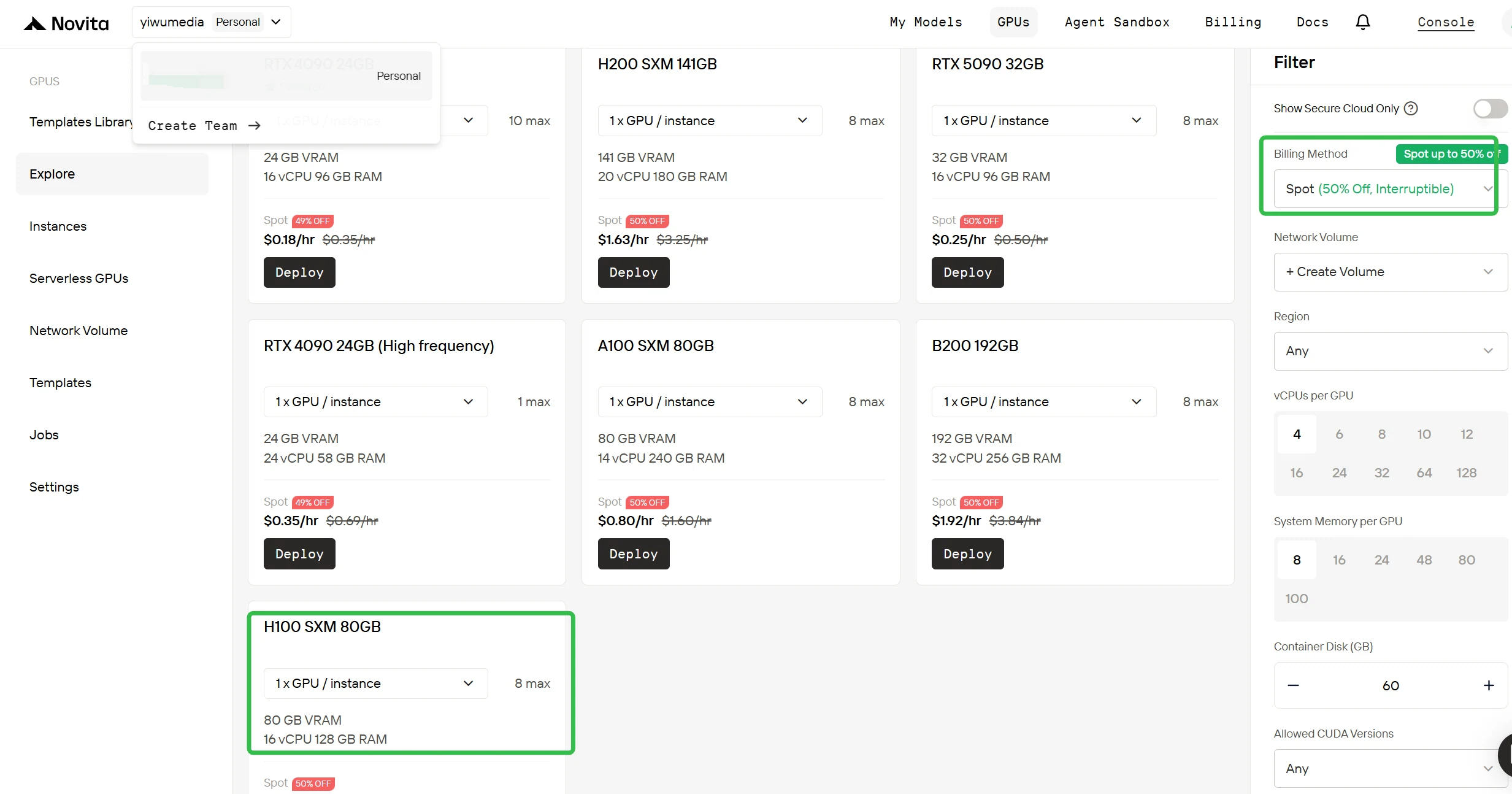
Le lancement d’une instance spot H100 sur Novita AI suit le même processus simplifié qui a fait ses preuves pour les autres déploiements de GPU.
Accédez à votre console
Connectez-vous à votre Console GPU Novita AI. Le tableau de bord affiche la disponibilité des GPU en temps réel, la capacité actuelle des instances spot et vos déploiements récents. Cette vue d’ensemble vous aide à prendre des décisions éclairées sur le moment et l’endroit où déployer vos instances.
Passez à la facturation spot
Dans la barre latérale droite sous Filtre, modifiez la méthode de facturation de « À la demande » à « Spot » pour voir les tarifs réduits. L’interface se met à jour immédiatement pour afficher le H100 à 0,90 $/h. Cette transparence vous garantit de savoir exactement ce que vous payez avant le déploiement.
Comment fonctionnent les instances spot Novita AI ?
Les instances spot utilisent la capacité GPU disponible de Novita AI, rendant cette capacité accessible à des tarifs plus bas car elle peut être récupérée lorsque la demande pour les instances standard augmente.
Caractéristiques clés
Disponibilité variable : Les instances spot peuvent être interrompues lorsque Novita AI a besoin de récupérer la capacité. Cependant, cela ne signifie pas une résiliation aléatoire : la plateforme suit un processus structuré avec des notifications préalables.
Économies de coûts importantes : Accédez aux mêmes performances GPU à un tarif jusqu’à 50 % moins élevé que les tarifs à la demande. Le matériel et les performances sont identiques ; seule la garantie de disponibilité diffère.
Période de protection : Chaque instance spot inclut une fenêtre de protection d’une heure après le lancement. Pendant cette période, votre instance ne peut pas être interrompue, quelles que soient les demandes de capacité.
Notifications préalables : Recevez des notifications d’interruption 1 heure avant la récupération, avec un avertissement supplémentaire de 5 minutes. Ces notifications vous permettent de sauvegarder votre travail, de créer des points de reprise et d’arrêter vos applications proprement.
Comparaison avec les instances à la demande
| Fonctionnalité | Instances spot | Instances à la demande |
|---|---|---|
| Tarification | Jusqu’à 50 % moins chère | Tarifs standard |
| Disponibilité | Soumise à la capacité | Toujours disponible |
| Risque d’interruption | Peut être récupérée avec préavis | Pas d’interruptions |
| Période de protection | 1 heure après le lancement | Continue |
| Cas d’usage | Charges de travail flexibles et tolérantes aux pannes | Charges de travail critiques et ininterruptibles |
En choisissant des instances spot pour les charges de travail adaptées, vous accédez aux mêmes ressources GPU puissantes tout en optimisant vos coûts de calcul.
En savoir plus : Guide des instances spot Novita AI
Charges de travail adaptées au déploiement d’instances spot
Les charges de travail de développement et d’expérimentation représentent le cas d’usage idéal pour la tarification spot. Le prototypage de modèles, l’ajustement des hyperparamètres et les expériences de recherche peuvent tirer parti des économies de coûts tout en acceptant des interruptions occasionnelles. Ces charges de travail bénéficient généralement de stratégies de points de reprise et peuvent reprendre efficacement après des interruptions.
Les tâches de traitement par lots et d’entraînement fonctionnent parfaitement avec les instances spot lorsqu’elles sont conçues avec une tolérance aux pannes. Le traitement de données à grande échelle, l’entraînement de modèles avec des points de reprise réguliers et les tâches de calcul distribué peuvent réaliser des économies de coûts importantes. Les frameworks d’apprentissage profond modernes comme PyTorch et TensorFlow incluent des mécanismes de point de reprise intégrés qui s’intègrent parfaitement.
Les charges de travail flexibles en temps sans délais d’achèvement stricts maximisent les avantages de la tarification spot. Les runs d’entraînement de nuit, le traitement par lots le week-end et les tâches d’inférence non critiques peuvent utiliser exclusivement des instances spot. Cela permet d’atteindre une optimisation maximale des coûts tout en maintenant des normes de performance élevées.
Conclusion
Le NVIDIA H100 SXM 80 Go à 0,90 $/h en tarification spot sur Novita AI représente l’accès le plus rentable à l’accélération IA haut de gamme disponible aujourd’hui. Avec des améliorations de performances révolutionnaires par rapport à l’A100 et une intégration complète de la pile logicielle, cette offre permet aux entreprises de traiter des charges de travail IA exigeantes sans contraintes budgétaires. La combinaison de cœurs Tensor de 4e génération, de 80 Go de mémoire HBM3 et de la tarification spot intelligente rend le développement IA avancé accessible.
Que vous entraîniez des modèles de langage volumineux, que vous développiez des applications de vision par ordinateur ou que vous meniez des recherches scientifiques, le H100 SXM offre les performances nécessaires pour les projets IA de nouvelle génération. Commencez à construire dès aujourd’hui avec l’accélérateur IA le plus avancé au monde — déployez votre instance spot H100 SXM 80 Go sur Novita AI et bénéficiez de performances inégalées à des prix imbattables.
Foire aux questions
Quelle est la différence entre le H100 SXM et le PCIe ?
Le H100 SXM offre des performances supérieures avec une bande passante mémoire 67 % plus élevée (3,35 To/s contre 2,0 To/s) et plus de cœurs Tensor (528 contre 456). Le facteur de forme SXM s’intègre directement dans des cartes mères de serveur pour une alimentation et un refroidissement optimaux. Les versions PCIe utilisent des emplacements d’extension standard avec des capacités de performance réduites.
Quelle est la fiabilité des instances spot pour l’entraînement IA ?
Les instances spot de Novita AI incluent des fonctionnalités de fiabilité de niveau entreprise, notamment des périodes de protection garanties d’une heure. Les utilisateurs reçoivent des notifications d’interruption 60 minutes à l’avance et des avertissements finaux de 5 minutes. Les frameworks IA modernes prennent en charge le checkpointing transparent, permettant aux tâches d’entraînement de reprendre de manière transparente après toute interruption.
Puis-je utiliser le H100 SXM pour des charges de travail d’inférence ?
Absolument. Le H100 SXM excelle sur les charges de travail d’inférence, offrant des performances jusqu’à 30 fois plus rapides que les générations précédentes. Le Transformer Engine et la prise en charge de la précision FP8 offrent un débit exceptionnel pour les modèles de langage. La mémoire de 80 Go permet des tailles de batch importantes et des déploiements de modèles complexes, rendant la tarification spot rentable même pour les applications dédiées à l’inférence.
Que se passe-t-il si mon instance spot est interrompue ?
Vous recevez une notification 60 minutes à l’avance, suivie d’un avertissement final de 5 minutes avant toute interruption. Cela laisse amplement le temps de sauvegarder votre travail, de créer des points de reprise et d’arrêter vos applications proprement. Les frameworks IA modernes gèrent automatiquement les interruptions via des mécanismes de point de reprise intégrés, permettant un redémarrage immédiat avec les points de reprise sauvegardés.
Comment le H100 se compare-t-il à l’A100 ?
Le H100 est jusqu’à 6 fois plus rapide pour l’entraînement et 30 fois plus rapide pour l’inférence que l’A100, grâce à la prise en charge de FP8 et au Transformer Engine. Il dispose également d’une bande passante mémoire de 3,35 To/s contre ~2 To/s pour l’A100, réduisant les goulots d’étranglement de données. Bien que l’A100 reste rentable pour les petites tâches, le H100 offre de meilleures performances et un coût total plus faible pour les charges de travail volumineuses et sensibles au temps.
Novita AI est une plateforme cloud IA qui offre aux développeurs un moyen simple de déployer des modèles IA via notre API intuitive, tout en fournissant un cloud GPU abordable et fiable pour construire et mettre à l’échelle vos projets.



