

- Почему H100 идеально подходит для обучения и инференса моделей машинного обучения?
- H100 SXM против PCIe: различия в производительности и цене
- H100 против A100: какой GPU подходит для ваших задач?
- Сравнение стоимости H100 и A100
- Как найти спотовые инстансы H100 SXM 80GB на Novita AI
- Как работают спотовые инстансы Novita AI?
- Оптимальные рабочие нагрузки для развертывания на спотовых инстансах
- Заключение
GPU NVIDIA H100 SXM 80GB представляет собой вершину технологий ускорения ИИ. Novita AI теперь предлагает этот премиальный GPU по беспрецедентной цене $0.90 в час в рамках спотового тарифа. Эта конкурентоспособная ставка делает самый продвинутый ускоритель ИИ в мире доступным для бизнеса и разработчиков, которые стремятся получить максимальную производительность.
H100 обеспечивает исключительную производительность для обучения больших языковых моделей, задач компьютерного зрения и высокопроизводительных вычислений. Обладая 80GB памяти HBM3 и тензорными ядрами 4-го поколения, он обеспечивает до 30-кратного ускорения инференса по сравнению с предыдущими поколениями. Интеллектуальная модель спотового тарифа Novita AI сохраняет экономическую эффективность, предоставляя при этом прорывную производительность.
Разверните свой спотовый инстанс H100 прямо сейчас
Почему H100 идеально подходит для обучения и инференса моделей машинного обучения?
Полностью новая архитектура GPU
H100 SXM 80GB построен на революционной архитектуре NVIDIA Hopper. Он содержит более 80 миллиардов транзисторов по 5-нм техпроцессу, обеспечивая беспрецедентную производительность для задач ИИ и высокопроизводительных вычислений (HPC). GPU оснащен 16 896 ядрами CUDA, 528 тензорными ядрами 4-го поколения и 80GB высокоскоростной памяти HBM3.
Система памяти обеспечивает пропускную способность 3,35 ТБ/с для молниеносного доступа к данным. Прорывовой Transformer Engine автоматически переключается между точностью FP8 и FP16. Это позволяет увеличить пропускную способность до 4 раз при сохранении точности моделей на архитектурах на основе трансформеров.
Производительность GPU H100 в ключевых областях применения ИИ
Преобразующее обучение ИИ: Четвертое поколение тензорных ядер H100 и Transformer Engine с поддержкой точности FP8 ускоряют обучение ИИ до 4 раз по сравнению с предыдущими поколениями для крупных моделей, таких как GPT-3. Продвинутые интерфейсы подключения, включая NVLink с пропускной способностью 900 ГБ/с и NDR InfiniBand, обеспечивают эффективное масштабирование от корпоративных систем до массивных кластеров GPU, делая эксафлопсные HPC и ИИ с триллионами параметров доступными для всех исследователей.
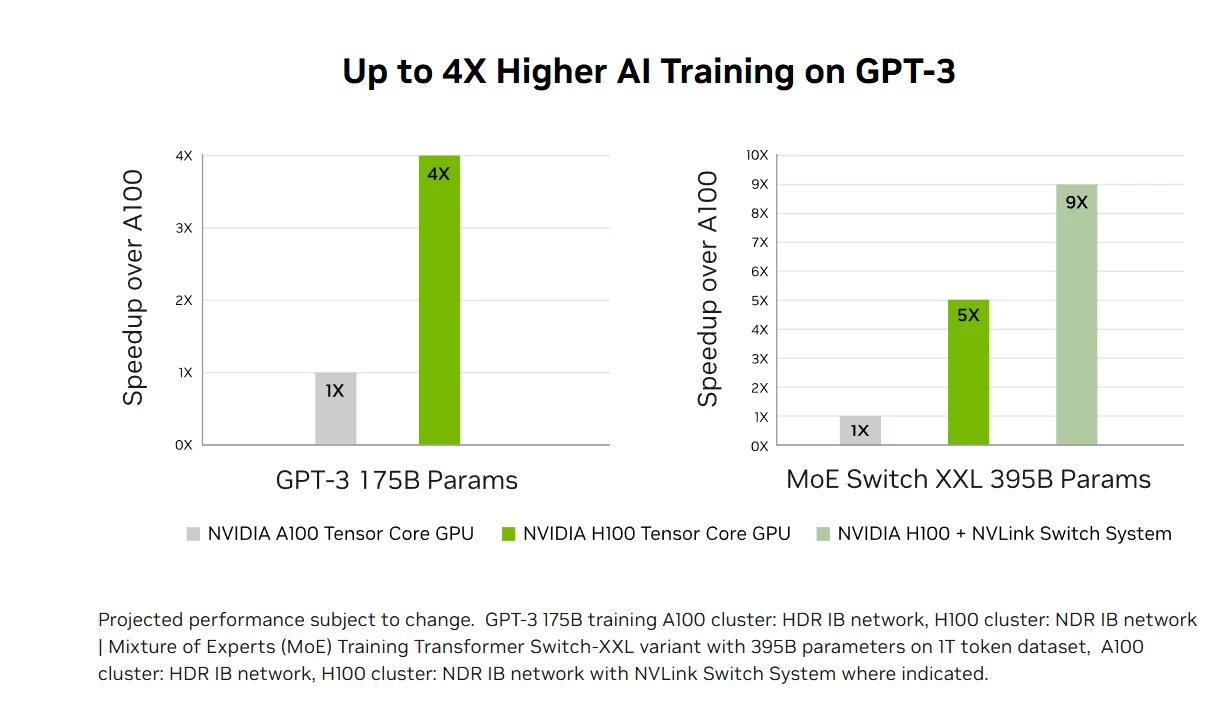
Ускоренная производительность инференса ИИ: H100 обеспечивает ведущую на рынке производительность инференса ИИ с ускорением до 30 раз и минимальной задержкой за счет тензорных ядер 4-го поколения, поддерживающих все форматы точности от FP64 до нового формата FP8. Эта универсальность позволяет H100 ускорять разнообразные архитектуры нейронных сетей в бизнес-приложениях, сокращая использование памяти и сохраняя точность для больших языковых моделей, что делает его комплексным решением для задач инференса глубокого обучения в реальном времени.
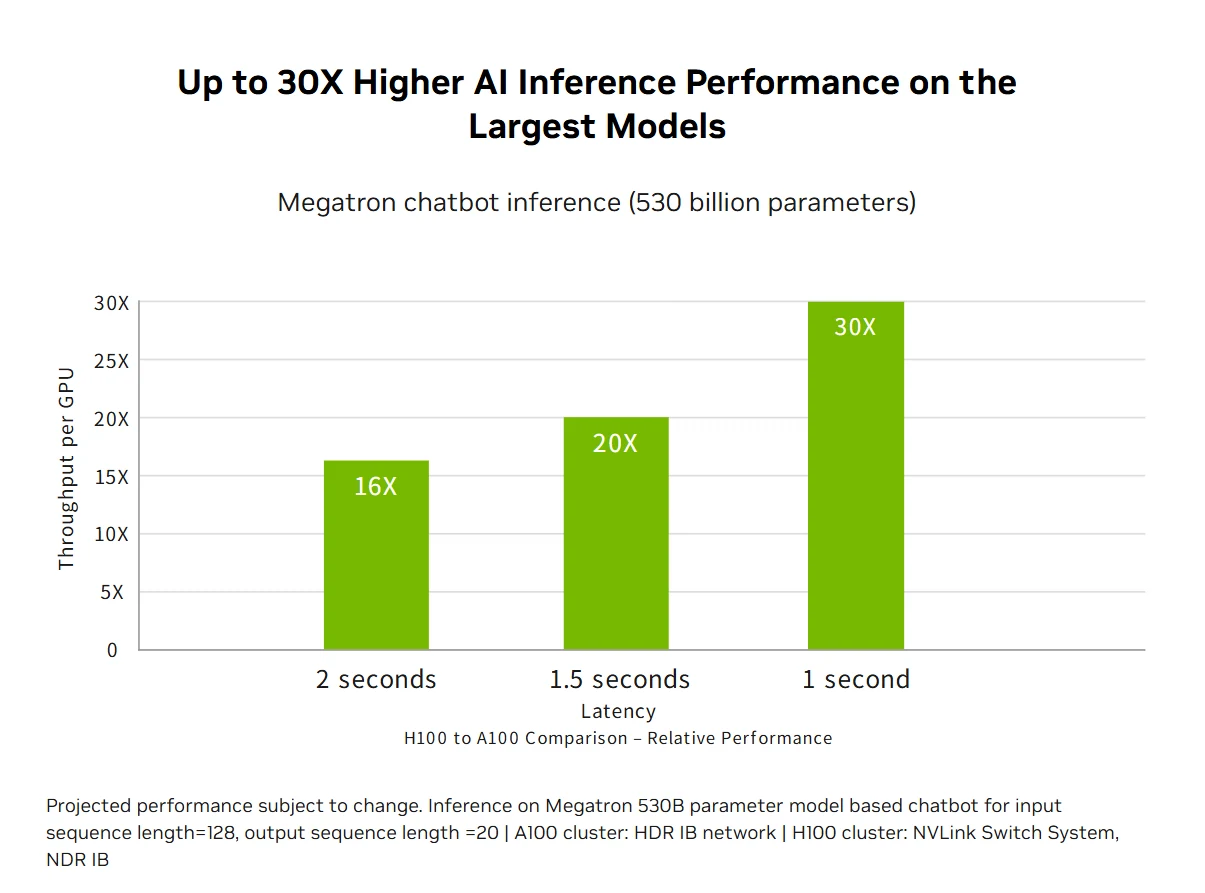
Производительность эксафлопсных HPC: Платформа дата-центров NVIDIA H100 обеспечивает эксафлопсную производительность HPC, превышающую закон Мура, утраивая производительность вычислений с двойной точностью до 60 терафлопсов FP64, и позволяя приложениям с интеграцией ИИ достигать пропускной способности в 1 петафлопс с использованием точности TF32 без каких-либо изменений кода. Новые инструкции DPX обеспечивают 7-кратное ускорение по сравнению с A100 и 40-кратное по сравнению с ЦП для алгоритмов динамического программирования, таких как секвенирование ДНК по алгоритму Смита-Уотермана, сочетая традиционные HPC с прорывными возможностями ИИ для ускорения научных открытий в рамках самых важных исследовательских задач в мире.
80GB памяти: планирование емкости для крупных моделей
Объем памяти HBM3 80GB определяет, какие модели можно полностью разместить в памяти GPU.
Развертывания на одном GPU могут обрабатывать модели объемом до примерно 70-75 миллиардов параметров с использованием точности FP16. Сюда относятся популярные модели, такие как Llama 2 70B, Code Llama 70B и аналогичные архитектуры.
Точность FP8 эффективно удваивает эту емкость, позволяя развертывать модели объемом до 140-150 миллиардов параметров на одном H100.
Масштабирование на нескольких GPU становится необходимым для более крупных моделей. При использовании тензорного параллелизма два GPU H100 SXM могут обрабатывать модели объемом до 150 миллиардов параметров с точностью FP16.
Четыре GPU позволяют обучать и запускать инференс моделей объемом более 300 миллиардов параметров. Высокоскоростной интерфейс подключения NVLink обеспечивает эффективную связь между GPU. Это сохраняет почти линейную производительность масштабирования на нескольких устройствах.
Память-интенсивные приложения, помимо параметров моделей, включают большие окна контекста для языковых моделей. Приложения, требующие окна контекста более 32K токенов, особенно выигрывают от большого пула памяти H100. Обработка изображений в высоком разрешении и научные наборы данных также используют обширную емкость памяти.
H100 SXM против PCIe: различия в производительности и цене
| Характеристика | H100 SXM | H100 PCIe |
|---|---|---|
| Ядра CUDA | 16 896 | 14 592 |
| Тензорные ядра | 528 | 456 |
| Память GPU | 80GB HBM3 | 80GB HBM2e |
| Пропускная способность памяти | 3,35 ТБ/с | 2,0 ТБ/с |
| Производительность TF32 | 989 TFLOPS | 756 TFLOPS |
| Производительность FP16 | 1 979 TFLOPS | 1 513 TFLOPS |
| Производительность FP8 | 3 958 TFLOPS | 3 026 TFLOPS |
| Макс. тепловыделение (TDP) | 700 Вт | 350 Вт |
| Интерфейс подключения | NVLink 900 ГБ/с | NVLink 600 ГБ/с |
| Форм-фактор | Модуль SXM5 | Двухслотовая PCIe |
Вариант SXM5 имеет премиальную цену благодаря своей превосходной архитектуре, разработанной для максимальной плотности производительности. Форм-фактор SXM напрямую интегрируется в специализированные материнские платы серверов, обеспечивая оптимальную подачу питания и охлаждение. Эта конструкция обеспечивает на 67% более высокую пропускную способность памяти, на 30% больше тензорных ядер и значительно более быструю связь между несколькими GPU по сравнению с версией PCIe.
H100 против A100: какой GPU подходит для ваших задач?
| Характеристика | NVIDIA A100 | NVIDIA H100 SXM5 |
|---|---|---|
| Форм-фактор | SXM4 | SXM5 |
| Потоковые мультипроцессоры (SM) | 108 | 132 |
| TPC | 54 | 66 |
| Ядра FP32 на SM | 64 | 128 |
| Всего ядер FP32 | 6 912 | 16 896 |
| Ядра FP64 на SM (без тензорных) | 32 | 64 |
| Всего ядер FP64 (без тензорных) | 3 456 | 8 448 |
| Тензорные ядра | 432 | 528 |
| Интерфейс памяти | 5120-битный HBM2 | 5120-битный HBM3 |
| Транзисторов | 54,2 миллиарда | 80 миллиардов |
| Пропускная способность памяти | 1 555 ГБ/с | 3 000 ГБ/с |
| Макс. тепловыделение (TDP) | 400 Вт | 700 Вт |
H100 имеет на 2,4 раза больше вычислительных ядер, почти вдвое более высокую скорость памяти (3 000 против 1 555 ГБ/с) и на 48% больше транзисторов по сравнению с A100. Однако он потребляет на 75% больше энергии (700 Вт против 400 Вт).
Сравнение стоимости H100 и A100
| Провайдер/Модель GPU | Спотовая цена | On-Demand |
|---|---|---|
| Novita AI H100 SXM 80GB | $0.90 в час | $1.80 в час |
| RunPod H100 SXM 80GB | $1.75 в час | $2.69 в час |
| Novita AI A100 SXM 80GB | $0.80 в час | $1.60 в час |
| RunPod A100 SXM 80GB | $0.95 в час | $1.74 в час |
Спот против On-Demand: когда что выбирать
Выбирайте спотовый тариф, если: ваши рабочие нагрузки могут переносить периодические прерывания, и вы выполняете работы по разработке. Спотовый тариф отлично подходит для запусков обучения с чекпоинтингом, исследовательских проектов и приложений с чувствительностью к стоимости. Экономия в 50% оправдывает периодические перезапуски для большинства сценариев разработки и пакетной обработки.
Выбирайте тариф по запросу (On-Demand), если: вы запускаете производственные сервисы инференса или выполняете срочное обучение с жесткими дедлайнами. Инстансы по запросу обеспечивают стабильную производительность без риска прерываний. Это необходимо для клиентских приложений и критически важных рабочих нагрузок, требующих гарантированной доступности.
Гибридные стратегии: Многие организации оптимизируют расходы, используя спотовые инстансы для разработки и некритичных рабочих нагрузок. Они резервируют инстансы по запросу для производственных сервисов. Такой подход максимизирует экономию расходов, обеспечивая при этом надежную доставку сервисов там, где это необходимо.
Как найти спотовые инстансы H100 SXM 80GB на Novita AI
Запуск спотового инстанса H100 на Novita AI происходит по тому же оптимизированному процессу, который успешно зарекомендовал себя при развертывании других GPU.
Получите доступ к консоли
Войдите в свою консоль GPU Novita AI. Панель управления отображает актуальную доступность GPU, текущую емкость спотовых инстансов и ваши недавние развертывания. Этот обзор помогает вам принимать обоснованные решения о том, когда и где развертывать ваши инстансы.
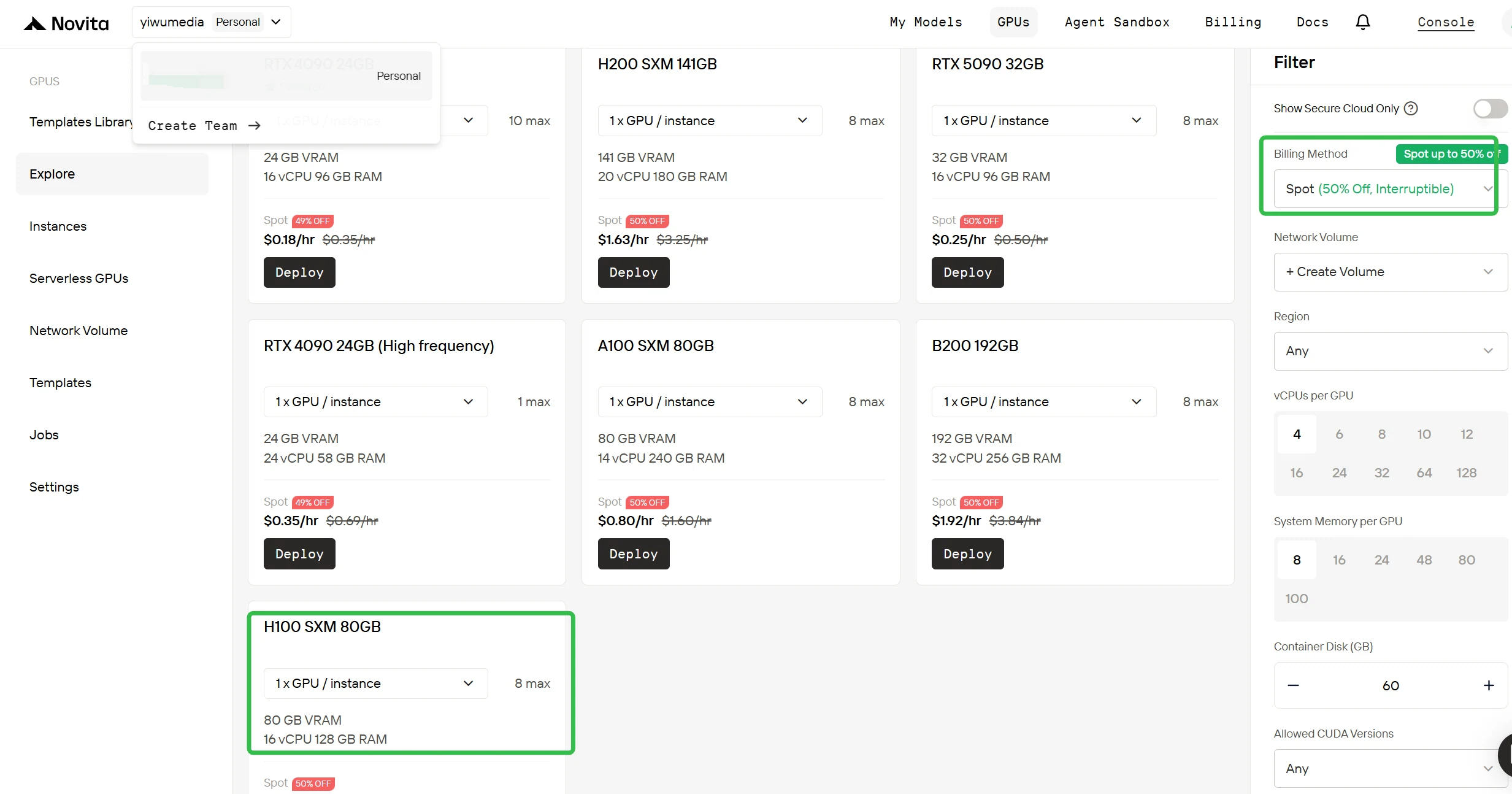
Переключитесь на спотовое тарифицирование
В правой боковой панели в разделе Фильтр измените метод тарификации с «On-Demand» на «Spot», чтобы увидеть сниженные цены. Интерфейс сразу обновляется, показывая H100 по цене $0.90 в час. Эта прозрачность гарантирует, что вы точно знаете, сколько будете платить, перед развертыванием.
Как работают спотовые инстансы Novita AI?
Спотовые инстансы используют резервную емкость GPU Novita AI, предоставляя эту емкость по более низким ценам, поскольку она может быть возвращена, когда спрос на обычные инстансы возрастает.
Ключевые особенности
Изменяемая доступность: Спотовые инстансы могут быть прерваны, когда Novita AI требует вернуть емкость. Однако это не означает случайное завершение — платформа следует структурированному процессу с предварительными уведомлениями.
Значительная экономия расходов: Получите доступ к той же производительности GPU со скидкой до 50% по сравнению с ценами по запросу (On-Demand). Оборудование и производительность идентичны; отличается только гарантия доступности.
Период защиты: Каждый спотовый инстанс включает 1-часовое окно защиты после запуска. В течение этого времени ваш инстанс не может быть прерван независимо от спроса на емкость.
Предварительные уведомления: Вы получаете уведомления о прерывании за 1 час до возврата емкости, с дополнительным 5-минутным предупреждением. Эти уведомления позволяют вам сохранить работу, создать чекпоинты и корректно завершить работу приложений.
Сравнение с инстансами по запросу
| Характеристика | Спотовые инстансы | Инстансы по запросу |
|---|---|---|
| Цена | Скидка до 50% | Стандартные тарифы |
| Доступность | Зависит от емкости | Всегда доступны |
| Риск прерывания | Могут быть возвращены с уведомлением | Нет прерываний |
| Период защиты | 1 час после запуска | Непрерывный |
| Сценарии использования | Гибкие, отказоустойчивые рабочие нагрузки | Критические, непрерываемые рабочие нагрузки |
Выбирая спотовые инстансы для подходящих рабочих нагрузок, вы получаете доступ к таким же мощным ресурсам GPU, оптимизируя при этом расходы на вычисления.
Узнайте больше: Руководство по спотовым инстансам Novita AI
Оптимальные рабочие нагрузки для развертывания на спотовых инстансах
Рабочие нагрузки для разработки и экспериментов являются идеальным сценарием для использования спотового тарифа. Прототипирование моделей, подбор гиперпараметров и исследовательские эксперименты могут использовать экономию расходов, принимая при этом периодические прерывания. Эти рабочие нагрузки обычно выигрывают от стратегий чекпоинтинга и могут эффективно возобновляться после прерываний.
Задачи пакетной обработки и обучения отлично работают со спотовыми инстансами при проектировании с отказоустойчивостью. Масштабная обработка данных, обучение моделей с регулярными чекпоинтами и задачи распределенных вычислений могут обеспечить значительную экономию расходов. Современные фреймворки глубокого обучения, такие как PyTorch и TensorFlow, включают встроенные механизмы чекпоинтинга, которые интегрируются без проблем.
Рабочие нагрузки с гибким временем без строгих дедлайнов завершения максимизируют преимущества спотового тарифа. Запуски обучения в ночное время, пакетная обработка в выходные и некритические задачи инференса могут использовать исключительно спотовые инстансы. Это обеспечивает максимальную оптимизацию расходов при сохранении высоких стандартов производительности.
Заключение
GPU NVIDIA H100 SXM 80GB по спотовой цене $0.90 в час на Novita AI представляет собой наиболее экономически эффективный доступ к премиальному ускорению ИИ, доступный сегодня. Благодаря прорывным улучшениям производительности по сравнению с A100 и комплексной интеграции со стеком программного обеспечения это предложение позволяет бизнесу решать сложные рабочие нагрузки ИИ без бюджетных ограничений. Сочетание тензорных ядер 4-го поколения, памяти HBM3 80GB и интеллектуального спотового тарифа делает разработку продвинутого ИИ доступной.
Независимо от того, обучаете ли вы большие языковые модели, разрабатываете приложения компьютерного зрения или проводите научные исследования, H100 SXM обеспечивает производительность, необходимую для проектов с ИИ следующего поколения. Начните строить решения с самым продвинутым ускорителем ИИ в мире уже сегодня — разверните свой спотовый инстанс H100 SXM 80GB на Novita AI и ощутите непревзойденную производительность по непревзойденным ценам.
Часто задаваемые вопросы
В чем разница между H100 SXM и PCIe? H100 SXM обеспечивает превосходную производительность с на 67% более высокой пропускной способностью памяти (3,35 ТБ/с против 2,0 ТБ/с) и большим количеством тензорных ядер (528 против 456). Форм-фактор SXM напрямую интегрируется в материнские платы серверов для оптимальной подачи питания и охлаждения. Версии PCIe используют стандартные слоты расширения с сокращенными возможностями производительности.
Насколько надежны спотовые инстансы для обучения ИИ? Спотовые инстансы Novita AI включают функции надежности корпоративного уровня, включая гарантированные периоды защиты продолжительностью 1 час. Пользователи получают предварительные уведомления о прерывании за 60 минут и окончательные предупреждения за 5 минут. Современные фреймворки ИИ поддерживают прозрачный чекпоинтинг, что позволяет задачам обучения беспрепятственно возобновляться после любых прерываний.
Можно ли использовать H100 SXM для рабочих нагрузок инференса? Безусловно. H100 SXM превосходно справляется с рабочими нагрузками инференса, обеспечивая до 30-кратного ускорения производительности по сравнению с предыдущими поколениями. Transformer Engine и поддержка точности FP8 обеспечивают исключительную пропускную способность для языковых моделей. Память 80GB позволяет использовать большие размеры пакетов и развертывать сложные модели, что делает спотовый тариф экономически эффективным даже для приложений, предназначенных исключительно для инференса.
Что произойдет, если мой спотовый инстанс будет прерван? Вы получаете предварительное уведомление за 60 минут, за которым следует окончательное предупреждение за 5 минут до любого прерывания. Это предоставляет достаточно времени для сохранения работы, создания чекпоинтов и корректного завершения работы приложений. Современные фреймворки ИИ автоматически обрабатывают прерывания с помощью встроенных механизмов чекпоинтинга, что позволяет немедленно перезапустить работу с сохраненными чекпоинтами.
Как H100 сравнивается с A100? H100 до 6 раз быстрее для обучения и до 30 раз быстрее для инференса по сравнению с A100 благодаря поддержке FP8 и Transformer Engine. Он также имеет пропускную способность памяти 3,35 ТБ/с против ~2 ТБ/с у A100, что сокращает узкие места в передаче данных. Хотя A100 все еще остается экономически эффективным для небольших задач, H100 предлагает лучшую производительность и более низкую общую стоимость для крупных рабочих нагрузок с жесткими временными ограничениями.
Novita AI — это облачная платформа ИИ, которая предлагает разработчикам простой способ развертывать модели ИИ с использованием нашего простого API, а также предоставляет доступное и надежное облако GPU для построения и масштабирования решений.



