

- Why Is H100 Ideal for ML Training and Inference?
- H100 SXM vs PCIe: Performance and Pricing Differences
- H100 vs A100: Which GPU Fits Your Workload?
- Compare Cost of H100 and A100
- How to Find H100 SXM 80GB Spot Instances on Novita AI
- How Do Novita AI Spot Instances Work?
- Smart Workloads for Spot Instance Deployment
- Conclusion
The NVIDIA H100 SXM 80GB represents the pinnacle of AI acceleration technology. Novita AI now offers this premium GPU at an unprecedented $0.90/hr through spot pricing. This competitive rate makes the world’s most advanced AI accelerator accessible to businesses and developers seeking maximum performance.
The H100 delivers exceptional performance for large language model training, computer vision, and high-performance computing workloads. With 80GB of HBM3 memory and 4th-generation Tensor Cores, it provides up to 30x faster inference than previous generations. Novita AI’s intelligent spot pricing model maintains cost efficiency while delivering breakthrough performance.
Deploy your H100 Spot Instance Now
Why Is H100 Ideal for ML Training and Inference?
A completely new GPU architecture
The H100 SXM 80GB is built on NVIDIA’s revolutionary Hopper architecture. It houses over 80 billion transistors in a 5nm process node, delivering unprecedented performance for AI and HPC workloads. The GPU features 16,896 CUDA cores, 528 4th-generation Tensor Cores, and 80GB of high-bandwidth HBM3 memory.
The memory system provides 3.35TB/s memory bandwidth for lightning-fast data access. The breakthrough Transformer Engine automatically switches between FP8 and FP16 precision. This enables up to 4x higher throughput while maintaining model accuracy for transformer-based architectures.
H100 GPU Performance Across Key AI Applications
Transformational AI Training: H100’s fourth-generation Tensor Cores and Transformer Engine with FP8 precision accelerate AI training up to 4X faster than previous generations for large models like GPT-3. Advanced interconnects including 900 GB/s NVLink and NDR InfiniBand enable efficient scaling from enterprise systems to massive GPU clusters, making exascale HPC and trillion-parameter AI accessible to all researchers.
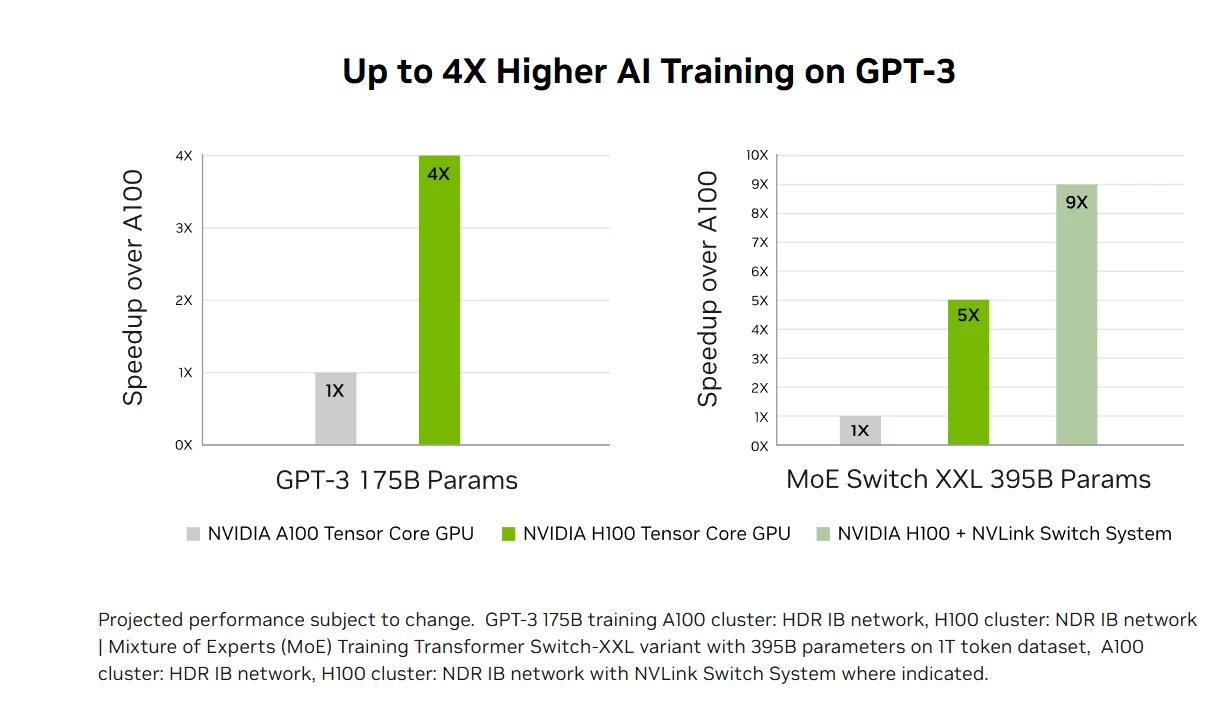
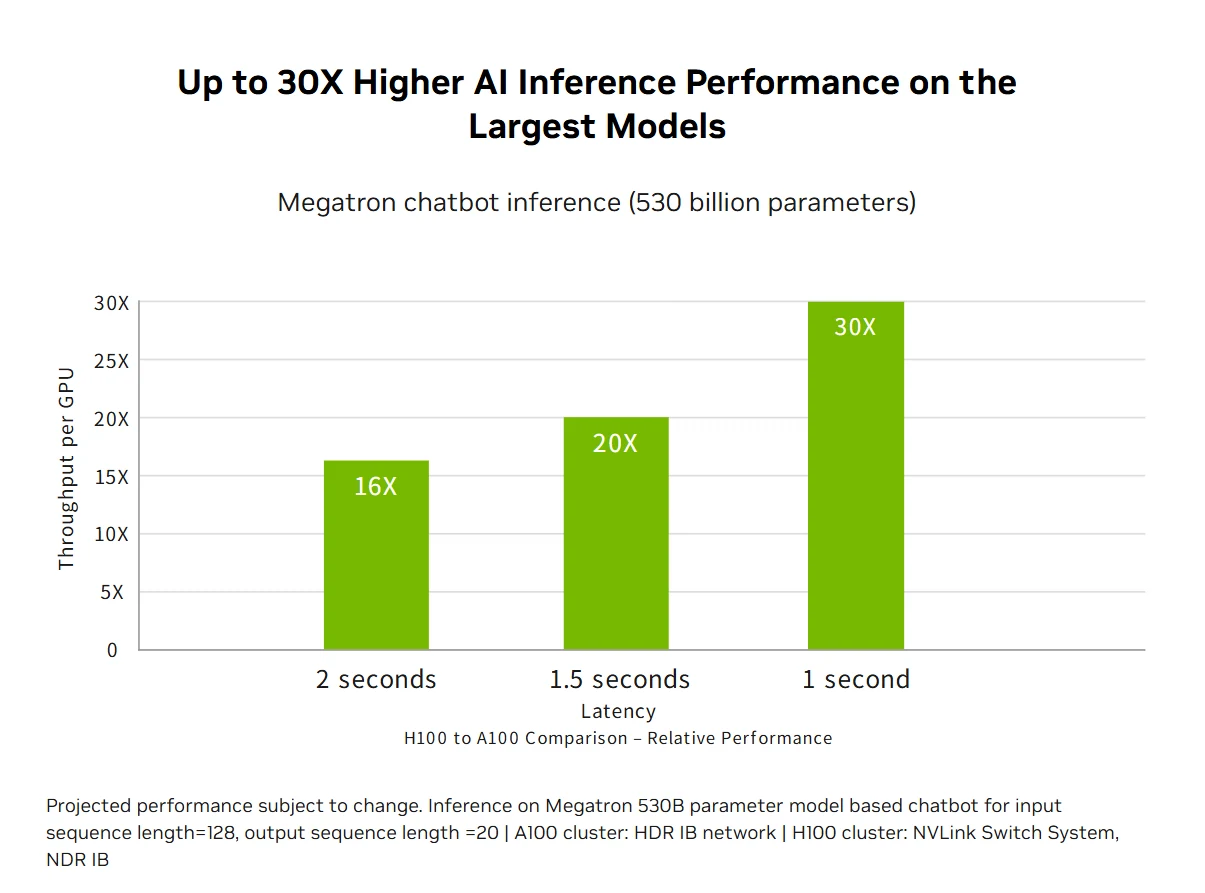
Accelerated AI Inference Performance: H100 delivers market-leading AI inference performance with up to 30X acceleration and lowest latency through fourth-generation Tensor Cores that support all precisions from FP64 to the new FP8 format. This versatility enables the H100 to accelerate diverse neural network architectures across business applications while reducing memory usage and maintaining accuracy for large language models, making it a comprehensive solution for real-time deep learning inference challenges.
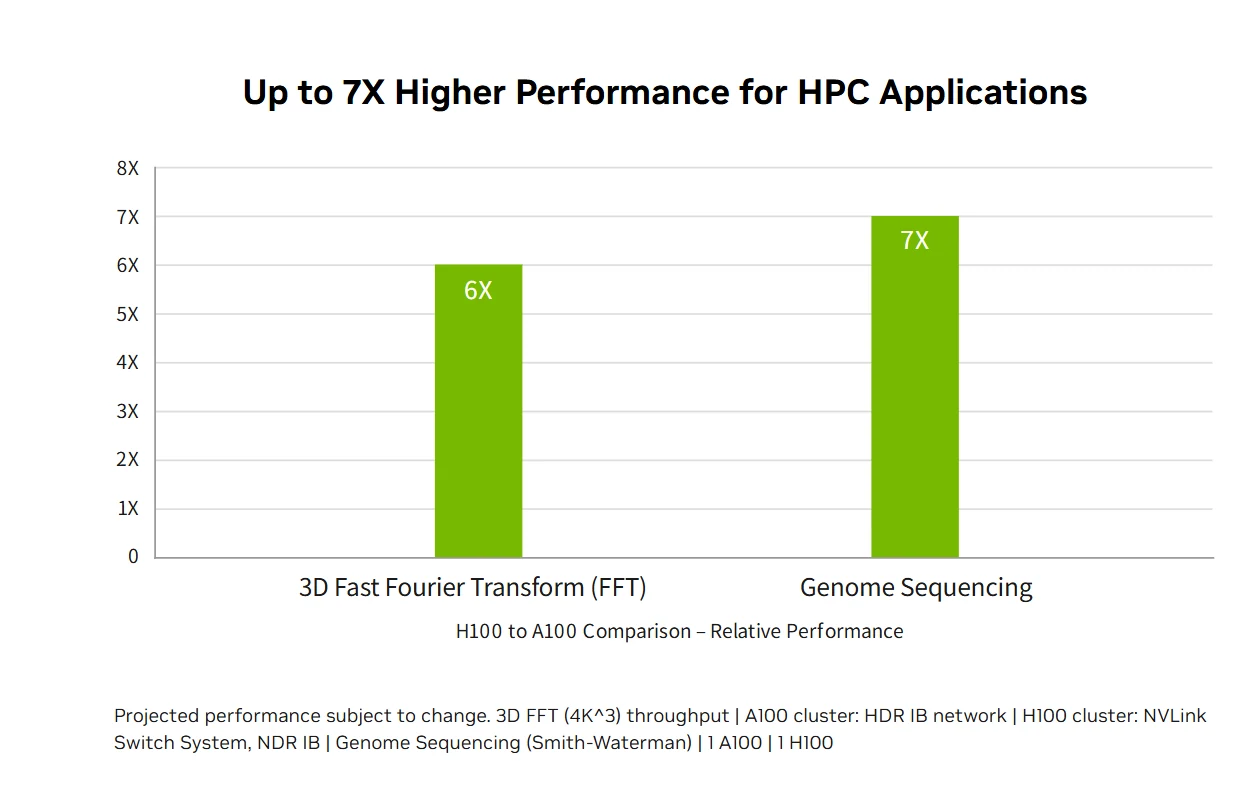
Exascale HPC Performance: The NVIDIA H100 data center platform delivers exascale HPC performance that exceeds Moore’s law, tripling double-precision computing to 60 teraflops FP64 while enabling AI-fused applications to achieve one petaflop throughput using TF32 precision with zero code changes. New DPX instructions provide 7X speedups over A100 and 40X over CPUs for dynamic programming algorithms like Smith-Waterman DNA sequencing, combining traditional HPC with breakthrough AI capabilities to accelerate scientific discovery across the world’s most important research challenges.
80GB Memory: Capacity Planning for Large Models
The 80GB HBM3 memory capacity determines which models can fit entirely in GPU memory.
Single GPU Deployments can handle models up to approximately 70-75 billion parameters using FP16 precision. This includes popular models like Llama 2 70B, Code Llama 70B, and similar architectures.
FP8 precision effectively doubles this capacity, enabling deployment of models approaching 140-150 billion parameters on a single H100.
Multi-GPU Scaling becomes necessary for larger models. Using tensor parallelism, two H100 SXM GPUs can handle models up to 150 billion parameters in FP16.
Four GPUs enable training and inference of models exceeding 300 billion parameters. The high-bandwidth NVLink interconnect ensures efficient communication between GPUs. This maintains near-linear scaling performance across multiple devices.
Memory-Intensive Applications beyond model parameters include large context windows for language models. Applications requiring context windows beyond 32K tokens particularly benefit from the H100’s substantial memory pool. High-resolution image processing and scientific datasets also leverage the extensive memory capacity.
H100 SXM vs PCIe: Performance and Pricing Differences
| Specification | H100 SXM | H100 PCIe |
|---|---|---|
| CUDA Cores | 16,896 | 14,592 |
| Tensor Cores | 528 | 456 |
| GPU Memory | 80GB HBM3 | 80GB HBM2e |
| Memory Bandwidth | 3.35TB/s | 2.0TB/s |
| TF32 Performance | 989 TFLOPS | 756 TFLOPS |
| FP16 Performance | 1,979 TFLOPS | 1,513 TFLOPS |
| FP8 Performance | 3,958 TFLOPS | 3,026 TFLOPS |
| Max TDP | 700W | 350W |
| Interconnect | NVLink 900GB/s | NVLink 600GB/s |
| Form Factor | SXM5 Module | PCIe Dual-Slot |
The SXM5 variant commands premium pricing due to its superior architecture designed for maximum performance density. The SXM form factor integrates directly into specialized server motherboards, enabling optimal power delivery and cooling. This design delivers 67% higher memory bandwidth, 30% more Tensor Cores, and significantly faster multi-GPU communication compared to the PCIe version.
H100 vs A100: Which GPU Fits Your Workload?
| Specification | NVIDIA A100 | NVIDIA H100 SXM5 |
|---|---|---|
| Form Factor | SXM4 | SXM5 |
| Streaming Multiprocessors (SMs) | 108 | 132 |
| TPCs | 54 | 66 |
| FP32 Cores per SM | 64 | 128 |
| Total FP32 Cores | 6,912 | 16,896 |
| FP64 Cores per SM (excl. Tensor) | 32 | 64 |
| Total FP64 Cores (excl. Tensor) | 3,456 | 8,448 |
| Tensor Cores | 432 | 528 |
| Memory Interface | 5120-bit HBM2 | 5120-bit HBM3 |
| Transistors | 54.2 billion | 80 billion |
| Memory Bandwidth | 1,555 GB/s | 3,000 GB/s |
| Max TDP | 400 W | 700 W |
The H100 delivers 2.4x more processing cores, nearly double the memory speed (3,000 vs 1,555 GB/s), and 48% more transistors than the A100. However, it consumes 75% more power (700W vs 400W).
Compare Cost of H100 and A100
| Provider/GPU Model | Spot Pricing | On-Demand |
|---|---|---|
| Novita AI H100 SXM 80GB | $0.90/hr | $1.80/hr |
| RunPod H100 SXM 80GB | $1.75/hr | $2.69/hr |
| Novita AI A100 SXM 80GB | $0.80/hr | $1.60/hr |
| RunPod A100 SXM 80GB | $0.95/hr | $1.74/hr |
Spot vs On-Demand: When to Choose Each
Choose Spot Pricing When: Your workloads can handle occasional interruptions, and you’re conducting development work. Spot pricing works excellently for training runs with checkpointing, research projects, and cost-sensitive applications. The 50% savings justify occasional restarts for most development and batch processing scenarios.
Choose On-Demand When: Running production inference services or conducting time-critical training with tight deadlines. On-demand instances provide consistent performance without interruption risk. This is essential for customer-facing applications and mission-critical workloads requiring guaranteed availability.
Hybrid Strategies: Many organizations optimize costs by using spot instances for development and non-critical workloads. They reserve on-demand capacity for production services. This approach maximizes cost savings while ensuring reliable service delivery where needed.
How to Find H100 SXM 80GB Spot Instances on Novita AI
Launching an H100 Spot Instance on Novita AI follows the same streamlined process proven successful with other GPU deployments.
Access Your Console
Log in to your Novita AI GPU Console. The dashboard displays real-time GPU availability, current Spot Instance capacity, and your recent deployments. This overview helps you make informed decisions about when and where to deploy your instances.
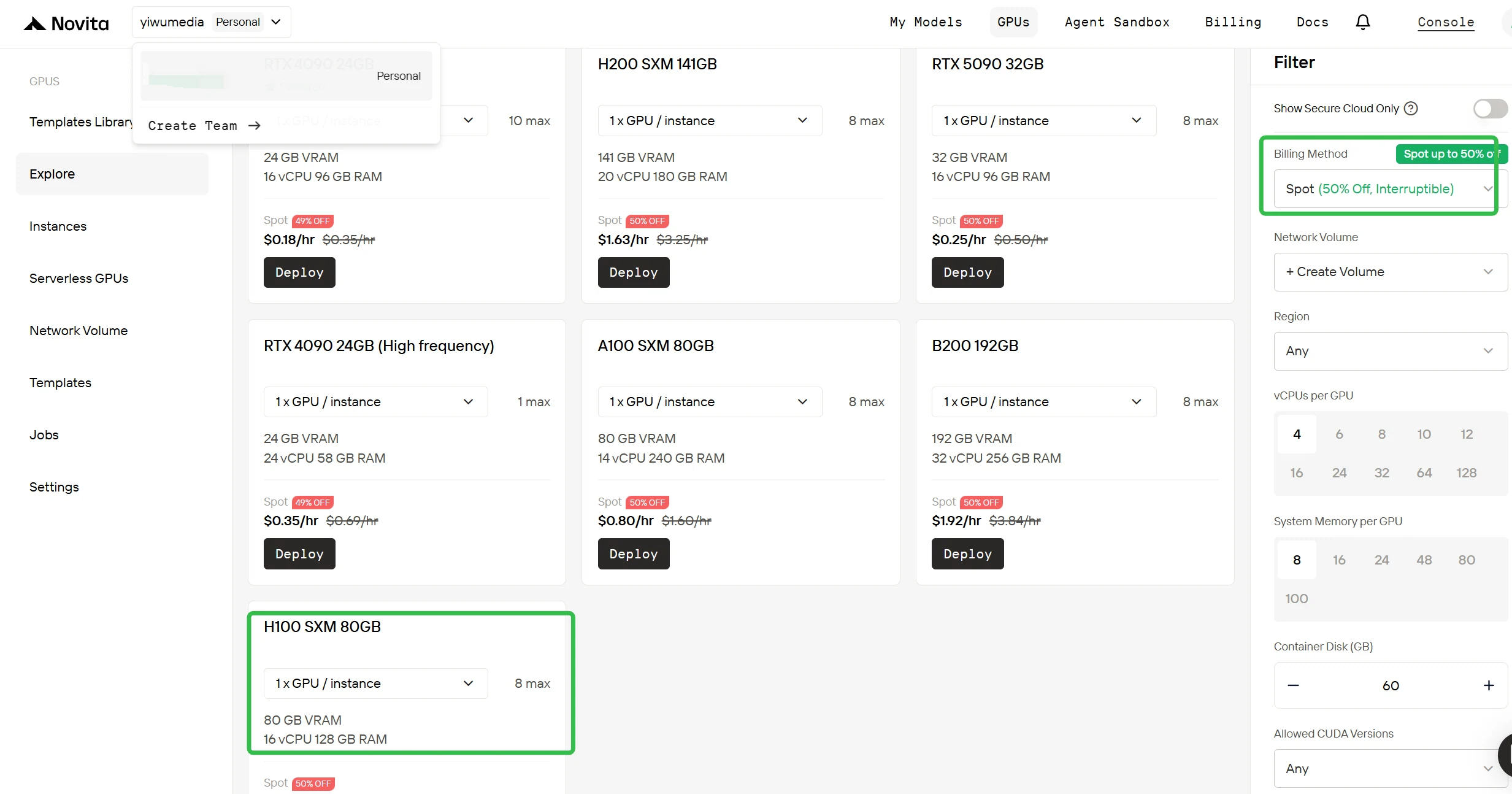
Switch to Spot Billing
In the right sidebar under Filter, change the Billing Method from “On-Demand” to “Spot” to see discounted prices. The interface immediately updates to show the H100 at $0.90/hr. This transparency ensures you know exactly what you’re paying before deployment.
How Do Novita AI Spot Instances Work?
Spot Instances utilize Novita AI’s spare GPU capacity, making this capacity available at lower prices because it can be reclaimed when demand for regular instances increases.
Key Characteristics
Variable availability: Spot Instances may be interrupted when Novita AI requires the capacity back. However, this doesn’t mean random termination—the platform follows a structured process with advance notifications.
Significant cost savings: Access the same GPU performance at up to 50% less than On-Demand prices. The hardware and performance are identical; only the availability guarantee differs.
Protection period: Each Spot Instance includes a 1-hour protection window after launch. During this time, your instance cannot be interrupted regardless of capacity demands.
Advance notifications: Receive interruption notifications 1 hour before reclamation, with an additional 5-minute warning. These notifications allow you to save work, checkpoint progress, and gracefully shut down applications.
Comparison with On-Demand Instances
| Feature | Spot Instances | On-Demand Instances |
|---|---|---|
| Pricing | Up to 50% less | Standard rates |
| Availability | Subject to capacity | Always available |
| Interruption risk | May be reclaimed with notice | No interruptions |
| Protection period | 1 hour after launch | Continuous |
| Use case | Flexible, fault-tolerant workloads | Critical, uninterruptible workloads |
By choosing Spot Instances for appropriate workloads, you access the same powerful GPU resources while optimizing compute costs.
Learn more: Novita AI Spot Instances Guide
Smart Workloads for Spot Instance Deployment
Development and Experimentation workloads represent the ideal use case for spot pricing. Model prototyping, hyperparameter tuning, and research experiments can leverage the cost savings while accepting occasional interruptions. These workloads typically benefit from checkpointing strategies and can resume efficiently after interruptions.
Batch Processing and Training jobs work excellently with spot instances when designed with fault tolerance. Large-scale data processing, model training with regular checkpoints, and distributed computing tasks can achieve significant cost savings. Modern deep learning frameworks like PyTorch and TensorFlow include built-in checkpointing mechanisms that integrate seamlessly.
Time-Flexible Workloads without strict completion deadlines maximize spot pricing benefits. Overnight training runs, weekend batch processing, and non-critical inference tasks can utilize spot instances exclusively. This achieves maximum cost optimization while maintaining high performance standards.
Conclusion
The NVIDIA H100 SXM 80GB at $0.90/hr spot pricing on Novita AI represents the most cost-effective access to premium AI acceleration available today. With breakthrough performance improvements over A100 and comprehensive software stack integration, this offering enables businesses to tackle demanding AI workloads without budget constraints. The combination of 4th-generation Tensor Cores, 80GB HBM3 memory, and intelligent spot pricing makes advanced AI development accessible.
Whether training large language models, developing computer vision applications, or conducting scientific research, H100 SXM delivers the performance needed for next-generation AI projects. Start building with the world’s most advanced AI accelerator today—deploy your H100 SXM 80GB spot instance on Novita AI and experience unmatched performance at unbeatable prices.
Frequently Asked Questions
What’s the difference between H100 SXM and PCIe?
H100 SXM offers superior performance with 67% higher memory bandwidth (3.35TB/s vs 2.0TB/s) and more Tensor Cores (528 vs 456). The SXM form factor integrates directly into server motherboards for optimal power delivery and cooling. PCIe versions use standard expansion slots with reduced performance capabilities.
How reliable are spot instances for AI training?
Novita AI’s spot instances include enterprise-grade reliability features including 1-hour guaranteed protection periods. Users receive 60-minute advance interruption notifications and 5-minute final warnings. Modern AI frameworks support transparent checkpointing, enabling training jobs to resume seamlessly after any interruptions.
Can I use H100 SXM for inference workloads?
Absolutely. H100 SXM excels at inference workloads, delivering up to 30x faster performance than previous generations. The Transformer Engine and FP8 precision support provide exceptional throughput for language models. The 80GB memory enables large batch sizes and complex model deployments, making spot pricing cost-effective even for inference-only applications.
What happens if my spot instance gets interrupted?
You receive 60-minute advance notification followed by a 5-minute final warning before any interruption. This provides ample time to save work, create checkpoints, and gracefully shut down applications. Modern AI frameworks automatically handle interruptions through built-in checkpointing mechanisms, allowing immediate relaunch with saved checkpoints.
How does H100 compare to A100?
H100 is up to 6x faster for training and 30x faster for inference than A100, thanks to FP8 support and the Transformer Engine. It also has 3.35TB/s memory bandwidth vs A100’s ~2TB/s, reducing data bottlenecks. While A100 is still cost-efficient for smaller jobs, H100 offers better performance and lower total cost for large, time-sensitive workloads.
Novita AI is an AI cloud platform that offers developers an easy way to deploy AI models using our simple API, while also providing the affordable and reliable GPU cloud for building and scaling.



