

NVIDIA H100 SXM 80GB 代表了 AI 加速技術的巔峰。Novita AI 現在透過搶實例(Spot)定價,以史無前例的 $0.90/hr 價格提供這款頂級 GPU,這一定價讓全球最先進的 AI 加速器對追求極致效能的企業與開發者而言觸手可及。
H100 在大型語言模型訓練、電腦視覺與高效能運算工作負載上都有卓越表現。搭載 80GB HBM3 記憶體與第四代 Tensor Cores,其推論速度比上一代快最高達 30 倍。Novita AI 智慧搶實例定價模型在提供突破性效能的同時,也能維持成本效益。
為什麼 H100 是機器學習訓練與推論的理想選擇?
完全創新的 GPU 架構
H100 SXM 80GB 基於 NVIDIA 革命性的 Hopper 架構打造,採用 5nm 製程節點內建超過 800 億個電晶體,為 AI 與高效能運算(HPC)工作負載提供前所未有的效能。這款 GPU 配備 16,896 個 CUDA 核心、528 個第四代 Tensor Cores 以及 80GB 高頻寬 HBM3 記憶體。
記憶體系統提供 3.35TB/s 的記憶體頻寬,能實現極速資料存取。突破性的 Transformer Engine 會自動切換 FP8 與 FP16 精度,在維持 Transformer 架構模型準確率的同時,可將吞吐量提升最高達 4 倍。
H100 GPU 在關鍵 AI 應用中的效能表現
變革性 AI 訓練:H100 的第四代 Tensor Cores 與支援 FP8 精度的 Transformer Engine,能讓 GPT-3 等大型模型的 AI 訓練速度比上一代快最高 4 倍。搭載 900 GB/s NVLink 與 NDR InfiniBand 等先進互連技術,可實現從企業級系統到大型 GPU 叢集的高效擴展,讓超算級 HPC 與兆參數級 AI 對所有研究人員都觸手可及。
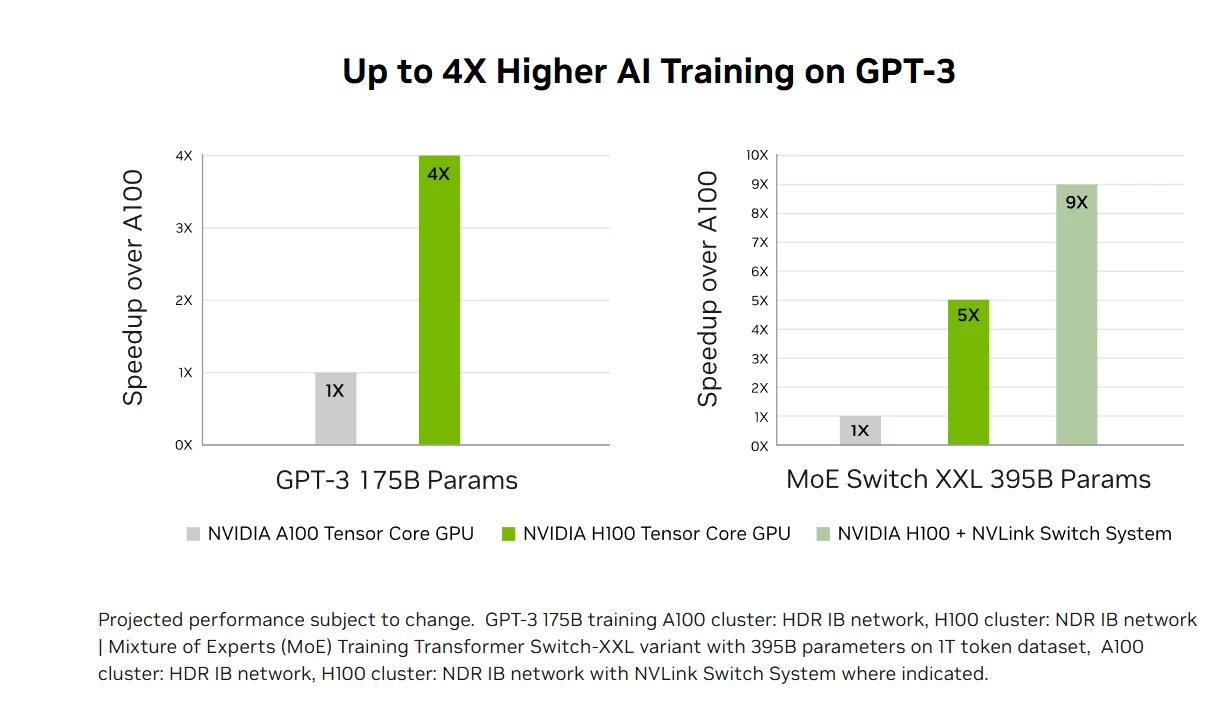
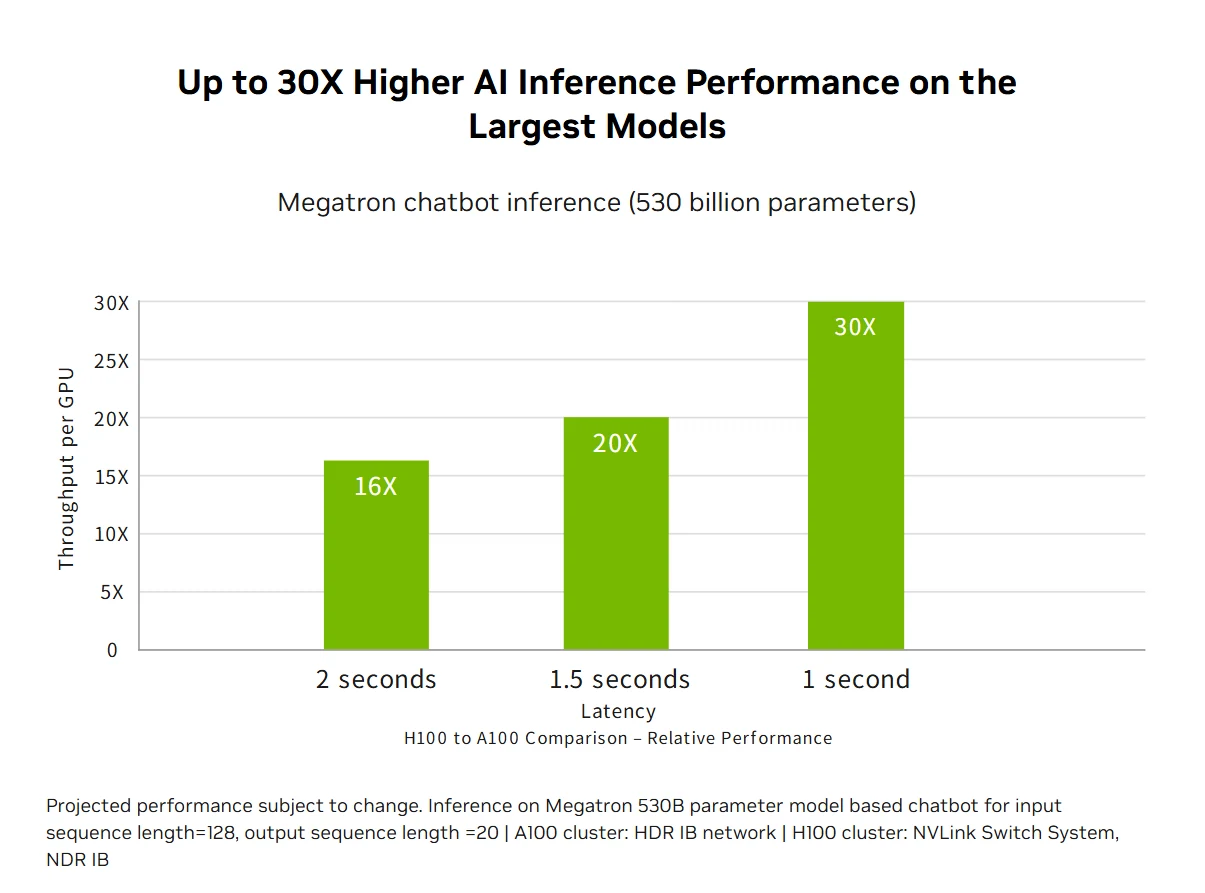
加速 AI 推論效能:H100 搭載支援從 FP64 到全新 FP8 格式所有精度的第四代 Tensor Cores,可提供市場領先的 AI 推論效能,加速比最高達 30 倍且延遲最低。這項多元適配性讓 H100 能加速各類商業應用的神經網路架構,同時降低大型語言模型的記憶體用量、維持準確率,是即時深度學習推論挑戰的全面解決方案。
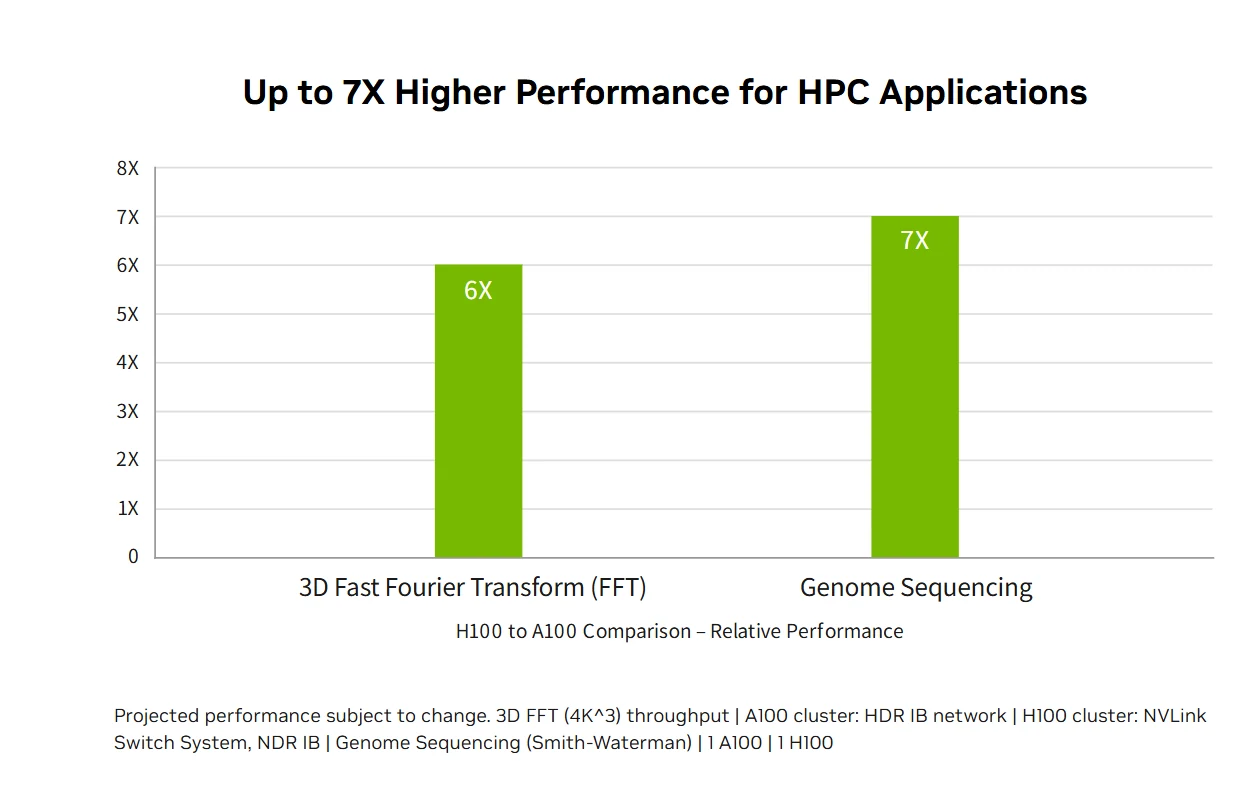
超算級 HPC 效能:NVIDIA H100 資料中心平台提供超越摩爾定律的超算級 HPC 效能,雙精度運算效能提升至 60 TFLOPS FP64,為上一代的 3 倍;同時無需修改任何程式碼,即可讓 AI 融合應用程式以 TF32 精度達到 1 PFLOPS 的吞吐量。全新的 DPX 指令集針對 Smith-Waterman DNA 定序等動態規劃算法,比 A100 快 7 倍、比 CPU 快 40 倍,結合傳統 HPC 與突破性 AI 能力,加速全球最重要研究領域的科學發現。
80GB 記憶體:大型模型的容量規劃
80GB HBM3 記憶體容量決定了哪些模型可以完整裝入 GPU 記憶體中運行。
單 GPU 部署:使用 FP16 精度時,可處理最高約 700 億至 750 億參數的模型,包括 Llama 2 70B、Code Llama 70B 等熱門模型與類似架構。使用 FP8 精度時,容量幾乎翻倍,可在單張 H100 上部署參數量接近 1400 億至 1500 億的模型。
多 GPU 擴展:更大的模型需要進行多 GPU 擴展。使用張量並行(Tensor Parallelism)技術時,2 張 H100 SXM GPU 可在 FP16 精度下處理最高 1500 億參數的模型;4 張 GPU 則可訓練與推論參數量超過 3000 億的模型。高頻寬 NVLink 互連技術確保 GPU 之間的通訊效率,在多個裝置上維持近乎線性的擴展效能。
記憶體密集型應用:除了模型參數外,大型語言模型的長上下文視窗也屬於記憶體密集型應用。需要超過 32K tokens 上下文視窗的應用,能特別受益於 H100 的大量記憶體資源。高解析度影像處理與科學資料集也能充分利用其充足的記憶體容量。
H100 SXM 與 PCIe 版本:效能與定價差異
| 規格 | H100 SXM | H100 PCIe |
|---|---|---|
| CUDA 核心數 | 16,896 | 14,592 |
| Tensor Cores 數量 | 528 | 456 |
| GPU 記憶體 | 80GB HBM3 | 80GB HBM2e |
| 記憶體頻寬 | 3.35TB/s | 2.0TB/s |
| TF32 效能 | 989 TFLOPS | 756 TFLOPS |
| FP16 效能 | 1,979 TFLOPS | 1,513 TFLOPS |
| FP8 效能 | 3,958 TFLOPS | 3,026 TFLOPS |
| 最大熱設計功耗(TDP) | 700W | 350W |
| 互連技術 | NVLink 900GB/s | NVLink 600GB/s |
| 規格形式 | SXM5 模組 | PCIe 雙槽位 |
SXM5 版本因其為最大化效能密度設計的優異架構,定價更高。SXM 規格形式直接整合至專用伺服器主機板,能實現最佳的供電與散熱效果。與 PCIe 版本相比,這項設計擁有高出 67% 的記憶體頻寬、多出 30% 的 Tensor Cores,以及快得多的多 GPU 通訊速度。
H100 與 A100 對比:哪款 GPU 適合你的工作負載?
| 規格 | NVIDIA A100 | NVIDIA H100 SXM5 |
|---|---|---|
| 規格形式 | SXM4 | SXM5 |
| 串流多處理器(SMs)數量 | 108 | 132 |
| 紋理處理集群(TPCs)數量 | 54 | 66 |
| 每 SM 的 FP32 核心數 | 64 | 128 |
| FP32 核心總數 | 6,912 | 16,896 |
| 每 SM 的 FP64 核心數(不含 Tensor Core) | 32 | 64 |
| FP64 核心總數(不含 Tensor Core) | 3,456 | 8,448 |
| Tensor Cores 數量 | 432 | 528 |
| 記憶體介面 | 5120-bit HBM2 | 5120-bit HBM3 |
| 電晶體數量 | 542 億 | 800 億 |
| 記憶體頻寬 | 1,555 GB/s | 3,000 GB/s |
| 最大熱設計功耗(TDP) | 400 W | 700 W |
與 A100 相比,H100 的處理核心數量多出 2.4 倍,記憶體速度幾乎翻倍(3000 GB/s 對比 1555 GB/s),電晶體數量多出 48%。不過其功耗也高出 75%(700W 對比 400W)。
H100 與 A100 成本對比
| 供應商/GPU 型號 | 搶實例定價 | 隨需定價 |
|---|---|---|
| Novita AI H100 SXM 80GB | 每小時 0.9 美元 | 每小時 1.8 美元 |
| RunPod H100 SXM 80GB | 每小時 1.75 美元 | 每小時 2.69 美元 |
| Novita AI A100 SXM 80GB | 每小時 0.8 美元 | 每小時 1.6 美元 |
| RunPod A100 SXM 80GB | 每小時 0.95 美元 | 每小時 1.74 美元 |
搶實例 vs 隨需實例:如何選擇合適的方案
選擇搶實例定價的時機:你的工作負載可以容忍偶爾中斷,且正在進行開發工作時。搶實例定價非常適合帶有檢查點(checkpoint)機制的訓練任務、研究專案與成本敏感的應用。對大多數開發與批次處理場景而言,50% 的價差足以抵消偶爾重啟的成本。
選擇隨需實例的時機:執行生產環境推論服務,或有嚴格時限的關鍵訓練任務時。隨需實例能提供穩定效能,無中斷風險,是對接客戶的應用與需要保證可用性的關鍵工作負載的必要選擇。
混合策略:許多企業會將搶實例用於開發與非關鍵工作負載來優化成本,同時保留隨需實例容量給生產環境服務。這種方式能在需要的地方確保服務可靠交付的同時,實現成本節約最大化。
如何在 Novita AI 上找到 H100 SXM 80GB 搶實例
在 Novita AI 上啟動 H100 搶實例的流程與其他 GPU 部署的簡化流程一致,已驗證可行性。
進入控制台
登入你的 Novita AI GPU 控制台,儀表板會即時顯示 GPU 可用數量、當前搶實例容量與你最近的部署記錄,這份概覽能幫助你明智決定部署實例的時機與位置。
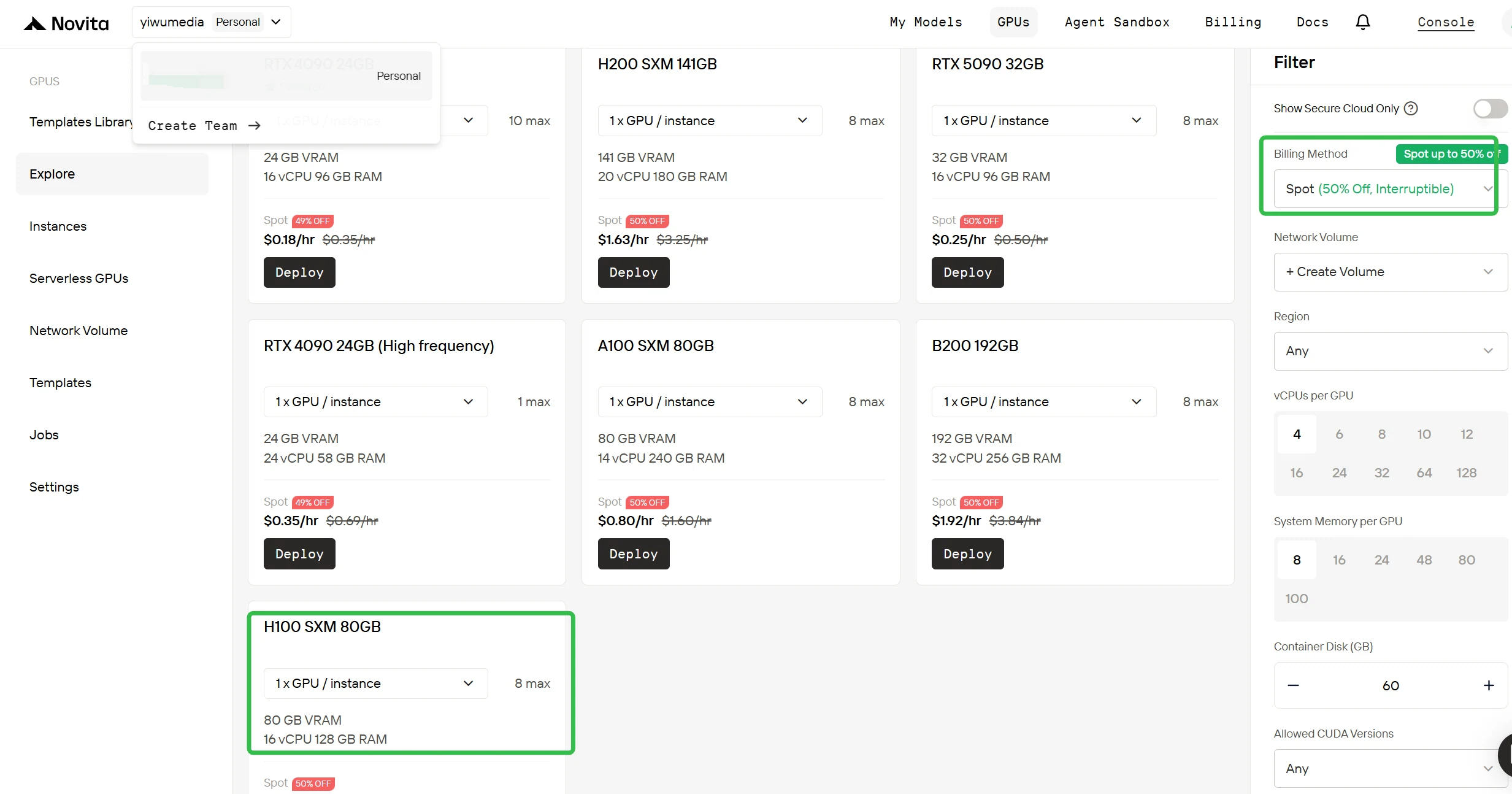
切換至搶實例計費
在右側邊欄的篩選器中,將計費方式從「隨需」改為「搶實例」,即可看到折扣後的價格。介面會立即更新顯示 H100 每小時 0.9 美元的價格,這種透明化設計能確保你在部署前清楚知道所需支付的費用。
Novita AI 搶實例的運作方式
搶實例利用 Novita AI 的閒置 GPU 容量,由於當一般實例需求上升時,這些容量可能被回收,因此提供更低的價格。
核心特性
可用性不固定:當 Novita AI 需要回收容量時,搶實例可能會被中斷。但這不代表隨機終止,平台會遵循結構化的流程並提前發送通知。
大幅成本節省:可獲得與隨需實例相同的 GPU 效能,價格最多低 50%。硬體與效能完全一致,僅有可用性保證不同。
保護期:每台搶實例在啟動後都有 1 小時的保護視窗,在此期間內無論容量需求如何,你的實例都不會被中斷。
提前通知:在容量回收前 1 小時會收到中斷通知,並有額外的 5 分鐘預警。這些通知讓你可以儲存工作、建立檢查點,並優雅地關閉應用程式。
與隨需實例的對比
| 特性 | 搶實例 | 隨需實例 |
|---|---|---|
| 定價 | 最多低 50% | 標準費率 |
| 可用性 | 取決於容量 | 隨時可用 |
| 中斷風險 | 可能被提前通知後回收 | 無中斷風險 |
| 保護期 | 啟動後 1 小時 | 持續保護 |
| 適用場景 | 具彈性、容錯的工作負載 | 關鍵、不可中斷的工作負載 |
透過為合適的工作負載選擇搶實例,你就能在優化運算成本的同時,使用同樣強大的 GPU 資源。
了解更多: Novita AI 搶實例指南
適合部署搶實例的智慧工作負載
開發與實驗類工作負載是搶實例定價的理想適用場景。模型原型設計、超參數調整與研究實驗都能享受成本優惠,同時容忍偶爾的中斷。這類工作負載通常能從檢查點策略中受益,並能在中斷後高效恢復運行。
批次處理與訓練任務:若設計時納入容錯機制,這類任務與搶實例的搭配效果極佳。大規模資料處理、定期建立檢查點的模型訓練與分散式運算任務都能實現顯著的成本節省。PyTorch、TensorFlow 等現代深度學習框架內建檢查點機制,可無縫整合使用。
時間具彈性的工作負載:沒有嚴格完成期限的工作負載能最大化搶實例的優勢。夜間訓練任務、週末批次處理與非關鍵推論任務可以完全使用搶實例,在維持高效能標準的同時實現成本優化最大化。
總結
Novita AI 上每小時 0.9 美元的 H100 SXM 80GB 搶實例定價,是目前取得頂級 AI 加速資源最具成本效益的方案。相較於 A100 的突破性效能提升,加上完整的軟體堆疊整合,這項服務能讓企業在不受預算限制的情況下應對高要求的 AI 工作負載。第四代 Tensor Cores、80GB HBM3 記憶體與智慧搶實例定價的結合,讓進階 AI 開發變得觸手可及。
無論是訓練大型語言模型、開發電腦視覺應用,還是進行科學研究,H100 SXM 都能為下一代 AI 專案提供所需的效能。今天就使用全球最先進的 AI 加速器開始開發——在 Novita AI 上部署您的 H100 SXM 80GB 搶實例,以無與倫比的價格體驗卓越效能。
常見問題
H100 SXM 與 PCIe 版本有什麼差異? H100 SXM 擁有更優異的效能,記憶體頻寬高出 67%(3.35TB/s 對比 2.0TB/s),Tensor Cores 數量也更多(528 個對比 456 個)。SXM 規格形式直接整合至伺服器主機板,能實現最佳的供電與散熱效果。PCIe 版本使用標準擴充槽,效能相對較低。
搶實例用於 AI 訓練的可靠性如何? Novita AI 的搶實例具備企業級可靠性功能,包含 1 小時的保證保護期。使用者會收到 60 分鐘的中斷提前通知與 5 分鐘的最終預警。現代 AI 框架支援透明化檢查點機制,能讓訓練任務在任何中斷後無縫恢復。
我可以將 H100 SXM 用於推論工作負載嗎? 當然可以。H100 SXM 非常適合推論工作負載,效能比上一代快最高達 30 倍。Transformer Engine 與 FP8 精度支援能為大型語言模型提供卓越的吞吐量,80GB 記憶體支援大批次與複雜模型部署,即使純推論應用使用搶實例定價也非常划算。
如果我的搶實例被中斷會怎麼樣? 你會在實例被中斷前收到 60 分鐘的提前通知,以及 5 分鐘的最終預警,有充足的時間儲存工作、建立檢查點並優雅關閉應用程式。現代 AI 框架透過內建的檢查點機制自動處理中斷情況,可直接使用儲存的檢查點重新啟動任務。
H100 與 A100 相比如何? 由於支援 FP8 與 Transformer Engine,H100 的訓練速度比 A100 快最高 6 倍,推論速度快最高 30 倍。其記憶體頻寬為 3.35TB/s,高於 A100 的約 2TB/s,能減少資料瓶頸。雖然 A100 對小型任務而言仍具成本效益,但 H100 在大型、時間敏感的任務上能提供更好的效能與更低的總成本。
Novita AI 是一個 AI 雲端平台,為開發者提供簡單的 API 介面,方便輕鬆部署 AI 模型,同時也提供平價且可靠的 GPU 雲端服務,用於建構與擴展 AI 應用。



