

Gemma 3 1B — наименьшая модель в семействе Gemma 3 от Google DeepMind, содержащая 1 миллиард параметров. Она разработана для мобильных и веб-приложений, оптимизирована для быстрой загрузки и низкой задержки. При квантовании её размер составляет всего 0,5 ГБ, поэтому она может работать полностью на устройстве, обеспечивая автономное использование AI без зависимости от облака, снижая затраты и повышая конфиденциальность. В этой статье вы получите бесплатный доступ к Gemma 3 1B, чтобы создавать собственные AI-приложения!
Обратите внимание: Novita AI запустила полностью бесплатный и очень стабильный API для Gemma 3 1B. Вам даже не нужно платить за оборудование — вы можете создать собственное мобильное приложение с поддержкой AI совершенно бесплатно.
Что такое Gemma 3 1B?
В отличие от более крупных моделей с 4B+ параметрами, у модели 1B не реализована возможность распознавания изображений, чтобы сохранить её легковесность.
| Характеристика | Детали |
|---|---|
| Тип модели | Малая языковая модель (SLM) |
| Количество параметров | 1 миллиард |
| Размер (при квантовании) | ~0,5 ГБ |
| Поддержка нескольких модальностей | Текстовый ввод, текстовый вывод |
| Контекстное окно | 128K |
| Поддержка языков | 140+ языков |
| Открытые веса | Варианты с предобучением и тонкой настройкой под инструкции |
Как обучалась модель Gemma 3 1B?
Обучающие данные:
Gemma 3 1B обучалась на разнообразном текстовом корпусе объемом примерно 2 триллиона токенов, включающем веб-страницы (на 140+ языках), код, а также математические и логические данные.
Преимущества данных по коду и математике:
Наличие наборов данных с кодом и математикой позволяет модели обрабатывать базовые вопросы по программированию и задачи на логическое мышление, несмотря на её небольшой размер. Примечательно, что Gemma 3 1B превосходит более старую модель Gemma 2 (2B), достигая этого при размере всего ~20% от её объема. Google связывает этот рост производительности с передовыми методами обучения и оптимизациями.
Что сделано в Gemma 3 1B для работы на маломощном оборудовании?
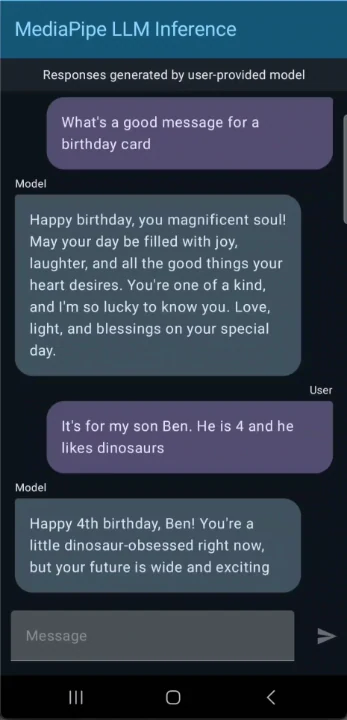
Используйте Gemma 3 1B для создания чат-приложения для Android
Квантование и оптимизация размера модели:
Gemma 3 1B использует Quantization-Aware Training (QAT), что позволяет снизить точность весов до 4 бит с минимальной потерей качества. Google предлагает квантованный чекпоинт int4 (~529 МБ), который сохраняет высокую точность при значительном уменьшении размера модели.
Улучшения архитектуры Transformer:
Модель оснащена оптимизированной архитектурой Transformer, включающей улучшенную обработку кэша ключ-значение для снижения нагрузки на пропускную способность памяти и обмен весами между фазами инференса «prefill» и «decode». Эти изменения повышают пропускную способность и снижают использование памяти, что делает модель очень эффективной для маломощного оборудования.
Где можно бесплатно скачать Gemma 3 1B?
Системные требования для Gemma 3 1B
Краткий итог: любой современный ПК или смартфон, выпущенный за последние несколько лет, потенциально может запускать Gemma 3 1B, если у него есть несколько ГБ свободной памяти.
| Категория | Детали |
|---|---|
| Память (RAM/VRAM) | 16-бит (BF16): 1,5 ГБ |
| 8-бит (SFP8): 1,1 ГБ | |
| 4-бит (INT4): 0,9 ГБ (861 МБ) | |
| Рекомендуется: устройства с 4 ГБ и более RAM для накладных расходов во время работы. | |
| Хранилище | Возможность автономной работы с AI делает компромисс по объему хранилища управляемым для мобильных устройств. |
| Производительность | Может работать на системах только с CPU (производительность ограничена). |
| GPU значительно повышает пропускную способность (см. метрики для Android): | |
| Prefill (токенов/с): CPU: 322,5/GPU 2585,9 | |
| Decode (токенов/с): CPU: 47,4/GPU 56,4 | |
| Требования к программному обеспечению | Python: Transformers 4.50+, Python 3.10+, PyTorch или TensorFlow (последние версии). |
| Мобильные/C++: Gemma.cpp (оптимизированный порт GGML/gguf) или среда выполнения Google LiteRT (требуется компилятор C++). | |
| Рекомендуется: для простоты используйте Transformers с PyTorch. |
Способы скачивания Gemma 3 1B
Веса модели Gemma 3 распространяются бесплатно, но вам нужно оплатить оборудование и согласиться с лицензией на ответственное использование AI.
Шаг 1: Выберите конфигурацию и оборудование
Вы можете запускать Gemma 3 1B одним из следующих способов:
- Вариант А: Используйте демо-приложение на Android
Скачайте готовое демо-приложение с GitHub и установите его на ваше Android-устройство:
$ wget https://github.com/google-ai-edge/mediapipe-samples/releases/download/v0.1.3/llm_inference_v0.1.3-debug.apk
$ adb install llm_inference_v0.1.3-debug.apk
- Вариант Б: Запустите на компьютере (CPU или GPU)
Если вы предпочитаете использовать компьютер, вы можете пропустить демо-приложение и запустить модель напрямую с помощью инструментов вродеgemma.cppили Python-библиотек (например,Transformers). Убедитесь, что ваше оборудование соответствует требованиям:
Шаг 2: Скачайте модель с Hugging Face
На экране выбора модели (или через вашу собственную конфигурацию) скачайте квантованную версию INT4 модели Gemma 3 1B. Вам нужно будет войти в аккаунт Hugging Face и принять условия использования. После скачивания модель объемом примерно 529 МБ автоматически оптимизируется под ваше устройство, этот процесс занимает всего несколько секунд.
Шаг 3: Запустите модель
Начните использовать Gemma 3! Взаимодействуйте с ней через текстовые задачи: например, суммирование статей, генерация постов для социальных сетей или ответы на вопросы. Для эффективной обработки на устройстве модель использует LLM Inference API от Google AI Edge.
Шаг 4: Настройте Gemma 3 под свои нужды (опционально)
Создайте собственную дообученную версию Gemma 3 1B, используя ваши данные. Следуйте инструкциям в предоставленном блокноте Colab, чтобы обучить, квантовать и развернуть вашу кастомную модель на мобильных устройствах или компьютерах.
Эта версия объединяет настройку приложения и выбор оборудования в один шаг, сохраняя понятность и логическую последовательность.
Где можно запускать Gemma 3 1B через API?
Обратите внимание: Novita AI запустила полностью бесплатный и очень стабильный API для Gemma 3 1B. Вам даже не нужно платить за оборудование — вы можете создать собственное мобильное приложение с поддержкой AI совершенно бесплатно.
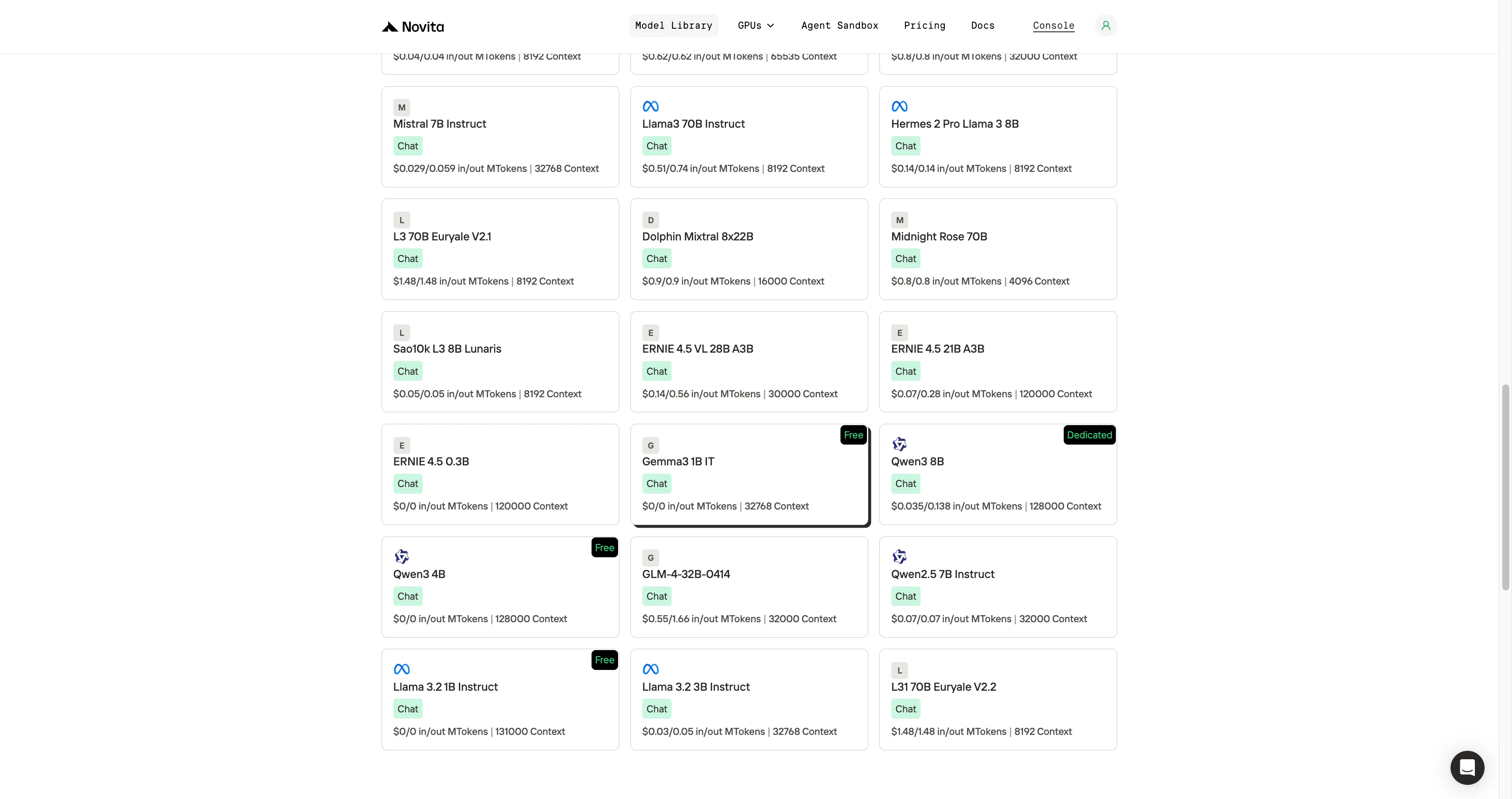
Шаг 1: Войдите в аккаунт и откройте библиотеку моделей
Войдите в свой аккаунт и нажмите кнопку Библиотека моделей.

Попробуйте Gemma 3 1B бесплатно сейчас!
Шаг 2: Выберите нужную модель
Просмотрите доступные варианты и выберите модель, которая подходит для ваших задач.
Шаг 3: Начните бесплатный пробный период
Начните бесплатный пробный период, чтобы изучить возможности выбранной модели.
Шаг 4: Получите ваш API-ключ
Для аутентификации в API мы предоставим вам новый API-ключ. Перейдя на страницу «Настройки», вы можете скопировать API-ключ, как показано на изображении.

Шаг 5: Установите API
Установите API с помощью менеджера пакетов, соответствующего вашему языку программирования.
После установки импортируйте необходимые библиотеки в вашу среду разработки. Инициализируйте API с вашим API-ключом, чтобы начать взаимодействие с Novita AI LLM. Ниже приведен пример использования API завершения чата для пользователей Python.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/openai",
api_key="session_tx4VxsO56QFZbUWkCyCGSwujMfCa0XiMF6_y7U_s60AujO5Ti-XaXPZLjd4WVHPMO4FuR2tLmuSy9n1m5iIdIw==",
)
model = "google/gemma-3-1b-it"
stream = True # or False
max_tokens = 65536
system_content = "Be a helpful assistant"
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Gemma 3 1B демонстрирует, как далеко продвинулся открытый AI: 1 миллиард параметров умещаются всего в ~0,5 ГБ. Модель работает полностью автономно на современных смартфонах или ПК, предлагая AI с низкой задержкой без затрат на облачные сервисы. Благодаря бесплатному доступу через Hugging Face, Kaggle или стабильный API от Novita AI вы можете экспериментировать, создавать прототипы или даже выпускать собственные мобильные приложения с поддержкой AI совершенно бесплатно. Gemma 3 1B делает концепцию «AI в кармане» практической реальностью.
Часто задаваемые вопросы
Нужна ли GPU для использования Gemma 3 1B?
Нет. Модель может работать на CPU или мобильном оборудовании с объемом RAM ≥4 ГБ. GPU повышают скорость, но не являются обязательными.
В чем разница между версиями Gemma 3 1B PT и IT?
PT = предобученная (исходная модель), IT = дообученная под инструкции (готовая для работы в чате/в роли ассистента). Большинству разработчиков рекомендуется использовать версию IT.
Как использовать Gemma 3 1B без скачивания весов модели?
Вы можете получить к ней мгновенный доступ через бесплатный API от Novita AI или протестировать её в демо-версии на Hugging Face.
Novita AI — это облачная AI-платформа, которая предоставляет разработчикам простой способ развертывать AI-модели с помощью нашего простого API, а также предлагает доступное и надежное облако GPU для разработки и масштабирования.



