

Gemma 3 1B est le plus petit membre de la famille Gemma 3 de Google DeepMind, avec 1 milliard de paramètres. Conçu pour les applications mobiles et web, il est optimisé pour des téléchargements rapides et une faible latence. Avec seulement 0,5 Go une fois quantifié, il peut fonctionner entièrement sur l’appareil, permettant une utilisation IA hors ligne sans dépendance au cloud, réduisant les coûts et améliorant la confidentialité. Cet article vous donne accès gratuitement à Gemma 3 1B pour vous aider à créer votre propre IA !
Notamment, Novita AI a lancé une API Gemma 3 1B entièrement gratuite et très stable. Vous n’avez même pas besoin de payer pour du matériel – vous pouvez créer votre propre application mobile alimentée par IA à coût zéro.
Qu’est-ce que Gemma 3 1B ?
Contrairement aux modèles plus grands de 4B+, le modèle 1B n’a pas reçu de capacité de compréhension d’image, pour rester léger.
| Fonctionnalité | Détails |
|---|---|
| Type de modèle | Petit modèle de langage (SLM) |
| Paramètres | 1 milliard |
| Taille (quantifié) | ~0,5 Go |
| Prise en charge multimodale | Entrée texte, sortie texte |
| Fenêtre de contexte | 128K |
| Prise en charge des langues | 140+ langues |
| Poids ouverts | Variantes pré-entraînées et ajustées par instruction |
Comment Gemma 3 1B est-il entraîné ?
Données d’entraînement :
Gemma 3 1B a été entraîné sur un corpus de texte diversifié d’environ 2 billions de tokens, comprenant des pages web (couvrant 140+ langues), du code et des données mathématiques ou logiques.
Avantages des données de code et de mathématiques :
L’inclusion d’ensembles de données de code et de mathématiques permet au modèle de traiter des questions de codage basiques et des tâches de raisonnement, malgré sa taille plus petite. De manière remarquable, Gemma 3 1B surpasse l’ancien modèle Gemma 2 (2B), en réalisant cela tout en n’étant que ~20% de sa taille. Google attribue ce gain de performance à des techniques d’entraînement avancées et des optimisations.
Qu’a fait Gemma 3 1B pour fonctionner sur du matériel peu puissant ?
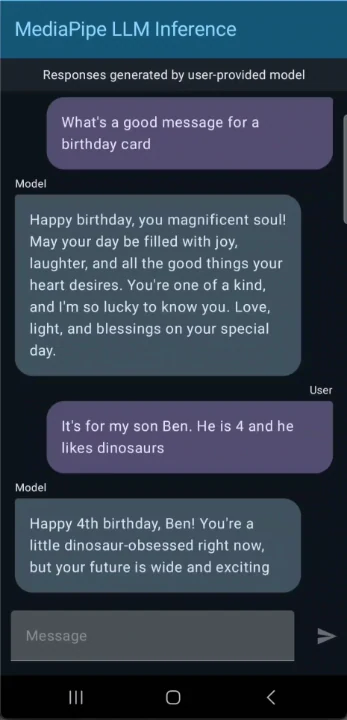
Utiliser Gemma 3 1B pour créer une application de chat pour Android
Quantification et optimisation de la taille du modèle :
Gemma 3 1B utilise l’entraînement conscient de la quantification (QAT), permettant une précision des poids jusqu’à 4 bits avec une perte de qualité minimale. Google propose un point de contrôle quantifié int4 (~529 Mo), qui préserve une haute précision tout en réduisant drastiquement la taille du modèle.
Améliorations de l’architecture Transformer :
Le modèle dispose d’une architecture Transformer optimisée, incluant une gestion améliorée du cache clé-valeur pour réduire la surcharge de bande passante mémoire et un partage de poids entre les phases de « préremplissage » et de « décodage » de l’inférence. Ces ajustements augmentent le débit et réduisent l’utilisation de la mémoire, le rendant très efficace pour du matériel limité.
Où puis-je télécharger Gemma 3 1B gratuitement ?
Configuration système requise pour Gemma 3 1B
En résumé, tout PC moderne ou smartphone des dernières années peut potentiellement faire fonctionner Gemma 3 1B, à condition de disposer de quelques Go de mémoire disponibles.
| Catégorie | Détails |
|---|---|
| Mémoire (RAM/VRAM) | 16 bits (BF16) : 1,5 Go |
| 8 bits (SFP8) : 1,1 Go | |
| 4 bits (INT4) : 0,9 Go (861 Mo) | |
| Recommandé : Appareils avec 4 Go ou plus de RAM pour la surcharge d’exécution. | |
| Stockage | La capacité d’IA hors ligne rend le compromis de stockage gérable pour les appareils mobiles. |
| Performance | Peut fonctionner sur des systèmes à processeur uniquement (performances limitées). |
| Le GPU améliore considérablement le débit (voir les métriques Android) : | |
| Préremplissage (tokens/sec) : CPU : 322,5 / GPU 2585,9 | |
| Décodage (tokens/sec) : CPU : 47,4 / GPU 56,4 | |
| Exigences logicielles | Python : Transformers 4.50+, Python 3.10+, PyTorch ou TensorFlow (dernières versions). |
| Mobile/C++ : Gemma.cpp (port optimisé GGML/gguf) ou runtime Google LiteRT (compilateur C++ nécessaire). | |
| Recommandé : Utilisez Transformers avec PyTorch pour plus de simplicité. |
Méthodes de téléchargement de Gemma 3 1B
Les poids de Gemma 3 sont gratuits, mais vous devez payer pour le matériel et accepter une licence d’IA responsable.
Étape 1 : Choisissez votre configuration et votre matériel
Vous pouvez faire fonctionner Gemma 3 1B de l’une des manières suivantes :
- Option A : Utiliser l’application de démo sur Android
Téléchargez l’application de démo préconstruite depuis GitHub et installez-la sur votre appareil Android :
$ wget https://github.com/google-ai-edge/mediapipe-samples/releases/download/v0.1.3/llm_inference_v0.1.3-debug.apk
$ adb install llm_inference_v0.1.3-debug.apk
- Option B : Exécuter sur votre ordinateur (CPU ou GPU)
Si vous préférez utiliser un ordinateur, vous pouvez ignorer l’application de démo et exécuter le modèle directement à l’aide d’outils commegemma.cppou des bibliothèques Python (par ex.Transformers). Assurez-vous que votre matériel répond aux exigences :
Étape 2 : Télécharger le modèle depuis Hugging Face
Sur l’écran de sélection du modèle (ou via votre propre configuration), téléchargez la version INT4 quantifiée de Gemma 3 1B. Vous devrez vous connecter à Hugging Face et accepter les conditions d’utilisation. Le modèle, d’environ 529 Mo, s’optimisera automatiquement pour votre appareil après le téléchargement, un processus qui ne prend que quelques secondes.
Étape 3 : Exécuter le modèle
Commencez à utiliser Gemma 3 ! Interagissez avec lui via des tâches textuelles, comme résumer des articles, générer des publications sur les réseaux sociaux ou répondre à des questions. Le modèle exploite l’API d’inférence LLM de Google AI Edge pour un traitement efficace sur l’appareil.
Étape 4 : Personnaliser Gemma 3 (facultatif)
Créez votre propre version affinée de Gemma 3 1B en utilisant vos données. Suivez le notebook Colab fourni pour entraîner, quantifier et déployer votre modèle personnalisé sur des appareils mobiles ou des ordinateurs.
Cette version fusionne la configuration de l’application et la sélection du matériel en une seule étape tout en maintenant la clarté et le flux logique.
Où puis-je exécuter Gemma 3 1B via API ?
Notamment, Novita AI a lancé une API Gemma 3 1B entièrement gratuite et très stable. Vous n’avez même pas besoin de payer pour du matériel – vous pouvez créer votre propre application mobile alimentée par IA à coût zéro.
Étape 1 : Connectez-vous et accédez à la bibliothèque de modèles
Connectez-vous à votre compte et cliquez sur le bouton Bibliothèque de modèles.

Essayez Gemma 3 1B gratuitement maintenant !
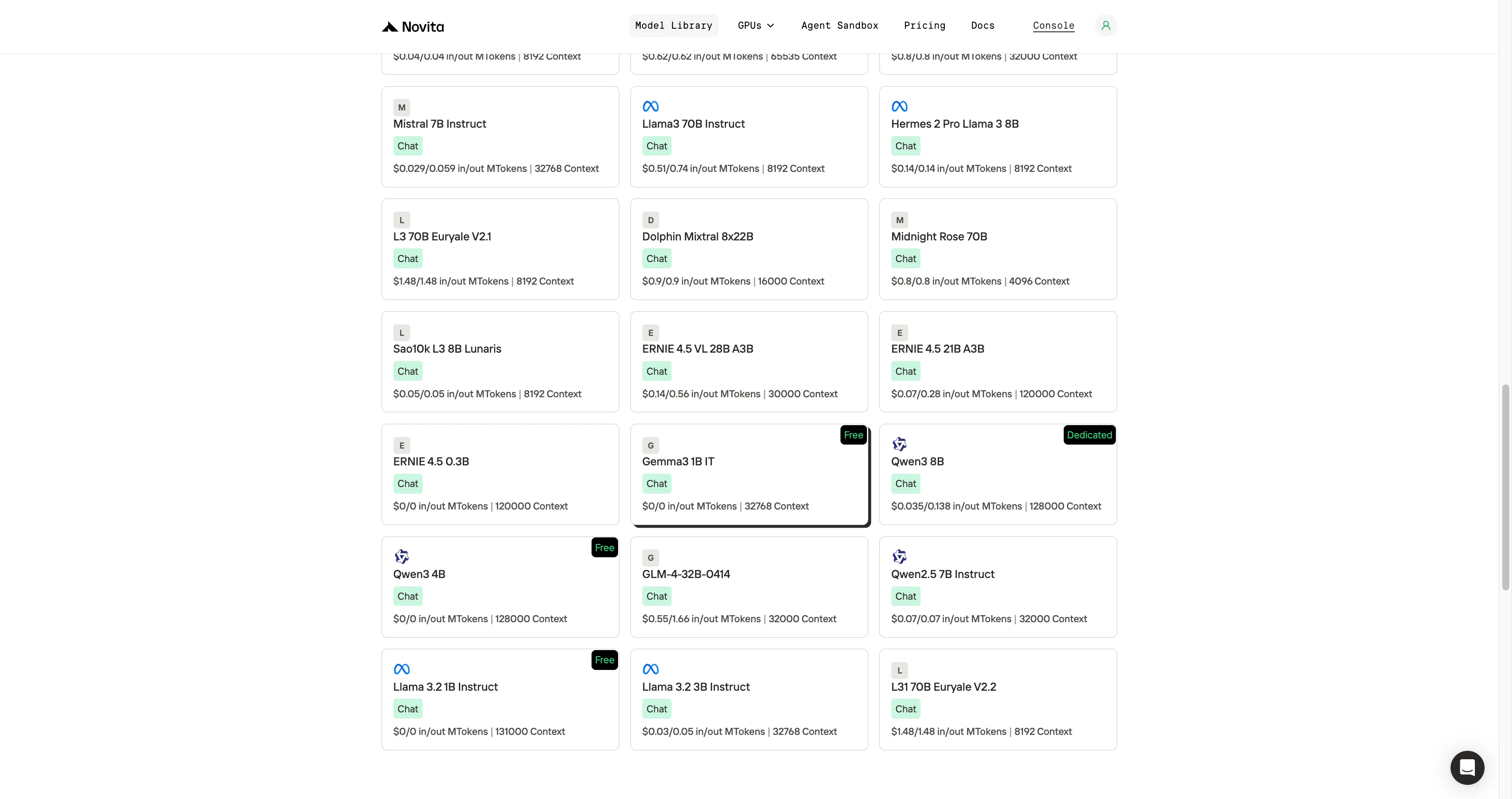
Étape 2 : Choisissez votre modèle
Parcourez les options disponibles et sélectionnez le modèle qui correspond à vos besoins.
Étape 3 : Commencez votre essai gratuit
Commencez votre essai gratuit pour explorer les capacités du modèle sélectionné.
Étape 4 : Récupérez votre clé API
Pour vous authentifier auprès de l’API, nous vous fournirons une nouvelle clé API. En accédant à la page « Paramètres », vous pouvez copier la clé API comme indiqué sur l’image.

Étape 5 : Installez l’API
Installez l’API à l’aide du gestionnaire de packages spécifique à votre langage de programmation.
Après l’installation, importez les bibliothèques nécessaires dans votre environnement de développement. Initialisez l’API avec votre clé API pour commencer à interagir avec le LLM Novita AI. Voici un exemple d’utilisation de l’API de complétion de chat pour les utilisateurs Python.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/openai",
api_key="session_tx4VxsO56QFZbUWkCyCGSwujMfCa0XiMF6_y7U_s60AujO5Ti-XaXPZLjd4WVHPMO4FuR2tLmuSy9n1m5iIdIw==",
)
model = "google/gemma-3-1b-it"
stream = True # or False
max_tokens = 65536
system_content = "Be a helpful assistant"
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Gemma 3 1B montre à quel point l’IA ouverte a progressé – en intégrant 1 milliard de paramètres dans seulement ~0,5 Go. Il fonctionne entièrement hors ligne sur les smartphones ou PC modernes, offrant une IA à faible latence sans coûts cloud. Avec un accès gratuit via Hugging Face, Kaggle ou l’API stable de Novita AI, vous pouvez expérimenter, créer des prototypes ou même déployer votre propre application mobile alimentée par IA à coût zéro. Gemma 3 1B rend « l’IA dans votre poche » une réalité pratique.
Questions fréquemment posées
Ai-je besoin d’un GPU pour utiliser Gemma 3 1B ?
Non. Il peut fonctionner sur du matériel à processeur ou mobile avec ≥4 Go de RAM. Les GPU améliorent la vitesse mais ne sont pas nécessaires.
Quelle est la différence entre les versions PT et IT de Gemma 3 1B ?
PT = pré-entraîné (modèle brut), IT = ajusté par instruction (prêt pour chat/assistant). La plupart des développeurs doivent utiliser la version IT.
Comment puis-je utiliser Gemma 3 1B sans télécharger les poids ?
Vous pouvez y accéder instantanément via l’API gratuite de Novita AI, ou le tester dans une démo Hugging Face.
Novita AI est une plateforme cloud IA qui offre aux développeurs un moyen simple de déployer des modèles IA grâce à notre API simple, tout en fournissant un cloud GPU abordable et fiable pour construire et mettre à l’échelle.



