

Gemma 3 1BはGoogle DeepMindのGemma 3ファミリーで最小のメンバーで、10億個のパラメータを搭載しています。モバイル・Webアプリケーション向けに設計されており、高速ダウンロードと低遅延に最適化されています。量子化時にはわずか0.5GBで、クラウドに依存せずにオフラインでAIを利用できるため、コスト削減とプライバシー向上にも貢献します。この記事ではGemma 3 1Bに無料でアクセスし、独自のAIを構築する方法を解説します!
特に、Novita AIは完全無料で非常に安定したGemma 3 1B APIを提供開始しました。ハードウェア代を支払う必要すらなく、ゼロコストで独自のAI搭載モバイルアプリを構築できます。
Gemma 3 1Bとは?
4B以上の大規模モデルとは異なり、1Bモデルは軽量化のために画像理解機能が搭載されていません。
| 機能 | 詳細 |
|---|---|
| モデルタイプ | 小型言語モデル(SLM) |
| パラメータ数 | 10億個 |
| サイズ(量子化時) | 約0.5GB |
| マルチモーダル対応 | テキスト入力、テキスト出力 |
| コンテキストウィンドウ | 128K |
| 言語対応 | 140以上の言語 |
| オープンウェイト | 事前学習版とインストラクションチューニング版の2種類 |
Gemma 3 1Bの学習方法は?
学習データ:
Gemma 3 1Bは約2兆トークンの多様なテキストコーパスで学習されており、Webページ(140以上の言語で構成)、コード、数学・論理データが含まれています。
コード・数学データのメリット:
コードと数学のデータセットが含まれていることで、小型モデルでありながら基本的なコーディングの質問や推論タスクを処理できます。特筆すべきは、Gemma 3 1Bが旧モデルの**Gemma 2(2B)よりも性能が高いことです。これはサイズがわずか約20%**しかないにもかかわらずです。Googleはこの性能向上を、高度な学習技術と最適化によるものと説明しています。
Gemma 3 1Bが小型ハードウェアで動作するための工夫は?
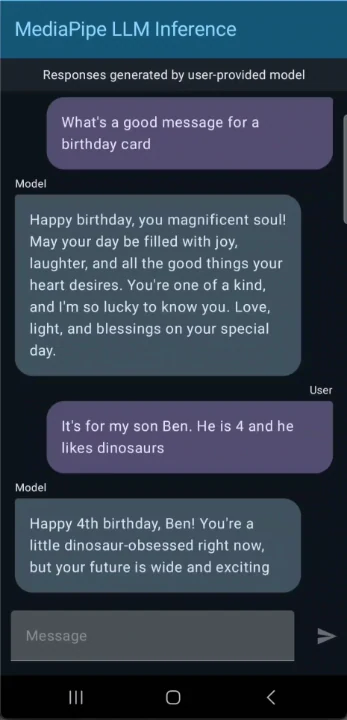
Gemma 3 1BでAndroid向けチャットアプリを構築する方法
量子化とモデルサイズの最適化:
Gemma 3 1Bは量子化対応学習(QAT: Quantization-Aware Training)を採用しており、品質の低下を最小限に抑えつつ重みの精度を4ビットまで下げられます。Googleはint4量子化済みチェックポイント(約529MB)を提供しており、モデルサイズを大幅に削減しつつ高い精度を維持しています。
Transformerアーキテクチャの改善:
本モデルは最適化されたTransformerアーキテクチャを採用しており、メモリバンド幅のオーバーヘッドを削減するキー・バリューキャッシュ処理の改善、推論の「プリフィル」フェーズと「デコード」フェーズでの重み共有などが行われています。これらの調整によりスループットが向上し、メモリ使用量が削減されるため、限られたハードウェアでも非常に効率的に動作します。
Gemma 3 1Bを無料でダウンロードする方法は?
Gemma 3 1Bのシステム要件
まとめると、数GBのメモリが利用可能であれば、ここ数年のモダンなPCやスマートフォンであればGemma 3 1Bを実行できる可能性があります。
| カテゴリ | 詳細 |
|---|---|
| メモリ(RAM/VRAM) | 16ビット(BF16):1.5GB |
| 8ビット(SFP8):1.1GB | |
| 4ビット(INT4):0.9GB(861MB) | |
| 推奨:ランタイムのオーバーヘッドを考慮し、4GB以上のRAMを搭載したデバイスを使用してください。 | |
| ストレージ | オフラインAI機能により、モバイルデバイスでもストレージのトレードオフが管理しやすくなっています。 |
| パフォーマンス | CPUのみのシステムでも実行可能(性能は制限されます)。 |
| GPUを使用するとスループットが大幅に向上します(Androidの測定値を参照): | |
| プリフィル(トークン/秒):CPU 322.5 / GPU 2585.9 | |
| デコード(トークン/秒):CPU 47.4 / GPU 56.4 | |
| ソフトウェア要件 | Python:Transformers 4.50以降、Python 3.10以降、PyTorchまたはTensorFlow(最新版) |
| モバイル/C++:Gemma.cpp(最適化されたGGML/ggufポート)またはGoogle LiteRTランタイム(C++コンパイラが必要) | |
| 推奨:簡単に利用するため、PyTorchとTransformersを組み合わせて使用することをおすすめします。 |
Gemma 3 1Bのダウンロード方法
Gemma 3の重みデータは無料ですが、ハードウェア代は自己負担となり、責任あるAI利用ライセンスに同意する必要があります。
ステップ1:実行環境とハードウェアを選択する
Gemma 3 1Bは以下のいずれかの方法で実行できます:
- オプションA:Androidでデモアプリを使用する
GitHubからビルド済みのデモアプリをダウンロードし、Androidデバイスにインストールします:
$ wget https://github.com/google-ai-edge/mediapipe-samples/releases/download/v0.1.3/llm_inference_v0.1.3-debug.apk
$ adb install llm_inference_v0.1.3-debug.apk
- オプションB:PC(CPU/GPU)で実行する
PCを使用する場合は、デモアプリをスキップし、gemma.cppやPythonライブラリ(例:Transformers)などのツールを使ってモデルを直接実行できます。ハードウェアが要件を満たしていることを確認してください:
ステップ2:Hugging Faceからモデルをダウンロードする
モデル選択画面(または独自の環境)から、Gemma 3 1Bの量子化INT4版をダウンロードします。Hugging Faceにサインインし、利用規約に同意する必要があります。約529MBのモデルはダウンロード後、数秒で自動的にデバイスに最適化されます。
ステップ3:モデルを実行する
Gemma 3の使用を開始しましょう!記事の要約、SNS投稿の生成、質問への回答などのテキストベースのタスクを通じて対話できます。本モデルはGoogle AI EdgeのLLM推論APIを活用し、デバイス上での効率的な処理を実現しています。
ステップ4:Gemma 3をカスタマイズ(任意)
独自のデータを使ってGemma 3 1Bのファインチューニング版を作成できます。提供されているColabノートブックに従って、カスタマイズしたモデルの学習・量子化・モバイルデバイスやPCへのデプロイを行えます。
このバージョンでは、アプリのセットアップとハードウェア選択を1つのステップに統合し、明確さと論理的な流れを維持しています。
API経由でGemma 3 1Bを実行する方法は?
特に、Novita AIは完全無料で非常に安定したGemma 3 1B APIを提供開始しました。ハードウェア代を支払う必要すらなく、ゼロコストで独自のAI搭載モバイルアプリを構築できます。
ステップ1:ログインしてモデルライブラリにアクセスする
アカウントにログインし、モデルライブラリボタンをクリックします。

ステップ2:モデルを選択する
利用可能なモデルを閲覧し、ニーズに合ったモデルを選択します。
ステップ3:無料トライアルを開始する
選択したモデルの機能を試すために、無料トライアルを開始します。
ステップ4:APIキーを取得する
APIでの認証のために、新しいAPIキーを発行します。「設定」ページに移動すると、画像の指示に従ってAPIキーをコピーできます。

ステップ5:APIをインストールする
使用するプログラミング言語に対応したパッケージマネージャーを使ってAPIをインストールします。
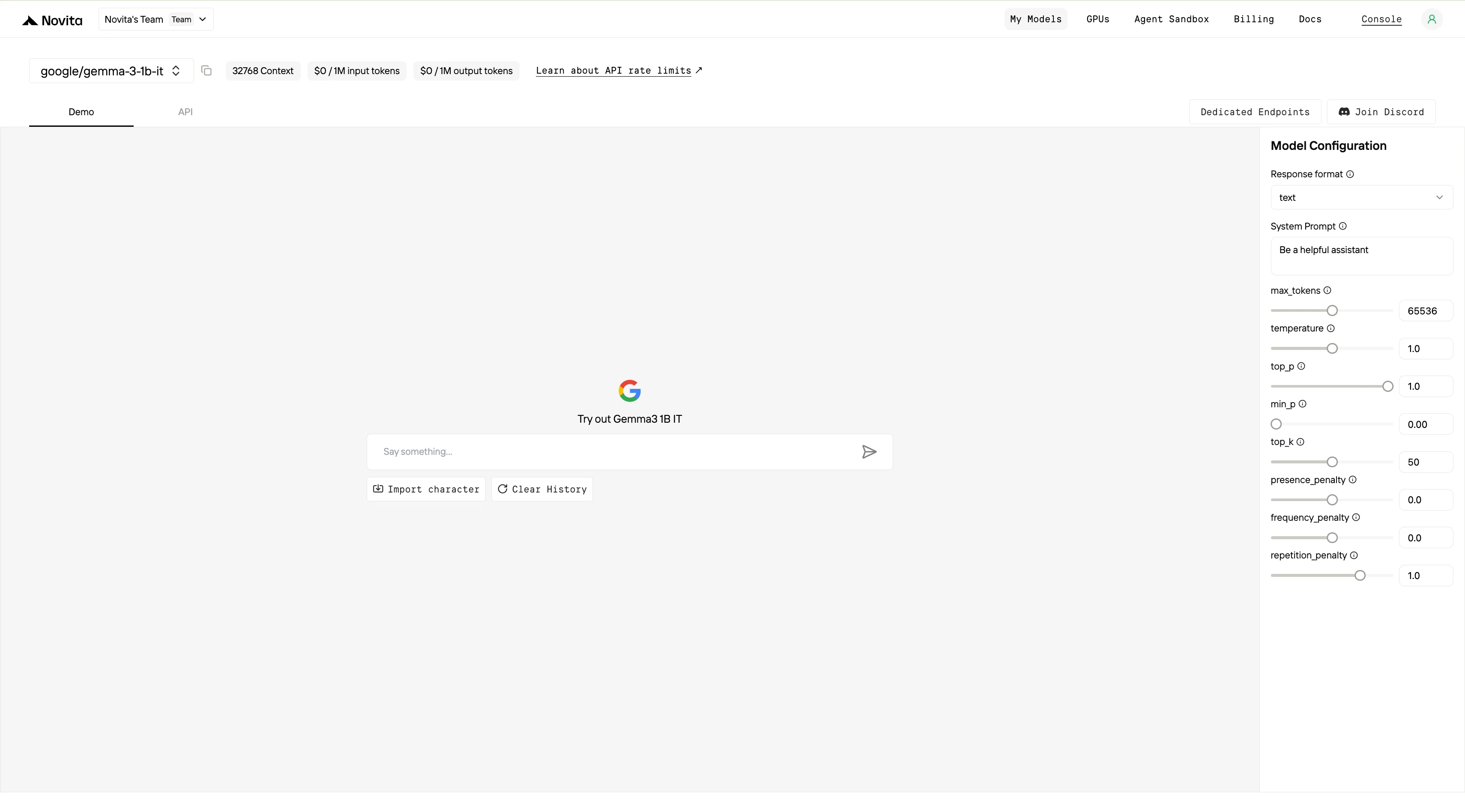
インストール後、開発環境に必要なライブラリをインポートします。APIキーを使ってAPIを初期化することで、Novita AI LLMとの対話を開始できます。以下はPythonユーザー向けのチャット補完APIの使用例です。
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/openai",
api_key="session_tx4VxsO56QFZbUWkCyCGSwujMfCa0XiMF6_y7U_s60AujO5Ti-XaXPZLjd4WVHPMO4FuR2tLmuSy9n1m5iIdIw==",
)
model = "google/gemma-3-1b-it"
stream = True # or False
max_tokens = 65536
system_content = "Be a helpful assistant"
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Gemma 3 1Bは、オープンAIの進歩を示すものであり、10億個のパラメータをわずか約0.5GBに収めています。最新のスマートフォンやPCで完全にオフラインで動作し、クラウドコストなしで低遅延のAIを提供します。Hugging Face、Kaggle、またはNovita AIの安定したAPIを介して無料でアクセスできるため、実験やプロトタイプ作成はもちろん、ゼロコストで独自のAI搭載モバイルアプリをリリースすることも可能です。Gemma 3 1Bは「ポケットの中のAI」を現実のものにします。
よくある質問
Gemma 3 1Bを使用するためにGPUは必要ですか?
いいえ。4GB以上のRAMを搭載したCPUまたはモバイルハードウェアで実行できます。GPUは速度を向上させますが、必須ではありません。
Gemma 3 1BのPT版とIT版の違いは何ですか?
PTは事前学習済みの(未チューニングの)モデル、ITはインストラクションチューニング済み(チャット・アシスタント対応)のモデルです。ほとんどの開発者はIT版を使用することをおすすめします。
重みデータをダウンロードせずにGemma 3 1Bを使用する方法は?
Novita AIの無料APIを介してすぐにアクセスするか、Hugging Faceのデモでテストできます。
Novita AIは、シンプルなAPIを使ってAIモデルを簡単にデプロイできる開発者向けAIクラウドプラットフォームであり、構築・スケーリングのための手頃で信頼性の高いGPUクラウドも提供しています。



