

Gemma 3 1B es el miembro más pequeño de la familia Gemma 3 de Google DeepMind, con 1 mil millones de parámetros. Diseñado para aplicaciones móviles y web, está optimizado para descargas rápidas y baja latencia. Con solo 0,5 GB cuando está cuantizado, puede ejecutarse completamente en el dispositivo, lo que permite el uso de IA sin conexión sin dependencia de la nube, reduce costos y mejora la privacidad. Este artículo te dará acceso gratuito a Gemma 3 1B para ayudarte a crear tu propia IA.
Cabe destacar que Novita AI ha lanzado una API de Gemma 3 1B completamente gratuita y muy estable. No necesitas pagar por hardware: puedes crear tu propia aplicación móvil impulsada por IA sin costo alguno.
¿Qué es Gemma 3 1B?
A diferencia de los modelos más grandes de 4B+, el modelo 1B no cuenta con capacidad de comprensión de imágenes, para mantenerlo ligero.
| Característica | Detalles |
|---|---|
| Tipo de modelo | Modelo de lenguaje pequeño (SLM) |
| Parámetros | 1 mil millones |
| Tamaño (cuantizado) | ~0,5 GB |
| Soporte multimodal | Entrada de texto, salida de texto |
| Ventana de contexto | 128K |
| Soporte de idiomas | Más de 140 idiomas |
| Pesos abiertos | Variantes preentrenadas y ajustadas por instrucciones |
¿Cómo se entrena Gemma 3 1B?
Datos de entrenamiento:
Gemma 3 1B se entrenó con un corpus de texto diverso de aproximadamente 2 billones de tokens, que incluye páginas web (de más de 140 idiomas), código y datos matemáticos o lógicos.
Ventajas de los datos de código y matemáticas:
La inclusión de conjuntos de datos de código y matemáticas permite al modelo manejar preguntas básicas de programación y tareas de razonamiento, a pesar de su tamaño reducido. Sorprendentemente, Gemma 3 1B supera al modelo anterior Gemma 2 (2B), logrando esto mientras que su tamaño es solo de ~20% del de este último. Google atribuye este aumento de rendimiento a técnicas de entrenamiento avanzadas y optimizaciones.
¿Qué ha hecho Gemma 3 1B para funcionar en hardware pequeño?
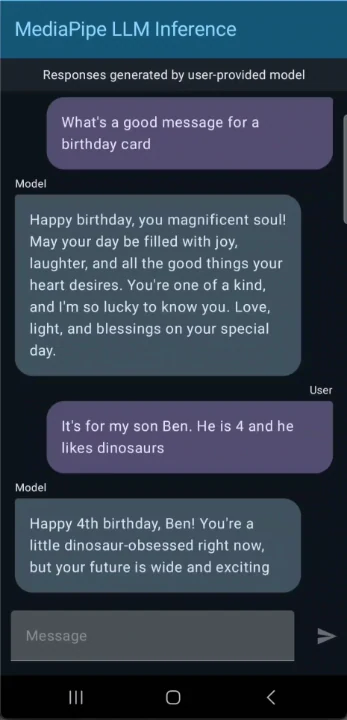
Usa Gemma 3 1B para crear una aplicación de chat para Android
Cuantización y optimización del tamaño del modelo:
Gemma 3 1B utiliza Entrenamiento Consciente de Cuantización (QAT), que permite reducir la precisión de los pesos hasta 4 bits con una pérdida de calidad mínima. Google ofrece un punto de control cuantizado a int4 (~529 MB), que preserva una alta precisión al tiempo que reduce drásticamente el tamaño del modelo.
Mejoras en la arquitectura Transformer:
El modelo cuenta con una arquitectura Transformer optimizada, que incluye una mejora en el manejo de la caché de valores clave para reducir la sobrecarga de ancho de banda de memoria y compartición de pesos entre las fases de “prefill” y “decode” de la inferencia. Estos ajustes aumentan el rendimiento y reducen el uso de memoria, lo que lo hace muy eficiente para hardware limitado.
¿Dónde puedo descargar Gemma 3 1B gratis?
Requisitos del sistema de Gemma 3 1B
En resumen, cualquier PC moderno o teléfono inteligente de los últimos años puede ejecutar Gemma 3 1B, siempre que tenga unos pocos GB de memoria disponibles.
| Categoría | Detalles |
|---|---|
| Memoria (RAM/VRAM) | 16-bit (BF16): 1,5 GB |
| 8-bit (SFP8): 1,1 GB | |
| 4-bit (INT4): 0,9 GB (861 MB) | |
| Recomendado: Dispositivos con 4 GB o más de RAM para la sobrecarga de ejecución. | |
| Almacenamiento | La capacidad de IA sin conexión hace que el compromiso de almacenamiento sea manejable para dispositivos móviles. |
| Rendimiento | Puede ejecutarse en sistemas solo con CPU (rendimiento limitado). |
| La GPU mejora significativamente el rendimiento (consulte las métricas de Android): | |
| Prefill (tokens/sec): CPU: 322.5/GPU 2585.9 | |
| Decode (tokens/sec): CPU: 47.4/GPU 56.4 | |
| Requisitos de software | Python: Transformers 4.50+, Python 3.10+, PyTorch o TensorFlow (versiones más recientes). |
| Móvil/C++: Gemma.cpp (puerto GGML/gguf optimizado) o tiempo de ejecución Google LiteRT (se necesita compilador de C++). | |
| Recomendado: Usa Transformers con PyTorch para mayor simplicidad. |
Métodos para descargar Gemma 3 1B
Los pesos de Gemma 3 son gratuitos, pero debes pagar por el hardware y aceptar una licencia de IA responsable.
Paso 1: Elige tu configuración y hardware
Puedes ejecutar Gemma 3 1B de una de las siguientes formas:
- Opción A: Usa la aplicación de demostración en Android
Descarga la aplicación de demostración precompilada de GitHub e instálala en tu dispositivo Android:
$ wget https://github.com/google-ai-edge/mediapipe-samples/releases/download/v0.1.3/llm_inference_v0.1.3-debug.apk
$ adb install llm_inference_v0.1.3-debug.apk
- Opción B: Ejecútalo en tu computadora (CPU o GPU)
Si prefieres usar una computadora, puedes omitir la aplicación de demostración y ejecutar el modelo directamente con herramientas comogemma.cppo bibliotecas de Python (por ejemplo,Transformers). Asegúrate de que tu hardware cumpla con los requisitos:
Paso 2: Descarga el modelo desde Hugging Face
En la pantalla de selección de modelos (o a través de tu propia configuración), descarga la versión cuantizada INT4 de Gemma 3 1B. Necesitarás iniciar sesión en Hugging Face y aceptar los términos de uso. El modelo, de aproximadamente 529 MB, se optimizará automáticamente para tu dispositivo después de descargarlo, un proceso que solo tarda unos segundos.
Paso 3: Ejecuta el modelo
¡Comienza a usar Gemma 3! Interactúa con él mediante tareas basadas en texto, como resumir artículos, generar publicaciones para redes sociales o responder preguntas. El modelo aprovecha la API de inferencia LLM de Google AI Edge para un procesamiento eficiente en el dispositivo.
Paso 4: Personaliza Gemma 3 (opcional)
Crea tu propia versión de ajuste fino de Gemma 3 1B usando tus datos. Sigue el cuaderno de Colab proporcionado para entrenar, cuantizar e implementar tu modelo personalizado en dispositivos móviles o computadoras.
Esta versión combina la configuración de la aplicación y la selección de hardware en un solo paso, manteniendo la claridad y el flujo lógico.
¿Dónde puedo ejecutar Gemma 3 1B mediante una API?
Cabe destacar que Novita AI ha lanzado una API de Gemma 3 1B completamente gratuita y muy estable. No necesitas pagar por hardware: puedes crear tu propia aplicación móvil impulsada por IA sin costo alguno.
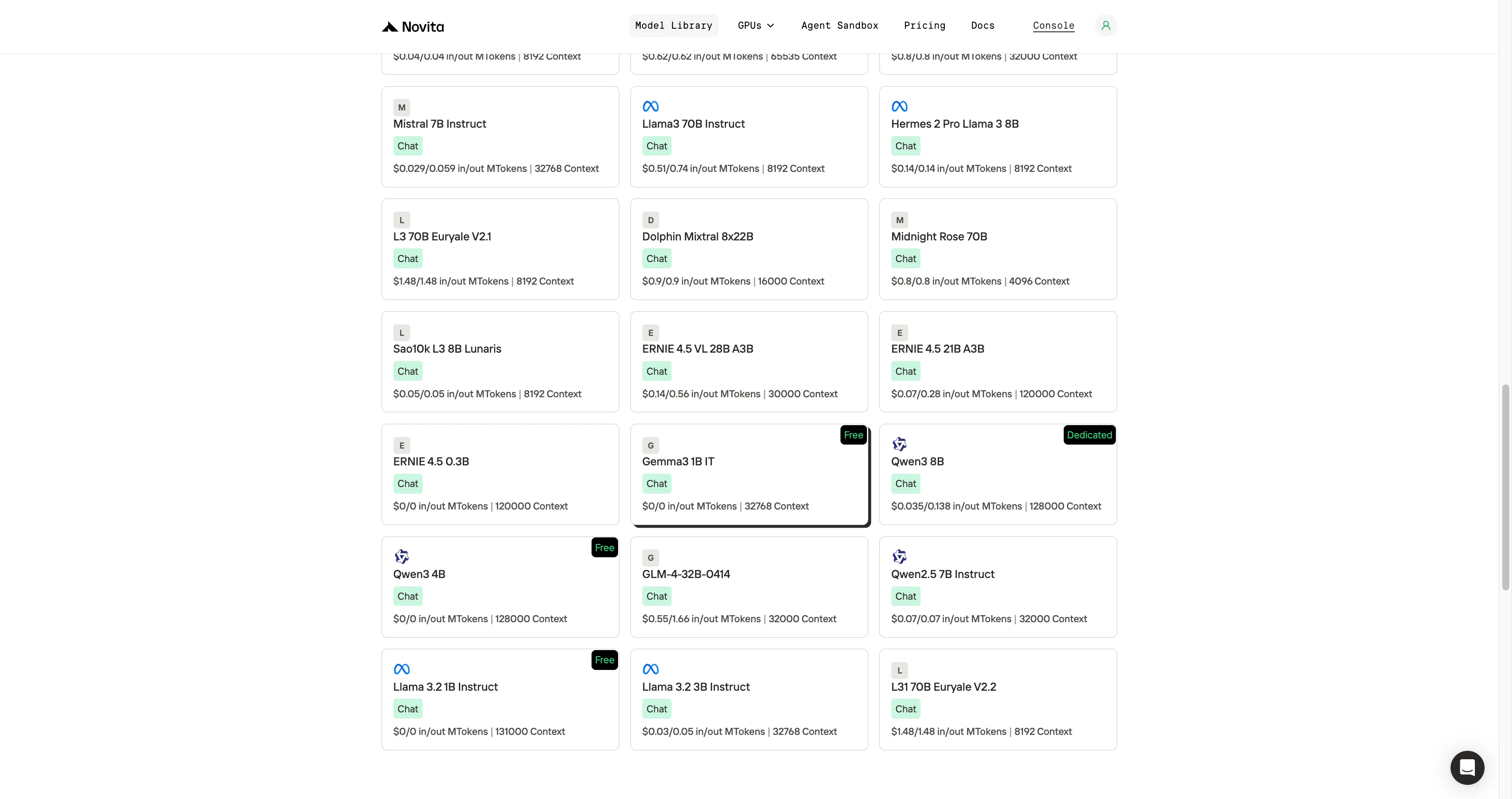
Paso 1: Inicia sesión y accede a la biblioteca de modelos
Inicia sesión en tu cuenta y haz clic en el botón Biblioteca de modelos.

¡Prueba Gemma 3 1B gratis ahora!
Paso 2: Elige tu modelo
Explora las opciones disponibles y selecciona el modelo que se adapte a tus necesidades.
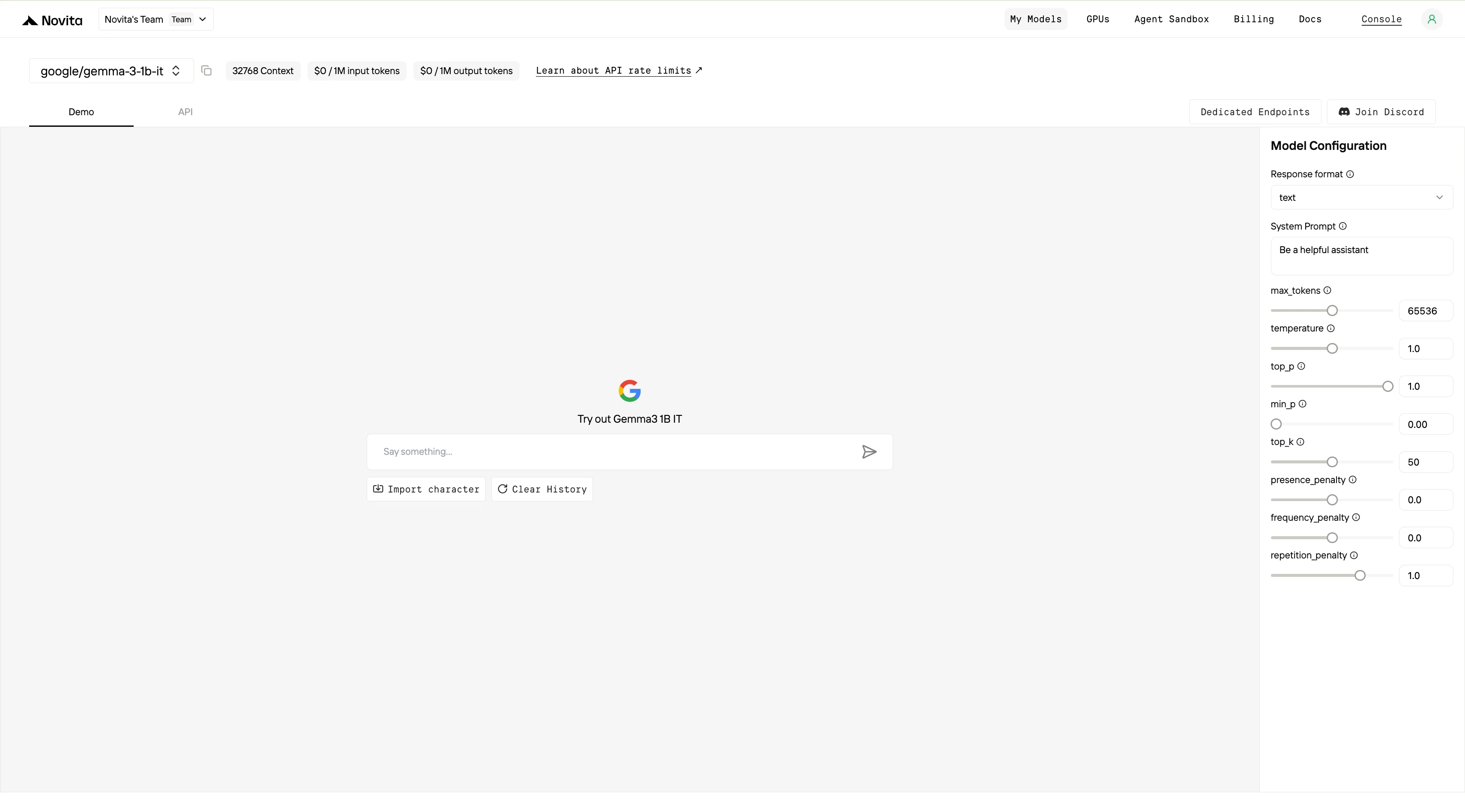
Paso 3: Inicia tu prueba gratuita
Comienza tu prueba gratuita para explorar las capacidades del modelo seleccionado.
Paso 4: Obtén tu clave de API
Para autenticarte con la API, te proporcionaremos una nueva clave de API. Entrando a la página de “Ajustes”, puedes copiar la clave de API como se indica en la imagen.

Paso 5: Instala la API
Instala la API usando el gestor de paquetes específico de tu lenguaje de programación.
Después de la instalación, importa las bibliotecas necesarias en tu entorno de desarrollo. Inicializa la API con tu clave de API para empezar a interactuar con el LLM de Novita AI. Este es un ejemplo de uso de la API de finalizaciones de chat para usuarios de Python.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/openai",
api_key="session_tx4VxsO56QFZbUWkCyCGSwujMfCa0XiMF6_y7U_s60AujO5Ti-XaXPZLjd4WVHPMO4FuR2tLmuSy9n1m5iIdIw==",
)
model = "google/gemma-3-1b-it"
stream = True # or False
max_tokens = 65536
system_content = "Be a helpful assistant"
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Gemma 3 1B muestra lo lejos que ha llegado la IA abierta: empaqueta 1B de parámetros en solo ~0,5 GB. Se ejecuta completamente sin conexión en teléfonos inteligentes o PC modernos, ofreciendo IA de baja latencia sin costos de nube. Con acceso gratuito a través de Hugging Face, Kaggle o la API estable de Novita AI, puedes experimentar, crear prototipos o incluso lanzar tu propia aplicación móvil impulsada por IA sin costo alguno. Gemma 3 1B hace que la “IA en tu bolsillo” sea una realidad práctica.
Preguntas frecuentes
¿Necesito una GPU para usar Gemma 3 1B?
No. Puede ejecutarse en hardware de CPU o móvil con ≥4 GB de RAM. Las GPUs mejoran la velocidad pero no son necesarias.
¿Cuál es la diferencia entre Gemma 3 1B PT y IT?
PT = preentrenado (modelo sin ajustar), IT = ajustado por instrucciones (listo para chat/asistente). La mayoría de los desarrolladores deben usar la versión IT.
¿Cómo puedo usar Gemma 3 1B sin descargar los pesos?
Puedes acceder a él al instante a través de la API gratuita de Novita AI, o probarlo en una demostración de Hugging Face.
Novita AI es una plataforma de IA en la nube que ofrece a los desarrolladores una forma sencilla de implementar modelos de IA mediante nuestra API simple, además de proporcionar una nube de GPU asequible y fiable para construir y escalar.



