

Gemma 3 1B 是Google DeepMind Gemma 3系列最小的成员,拥有10亿参数。专为移动端和Web应用设计,针对快速下载和低延迟进行了优化。量化后仅0.5GB,可完全在设备端运行,无需依赖云端即可实现离线AI使用,降低成本的同时提升隐私性。本文将帮助你免费获取Gemma 3 1B,打造属于你自己的AI应用!
值得注意的是,Novita AI已经推出了完全免费且高度稳定的Gemma 3 1B API。你甚至不需要支付硬件费用,零成本即可构建属于自己的AI驱动移动应用。
什么是Gemma 3 1B?
与更大的4B+参数模型不同,1B参数模型没有配备图像理解能力,以保持其轻量化。
| 特性 | 详情 |
|---|---|
| 模型类型 | 小型语言模型(SLM) |
| 参数规模 | 10亿 |
| 量化后体积 | 约0.5GB |
| 多模态支持 | 文本输入、文本输出 |
| 上下文窗口 | 128K |
| 语言支持 | 140+种语言 |
| 开放权重 | 提供预训练和指令微调版本 |
Gemma 3 1B是如何训练的?
训练数据:
Gemma 3 1B在约2万亿token的多样化文本语料上进行了训练,涵盖网页(覆盖140+种语言)、代码以及数学或逻辑数据。
代码与数学数据的优势:
加入代码和数学数据集后,尽管模型规模较小,仍可处理基础的编码问题和推理任务。值得注意的是,Gemma 3 1B的性能超越了旧版**Gemma 2(2B)**模型,而体积仅为后者的约20%。Google将这一性能提升归功于先进的训练技术和优化方案。
Gemma 3 1B做了哪些优化以适配小型硬件?
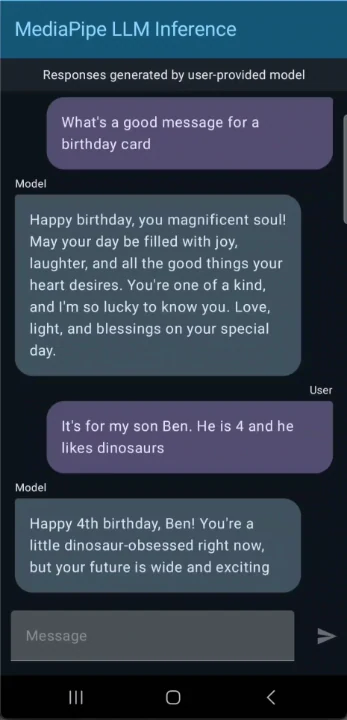
量化与模型体积优化:
Gemma 3 1B采用了量化感知训练(QAT)技术,可将权重精度降至4位,同时几乎不损失模型质量。Google提供了int4量化检查点(约529MB),在大幅缩减模型体积的同时保持了高精度。
Transformer架构优化:
该模型采用了优化的Transformer架构,包括改进的键值缓存处理机制,以降低内存带宽开销,同时在推理的“预填充”和“解码”阶段采用权重共享方案。这些调整提升了吞吐量、降低了内存占用,使其在有限硬件上也能高效运行。
哪里可以免费下载Gemma 3 1B?
Gemma 3 1B系统要求
总结来说,近几年的任何现代PC或智能手机,只要拥有几GB可用内存,都有可能运行Gemma 3 1B。
| 类别 | 详情 |
|---|---|
| 内存(RAM/显存) | 16位(BF16):1.5GB 8位(SFP8):1.1GB 4位(INT4):0.9GB(861MB) 建议:设备拥有4GB及以上内存以应对运行时开销。 |
| 存储 | 离线AI能力使得移动设备的存储成本可控。 |
| 性能 | 可在仅CPU的系统上运行(性能受限)。 GPU可大幅提升吞吐量(安卓端指标参考): 预填充(token/秒):CPU 322.5 / GPU 2585.9 解码(token/秒):CPU 47.4 / GPU 56.4 |
| 软件要求 | Python:Transformers 4.50+、Python 3.10+、PyTorch或TensorFlow(最新版本)。 移动端/C++:Gemma.cpp(优化的GGML/gguf移植版)或Google LiteRT运行时(需要C++编译器)。 建议:为简化操作,优先使用带PyTorch的Transformers库。 |
Gemma 3 1B下载方法
Gemma 3的权重是免费的,但你需要承担硬件成本,并同意遵守负责任的AI许可协议。
步骤1:选择你的运行环境和硬件
你可以通过以下方式运行Gemma 3 1B:
- 选项A:在安卓设备上使用演示应用
从GitHub下载预编译的演示应用并安装到你的安卓设备:
$ wget https://github.com/google-ai-edge/mediapipe-samples/releases/download/v0.1.3/llm_inference_v0.1.3-debug.apk
$ adb install llm_inference_v0.1.3-debug.apk
- 选项B:在电脑上运行(CPU或GPU)
如果你更倾向于使用电脑,可以跳过演示应用,直接使用gemma.cpp或Python库(如Transformers)运行模型。请确保你的硬件满足要求:
步骤2:从Hugging Face下载模型
在模型选择页面(或你自己的运行环境中),下载Gemma 3 1B量化INT4版本。你需要登录Hugging Face并接受使用条款。模型文件约529MB,下载完成后会自动针对你的设备进行优化,整个过程仅需几秒钟。
步骤3:运行模型
现在可以开始使用Gemma 3了!你可以通过文本类任务与模型交互,例如文章摘要、生成社交媒体文案或回答问题。该模型利用了Google AI Edge的LLM推理API,可实现高效的设备端处理。
步骤4:自定义Gemma 3(可选)
你可以使用自己的数据创建Gemma 3 1B的微调版本。按照提供的Colab笔记本进行训练、量化,并将自定义模型部署到移动设备或电脑上。
该版本将应用设置与硬件选择合并为单一步骤,同时保持内容的清晰度和逻辑流畅性。
如何通过API运行Gemma 3 1B?
值得注意的是,Novita AI已经推出了完全免费且高度稳定的Gemma 3 1B API。你甚至不需要支付硬件费用,零成本即可构建属于自己的AI驱动移动应用。
步骤1:登录并进入模型库
登录你的账户,点击模型库按钮。

步骤2:选择模型
浏览可用选项,选择适合你需求的模型。
步骤3:开始免费试用
开始免费试用,探索所选模型的能力。
步骤4:获取API密钥
为了通过API进行身份验证,我们会为你提供新的API密钥。进入“设置”页面,即可按照下图提示复制API密钥。

步骤5:安装API
使用对应编程语言的包管理器安装API。安装完成后,将必要的库导入到你的开发环境中,使用你的API密钥初始化API,即可开始与Novita AI LLM交互。以下是为Python用户提供的聊天补全API调用示例:
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/openai",
api_key="session_tx4VxsO56QFZbUWkCyCGSwujMfCa0XiMF6_y7U_s60AujO5Ti-XaXPZLjd4WVHPMO4FuR2tLmuSy9n1m5iIdIw==",
)
model = "google/gemma-3-1b-it"
stream = True # or False
max_tokens = 65536
system_content = "Be a helpful assistant"
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Gemma 3 1B展现了开放AI的进展——将10亿参数压缩到仅约0.5GB的体积中。它可在现代智能手机或PC上完全离线运行,无需云端成本即可提供低延迟AI服务。通过Hugging Face、Kaggle或Novita AI稳定的免费API,你可以零成本进行实验、原型开发,甚至发布自己的AI驱动移动应用。Gemma 3 1B让“口袋里的AI”成为现实。
常见问题解答
使用Gemma 3 1B需要GPU吗?
不需要。它可以在CPU或拥有≥4GB内存的移动硬件上运行。GPU可以提升速度,但并非必需。
Gemma 3 1B的PT版本和IT版本有什么区别?
PT = 预训练(原始模型),IT = 指令微调(可直接用于聊天/助手场景)。大多数开发者应使用IT版本。
如何在不下载权重的情况下使用Gemma 3 1B?
你可以通过Novita AI的免费API即时访问,或在Hugging Face的演示页面中测试。
Novita AI 是一个AI云平台,为开发者提供简单的API来部署AI模型,同时提供高性价比、可靠的GPU云服务,用于AI模型的构建和扩展。



