

Gemma 3 1B هو أصغر عضو في عائلة Gemma 3 من جوجل ديب مايند، ويحتوي على مليار معامل. صُمِّم لتطبيقات الهاتف المحمول والويب، وهو مُحسَّن لتنزيلات سريعة وزمن استجابة منخفض. يصل حجمه إلى 0.5 جيجابايت فقط عند ضغطه، ويمكن تشغيله بالكامل على الجهاز، مما يتيح استخدام ذكاء اصطناعي بدون اتصال بالإنترنت دون الحاجة إلى خدمات سحابية، ويقلل التكاليف ويعزز الخصوصية. ستمنحك هذه المقالة وصولاً مجانياً إلى نموذج Gemma 3 1B لمساعدتك في بناء ذكاء اصطناعي خاص بك!
ملاحظة هامة: أطلقت نوفيتا AI واجهة برمجة تطبيقات (API) مجانية بالكامل ومستقرة جداً لنموذج Gemma 3 1B. لا تحتاج حتى إلى دفع تكاليف الأجهزة – يمكنك بناء تطبيق هاتف محمول مدعوم بالذكاء الاصطناعي خاص بك بتكلفة صفرية.
ما هو نموذج Gemma 3 1B؟
على عكس النماذج الأكبر حجماً (4B+)، لم يتم منح نموذج 1B قدرة على فهم الصور، للحفاظ على خفته.
| الميزة | التفاصيل |
|---|---|
| نوع النموذج | نموذج لغوي صغير (SLM) |
| المعاملات | مليار |
| الحجم (بعد الضغط) | ~0.5 جيجابايت |
| دعم تعدد الوسائط | إدخال نصي، مخرج نصي |
| نافذة السياق | 128K |
| دعم اللغات | أكثر من 140 لغة |
| أوزان مفتوحة | نسخ مُدرَّبة مسبقاً ومُعدَّلة للتعليمات |
كيف يتم تدريب نموذج Gemma 3 1B؟
بيانات التدريب:
تم تدريب نموذج Gemma 3 1B على مجموعة نصية متنوعة من الرموز (tokens) تبلغ approximately 2 تريليون رمز، تتضمن صفحات ويب (تغطي أكثر من 140 لغة)، أكواد برمجية، وبيانات رياضية أو منطقية.
مزايا تضمين بيانات الأكواد والرياضيات:
يتيح تضمين مجموعات بيانات الأكواد والرياضيات للنموذج التعامل مع أسئلة البرمجة الأساسية ومهام الاستدلال، على الرغم من حجمه الأصغر. بشكل مذهل، يتفوق نموذج Gemma 3 1B على النموذج الأقدم Gemma 2 (2B)، ويحقق هذا الأداء بينما يصل حجمه إلى ~20% فقط من حجمه. تُعزى جوجل هذا التحسن في الأداء إلى تقنيات تدريب متقدمة وتحسينات.
ما الذي قام به نموذج Gemma 3 1B ليعمل على أجهزة صغيرة الحجم؟
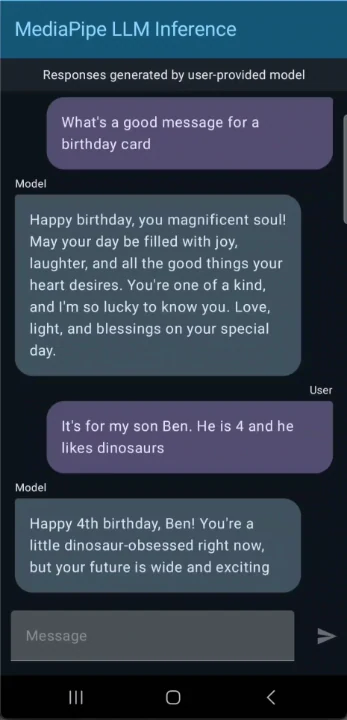
استخدم نموذج Gemma 3 1B لبناء تطبيق دردشة لنظام أندرويد
الضغط (Quantization) وتحسين حجم النموذج:
يستخدم نموذج Gemma 3 1B التدريب الواعي بالضغط (QAT)، مما يتيح دقة أوزان تصل إلى 4 بتات مع فقدان جودة ضئيل. تقدم جوجل نقطة تفتيش (checkpoint) مضغوطة بتقنية int4 (~529 ميجابايت)، التي تحافظ على دقة عالية بينما تقلل حجم النموذج بشكل كبير.
تحسينات بنية المحول (Transformer):
يتميز النموذج ببنية محول (Transformer) مُحسَّنة، تتضمن تحسين معالجة ذاكرة التخزين المؤقت للمفاتيح والقيم لتقليل حمل عرض النطاق الترددي للذاكرة، ومشاركة الأوزان بين مراحل “الملء المسبق” (prefill) و"فك التشفير" (decode) للاستدلال. تعزز هذه التعديلات الإنتاجية وتقلل استخدام الذاكرة، مما يجعلها فعالة جداً للأجهزة محدودة الإمكانيات.
أين يمكنني تنزيل نموذج Gemma 3 1B مجاناً؟
متطلبات النظام لنموذج Gemma 3 1B
باختصار، أي جهاز كمبيوتر شخصي حديث أو هاتف ذكي من السنوات الأخيرة يمكنه تشغيل نموذج Gemma 3 1B، طالما يحتوي على بضعة جيجابايت من الذاكرة المتاحة.
| الفئة | التفاصيل |
|---|---|
| الذاكرة (RAM/VRAM) | 16 بت (BF16): 1.5 جيجابايت |
| 8 بت (SFP8): 1.1 جيجابايت | |
| 4 بت (INT4): 0.9 جيجابايت (861 ميجابايت) | |
| موصى به: أجهزة تحتوي على 4 جيجابايت أو أكثر من ذاكرة الوصول العشوائي (RAM) لتحمل أوقات التشغيل. | |
| التخزين | تتيح قدرة الذكاء الاصطناعي بدون اتصال بالإنترنت إدارة مفاضلة التخزين بشكل جيد لأجهزة الهاتف المحمول. |
| الأداء | يمكن تشغيله على أنظمة تعمل بمعالج مركزي (CPU) فقط (أداء محدود). |
| تعزز وحدة المعالجة الرسومية (GPU) الإنتاجية بشكل كبير (انظر مقاييس أندرويد): | |
| الملء المسبق (tokens/ثانية): CPU: 322.5/GPU 2585.9 | |
| فك التشفير (tokens/ثانية): CPU: 47.4/GPU 56.4 | |
| متطلبات البرمجيات | بايثون: مكتبة Transformers 4.50 أو أحدث، بايثون 3.10 أو أحدث، PyTorch أو TensorFlow (أحدث الإصدارات). |
| للأجهزة المحمولة/C++: Gemma.cpp (منفذ مُحسَّن لـ GGML/gguf) أو بيئة تشغيل Google LiteRT (مطلوب مترجم C++). | |
| موصى به: استخدم مكتبة Transformers مع PyTorch للتبسيط. |
طرق تنزيل نموذج Gemma 3 1B
أوزان نموذج Gemma 3 مجانية، ولكن يجب عليك دفع تكاليف الأجهزة والموافقة على ترخيص ذكاء اصطناعي مسؤول.
الخطوة 1: اختر إعدادك والأجهزة الخاصة بك
يمكنك تشغيل نموذج Gemma 3 1B بإحدى الطرق التالية:
- الخيار أ: استخدم تطبيق العرض التجريبي على نظام أندرويد
قم بتنزيل تطبيق العرض التجريبي الجاهز من GitHub وتثبيته على جهاز أندرويد الخاص بك:
$ wget https://github.com/google-ai-edge/mediapipe-samples/releases/download/v0.1.3/llm_inference_v0.1.3-debug.apk
$ adb install llm_inference_v0.1.3-debug.apk
- الخيار ب: التشغيل على جهاز الكمبيوتر الخاص بك (معالج مركزي CPU أو وحدة معالجة رسومية GPU)
إذا كنت تفضل استخدام جهاز كمبيوتر، يمكنك تخطي تطبيق العرض التجريبي وتشغيل النموذج مباشرة باستخدام أدوات مثلgemma.cppأو مكتبات بايثون (مثلTransformers). تأكد من أن أجهزتك تلبي المتطلبات:
الخطوة 2: تنزيل النموذج من منصة Hugging Face
على شاشة اختيار النموذج (أو عبر إعدادك الخاص)، قم بتنزيل النسخة المضغوطة بتقنية INT4 من نموذج Gemma 3 1B. ستحتاج إلى تسجيل الدخول إلى منصة Hugging Face وقبول شروط الاستخدام. سيقوم النموذج، الذي يبلغ حجمه approximately 529 ميجابايت، بالتحسين تلقائياً لجهازك بعد التنزيل، وهي عملية تستغرق بضع ثوانٍ فقط.
الخطوة 3: تشغيل النموذج
ابدأ باستخدام نموذج Gemma 3! تفاعل معه من خلال مهام نصية، مثل تلخيص المقالات، إنشاء منشورات لوسائل التواصل الاجتماعي، أو الإجابة على الأسئلة. يستفيد النموذج من واجهة برمجة تطبيقات استدلال النماذج اللغوية الكبيرة (LLM Inference API) من جوجل AI Edge لمعالجة فعالة على الجهاز.
الخطوة 4: تخصيص نموذج Gemma 3 (اختياري)
أنشئ نسختك الخاصة المُعدَّلة من نموذج Gemma 3 1B باستخدام بياناتك. اتبع دفتر Colab المقدم لتدريب النموذج، ضغطه، ونشره على أجهزة الهاتف المحمول أو أجهزة الكمبيوتر.
هذه النسخة تدمج إعداد التطبيق واختيار الأجهزة في خطوة واحدة مع الحفاظ على الوضوح والمنطق التسلسلي.
أين يمكنني تشغيل نموذج Gemma 3 1B عبر واجهة برمجة التطبيقات (API)؟
ملاحظة هامة: أطلقت نوفيتا AI واجهة برمجة تطبيقات (API) مجانية بالكامل ومستقرة جداً لنموذج Gemma 3 1B. لا تحتاج حتى إلى دفع تكاليف الأجهزة – يمكنك بناء تطبيق هاتف محمول مدعوم بالذكاء الاصطناعي خاص بك بتكلفة صفرية.
الخطوة 1: تسجيل الدخول والوصول إلى مكتبة النماذج
سجل الدخول إلى حسابك وانقر على زر مكتبة النماذج.

جرّب نموذج Gemma 3 1B المجاني الآن!
الخطوة 2: اختر النموذج الخاص بك
تصفح الخيارات المتاحة واختر النموذج الذي يناسب احتياجاتك.
الخطوة 3: ابدأ تجربتك المجانية
ابدأ تجربتك المجانية لاستكشاف قدرات النموذج المحدد.
الخطوة 4: احصل على مفتاح API الخاص بك
للمصادقة مع واجهة برمجة التطبيقات، سنزودك بمفتاح API جديد. عند الدخول إلى صفحة “الإعدادات”، يمكنك نسخ مفتاح API كما هو موضح في الصورة.

الخطوة 5: تثبيت واجهة برمجة التطبيقات
قم بتثبيت واجهة برمجة التطبيقات باستخدام مدير الحزم الخاص بلغة البرمجة التي تستخدمها.
بعد التثبيت، استورد المكتبات الضرورية إلى بيئة التطوير الخاصة بك. قم بتهيئة واجهة برمجة التطبيقات باستخدام مفتاح API الخاص بك لبدء التفاعل مع نماذج اللغات الكبيرة (LLM) من نوفيتا AI. هذا مثال على استخدام واجهة برمجة تطبيقات إكمال الدردشة لمستخدمي لغة بايثون.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/openai",
api_key="session_tx4VxsO56QFZbUWkCyCGSwujMfCa0XiMF6_y7U_s60AujO5Ti-XaXPZLjd4WVHPMO4FuR2tLmuSy9n1m5iIdIw==",
)
model = "google/gemma-3-1b-it"
stream = True # or False
max_tokens = 65536
system_content = "Be a helpful assistant"
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
يُظهر نموذج Gemma 3 1B مدى تقدم الذكاء الاصطناعي المفتوح – حيث يضم مليار معامل في حجم يصل إلى ~0.5 جيجابايت فقط. يعمل بالكامل بدون اتصال بالإنترنت على الهواتف الذكية الحديثة أو أجهزة الكمبيوتر الشخصية، ويوفر ذكاء اصطناعي منخفض زمن الاستجابة دون تكاليف سحابية. مع الوصول المجاني عبر منصة Hugging Face، Kaggle، أو واجهة برمجة التطبيقات المستقرة من نوفيتا AI، يمكنك التجربة، إنشاء نماذج أولية، أو حتى إطلاق تطبيق هاتف محمول مدعوم بالذكاء الاصطناعي خاص بك بتكلفة صفرية. يجعل نموذج Gemma 3 1B فكرة “الذكاء الاصطناعي في جيبك” حقيقة عملية.
الأسئلة الشائعة
هل أحتاج إلى وحدة معالجة رسومية (GPU) لاستخدام نموذج Gemma 3 1B؟
لا. يمكن تشغيله على معالج مركزي (CPU) أو أجهزة محمولة تحتوي على ذاكرة وصول عشوائي (RAM) سعة 4 جيجابايت أو أكثر. تعزز وحدات المعالجة الرسومية (GPU) السرعة ولكنها غير مطلوبة.
ما الفرق بين نسختي PT و IT من نموذج Gemma 3 1B؟
PT = مُدرَّب مسبقاً (نموذج خام)، IT = مُعدَّل للتعليمات (جاهز للدردشة/العمل كمساعد). يجب على معظم المطورين استخدام نسخة IT.
كيف يمكنني استخدام نموذج Gemma 3 1B بدون تنزيل الأوزان؟
يمكنك الوصول إليه فوراً عبر واجهة برمجة التطبيقات المجانية من نوفيتا AI، أو اختباره في عرض تجريبي على منصة Hugging Face.
نوفيتا AI هي منصة سحابية للذكاء الاصطناعي تقدم للمطورين طريقة سهلة لنشر نماذج الذكاء الاصطناعي باستخدام واجهة برمجة التطبيقات البسيطة الخاصة بنا، بالإضافة إلى توفير سحابة وحدات معالجة رسومية (GPU) بأسعار معقولة وموثوقة للبناء والتوسع.



