

Gemma 3 1B ist das kleinste Mitglied der Gemma-3-Familie von Google DeepMind mit 1 Milliarde Parametern. Es wurde für mobile und Web-Anwendungen entwickelt, ist optimiert für schnelle Downloads und niedrige Latenz. Bei nur 0,5 GB Größe im quantisierten Zustand läuft es vollständig On-Device, ermöglicht Offline-KI-Nutzung ohne Cloud-Abhängigkeit, senkt Kosten und verbessert den Datenschutz. Dieser Artikel gibt Ihnen kostenlosen Zugriff auf Gemma 3 1B, damit Sie Ihre eigene KI erstellen können!
Hinweis: Novita AI hat eine vollständig kostenlose und äußerst stabile Gemma 3 1B-API gestartet. Sie müssen nicht einmal für Hardware bezahlen – Sie können Ihre eigene KI-gestützte mobile Anwendung völlig kostenlos erstellen.
Was ist Gemma 3 1B?
Im Gegensatz zu den größeren 4B±Modellen wurde dem 1B-Modell keine Bildverstehen-Funktion hinzugefügt, um es schlank zu halten.
| Funktion | Details |
|---|---|
| Modelltyp | Kleines Sprachmodell (SLM) |
| Parameter | 1 Milliarde |
| Größe (quantisiert) | ~0,5 GB |
| Multimodale Unterstützung | Texteingabe, Textausgabe |
| Kontextfenster | 128K |
| Sprachunterstützung | 140+ Sprachen |
| Offene Gewichte | Vortrainierte und instruktionsabgestimmte Varianten |
Wie wird Gemma 3 1B trainiert?
Trainingsdaten:
Gemma 3 1B wurde an einem vielfältigen Textkorpus von etwa 2 Billionen Tokens trainiert, darunter Webseiten (aus 140+ Sprachen), Code sowie mathematische oder logische Daten.
Vorteile von Code- und Mathematikdaten:
Die Einbeziehung von Code- und Mathematikdatensätzen ermöglicht es dem Modell, trotz seiner geringen Größe grundlegende Programmierfragen und Denkaufgaben zu bearbeiten. Bemerkenswerterweise übertrifft Gemma 3 1B das ältere Gemma 2 (2B)-Modell und erreicht dies bei nur ~20 % seiner Größe. Google führt diesen Leistungsschub auf fortschrittliche Trainingsmethoden und Optimierungen zurück.
Welche Maßnahmen hat Gemma 3 1B ergriffen, um auf kleiner Hardware zu laufen?
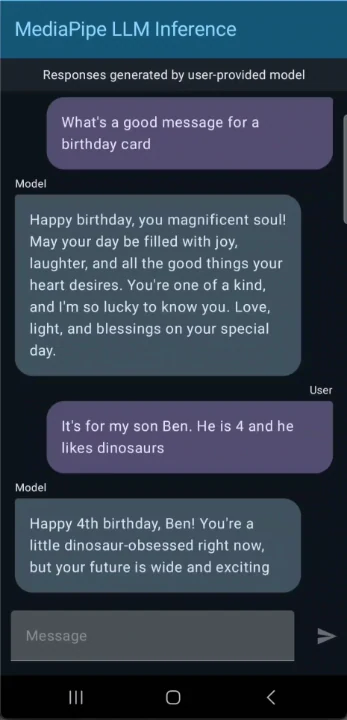
Verwenden Sie Gemma 3 1B, um eine Chat-App für Android zu erstellen
Quantisierung und Modellgrößenoptimierung:
Gemma 3 1B verwendet Quantisierungsbewusstes Training (QAT), das eine Gewichtsgenauigkeit von bis zu 4 Bit bei minimalem Qualitätsverlust ermöglicht. Google bietet einen int4-quantisierten Prüfpunkt (~529 MB), der eine hohe Genauigkeit beibehält und gleichzeitig die Modellgröße drastisch reduziert.
Verbesserungen der Transformer-Architektur:
Das Modell verfügt über eine optimierte Transformer-Architektur, einschließlich verbessertem Schlüssel-Wert-Cache-Handling zur Reduzierung des Speicherbandbreiten-Overheads und Gewichts gemeinsamer Nutzung zwischen den „Prefill“- und „Decode“-Phasen der Inferenz. Diese Anpassungen erhöhen den Durchsatz und reduzieren den Speicherverbrauch, sodass es für begrenzte Hardware äußerst effizient ist.
Wo kann ich Gemma 3 1B kostenlos herunterladen?
Systemanforderungen für Gemma 3 1B
Zusammenfassend kann jeder moderne PC oder jedes moderne Smartphone der letzten Jahre potenziell Gemma 3 1B ausführen, solange es über einige GB an verfügbarem Speicher verfügt.
| Kategorie | Details |
|---|---|
| Speicher (RAM/VRAM) | 16-Bit (BF16): 1,5 GB |
| 8-Bit (SFP8): 1,1 GB | |
| 4-Bit (INT4): 0,9 GB (861 MB) | |
| Empfohlen: Geräte mit 4 GB oder mehr RAM für Laufzeit-Overhead. | |
| Speicher | Die Offline-KI-Funktion macht den Speicherausgleich für mobile Geräte überschaubar. |
| Leistung | Kann auf CPU-only-Systemen ausgeführt werden (eingeschränkte Leistung). |
| GPU verbessert den Durchsatz deutlich (siehe Android-Metriken): | |
| Prefill (Tokens/s): CPU: 322.5/GPU 2585.9 | |
| Decode (Tokens/s): CPU: 47.4/GPU 56.4 | |
| Softwareanforderungen | Python: Transformers 4.50+, Python 3.10+, PyTorch oder TensorFlow (neueste Versionen). |
| Mobile/C++: Gemma.cpp (optimierter GGML/gguf-Port) oder Google LiteRT-Laufzeit (C+±Compiler erforderlich). | |
| Empfohlen: Verwenden Sie Transformers mit PyTorch für mehr Einfachheit. |
Methoden zum Herunterladen von Gemma 3 1B
Die Gewichte von Gemma 3 sind kostenlos, aber Sie müssen für Hardware bezahlen und einer verantwortungsvollen KI-Lizenz zustimmen.
Schritt 1: Wählen Sie Ihr Setup und Ihre Hardware
Sie können Gemma 3 1B auf eine der folgenden Arten ausführen:
- Option A: Verwenden Sie die Demo-App auf Android
Laden Sie die vorgefertigte Demo-App von GitHub herunter und installieren Sie sie auf Ihrem Android-Gerät:
$ wget https://github.com/google-ai-edge/mediapipe-samples/releases/download/v0.1.3/llm_inference_v0.1.3-debug.apk
$ adb install llm_inference_v0.1.3-debug.apk
- Option B: Auf Ihrem Computer ausführen (CPU oder GPU)
Wenn Sie lieber einen Computer verwenden möchten, können Sie die Demo-App überspringen und das Modell direkt mit Tools wiegemma.cppoder Python-Bibliotheken (z. B.Transformers) ausführen. Stellen Sie sicher, dass Ihre Hardware die Anforderungen erfüllt:
Schritt 2: Laden Sie das Modell von Hugging Face herunter
Wählen Sie auf der Modellauswahlseite (oder über Ihr eigenes Setup) die quantisierte INT4-Version von Gemma 3 1B herunter. Sie müssen sich bei Hugging Face anmelden und die Nutzungsbedingungen akzeptieren. Das Modell mit einer Größe von etwa 529 MB wird nach dem Herunterladen automatisch für Ihr Gerät optimiert, ein Vorgang, der nur wenige Sekunden dauert.
Schritt 3: Führen Sie das Modell aus
Beginnen Sie mit der Nutzung von Gemma 3! Interagieren Sie damit über textbasierte Aufgaben wie das Zusammenfassen von Artikeln, das Erstellen von Social-Media-Beiträgen oder das Beantworten von Fragen. Das Modell nutzt die LLM-Inferenz-API von Google AI Edge für eine effiziente On-Device-Verarbeitung.
Schritt 4: Passen Sie Gemma 3 an (optional)
Erstellen Sie Ihre eigene fein abgestimmte Version von Gemma 3 1B mit Ihren eigenen Daten. Befolgen Sie das bereitgestellte Colab-Notebook, um Ihr angepasstes Modell zu trainieren, zu quantisieren und auf mobilen Geräten oder Computern bereitzustellen.
Diese Version fasst die App-Einrichtung und die Hardware-Auswahl in einem einzigen Schritt zusammen und bewahrt dabei Klarheit und logischen Ablauf.
Wo kann ich Gemma 3 1B über eine API ausführen?
Hinweis: Novita AI hat eine vollständig kostenlose und äußerst stabile Gemma 3 1B-API gestartet. Sie müssen nicht einmal für Hardware bezahlen – Sie können Ihre eigene KI-gestützte mobile Anwendung völlig kostenlos erstellen.
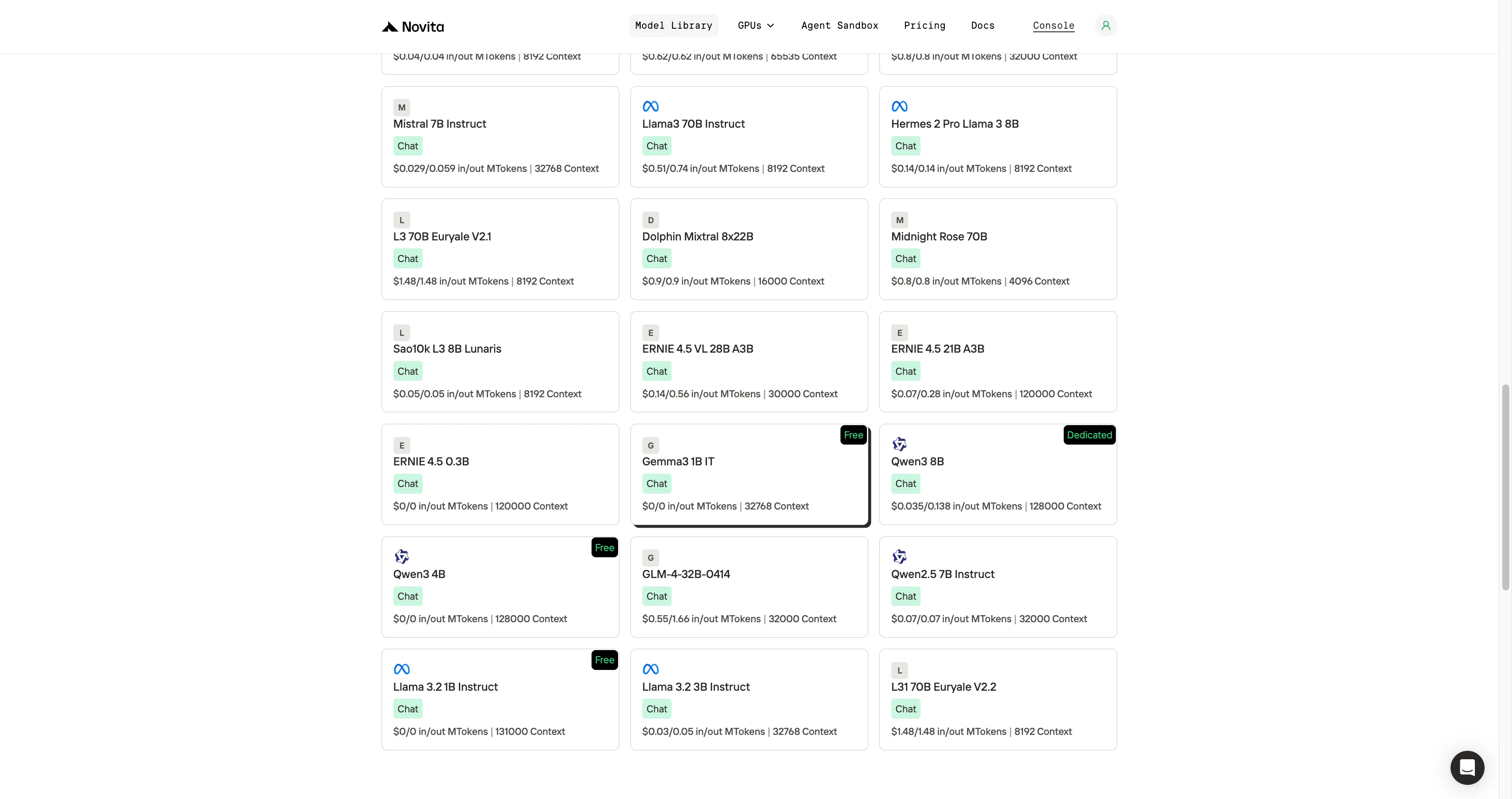
Schritt 1: Melden Sie sich an und greifen Sie auf die Modellbibliothek zu
Melden Sie sich bei Ihrem Konto an und klicken Sie auf die Schaltfläche Modellbibliothek.

Probieren Sie jetzt kostenlos Gemma 3 1B aus!
Schritt 2: Wählen Sie Ihr Modell
Durchsuchen Sie die verfügbaren Optionen und wählen Sie das Modell, das Ihren Anforderungen entspricht.
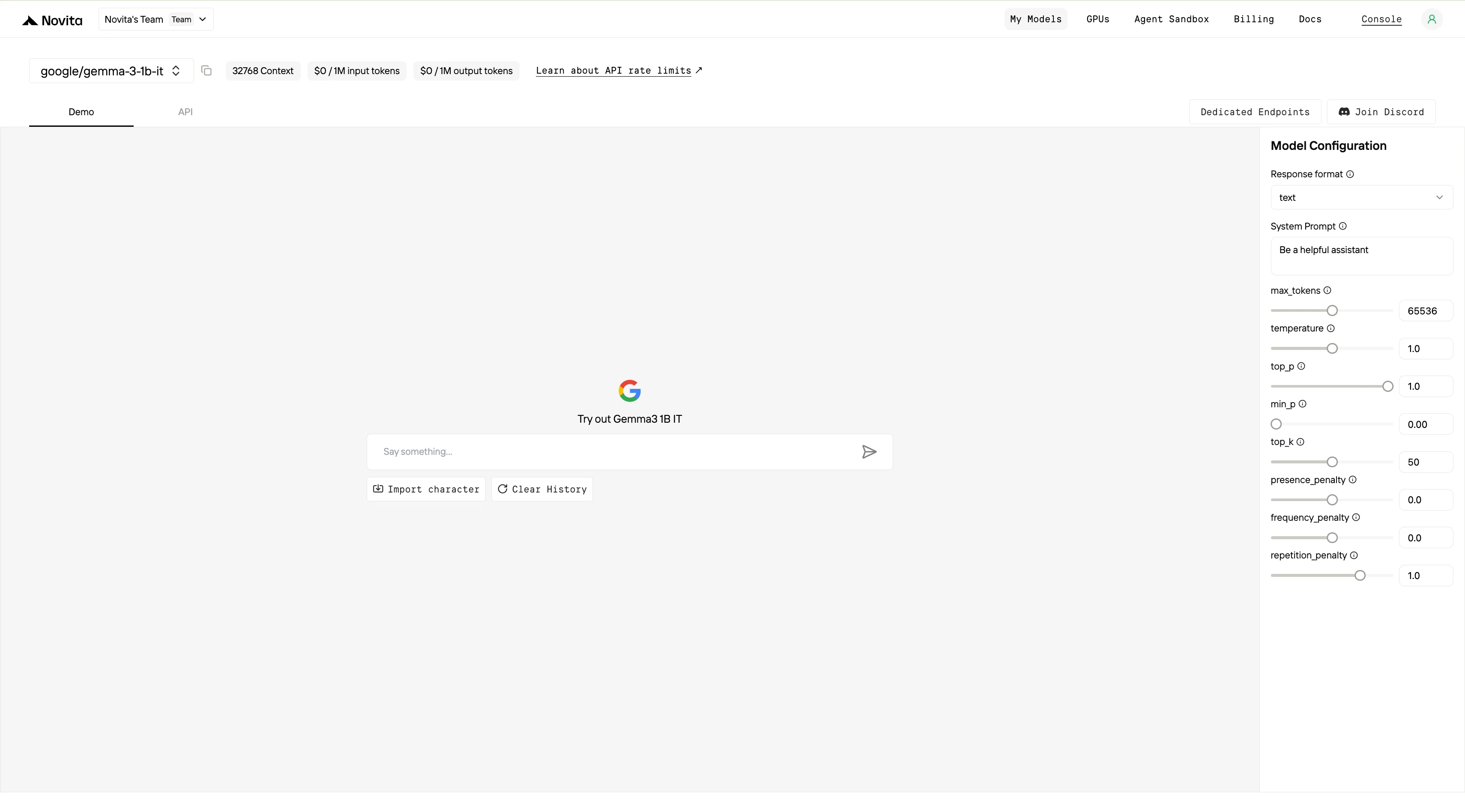
Schritt 3: Starten Sie Ihre kostenlose Testversion
Starten Sie Ihre kostenlose Testversion, um die Funktionen des ausgewählten Modells zu erkunden.
Schritt 4: Holen Sie sich Ihren API-Schlüssel
Zur Authentifizierung bei der API stellen wir Ihnen einen neuen API-Schlüssel zur Verfügung. Auf der Seite „Einstellungen“ können Sie den API-Schlüssel wie in der Abbildung gezeigt kopieren.

Schritt 5: Installieren Sie die API
Installieren Sie die API mit dem für Ihre Programmiersprache spezifischen Paketmanager.
Nach der Installation importieren Sie die erforderlichen Bibliotheken in Ihre Entwicklungsumgebung. Initialisieren Sie die API mit Ihrem API-Schlüssel, um mit dem Novita AI LLM zu interagieren. Dies ist ein Beispiel für die Verwendung der Chat-Completion-API für Python-Nutzer.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/openai",
api_key="session_tx4VxsO56QFZbUWkCyCGSwujMfCa0XiMF6_y7U_s60AujO5Ti-XaXPZLjd4WVHPMO4FuR2tLmuSy9n1m5iIdIw==",
)
model = "google/gemma-3-1b-it"
stream = True # or False
max_tokens = 65536
system_content = "Be a helpful assistant"
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Gemma 3 1B zeigt, wie weit die offene KI bereits fortgeschritten ist – es packt 1 Milliarde Parameter in nur ~0,5 GB. Es läuft vollständig offline auf modernen Smartphones oder PCs und bietet latenzarme KI ohne Cloud-Kosten. Mit kostenlosem Zugriff über Hugging Face, Kaggle oder die stabile API von Novita AI können Sie experimentieren, Prototypen erstellen oder sogar Ihre eigene KI-gestützte mobile App völlig kostenlos veröffentlichen. Gemma 3 1B macht „KI in der Tasche“ zu einer praktischen Realität.
Häufig gestellte Fragen
Benötige ich eine GPU, um Gemma 3 1B zu verwenden?
Nein. Es kann auf CPU oder mobiler Hardware mit ≥4 GB RAM ausgeführt werden. GPUs verbessern die Geschwindigkeit, sind aber nicht erforderlich.
Was ist der Unterschied zwischen Gemma 3 1B PT und IT?
PT = vortrainiert (rohes Modell), IT = instruktionsabgestimmt (bereit für Chat/Assistent). Die meisten Entwickler sollten die IT-Version verwenden.
Wie kann ich Gemma 3 1B verwenden, ohne Gewichte herunterzuladen?
Sie können sofort über die kostenlose API von Novita AI darauf zugreifen oder es in einer Hugging Face-Demo testen.
Novita AI ist eine KI-Cloud-Plattform, die Entwicklern eine einfache Möglichkeit bietet, KI-Modelle über unsere einfache API bereitzustellen, und gleichzeitig eine erschwingliche und zuverlässige GPU-Cloud zum Erstellen und Skalieren von Anwendungen bereitstellt.



