

Gemma 3 1B é o menor membro da família Gemma 3 do Google DeepMind, com 1 bilhão de parâmetros. Projetado para aplicativos móveis e web, ele é otimizado para downloads rápidos e baixa latência. Com apenas 0,5 GB quando quantizado, ele pode ser executado inteiramente no dispositivo, permitindo o uso de IA offline sem dependência de nuvem, reduzindo custos e aumentando a privacidade. Este artigo lhe dará acesso gratuito ao Gemma 3 1B para ajudá-lo a construir sua própria IA!
Notavelmente, a Novita AI lançou uma API do Gemma 3 1B completamente gratuita e altamente estável. Você não precisa nem pagar por hardware – pode construir seu próprio aplicativo móvel com tecnologia de IA sem nenhum custo.
O que é o Gemma 3 1B?
Ao contrário dos modelos maiores de 4B+, o modelo de 1B não recebeu capacidade de compreensão de imagens, para mantê-lo leve.
| Características | Detalhes |
|---|---|
| Tipo de Modelo | Modelo de Linguagem Pequeno (SLM) |
| Parâmetros | 1 bilhão |
| Tamanho (Quantizado) | ~0,5 GB |
| Suporte Multimodal | Entrada de texto, saída de texto |
| Janela de Contexto | 128K |
| Suporte a Idiomas | 140+ idiomas |
| Pesos Abertos | Variantes pré-treinadas e ajustadas para instruções |
Como o Gemma 3 1B é Treinado?
Dados de Treinamento:
O Gemma 3 1B foi treinado em um corpus de texto diversificado de aproximadamente 2 trilhões de tokens, incluindo páginas da web (abrangendo 140+ idiomas), código e dados matemáticos ou lógicos.
Vantagens dos Dados de Código e Matemática:
A inclusão de conjuntos de dados de código e matemática permite que o modelo lide com perguntas básicas de codificação e tarefas de raciocínio, apesar de seu tamanho menor. Impressionantemente, o Gemma 3 1B supera o modelo mais antigo Gemma 2 (2B), conseguindo isso enquanto tem apenas ~20% do seu tamanho. O Google atribui esse aumento de desempenho a técnicas de treinamento avançadas e otimizações.
O que o Gemma 3 1B Fez para Funcionar em Hardware Pequeno?
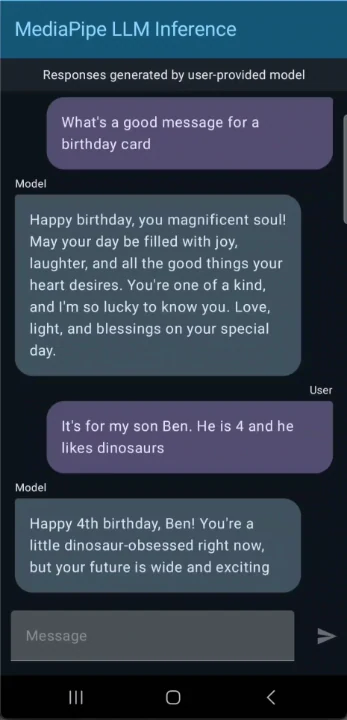
Use o Gemma 3 1B para construir um aplicativo de chat para Android
Quantização e Otimização de Tamanho de Modelo:
O Gemma 3 1B usa Treinamento Consciente de Quantização (QAT), permitindo que a precisão dos pesos chegue a 4 bits com perda mínima de qualidade. O Google oferece um checkpoint quantizado em int4 (~529 MB), que preserva alta precisão enquanto reduz drasticamente o tamanho do modelo.
Melhorias na Arquitetura Transformer:
O modelo apresenta uma arquitetura Transformer otimizada, incluindo um manuseio aprimorado do cache de chave-valor para reduzir a sobrecarga de largura de banda de memória e compartilhamento de pesos entre as fases de “prefill” e “decode” da inferência. Esses ajustes aumentam a taxa de transferência e reduzem o uso de memória, tornando-o altamente eficiente para hardware limitado.
Onde posso Baixar o Gemma 3 1B Gratuitamente?
Requisitos de Sistema do Gemma 3 1B
Em resumo, qualquer PC moderno ou smartphone dos últimos anos pode potencialmente executar o Gemma 3 1B, desde que tenha alguns GB de memória disponível.
| Categoria | Detalhes |
|---|---|
| Memória (RAM/VRAM) | 16 bits (BF16): 1,5 GB |
| 8 bits (SFP8): 1,1 GB | |
| 4 bits (INT4): 0,9 GB (861 MB) | |
| Recomendado: Dispositivos com 4 GB ou mais de RAM para sobrecarga de tempo de execução. | |
| Armazenamento | A capacidade de IA offline torna a troca de armazenamento gerenciável para dispositivos móveis. |
| Desempenho | Pode ser executado em sistemas apenas com CPU (desempenho limitado). |
| A GPU melhora significativamente a taxa de transferência (consulte as métricas do Android): | |
| Prefill (tokens/seg): CPU: 322,5/GPU 2585,9 | |
| Decode (tokens/seg): CPU: 47,4/GPU 56,4 | |
| Requisitos de Software | Python: Transformers 4.50+, Python 3.10+, PyTorch ou TensorFlow (versões mais recentes). |
| Móvel/C++: Gemma.cpp (porta GGML/gguf otimizada) ou runtime Google LiteRT (compilador C++ necessário). | |
| Recomendado: Use o Transformers com PyTorch para maior simplicidade. |
Métodos para Baixar o Gemma 3 1B
Os pesos do Gemma 3 são gratuitos, mas você deve pagar pelo hardware e concordar com uma licença de IA responsável.
Passo 1: Escolha sua Configuração e Hardware
Você pode executar o Gemma 3 1B de uma das seguintes formas:
- Opção A: Use o Aplicativo de Demonstração no Android
Baixe o aplicativo de demonstração pré-construído do GitHub e instale-o no seu dispositivo Android:
$ wget https://github.com/google-ai-edge/mediapipe-samples/releases/download/v0.1.3/llm_inference_v0.1.3-debug.apk
$ adb install llm_inference_v0.1.3-debug.apk
- Opção B: Execute no seu Computador (CPU ou GPU)
Se preferir usar um computador, você pode pular o aplicativo de demonstração e executar o modelo diretamente usando ferramentas comogemma.cppou bibliotecas Python (por exemplo,Transformers). Certifique-se de que seu hardware atenda aos requisitos:
Passo 2: Baixe o Modelo do Hugging Face
Na tela de seleção de modelo (ou através da sua própria configuração), baixe a versão quantizada INT4 do Gemma 3 1B. Você precisará fazer login no Hugging Face e aceitar os termos de uso. O modelo, com aproximadamente 529 MB, será otimizado automaticamente para o seu dispositivo após o download, um processo que leva apenas alguns segundos.
Passo 3: Execute o Modelo
Comece a usar o Gemma 3! Interaja com ele por meio de tarefas baseadas em texto, como resumir artigos, gerar publicações em redes sociais ou responder a perguntas. O modelo aproveita a API de Inferência LLM do Google AI Edge para processamento eficiente no dispositivo.
Passo 4: Personalize o Gemma 3 (Opcional)
Crie sua própria versão ajustada do Gemma 3 1B usando seus dados. Siga o notebook Colab fornecido para treinar, quantizar e implantar seu modelo personalizado em dispositivos móveis ou computadores.
Esta versão combina a configuração do aplicativo e a seleção de hardware em uma única etapa, mantendo a clareza e o fluxo lógico.
Onde Posso Executar o Gemma 3 1B via API?
Notavelmente, a Novita AI lançou uma API do Gemma 3 1B completamente gratuita e altamente estável. Você não precisa nem pagar por hardware – pode construir seu próprio aplicativo móvel com tecnologia de IA sem nenhum custo.
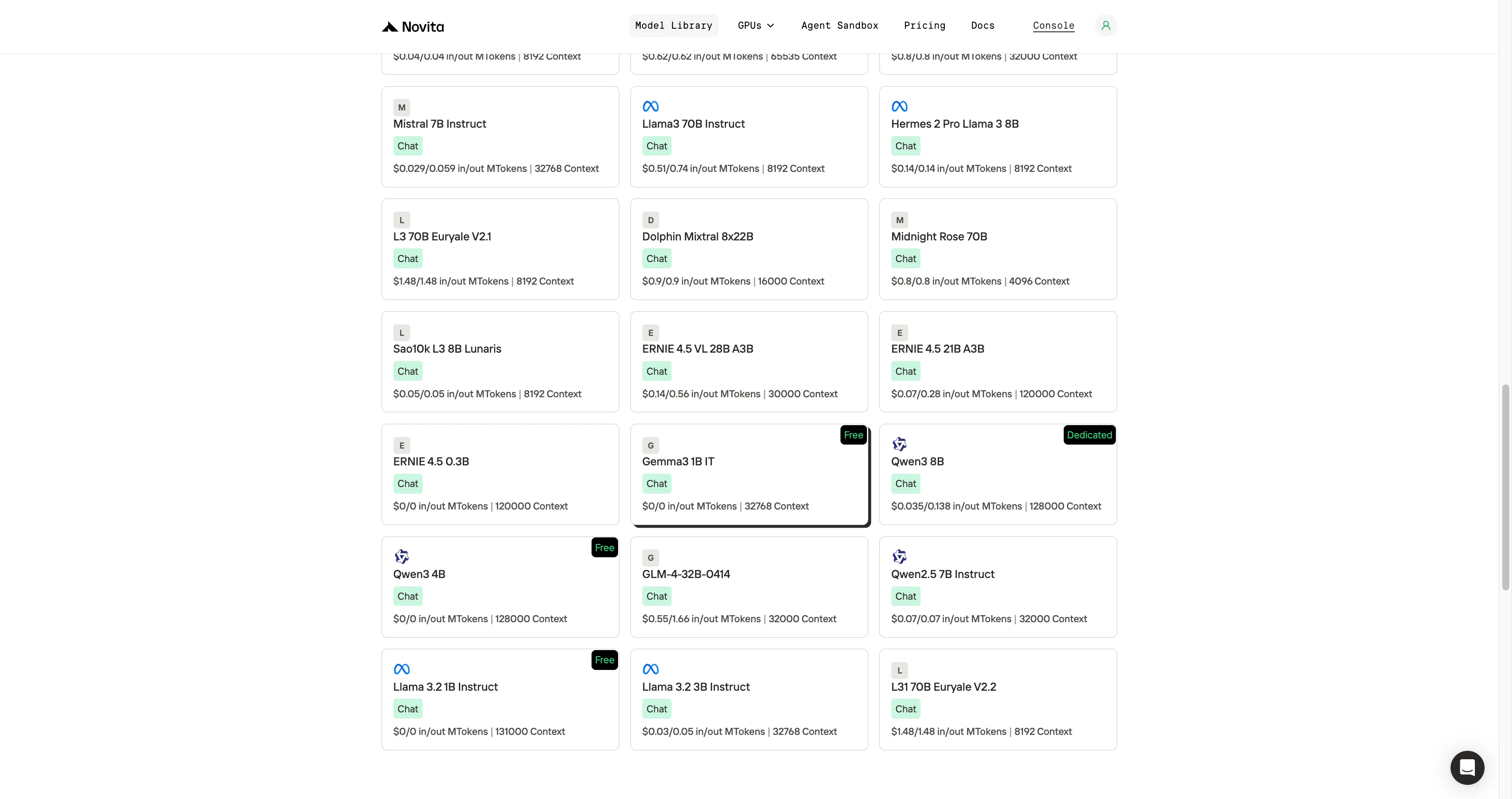
Passo 1: Faça Login e Acesse a Biblioteca de Modelos
Faça login na sua conta e clique no botão Biblioteca de Modelos.

Experimente o Gemma 3 1B Gratuito Agora!
Passo 2: Escolha seu Modelo
Navegue pelas opções disponíveis e selecione o modelo que atende às suas necessidades.
Passo 3: Inicie seu Teste Gratuito
Comece seu teste gratuito para explorar as capacidades do modelo selecionado.
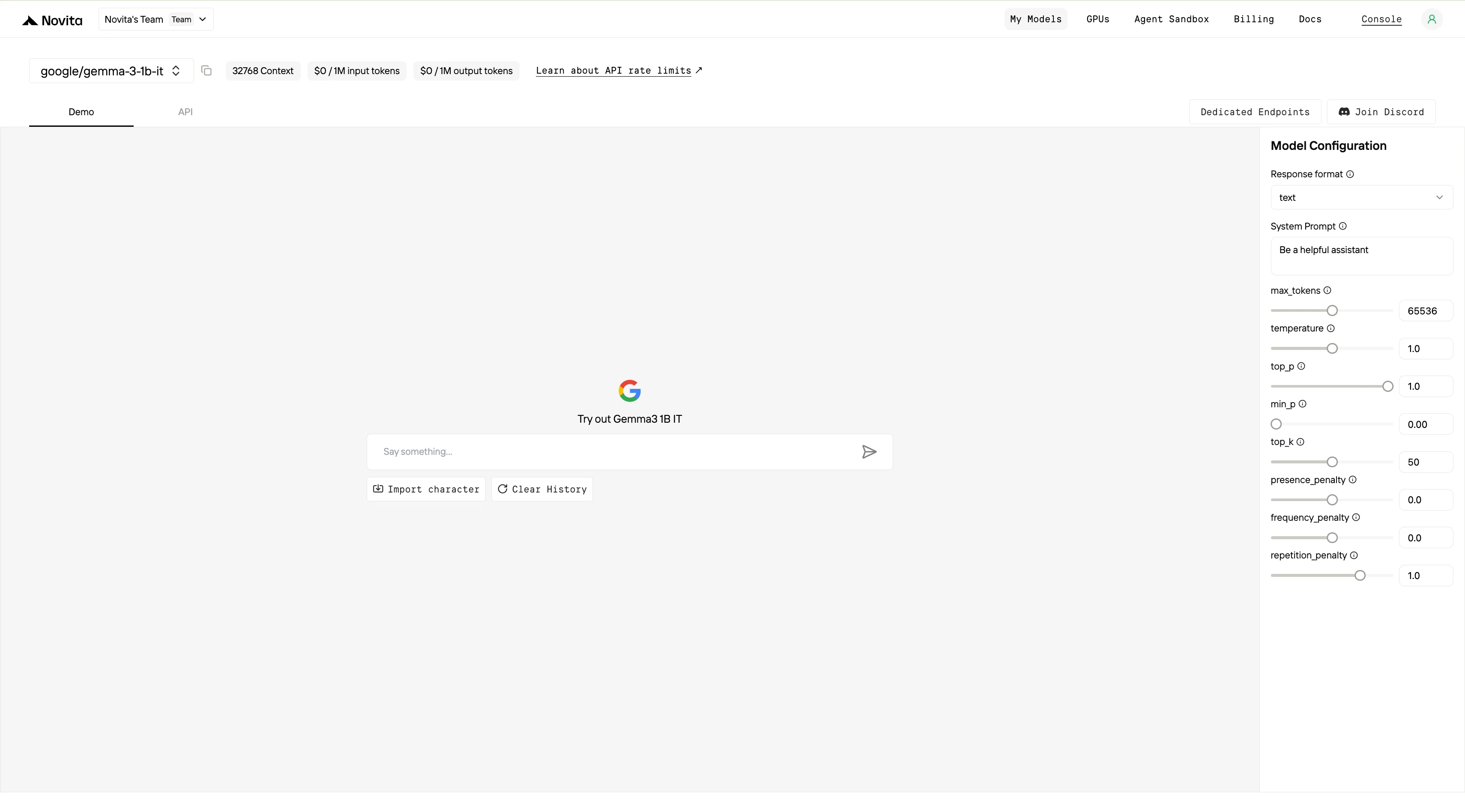
Passo 4: Obtenha sua Chave de API
Para se autenticar com a API, forneceremos uma nova chave de API. Na página “Configurações”, você pode copiar a chave de API conforme indicado na imagem.

Passo 5: Instale a API
Instale a API usando o gerenciador de pacotes específico para sua linguagem de programação.
Após a instalação, importe as bibliotecas necessárias para o seu ambiente de desenvolvimento. Inicialize a API com sua chave de API para começar a interagir com o Novita AI LLM. Este é um exemplo de uso da API de conclusões de chat para usuários de Python.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/openai",
api_key="session_tx4VxsO56QFZbUWkCyCGSwujMfCa0XiMF6_y7U_s60AujO5Ti-XaXPZLjd4WVHPMO4FuR2tLmuSy9n1m5iIdIw==",
)
model = "google/gemma-3-1b-it"
stream = True # or False
max_tokens = 65536
system_content = "Be a helpful assistant"
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
O Gemma 3 1B mostra o quanto a IA aberta evoluiu – empacotando 1 bilhão de parâmetros em apenas ~0,5 GB. Ele é executado totalmente offline em smartphones ou PCs modernos, oferecendo IA de baixa latência sem custos de nuvem. Com acesso gratuito via Hugging Face, Kaggle ou a API estável da Novita AI, você pode experimentar, criar protótipos ou até mesmo lançar seu próprio aplicativo móvel com tecnologia de IA sem nenhum custo. O Gemma 3 1B torna o “IA no seu bolso” uma realidade prática.
Perguntas Frequentes
Preciso de uma GPU para usar o Gemma 3 1B?
Não. Ele pode ser executado em CPU ou hardware móvel com ≥4 GB de RAM. As GPUs melhoram a velocidade, mas não são obrigatórias.
Qual a diferença entre o Gemma 3 1B PT e IT?
PT = pré-treinado (modelo bruto), IT = ajustado para instruções (pronto para chat/assistente). A maioria dos desenvolvedores deve usar a versão IT.
Como posso usar o Gemma 3 1B sem baixar os pesos?
Você pode acessá-lo instantaneamente através da API gratuita da Novita AI, ou testá-lo em uma demonstração do Hugging Face.
A Novita AI é uma plataforma de nuvem de IA que oferece aos desenvolvedores uma maneira fácil de implantar modelos de IA usando nossa API simples, além de fornecer uma nuvem de GPU acessível e confiável para construir e escalar.



