

À medida que pequenas empresas buscam adotar IA para tarefas como parsing de documentos, atendimento ao cliente, automação visual ou assistência de codificação, a escolha entre modelos de código aberto poderosos como Qwen3-VL-235B-A22B e GLM 4.5V pode parecer esmagadora. Qual é a diferença real entre seu desempenho, custo, acessibilidade e dificuldade de implantação?
Este artigo detalha a comparação entre arquitetura, capacidades de aplicação, benchmarks de desempenho, preços e métodos de acesso, oferecendo um caminho claro para decidir qual modelo se adapta melhor ao seu negócio. Seja você construindo fluxos de trabalho inteligentes, implantando localmente ou chamando APIs, este guia ajuda você a fazer uma escolha informada e confiante.
O Que Qwen3-VL-235B-A22B e GLM 4.5V Realmente Podem Fazer Pela Sua Pequena Empresa?
Quer ver qual modelo se adapta melhor ao seu fluxo de trabalho?
Tanto Qwen3-VL-235B-A22B quanto GLM 4.5V oferecem demonstrações online gratuitas da Novita AI!
| Área de Aplicação | Qwen3-VL-235B-A22B | GLM 4.5V | Quem Vence |
|---|---|---|---|
| Interação com GUI | Opera interfaces de PC/dispositivos móveis, entende elementos de interface, invoca ferramentas. | Suporta leitura de tela e ações básicas de desktop. | Empate Possível |
| Geração de Código a partir de Visual | ✅ Converte capturas de tela/vídeos em HTML, CSS, JS, diagramas Draw.io. | ❌ Nenhuma capacidade de geração de código a partir de visual divulgada. | Qwen Vence |
| Raciocínio 3D e Espacial | ✅ Avançado: reconhece posição de objetos, oclusão, ponto de vista; permite grounding 3D. | ⚠️ Lida com layout espacial entre imagens, sem grounding 3D ou IA incorporada. | Qwen Vence |
| Compreensão de Vídeo | ✅ Lida com vídeos de várias horas com contexto de 256K a 1M tokens; análise temporal detalhada. | ⚠️ Suporta segmentação de eventos, mas provavelmente limitado por uma janela de 66K tokens. | Qwen Vence |
| Escopo de Reconhecimento Visual | ✅ Treinado para “reconhecer tudo”: celebridades, anime, espécies raras, pontos turísticos, placas, texto antigo. | ⚠️ Análise de cena forte, mas nenhuma alegação de reconhecimento de entidades de nicho/raras. | Qwen Vence |
| OCR/Extração de Texto | ✅ 32 idiomas, robusto sob desfoque/inclinação, suporta caracteres raros/antigos e layouts estruturados. | ⚠️ Extrai documentos longos muito bem, mas falta amplitude de idiomas e texto raro. | Qwen Vence |
| Compreensão de Texto | ✅ Comparável a LLMs puros; fusão fluida de visão e texto sem perda de compreensão. | ✅ Gerador forte com alternância de “modo de raciocínio”; alta qualidade de linguagem. | Empate Possível |
| Facilidade de Acesso | Disponível via API ou demonstração. | Disponível via API ou demonstração e um Assistente de Desktop que suporta imagens, PDFs, vídeos etc. | GLM Vence |
Como Qwen3-VL-235B-A22B e GLM 4.5V Diferem em Arquitetura?
Qwen3-VL se destaca como a opção “peso pesado”, priorizando escala e capacidade de informação: seus 235B de parâmetros totais, janela de contexto de 256K tokens (expansível para 1M) e variantes de raciocínio especializadas o tornam ideal para tarefas em grande escala.
O GLM 4.5V, por outro lado, enfatiza flexibilidade e eficiência sem sacrificar desempenho. Seu design de parâmetros mais compacto de 106B, janela de contexto de 128K tokens e modelo unificado com um “Modo de Pensamento” alternável atingem um equilíbrio entre velocidade e profundidade
| Dimensão de Comparação | Qwen3-VL-235B-A22B | GLM 4.5V |
|---|---|---|
| Tamanho do Modelo e Arquitetura MoE | Parâmetros Totais: 235B Parâmetros Ativos por Entrada: 22B |
Parâmetros Totais: 106B Parâmetros Ativos por Entrada: 12B |
| Capacidade da Janela de Contexto | Nativa: 256K tokens Expansível para: 1M tokens |
Nativa: 128K tokens |
| Modos de Raciocínio e Instrução | Uma alternância de Modo de Pensamento, permitindo que usuários equilibrem entre respostas rápidas e raciocínio profundo. | Uma alternância de Modo de Pensamento, permitindo que usuários equilibrem entre respostas rápidas e raciocínio profundo. |
| Processamento Visual | Codificador baseado em ViT + decodificador de texto Melhorias: Interleaved-MRoPE (raciocínio em vídeo), recursos de visão fundidos |
Codificador baseado em ViT + decodificador de texto Melhoria: Adaptador limpo para fusão de visão e linguagem |
| Velocidade | Latência de 1,8 a 2s | Latência de 0,3 a 1,5s |
| Requisitos de Hardware | 8 GPUs NVIDIA H200. | uma única GPU de 80GB (como uma NVIDIA A100/H100 de 80GB) em precisão de 16 bits |
Então, Qual Modelo Tem Melhor Desempenho: Qwen3-VL-235B-A22B ou GLM 4.5V?
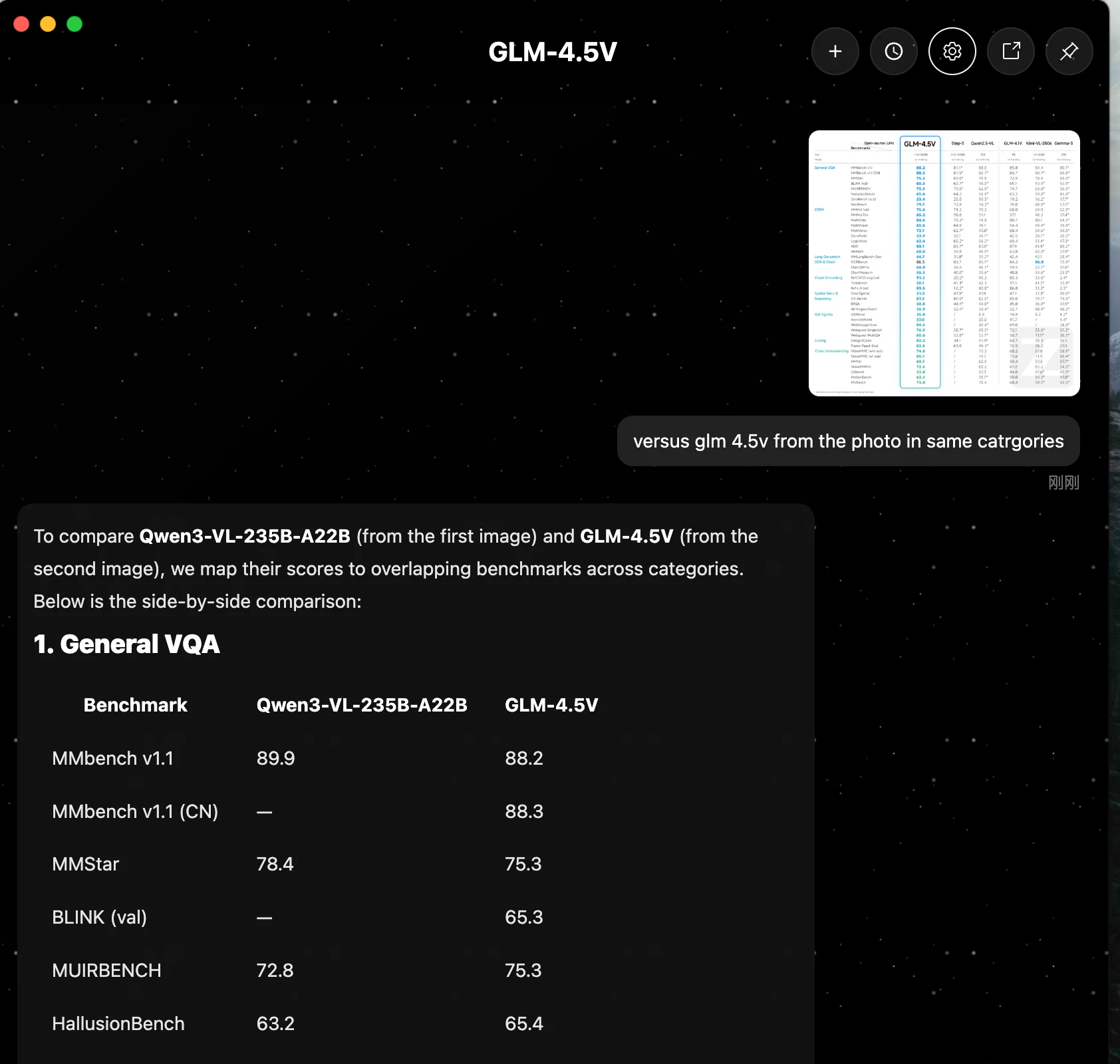
O Qwen3-VL-235B-A22B geralmente lidera em raciocínio central, processamento de documentos e geração de código. O GLM 4.5V tem desempenho próximo em várias tarefas, mas não supera o Qwen em nenhum benchmark apresentado.
| Categoria | Benchmark | Qwen3-VL-235B-A22B | GLM 4.5V |
|---|---|---|---|
| 1. VQA Geral | MMbench v1.1 | 89,9 | 88,2 |
| MMStar | 78,4 | 75,3 | |
| MUIRBENCH | 72,8 | 75,3 | |
| HallusionBench | 63,2 | 65,4 | |
| 2. STEM e Quebra-Cabeças | MMMU (val) | 78,7 | 75,4 |
| MMMU Pro | 68,1 | 65,2 | |
| MathVista | 84,9 | 84,6 | |
| MathVision | 66,5 | 65,6 | |
| MathVerse | 72,5 | 72,1 | |
| AI2D | 89,7 | 88,1 | |
| 3. Documentos Longos e OCR/Gráficos | MMLongBench-Doc | 57,0 | 44,7 |
| OCRBench | 920,0* | 86,5 | |
| 4. Codificação | Design2Code | 92,0 | 82,2 |
| 5. Compreensão de Vídeo | VideoMME (sem legendas) | 79,2 | 74,6 |
Você também pode usar uma chave de API da Novita AI para acessar o Assistente de Desktop do GLM gratuitamente—nenhum pagamento necessário, ao contrário do site oficial!
O Desktop foi projetado para os modelos multimodais da série GLM (GLM-4.5V, compatível com GLM-4.1V), suportando conversas interativas com texto, imagens, vídeos, PDFs, PPTs e muito mais. Ele se conecta à API multimodal do GLM para habilitar serviços inteligentes em vários cenários.
Configuração:
Nome do modelo: zai-org/glm-4.5v
URL da API: https://api.novita.ai/openai
Endpoint: /v1/chat/completions
Chave de API: da Novita AI
Obtenha a Chave de API e Experimente o Assistente de Desktop do GLM Gratuitamente Agora!
Como Acessar Qwen3-VL-235B-A22B e GLM 4.5V de Forma Barata e Rápida?
A Novita AI oferece APIs do Qwen3-VL com uma janela de contexto de 131K por $0,98 por entrada e $3,95 por saída. Ela também fornece APIs do GLM-4.6V com uma janela de contexto de 208K por $0,60 por entrada e $2,20 por saída, suportando saídas estruturadas e chamadas de função.
1. Interface Web (Mais Fácil para Iniciantes)
Experimente o Qwen 3 VL 235B A22B Agora!
2. Acesso via API (Para Desenvolvedores)
Passo 1: Faça Login e Acesse a Biblioteca de Modelos
Faça login na sua conta e clique no botão Biblioteca de Modelos.

Passo 2: Escolha Seu Modelo
Navegue pelas opções disponíveis e selecione o modelo que atende às suas necessidades.

Passo 3: Inicie Seu Teste Gratuito
Inicie seu teste gratuito para explorar as capacidades do modelo selecionado.
Passo 4: Obtenha Sua Chave de API
Para autenticar com a API, forneceremos uma nova chave de API para você. Acessando a página de “Configurações”, você pode copiar a chave de API conforme indicado na imagem.

Passo 5: Instale a API
Instale a API usando o gerenciador de pacotes específico da sua linguagem de programação.
Após a instalação, importe as bibliotecas necessárias para o seu ambiente de desenvolvimento. Inicialize a API com sua chave de API para começar a interagir com o LLM da Novita AI. Este é um exemplo de uso da API de conclusões de chat para usuários de Python.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/openai",
api_key="session_UxQ9B4FllYcK6ZwMw6OFh5Q15fFCM4gMHoTbNh4vB3ZF_Dc5yN4RzVXxOHjarOF-AhMO61lRJN8plthUCfFvZA==",
)
model = "qwen/qwen3-vl-235b-a22b-thinking"
stream = True # or False
max_tokens = 16384
system_content = "Be a helpful assistant"
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
3. Implantação Local (Usuários Avançados)
Requisitos:
- Qwen3-VL-235B-A22B: 8 GPUs NVIDIA H200.
- GLM 4.5V: uma única GPU de 80GB (como uma NVIDIA A100/H100 de 80GB) em precisão de 16 bits
Passos de Instalação:
- Baixe os pesos do modelo no HuggingFace ou ModelScope
- Escolha o framework de inferência: vLLM ou SGLang suportados
- Siga o guia de implantação no repositório oficial do GitHub
4. Integração
Usando CLI como Trae, Claude Code, Qwen Code
Se você quiser usar os principais modelos da Novita AI (como Qwen3-Coder, Kimi K2, DeepSeek R1) para assistência de codificação com IA no seu ambiente local ou IDE, o processo é simples: obtenha sua Chave de API, instale a ferramenta, configure as variáveis de ambiente e comece a codificar.
Para comandos de configuração detalhados e exemplos, consulte os tutoriais oficiais:
- Trae: Guia Passo a Passo para Acessar Modelos de IA na Sua IDE
- Claude Code: Como Usar o Kimi-K2 no Claude Code no Windows, Mac e Linux
- Qwen Code: Como Usar a API Compatível com OpenAI no Qwen Code (Configuração em 60s!)
Fluxos de Trabalho Multiagente com OpenAI Agents SDK
Construa sistemas multiagente avançados integrando a Novita AI com o SDK OpenAI Agents:
- Plug-and-play: Use os LLMs da Novita AI em qualquer fluxo de trabalho do OpenAI Agents.
- Suporta transferências, roteamento e uso de ferramentas: Projete agentes que podem delegar, triar ou executar funções, todos alimentados pelos modelos da Novita AI.
- Integração com Python: Basta definir o endpoint do SDK como
https://api.novita.ai/v3/openaie usar sua chave de API.
Conecte a API em Plataformas de Terceiros
API Compatível com OpenAI: Aproveite uma migração e integração sem complicações com ferramentas como Cline e Cursor, projetadas para o padrão de API do OpenAI.
Hugging Face: Use modelos nos Spaces, pipelines ou com a biblioteca Transformers via endpoints da Novita AI.
Frameworks de Agentes e Orquestração: Conecte facilmente a Novita AI com plataformas parceiras como Continue, AnythingLLM,LangChain, Dify e Langflow por meio de conectores oficiais e guias de integração passo a passo.
O Qwen3-VL-235B-A22B demonstra forças claras em raciocínio avançado, codificação visual, OCR multilíngue e processamento de longo contexto—tornando-o uma escolha de primeira para fluxos de trabalho exigentes e tarefas multimodais.
O GLM 4.5V, embora ligeiramente atrás em desempenho bruto, é mais leve e oferece um assistente de desktop, velocidade de inferência mais rápida e usabilidade plug-and-play mais ampla—especialmente para desenvolvedores e startups. Para a maioria dos casos de uso, Qwen3-VL-235B-A22B é ideal para profundidade e complexidade, enquanto GLM 4.5V se destaca em facilidade de uso e flexibilidade.
Perguntas Frequentes
O GLM 4.5V pode ser usado offline ou fora do navegador?
Sim, o GLM 4.5V suporta um assistente de desktop gratuito (via Novita AI) que permite que usuários interajam com texto, imagens, vídeos e PDFs localmente—algo que o Qwen3-VL-235B-A22B não oferece nativamente.
Qual é a forma mais barata e rápida de experimentar Qwen3-VL-235B-A22B e GLM 4.5V?
API do Qwen3-VL: Contexto de 131K, $0,98/entrada, $3,95/saída
API do GLM-4.6V: Contexto de 208K, $0,60/entrada, $2,20/saída, com saída estruturada e chamadas de função
Qual modelo tem melhor desempenho em avaliações de benchmark: Qwen3-VL-235B-A22B ou GLM 4.5V?
O Qwen3-VL-235B-A22B obtém pontuação consistentemente mais alta que o GLM 4.5V em categorias como raciocínio STEM (ex: MMMU), análise de documentos longos (MMLongBench-Doc), OCR (OCRBench) e codificação (Design2Code). O GLM 4.5V tem um bom desempenho, mas não supera o Qwen em nenhum benchmark listado.
A Novita AI é uma plataforma de nuvem de IA que oferece aos desenvolvedores uma maneira fácil de implantar modelos de IA usando nossa API simples, além de fornecer uma nuvem de GPU acessível e confiável para construção e escalonamento.



